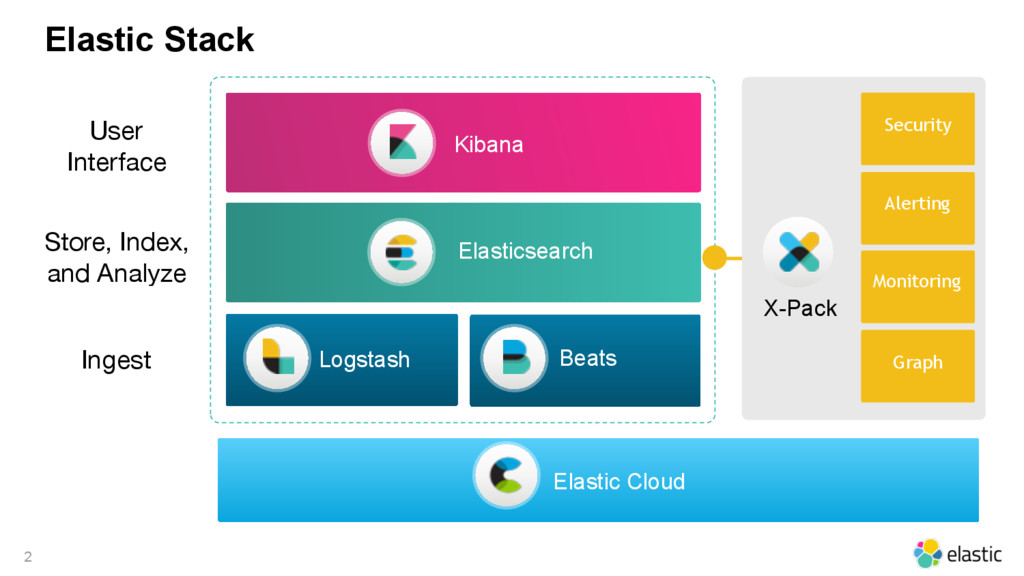
• Elasticsearch: pipeline aggregation, sampler aggregation, query profiler, query DSL update and optimization, doc_values x field_data, ingest node
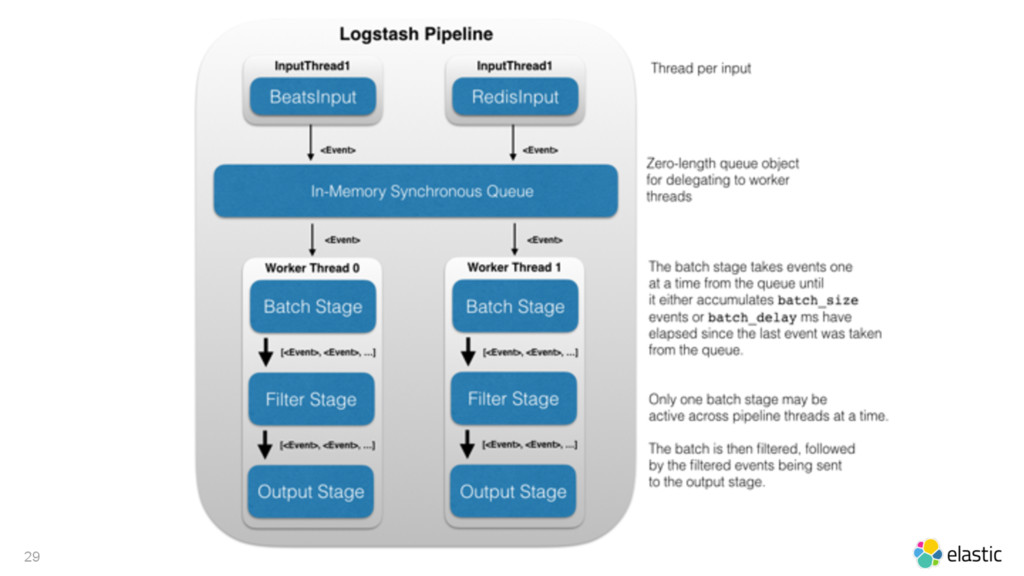
• Logstash: next generation pipeline
• Kibana: dark theme, plugins --- marvel (agent/ui), sense, timelion
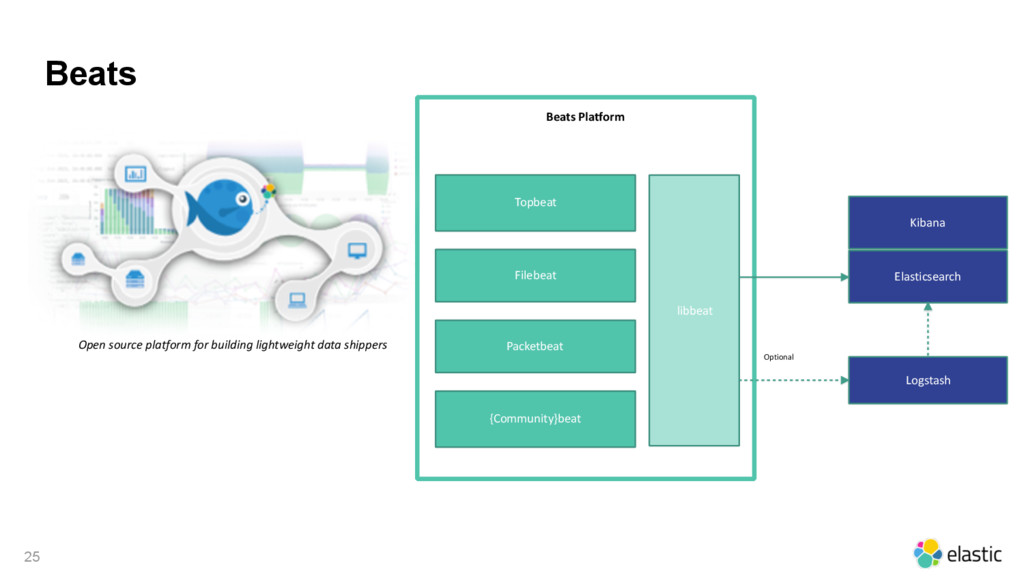
• Beats: lightweight shipper, {Top/File/Packet/Community}beat
• Elastic Cloud: easy updates, back up every 30 minutes, AWS integration
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
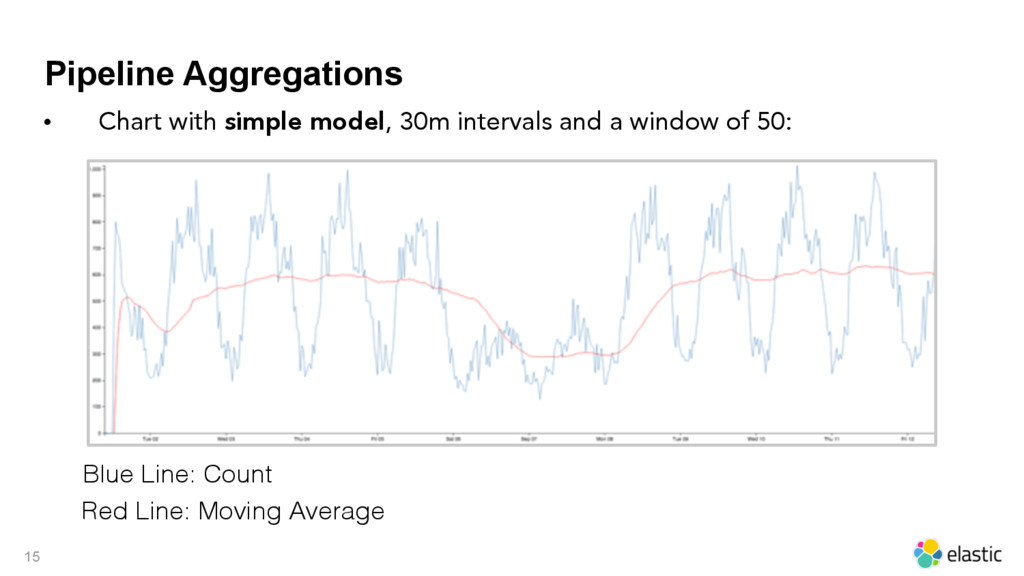
{kind=link}
{kind=link}
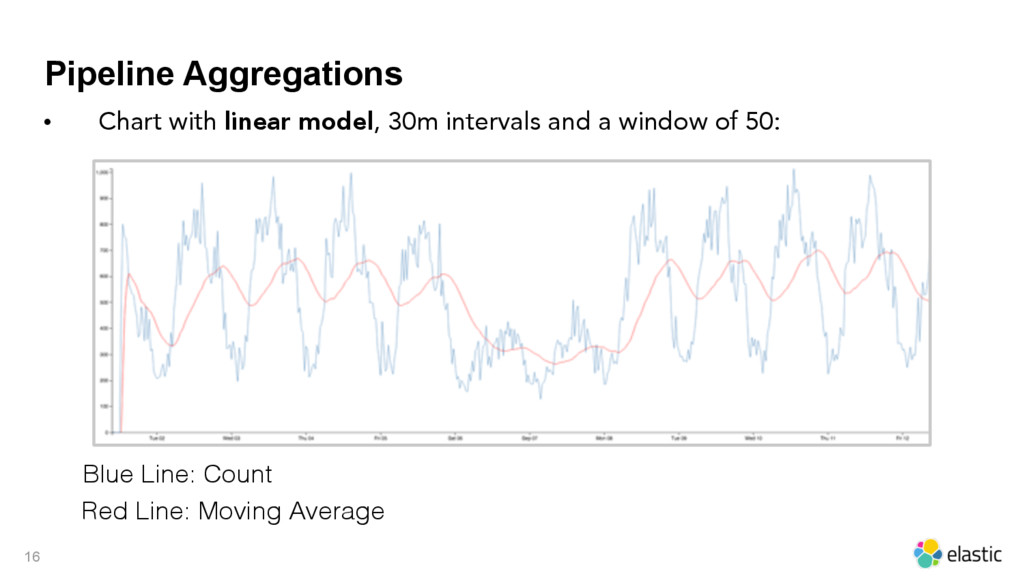
{kind=link}
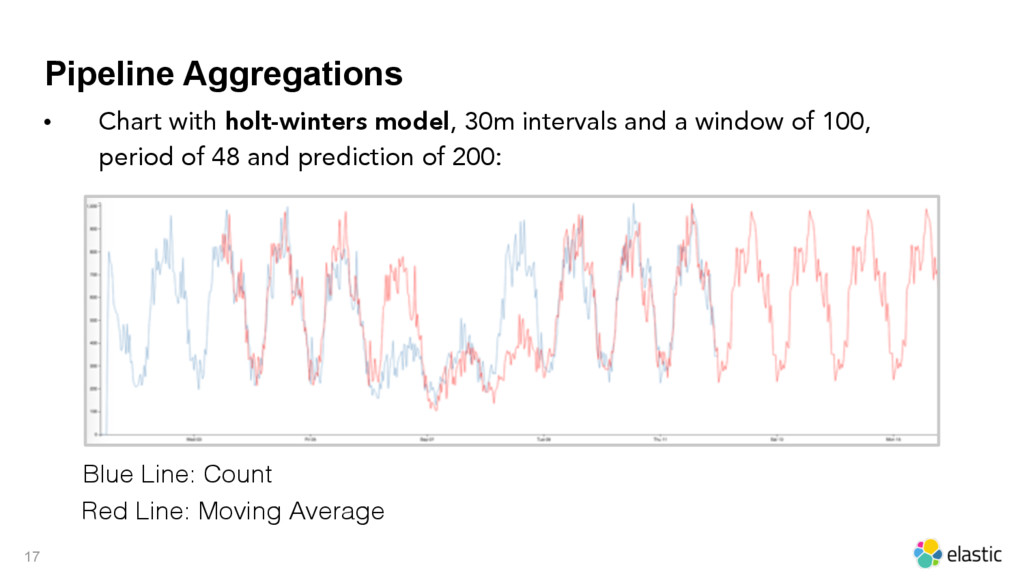
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}