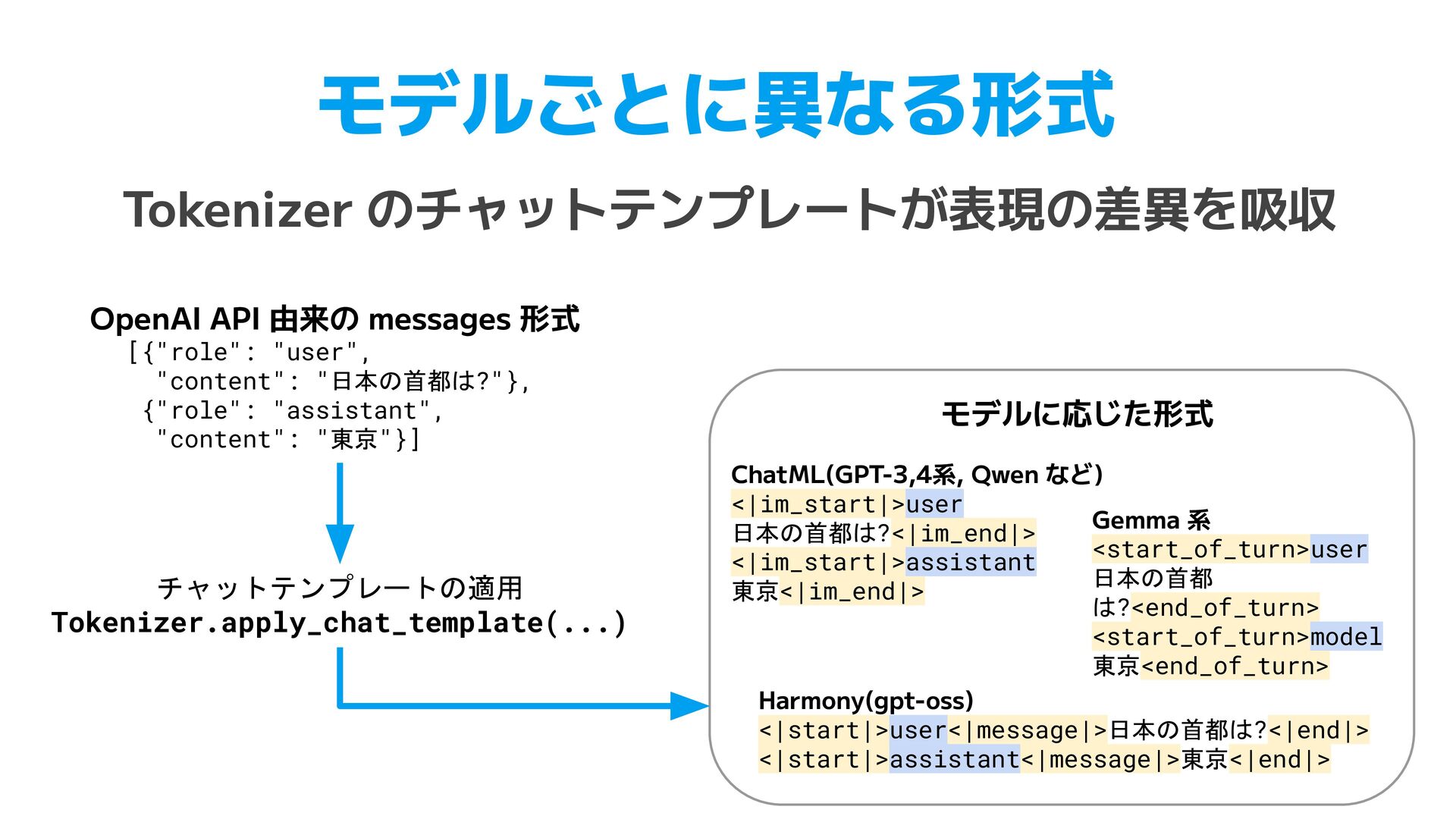
TOML. Use [table] for nested objects and [[array]] for arrays. Do not use inline tables. • XML (47行) ◦ JSON 入力時の root 要素の決定 ◦ パス構造の一致ルール, データ型(ISO 8601, UUID)の保持 • YAML (83行) ◦ XML, CSV, JSON からの個別の変換ルール ▪ XML 繰り返し要素のタグ省略、CSV列名のドットはネスト ◦ 学習データの一部が例として指示に含まれることも見られた
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}