Is throttled to not affect indexing − But if merging is too slow, Elasticsearch will also throttle indexing ! − Merge throttling − index.store.throttle.type=merge/none − indices.store.throttle.max_bytes_per_sec=<byte_string> − On SSDs consider throttling less, or not throttling at all − On spinning disks set: index.merge.scheduler.max_thread_count=1 ! − It is possible to „optimize“ an index towards some goal − Don’t call „optimize“ on a live index
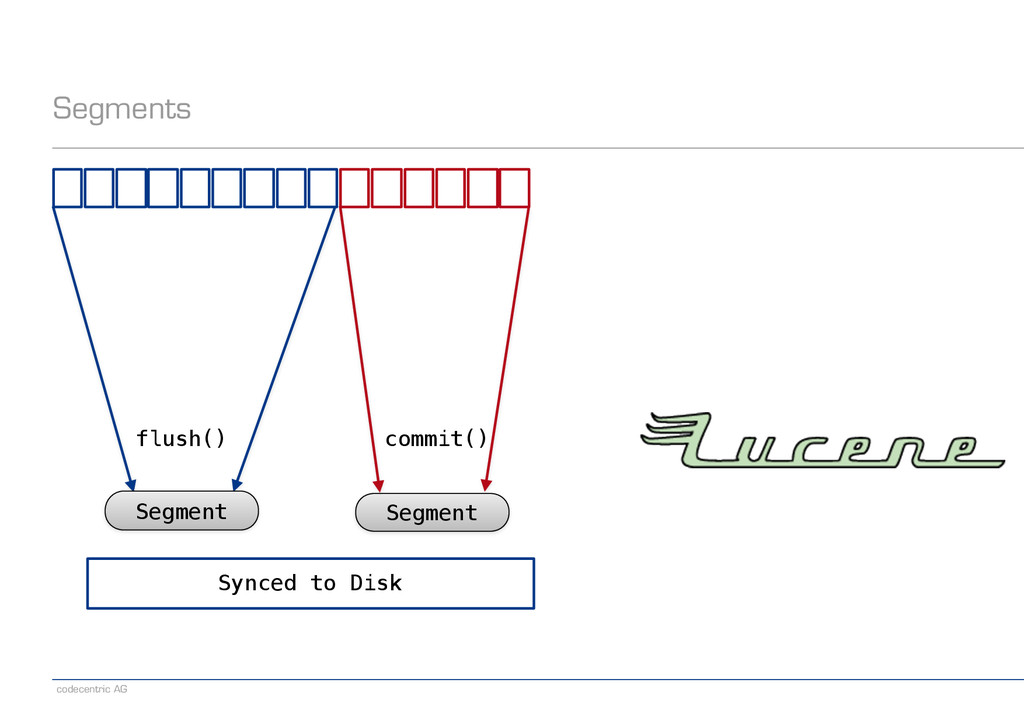
via index.refresh_interval (set to -1 to disable completely) − Dictated by application requirements − Can be explicitly requested via the refresh API or when indexing a document ! − Controlling flush − Some settings, most useful one is index.translog.flush_threshold_size − Disable flush completely via index.translog.disable_flush − Can be explicitly requested via the flush API
a single request − Index, create, update, delete ! − Try to find the optimal bulk size for your application − Consider bulk size in bytes, not only the number of documents − When in doubt, prefer smaller bulks over larger ones ! − Parallel bulk requests might improve throughput even further − Async calls or multiple clients
− Turn off refresh while indexing (if the index is not used) − Delay flushes (creates fewer but larger segments) − Throttle merging if applicable ! − Increase indices.memory.index_buffer_size (default is 10%) ! − Set number of replicas to zero − Add them when done indexing (and optimizing) − Adding new replicas is cheaper than „live“ replication ! − Use the bulk API ! − Disable warmup
Keep the _source field enabled and don’t set any fields to _stored − Only for very large _source, consider disabling it (but: no updates, reindexing, highlighting) ! − Analysis − Need field norms? If not, set norms.enabled=false − Need term frequencies and positions? Set index_options to what you really need ! − Use not_analyzed where you can ! − Enable dynamic mapping only where you need it
queries whenever you don’t need scoring − Filter results can be cached ! − Tricky caching behavior − Most simple filters are cached by default, but some not (e.g., geo) − Compound filters (bool/and/or/not) are not cached − You can still explicitly request caching by setting _cache − Bool filters query the cache for their (sub-)filters, but and/or/not filters don’t ! − But: This topic seems to be a moving target ! − Consider the scope of filters − Apply to query, aggregations/facets, or both? − Often „filtered query“ is what you need
query, then filter, then score − „First filter, then query“ is not as simple as one might expect ! − Elements of bool filters are executed sequentially − Place the most selective filter first ! − Consider using „accelerator“ filters − Additional filters which are not strictly needed − But aim to reduce work for uncached heavyweight filters − Place them before their respective counterpart
results with a single query − Avoid deep pagination (consider using scan+scroll API instead) ! − Try to optimize heavyweight queries via additional index-time operations − For example, prefix query vs. edge ngrams − Even if it requires indexing a source field twice − Consider using the „transform“ feature ! − Use warmup ! − Use query templates ! − Multi search API (bulk API for search)
Consider loading aggregations/facets as lazily as possible − Do you really need to offer all of them on the UI right away? − Can you hide some less relevant ones by default? ! − Only load once when retrieving paginated results − Consider omitting aggregations/facets when moving to another page − They likely stayed the same
the original document field contents − Sorting − Facetting/Aggregation − To some extent, scripting ! − Such field data of all documents is usually loaded into memory (and cached) − Can consume lots of memory − Especially when faceting on analyzed fields with many different values ! − Frequent cause of OutOfMemoryError
file system − Let the OS do the caching − Doc values can be enabled on a per-field basis ! − Advantages − Much lower JVM memory requirements − Much fewer garbage collections ! − Disadvantages − Slightly slower searches/aggregations (but not by much) ! − Recommendation − Try enabling them everywhere and see if you notice any bad effects − In any case, consider enabling them for fields used in big „offline“ aggregations
− Update = Delete + Add ! − Elasticsearch update API − Two flavors: „partial document“ and „script“ − Only saves network traffic, internally it is Read, Delete, Add − Do not use the update API to replace a whole document ! − Even small updates might take a while − A single expensive field prevents efficient update of a document
of inner objects are flattened, one-to-many relationships not possible − Elasticsearch offers „nested objects“ and „parent/child mapping“ ! − Nested objects − Stored as separate objects alongside the document − Loading/querying them does not cause much overhead − But cannot be updated on their own ! − Parent/child mapping − Child documents are separate documents on the same shard as their parent − Can be updated individually − Querying is more expensive and requires an in-memory join table
looking up documents ! − Not possible with random UUIDs − Like those generated by Java’s UUID class by default ! − Internally Elasticsearch now uses Flake IDs ! − If possible, consider using an appropriate UUID type
writes (index/update/delete) ! − Multiple replicas allow for parallel reads (get/search) − But indexing requests take longer − Unless you trade in safety via „replication=async“ ! − But sharding usually makes each individual search request slower − Accurate scoring may require an initial round-trip to each shard − Then a second round-trip performing the actual search − Reduce the search results of all shards at a single node − A third round-trip to retrieve the final set of documents from the relevant shards − Lots of network calls
Distributed search is expensive − Look for ways to direct each search request to a single shard only ! − Searching multiple indexes is the same as searching a sharded index − 1 index with 50 shards =~ 50 indexes with 1 shard each − In both cases, 50 Lucene indexes are searched
shards needs to be set at index creation time − Choose based on estimation and measurements − A little overallocation is OK, yet shards don’t come for free ! − If it turns out you need to scale higher, there are two options − Think about how to handle this right from the start ! − Migrate to a single new index with more shards − Requires the use of aliases and possibly a zero-downtime migration ! − Create a second index for new documents − Define an alias so that search considers both indexes − But: Requires additional effort for updates and deletes (which index to address?)
searches ! − Prerequisite: There are isolated „users“ (or tenants, etc.) ! − The „routing“ parameter allows for overriding the shard key − By default, the document ID is used ! − Consider using the user ID as shard key − Directs one user’s documents always to the same shard − Search will only require a single shard − Note: A shard may still contain multiple users’ data ! − Possible drawback: Some shards may become much bigger than others
searches cluttered with irrelevant data ! − Prerequisite: There are isolated „users“ (or tenants, etc.) ! − An index alias for each user decouples client-side view from physical storage − In the beginning, all aliases point to the same index − Later, migrate users with many documents into their own indexes − Switch aliases accordingly ! − Possible drawback: Cluster state may become big when there are lots of aliases ! − Consider combining the „routing“ and „aliases“ approaches
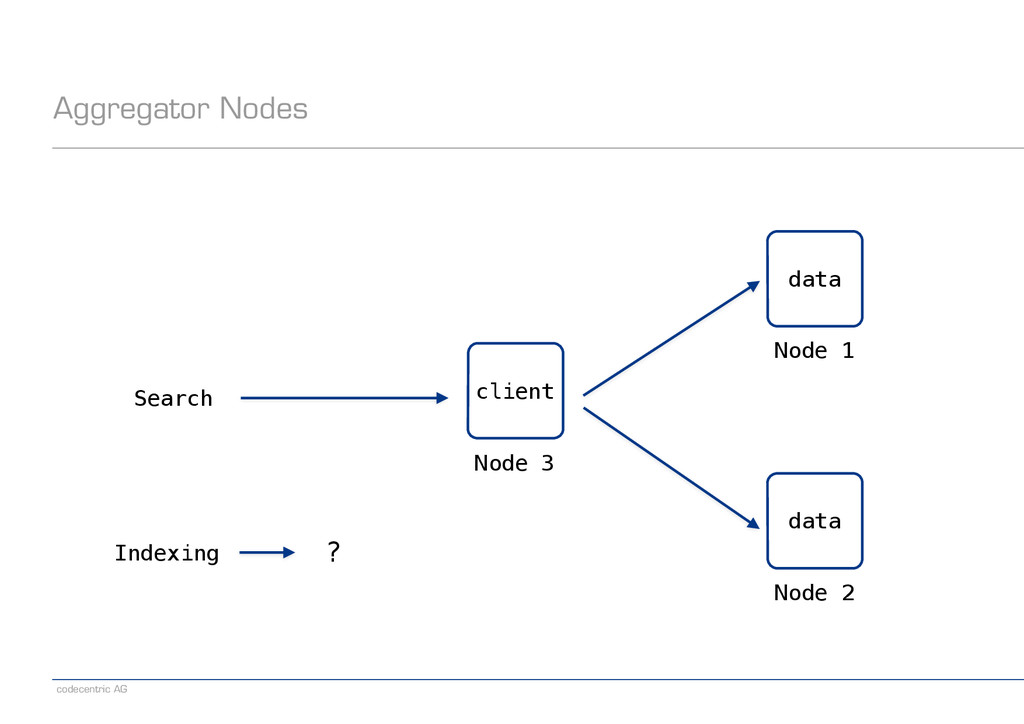
− If Java, choose the NodeClient − Joins the cluster and thus knows which node to address (potentially saves a hop) − Note: It is a client node and thus will participate in searches, too ! − If Java, and NodeClient is not an option, choose the TransportClient ! − HTTP − Use long-lived HTTP connections − Check HTTP chunking
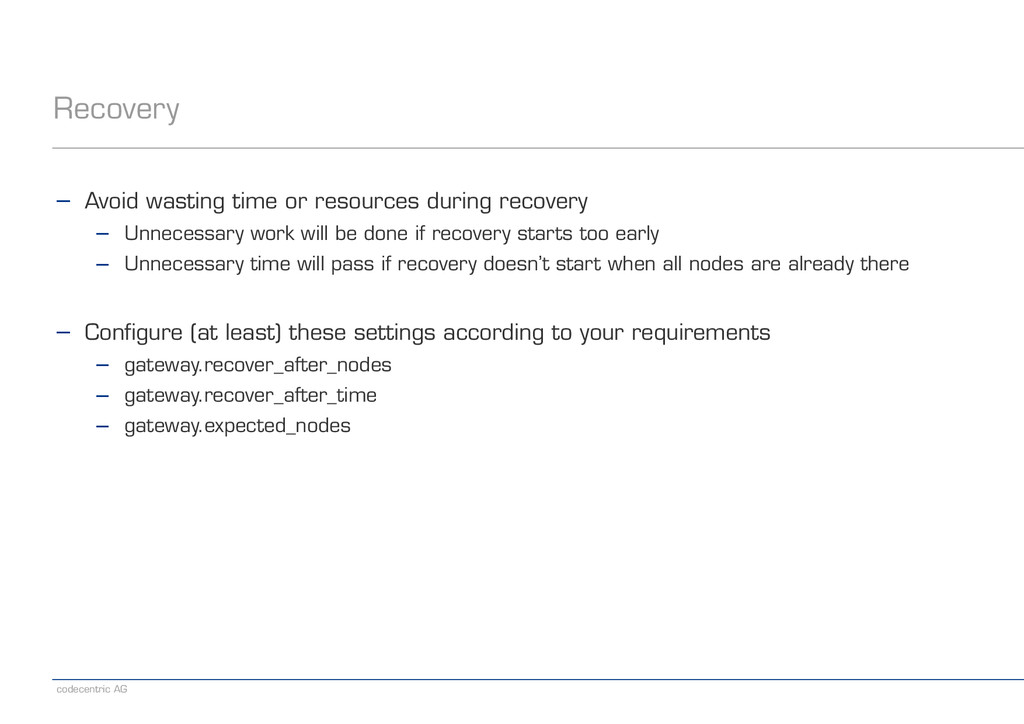
recovery − Unnecessary work will be done if recovery starts too early − Unnecessary time will pass if recovery doesn’t start when all nodes are already there ! − Configure (at least) these settings according to your requirements − gateway.recover_after_nodes − gateway.recover_after_time − gateway.expected_nodes
open file descriptors ! − Increase the maximum number of memory map areas ! − Avoid swapping ! − Details: http://www.elasticsearch.org/guide/en/elasticsearch/reference/current/setup-configuration.html
− Internally sets Xms = Xmx ! − Leave enough memory to the OS − Rule of thumb: Allocate (at most) half of the available memory to Elasticsearch − And: Not more than 32 GB (enables pointer compression) − Note: When using doc values for field data, a few GB might be more than enough ! − Use a concurrent garbage collector − Elasticsearch default is CMS − Try out G1 if you feel GC pressure ! − Make sure you run a supported Java version − Some may cause index corruption (e.g., Java 7 update 40)
you reliable reserve/isolate memory? − Possible conflicts with other services on the same physical node − Need to take good care even without virtualization ! − Storage − Use SSDs − Consider using RAID 0 for performance − Keep Elasticsearch data directories on local storage (beware NFS, etc.) ! − Memory − The more, the better ! − Prefer medium/large size machines over small ones
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}