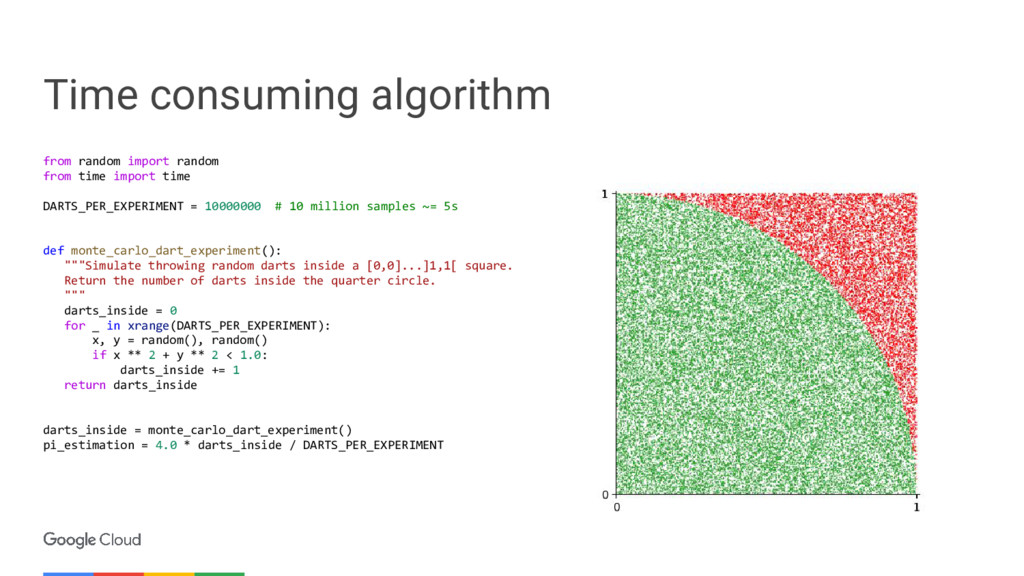
Ever had a batch job taking days to complete? By distributing an algorithm over 1,000 cores, a 1 week computation can be completed in 10 minutes only. Moreover, storing/processing the results can be complex and time consuming. This demo shows how this can be seamless, real-time and serverless.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}