in the whole document set and invert with the logarithm d1(I play a fun game) -> v1(i, play, a, fun, game) d2(I am a nice little text) -> v2(i, am, a, nice, little, text) -> v2(1*log(2/2), 1*log(2/1), 1*log(2/2), …) -> v2(0, 0.3, 0, 0.3, 0.3, 0.3)
and 2-grams): (nice, little, text) -> (nice, nice_little, little, little_text, text) -> From three tokens we just generated 5 tokens. example2 (1 and 2-grams): (new, york, is, a, nice, city) -> (new, new_york, york, york_is, is, is_a, a, a_nice, nice, nice_city, city)
form, the classification gets done with a classical statistical machine learning model (e.g. multinominal-naive-bayes, stochastic-gradient-descent- classifier, logistic-regression and random-forest)
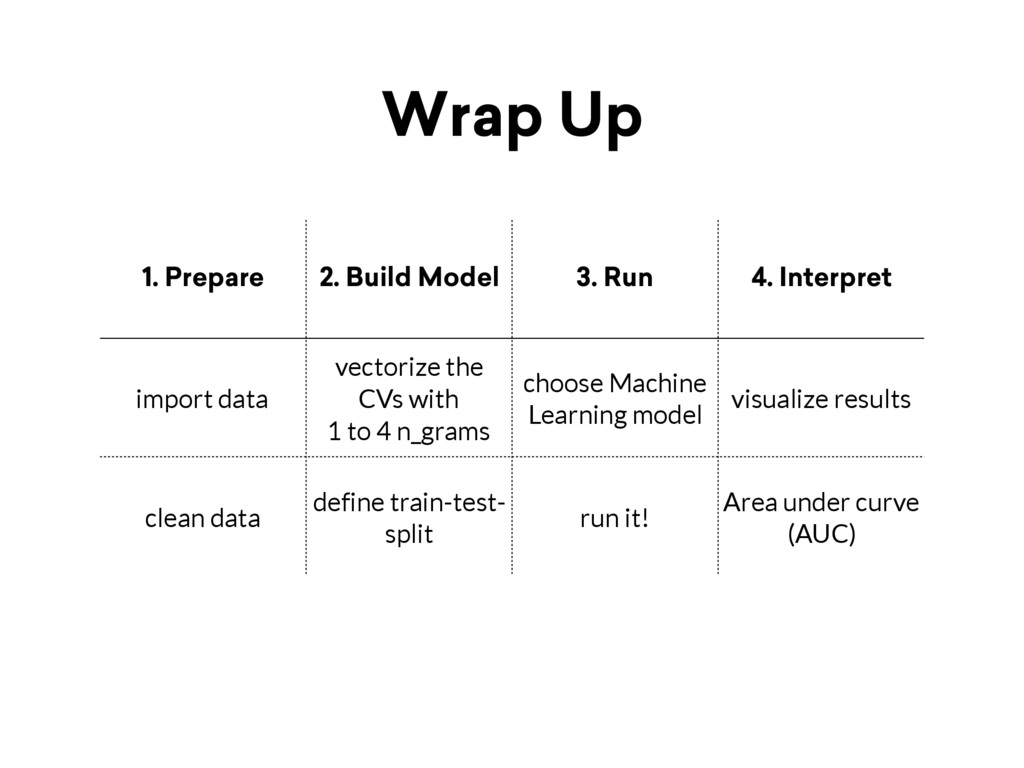
Interpret import data vectorize the CVs with 1 to 4 n_grams choose Machine Learning model visualize results clean data define train-test- split run it! Area under curve (AUC)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}