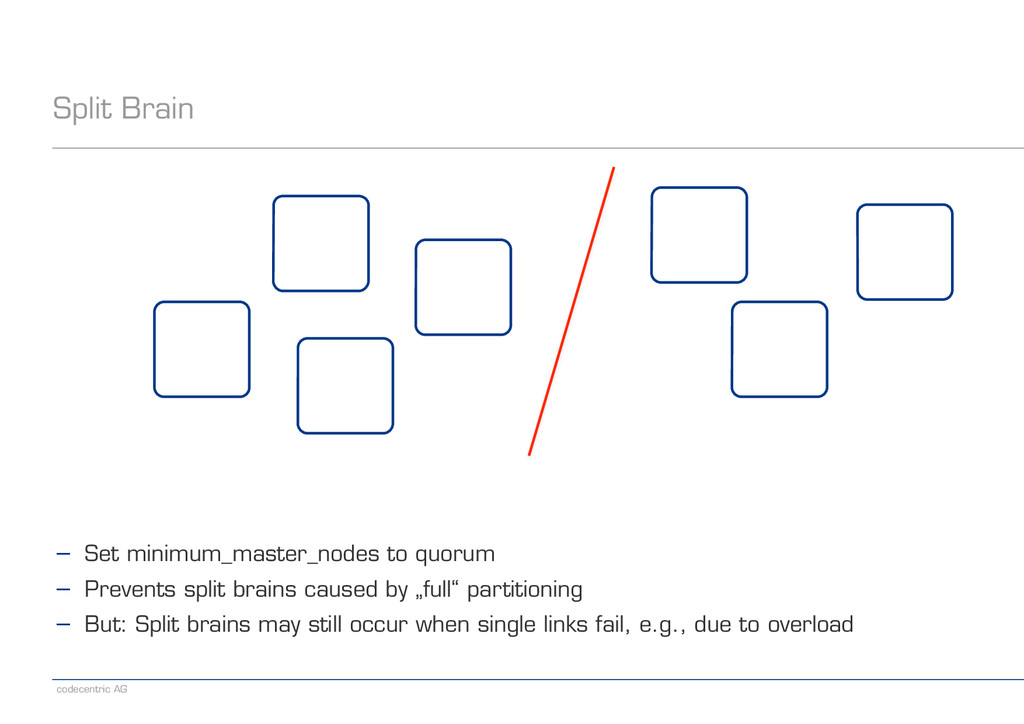
! ! ! ! − Set minimum_master_nodes to quorum − Prevents split brains caused by „full“ partitioning − But: Split brains may still occur when single links fail, e.g., due to overload
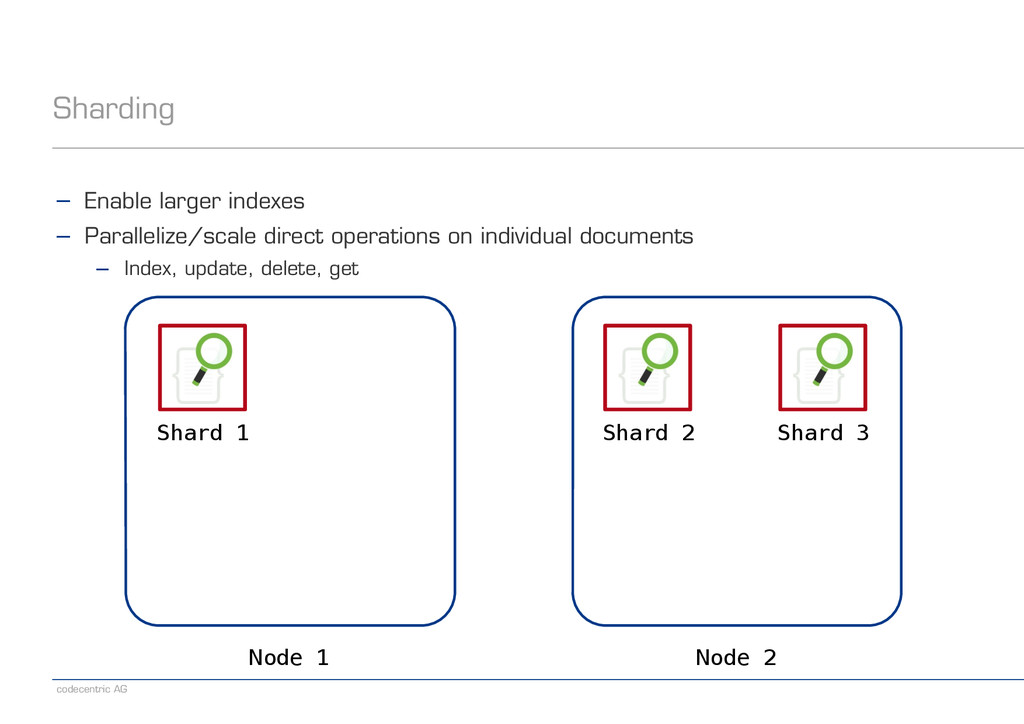
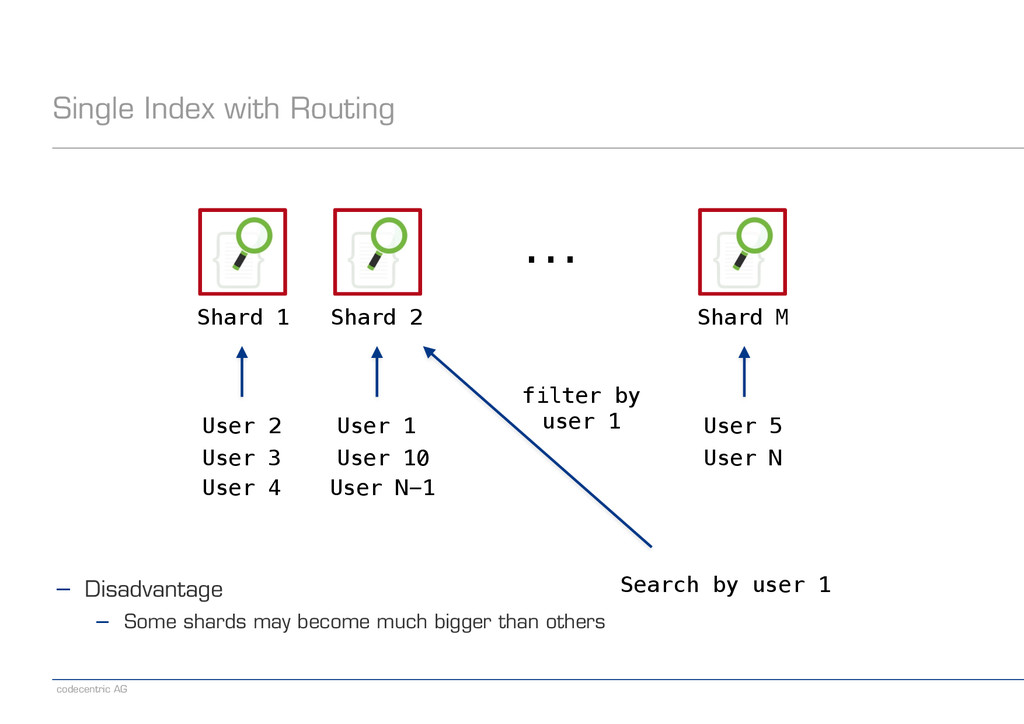
is used for shard key calculation ! − Can be overridden via explicit „routing“ ! − For example, select the shard depending on a user ID or some document field
search − Tends to make each individual search request (much) slower ! − A single search may involve several round trips to various nodes − 1. Gather global information for more accurate scoring − 2. Perform the actual search and compute scores − 3. Retrieve the final set of documents from the relevant shards − In between coordination/reduction by the node that initially received the request ! − The desired behavior may be specified on a per request basis („search type“) − By default, step 1 is omitted − Step 2 and 3 may be combined into one (but that’s risky with pagination)
to be chosen on index creation − No shard splitting later ! − General recommendation for determining the number of shards − Define metrics for a shard „capacity limit“ − Test the capacity limit of a single shard − Use realistic data and workloads − Depending on expected total amount of data, calculate the required number of shards − Overallocate a little
to be available to permit a write operation − all, quorum (default), one ! − „replication“ − Complete a write request already when the primary is done − Or only when all replicas have acknowledged the write (translog) − sync (default), async ! − „preference“ − On which shards to execute a search − round robin (default), local, primary, only some shards or nodes, arbitrary string − Helps to avoid inconsistent user experience when scoring differs between replicas − May happen because documents marked for deletion still affect scoring
or more Elasticsearch index(es) ! − Decouples client view from physical storage − Create views on an index, e.g., for different users − Search across multiple indexes ! − Enables changes without clients noticing − Point an alias to something new, e.g., switch to another index ! − Limitation: Writes are only permitted for aliases that point to a single index ! − Recommendation: Use aliases right from the start
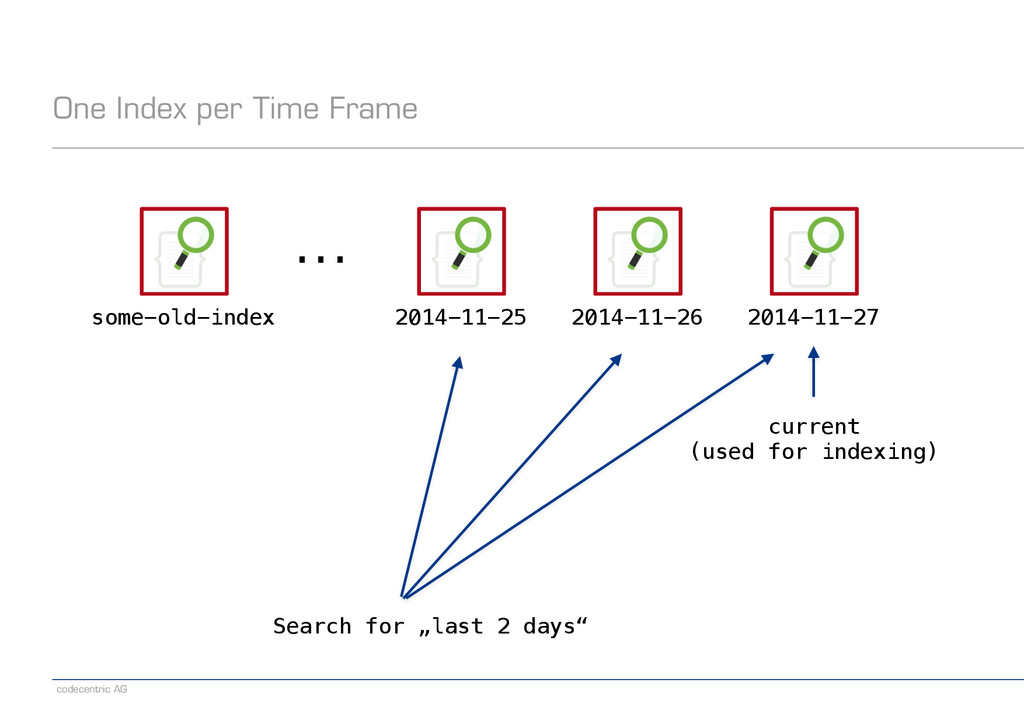
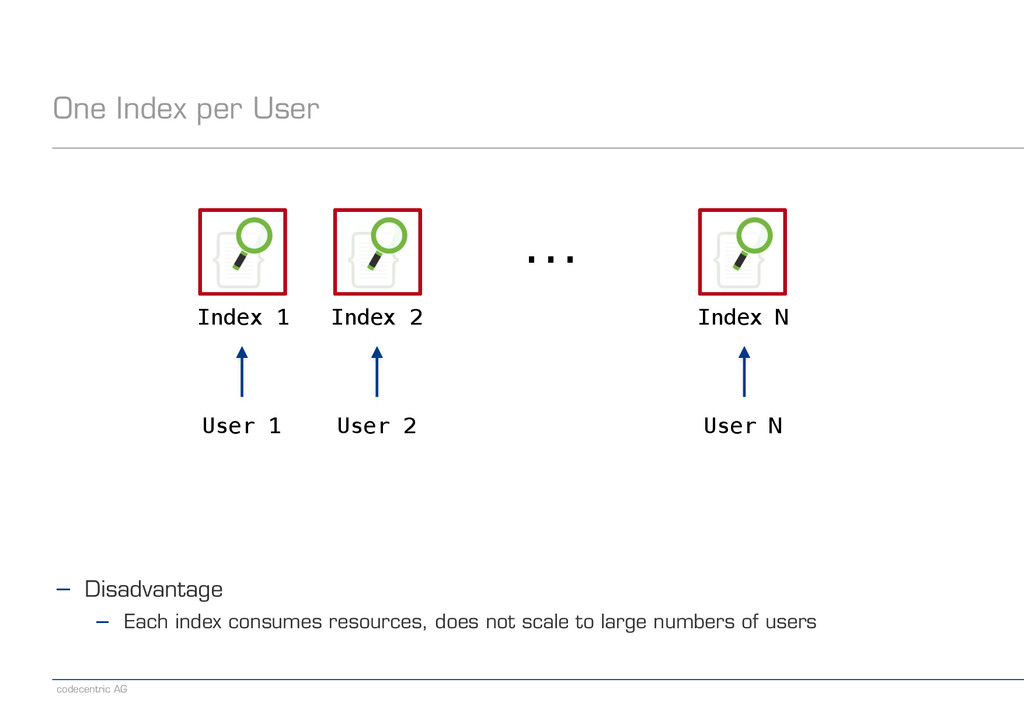
about scaling right from the start? − Fixed number of shards per index − Each new index involves some basic costs − Distributed searches are expensive ! − Consider possible patterns in your data − Time-based data − User-based data − Or maybe none at all ! − Recommended reading − http://www.elasticsearch.org/guide/en/elasticsearch/guide/current/scale.html
to index templates and aliases ! − The cost of error is small − Frequent index creation facilitates quick improvements ! − But more complicated when updates/deletes of individual documents are needed
Shard 1 Shard 2 Shard M ... User 2 User 1 User 5 User 3 User 4 User 10 User N User N-1 Search by user 1 ! ! ! ! ! ! ! ! ! ! ! − Disadvantage − Some shards may become much bigger than others
the approach chosen − Aliases can be associated with filter and routing information − In all cases, the client may address separate „user“ indexes (aliases) ! − It is possible to combine the approaches behind scenes − For example, start with „single index with routing“ − Depending on the need, migrate big users to dedicated indexes ! − Regardless of the approach chosen, we may always hit capacity limits − An index or a shard (and thus, with it, the index) may become too large − Then we basically have to deal with a „one big index“ scenario
an index has reached its capacity? − Let’s say we even overallocated a bit, but growth is larger than expected ! − Option 1: Extend the index by a second one ! − Option 2: Migrate to a new index with more shards ! − Note: Searching multiple indexes is the same as searching a sharded index − 1 index with 50 shards =~ 50 indexes with 1 shard each − In both cases, 50 Lucene indexes are searched
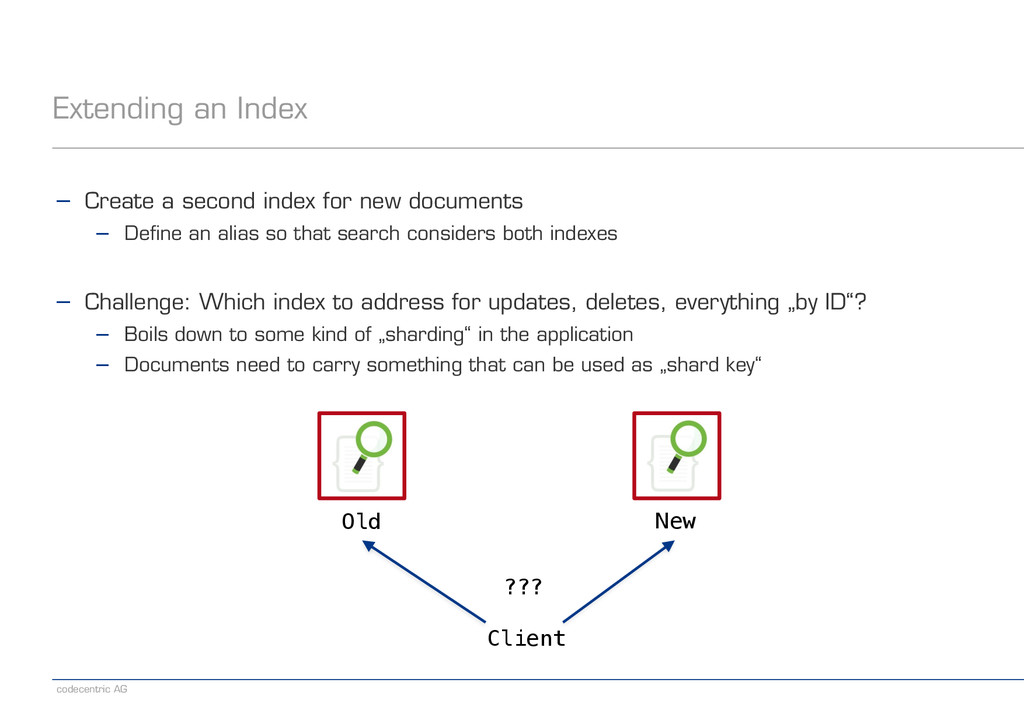
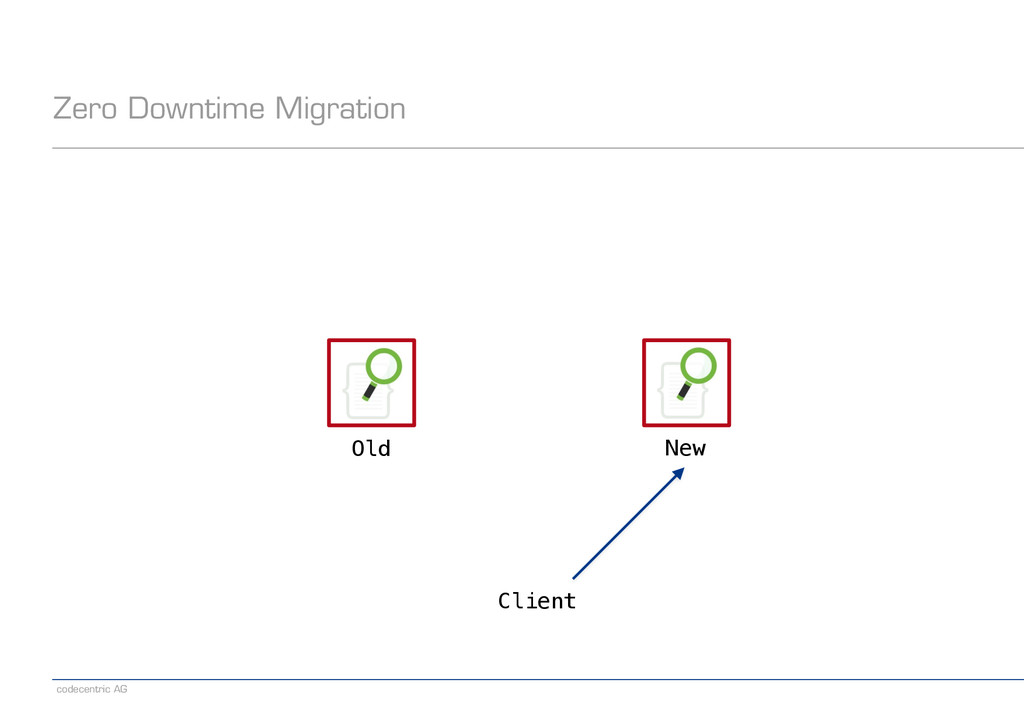
for new documents − Define an alias so that search considers both indexes ! − Challenge: Which index to address for updates, deletes, everything „by ID“? − Boils down to some kind of „sharding“ in the application − Documents need to carry something that can be used as „shard key“ Old New Client ???
DB for mapping documents to indexes − For example, everything beyond a certain „creation date“ is directed to the new index − Need to add client-side logic for mapping dates to index name − Alternatively, store the index name directly in the main DB − Only applicable if there actually is a main DB ! − Encode the index name into the document ID − For example, UUID followed by index name − Does not require a main DB − Need to add logic during document ID generation − Clients need to know how to extract the index name from the document ID ! − A bit fragile overall, as it depends on non-search parts of the application
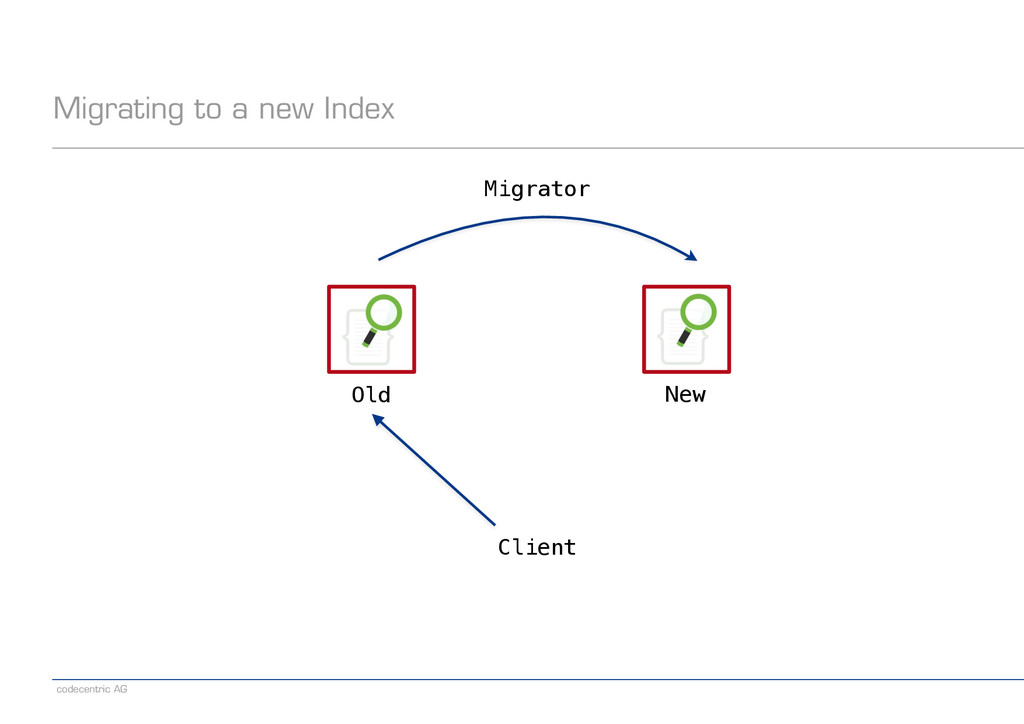
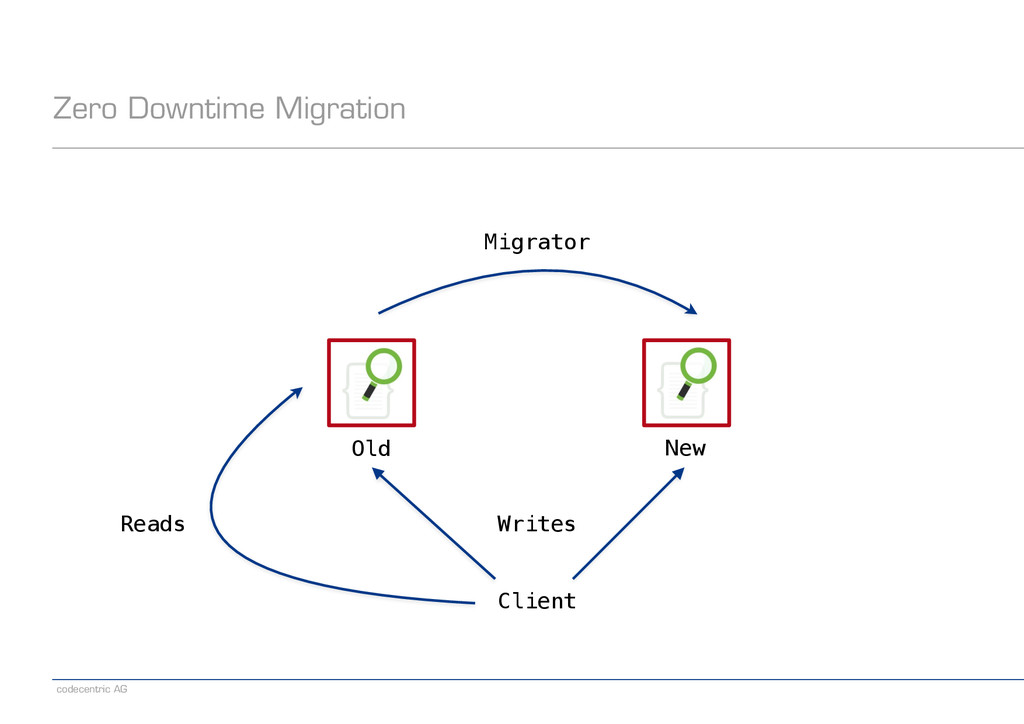
old index and writes to the new index ! − Read via scan+scroll API − Iterate in batches over a snapshot of the data ! − Write via bulk API − Send batches of documents in single requests − Bulk size needs to be determined empirically ! − Notes − Requires _source, but that’s really a best practice anyway − Consider having the migrator read and write in parallel − Consider (partially) disabling replication during migration
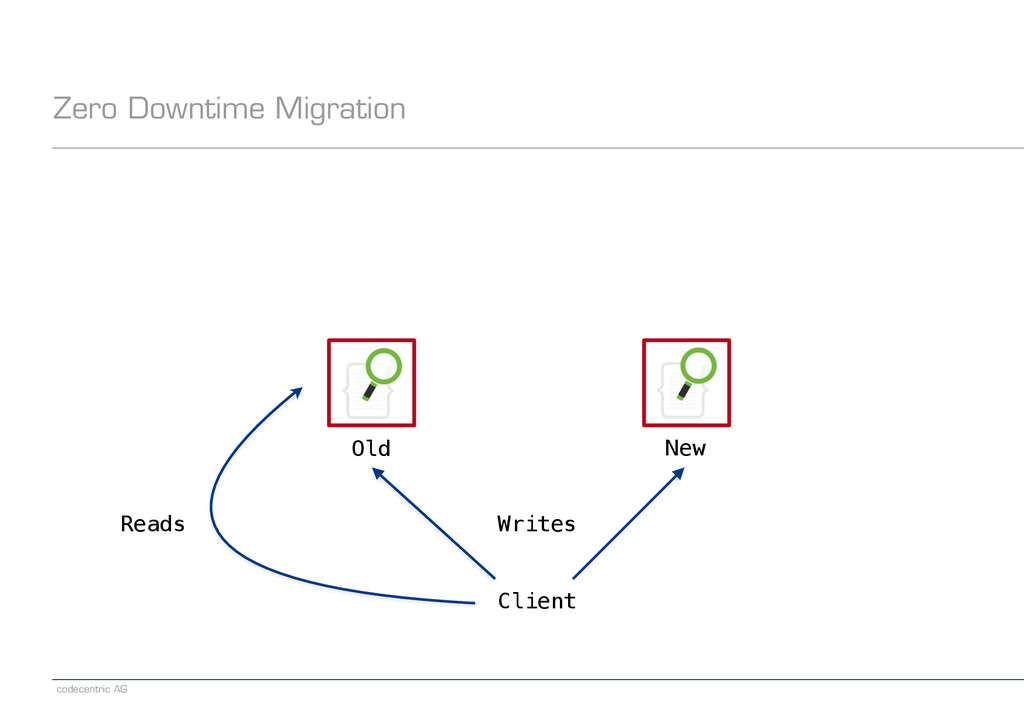
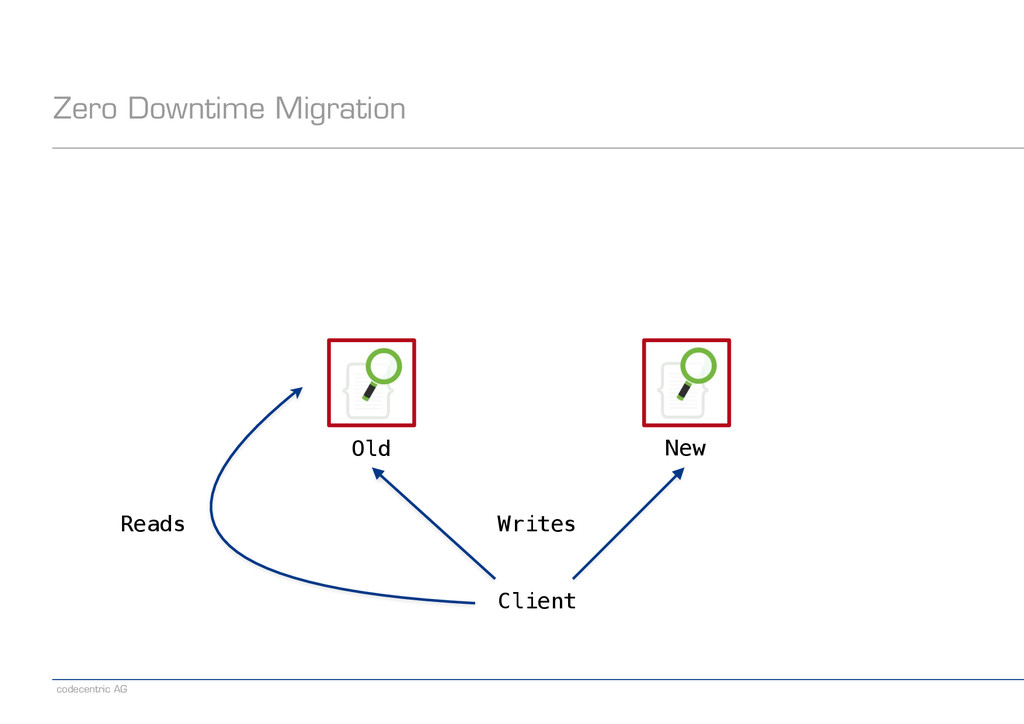
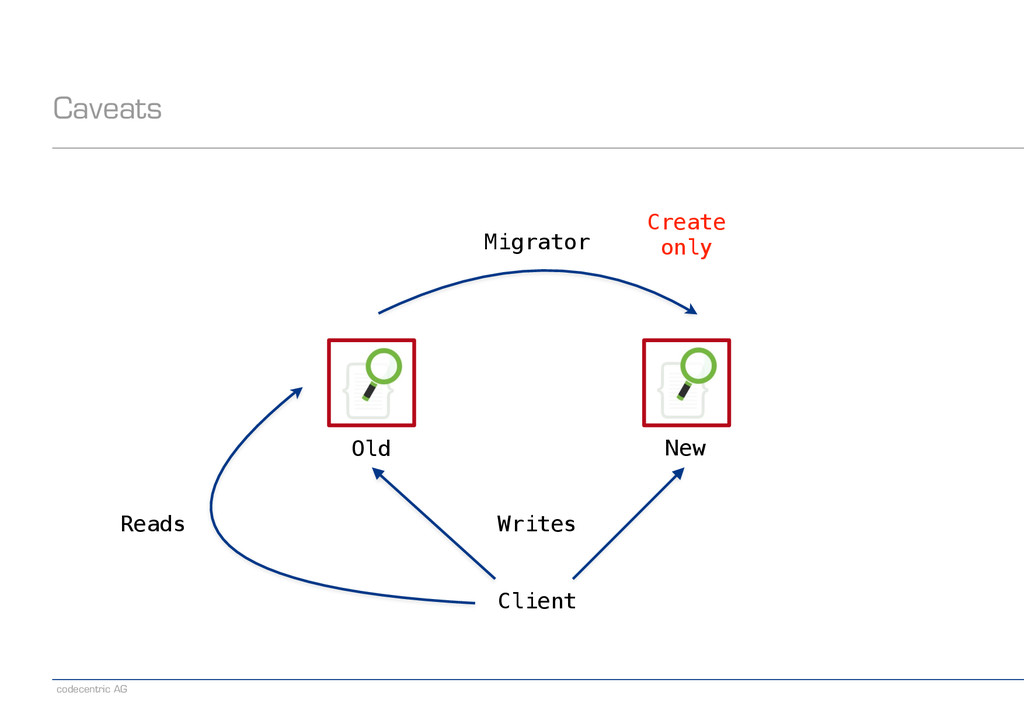
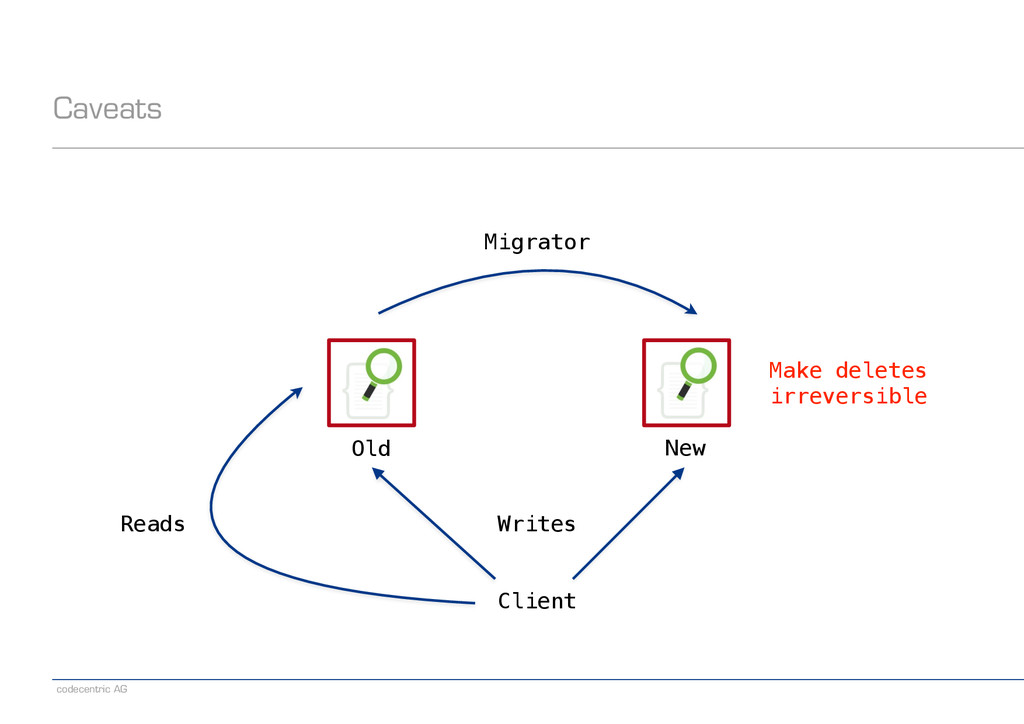
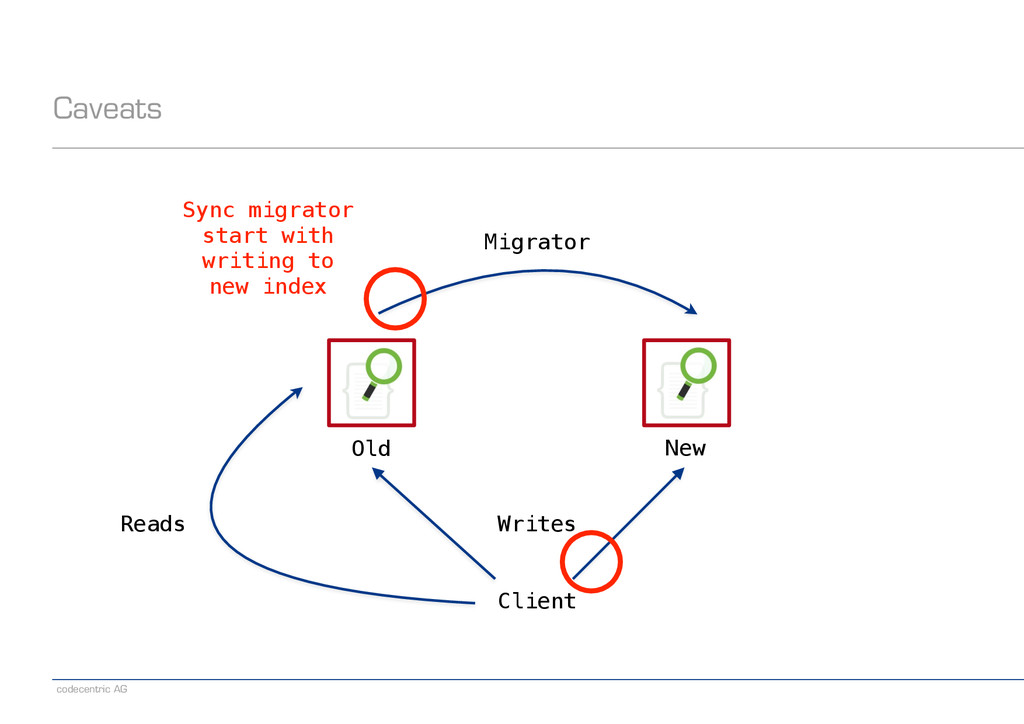
an alias pointing to the old index − Create a new index − Set index.gc_deletes to a large enough value (makes deletes irreversible) − Direct writes to both indexes − Wait until all old-index-only writes have been refreshed (check via search) − Run the migrator using optype=create (prevents lost updates) − When the migrator is done, stop indexing into the old index − Switch the read alias to the new index − Delete the old index ! − Note: Having a global „indexing queue“ eases the implementation of some steps − Single point where we need to make changes or monitor things
more complex when the application uses the Update API − Updates to the new index require an existing document ! − Possible solutions − Buffer writes to the new index, only run them when the migrator is done − But need to prevent duplicate updates − For example, by explicit versioning or a synced start of buffering and migrator − Another idea is to turn each update into a full re-indexing during migration − Start using the Update API again only after done with migration ! − Once again, having an „indexing queue“ is highly beneficial ! − Recipes for different scenarios will be detailed in the codecentric blog :-)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}