# AIで速く作れるのに なぜ遅くなるのか?
パフォーマンス改善のリードタイム問題とその解決
クラウドネイティブ会議 / 株式会社フライル
---
# 自己紹介
**吉澤 直哉** — 株式会社フライル / Software Engineer
- アプリケーションエンジニア → パフォーマンス改善エンジニア
- 釣りが好き🎣
- Twitter(現X): [@azihsoyn](https://x.com/azihsoyn)
- GitHub: [@azihsoyn](https://github.com/azihsoyn)
---
FLYLE, INC.
埋もれる VoC、5% しか聞けない品質評価、終わらない後処理
コンタクトセンターの
対話データ から AI 変革
VOC 分析・応対品質改善・ACW 削減・リスク検知まで改善する コンタクトセンター・CX の AI 変革パートナー
多様な業界の大手企業のコンタクトセンター・CX 部門で導入
---
高い業務負荷 を AI エージェントが代替
コンタクトセンター・CX の複雑な定型業務を AI が肩代わり、多様なユースケースに対応
VOC 分析
数十万件の声を構造化し、根本原因とアクションを自動抽出
CX・顧客体験改善
体験課題を多角的に可視化し、改善ポイントを特定
応対品質改善
全通話をスコアリングし、網羅的に品質を評価
ACW 削減
通話後の要約・入力を AI が自動化し、生産性を回復
リスク検知
クレーム・コンプラ違反の兆候を自動検出
大量データ × マルチテナント × リアルタイム性が同時に求められる SaaS
---
USE CASE — VOC 分析
数十万の VOC データから、課題・レポートを生成
数十万件の声を AI がリアルタイムで構造化。表層分類では見えない根本原因を特定し、各部門の目的に沿ったレポーティングを自動化。
月 100 万件
対応可能 複雑な形式 高精度で分析 原因深掘り 精度高く分類
「届かない」の裏にある根本原因を抽出、頻度 × 顧客離反リスクで優先順位化し、経営・他部門に直接届く
---
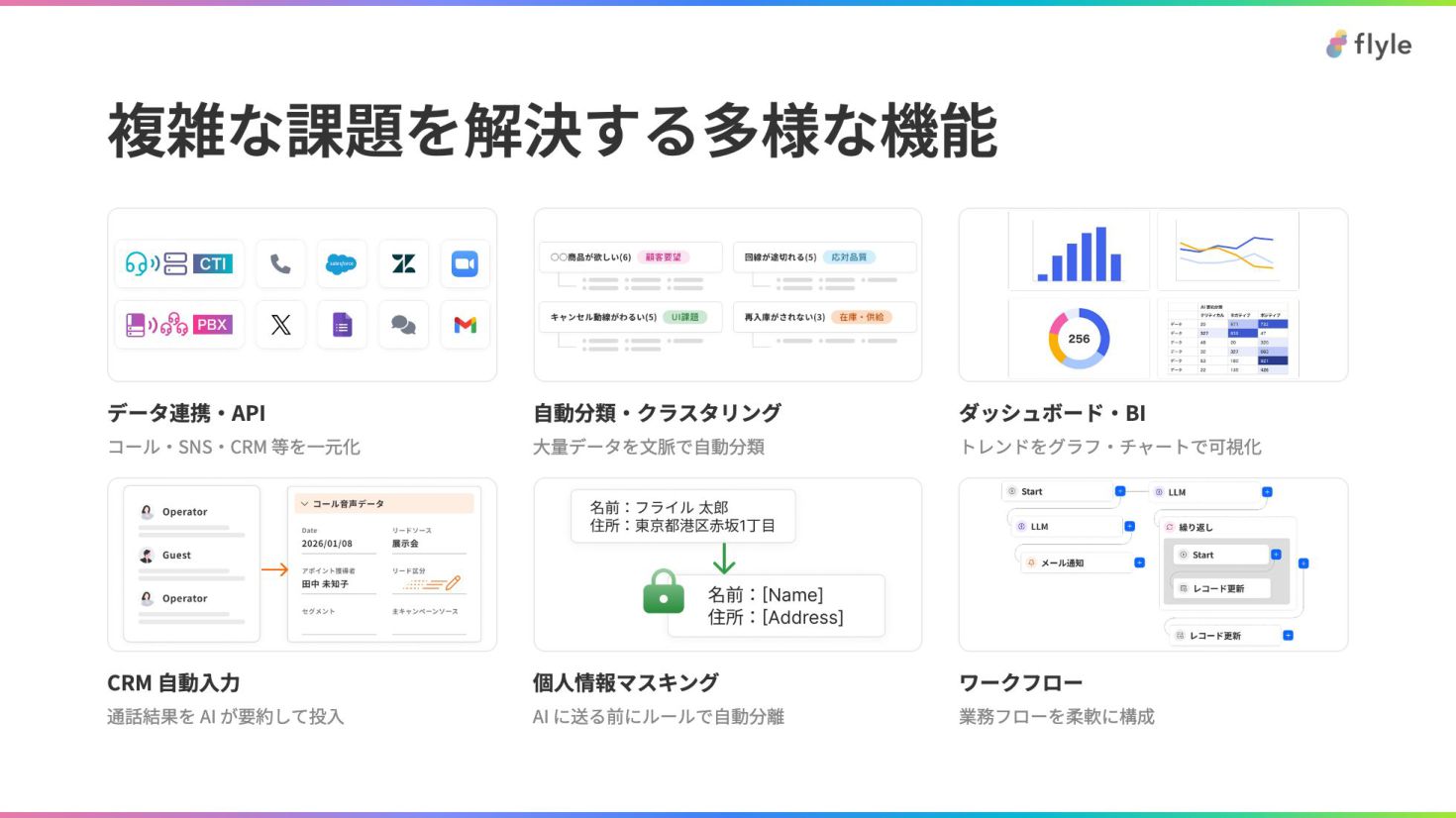
複雑な課題を解決する多様な機能
データ連携・API
コール・SNS・CRM 等を一元化
自動分類・クラスタリング
大量データを文脈で自動分類
ダッシュボード・BI
トレンドをグラフ・チャートで可視化
CRM 自動入力
通話結果を AI が要約して投入
個人情報マスキング
AI に送る前にルールで自動分離
ワークフロー
業務フローを柔軟に構成
---
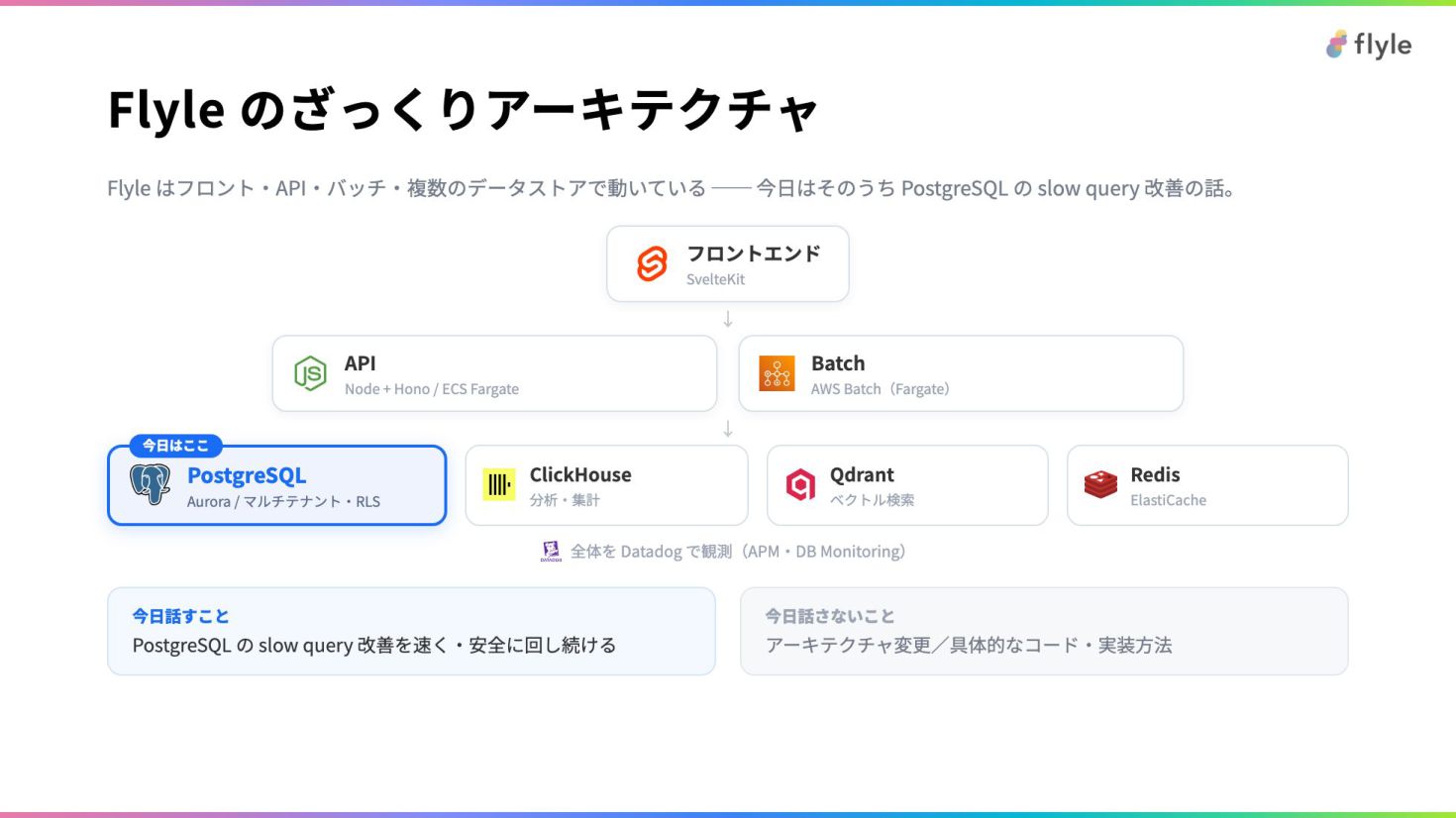
# Flyle のざっくりアーキテクチャ
Flyle はフロント・API・バッチ・複数のデータストアで動いている ── 今日はそのうち PostgreSQL の slow query 改善の話。
フロントエンド
SvelteKit
↓ API
Node + Hono / ECS Fargate
Batch
AWS Batch(Fargate)
↓ 今日はここ
PostgreSQL
Aurora / マルチテナント・RLS
ClickHouse
分析・集計 Qdrant ベクトル検索 Redis
ElastiCache
全体を Datadog で観測(APM・DB Monitoring)
今日話すこと
PostgreSQL の slow query 改善を速く・安全に回し続ける
今日話さないこと
アーキテクチャ変更/具体的なコード・実装方法
---
# AIを使い倒して開発している
- Claude Code / Cursor / Codex / Devin / CodeRabbit などの AI ツール
- 仕様検討の壁打ちから実装まで AI が伴走
- 1人のエンジニアの **開発スループットが数倍** に
> **日常風景**
>
> 「設計を相談 → コード生成 → レビュー → マージ」が **1日で複数回** 回る
---
# エンジニア以外もPRを出す
### 仕組み
- セールス・PdM・デザイナーが
AI を使って自分で PR を作る
- レビューはエンジニアが担当
- **作る人を増やす** 取り組み
### 結果
- 機能リクエストの **自走率** が上がる
- 開発の **スループット** がさらに加速
- ※現在は仕組みを再設計中で停止中
---
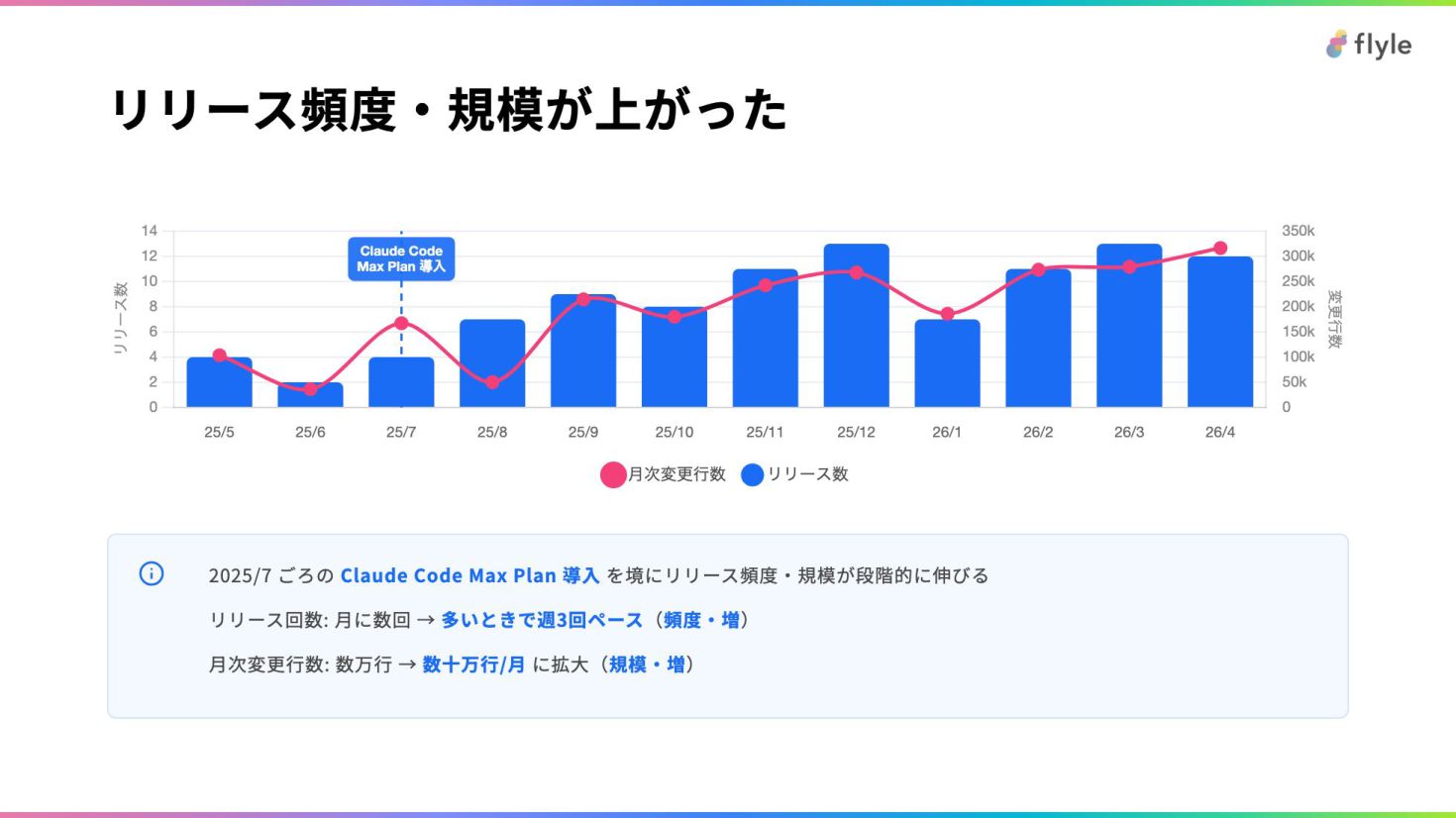
# リリース頻度・規模が上がった
> - 2025/7 ごろの **Claude Code Max Plan 導入** を境にリリース頻度・規模が段階的に伸びる
> - リリース回数: 月に数回 → **多いときで週3回ペース**(**頻度・増**)
> - 月次変更行数: 数万行 → **数十万行/月** に拡大(**規模・増**)
---
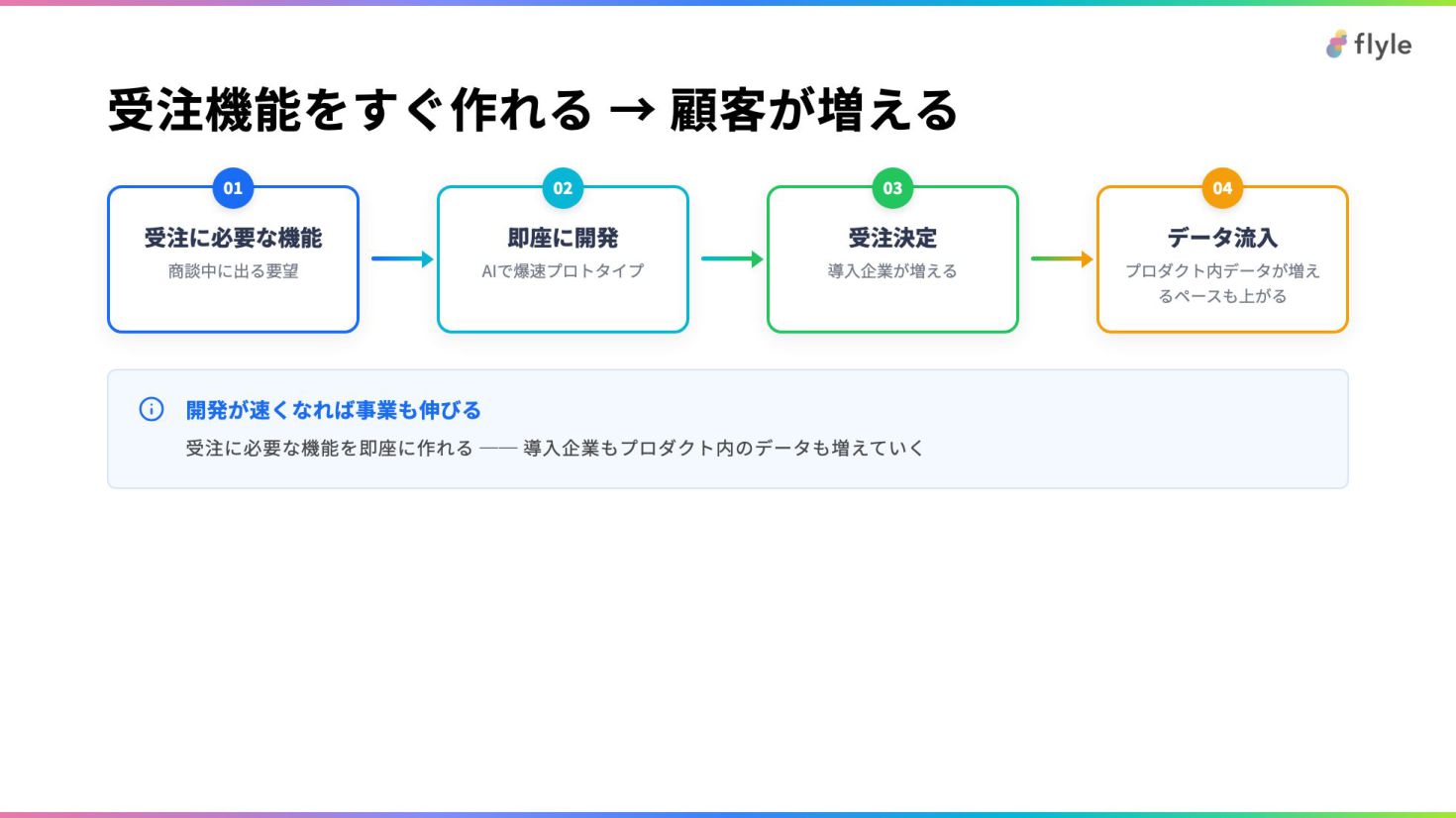
# 受注機能をすぐ作れる → 顧客が増える
- 01 — 受注に必要な機能 — 商談中に出る要望
- 02 — 即座に開発 — AIで爆速プロトタイプ
- 03 — 受注決定 — 導入企業が増える
- 04 — データ流入 — プロダクト内データが増えるペースも上がる
> **開発が速くなれば事業も伸びる**
>
> 受注に必要な機能を即座に作れる ── 導入企業もプロダクト内のデータも増えていく
---
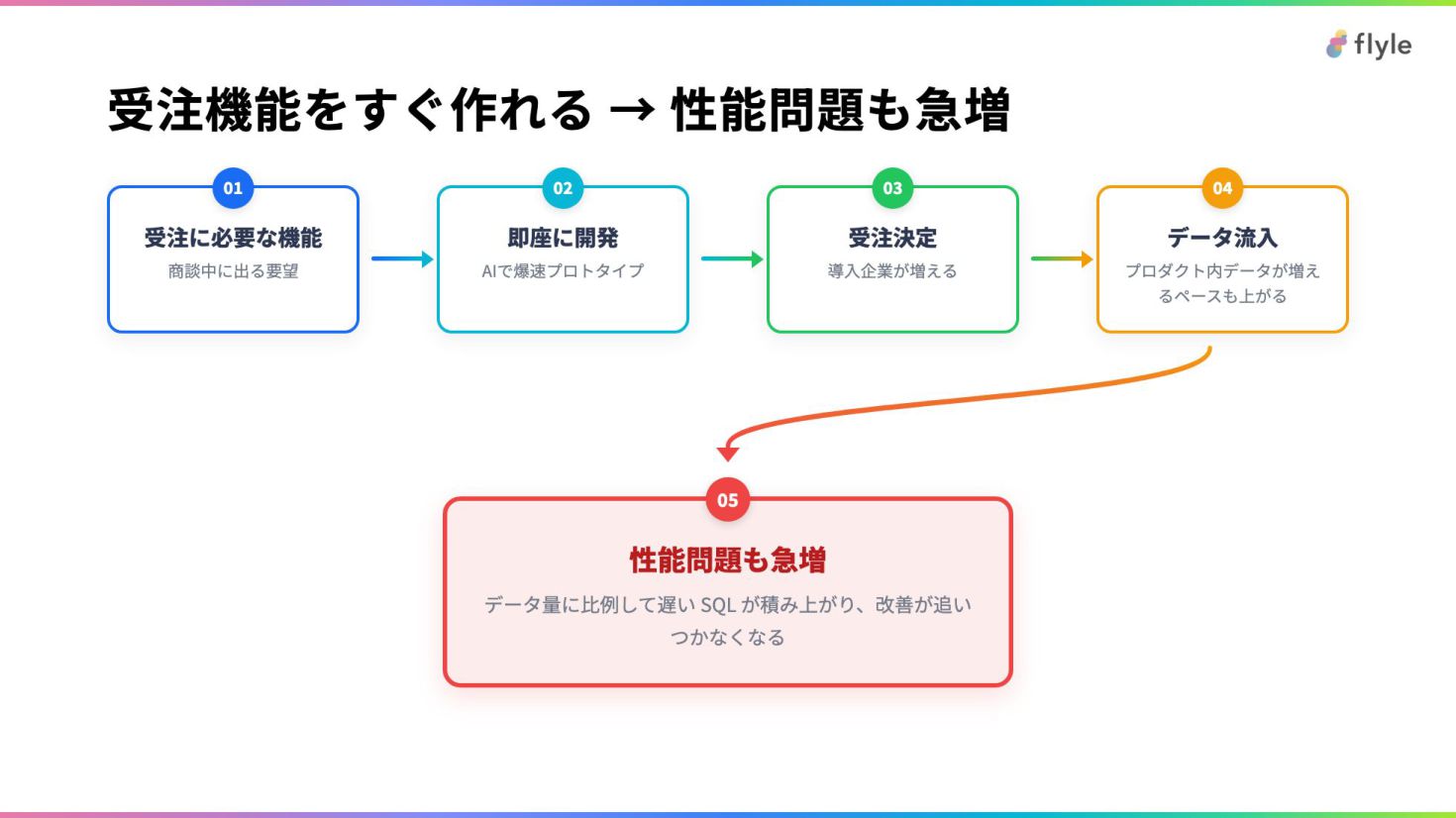
# 受注機能をすぐ作れる → 性能問題も急増
- 01 — 受注に必要な機能 — 商談中に出る要望
- 02 — 即座に開発 — AIで爆速プロトタイプ
- 03 — 受注決定 — 導入企業が増える
- 04 — データ流入 — プロダクト内データが増えるペースも上がる
05
性能問題も急増
データ量に比例して遅い SQL が積み上がり、改善が追いつかなくなる
---
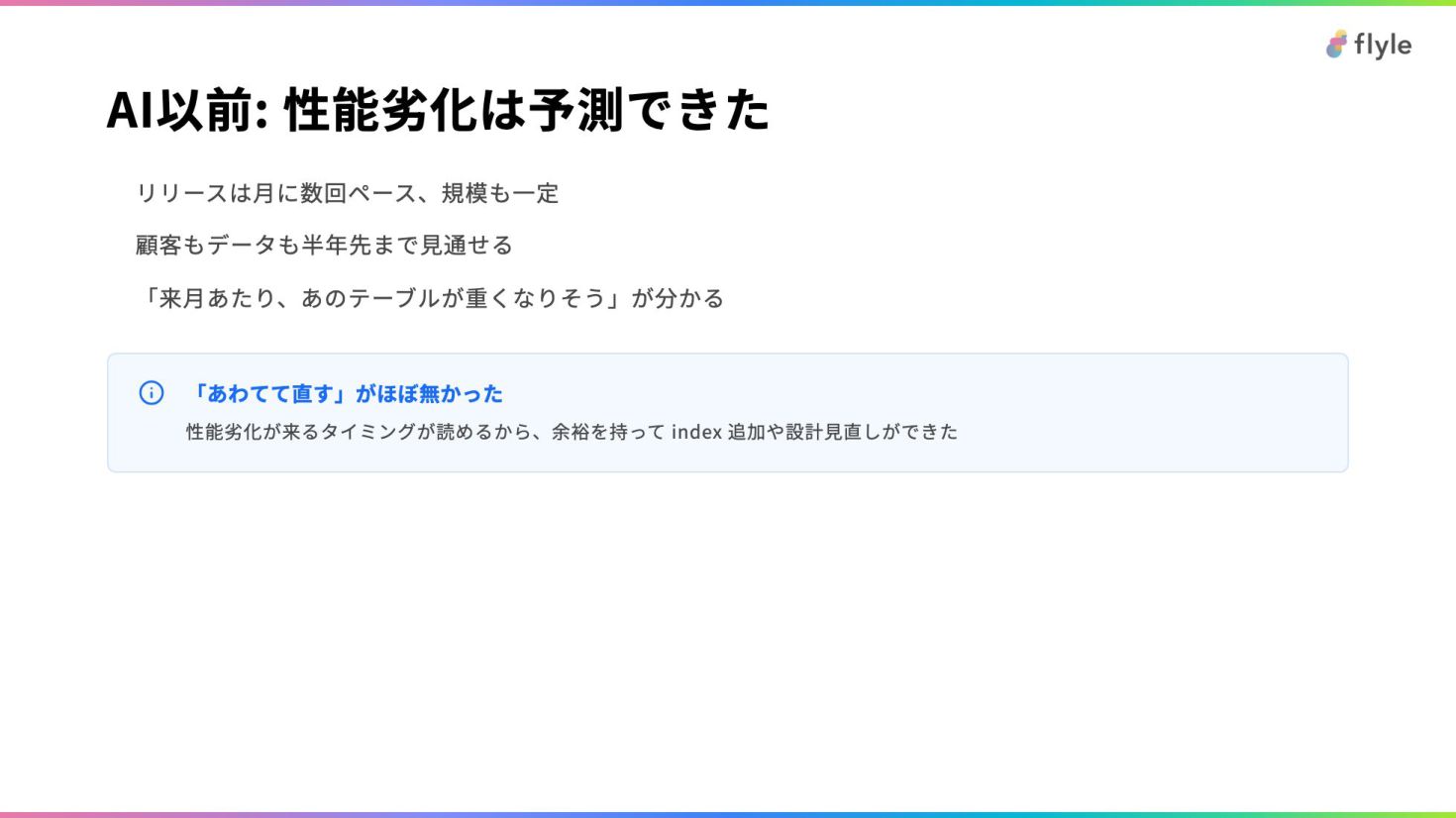
# AI以前: 性能劣化は予測できた
- リリースは月に数回ペース、規模も一定
- 顧客もデータも半年先まで見通せる
- 「来月あたり、あのテーブルが重くなりそう」が分かる
> **「あわてて直す」がほぼ無かった**
>
> 性能劣化が来るタイミングが読めるから、余裕を持って index 追加や設計見直しができた
---
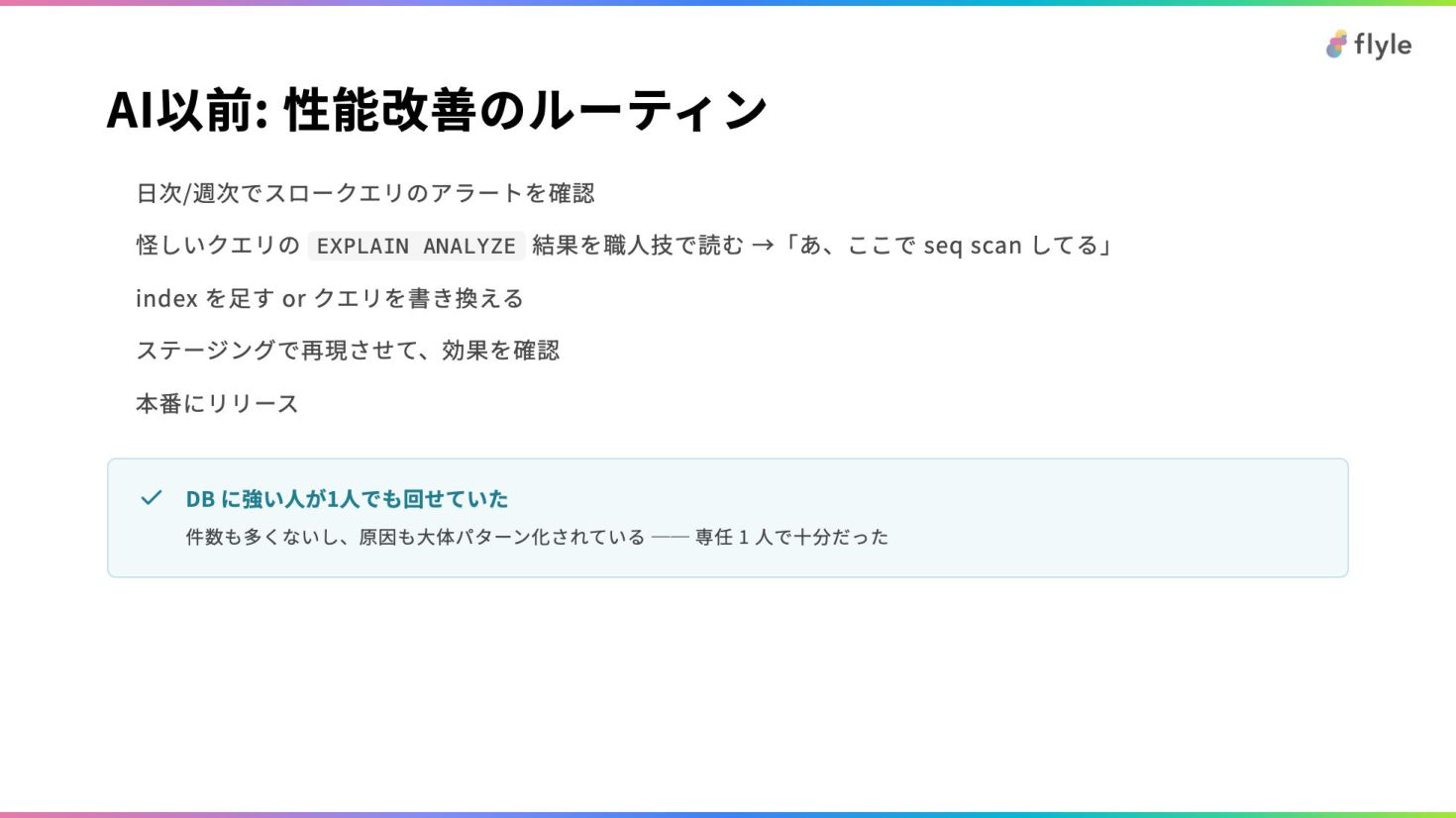
# AI以前: 性能改善のルーティン
- 日次/週次でスロークエリのアラートを確認
- 怪しいクエリの `EXPLAIN ANALYZE` 結果を職人技で読む →「あ、ここで seq scan してる」
- index を足す or クエリを書き換える
- ステージングで再現させて、効果を確認
- 本番にリリース
> **DB に強い人が1人でも回せていた**
>
> 件数も多くないし、原因も大体パターン化されている ── 専任 1 人で十分だった
---
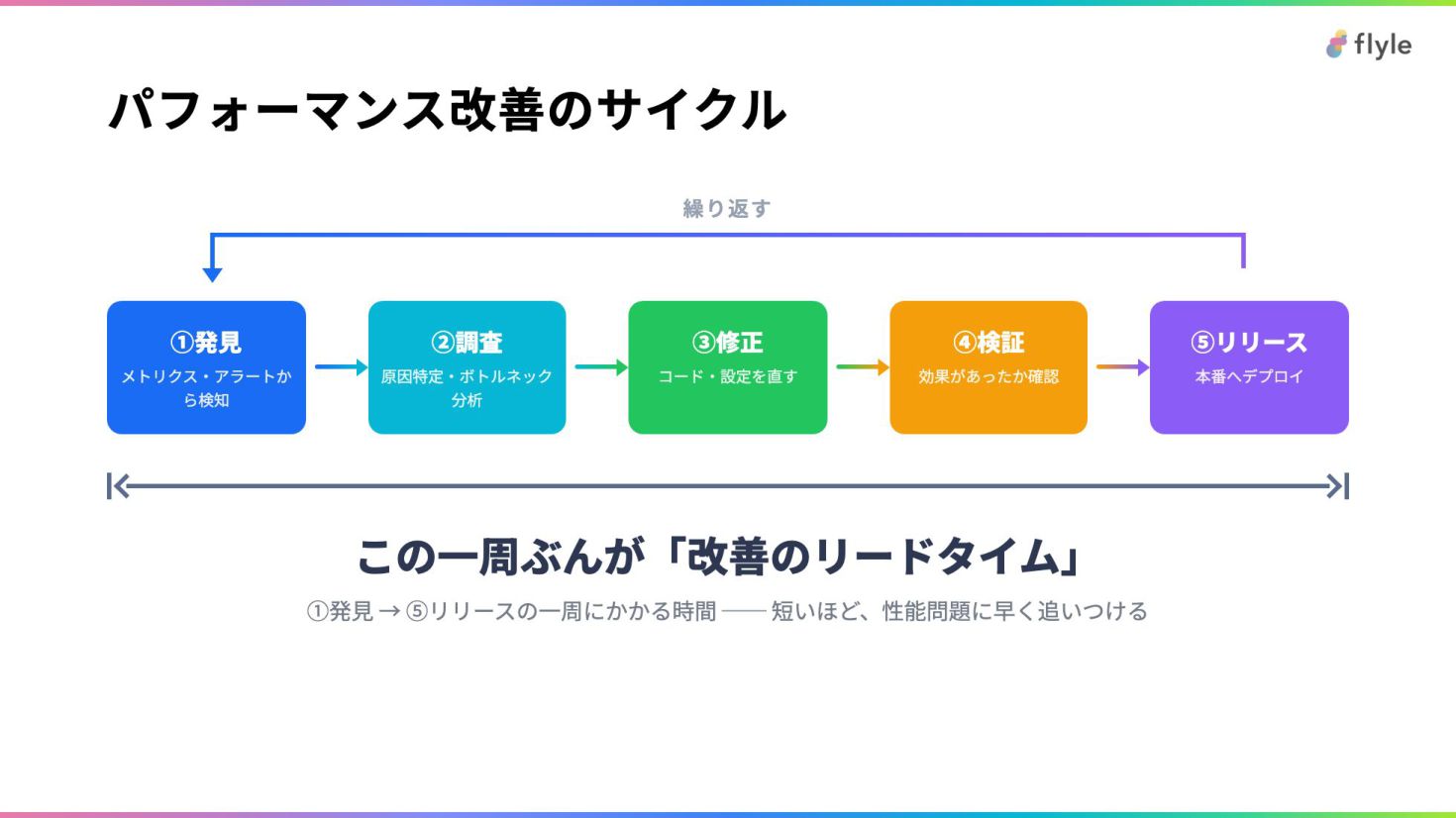
# パフォーマンス改善のサイクル
繰り返す ①発見
メトリクス・アラートから検知
②調査
原因特定・ボトルネック分析
③修正
コード・設定を直す
④検証
効果があったか確認
⑤リリース
本番へデプロイ
この一周ぶんが「改善のリードタイム」
①発見 → ⑤リリースの一周にかかる時間 ── 短いほど、性能問題に早く追いつける
---
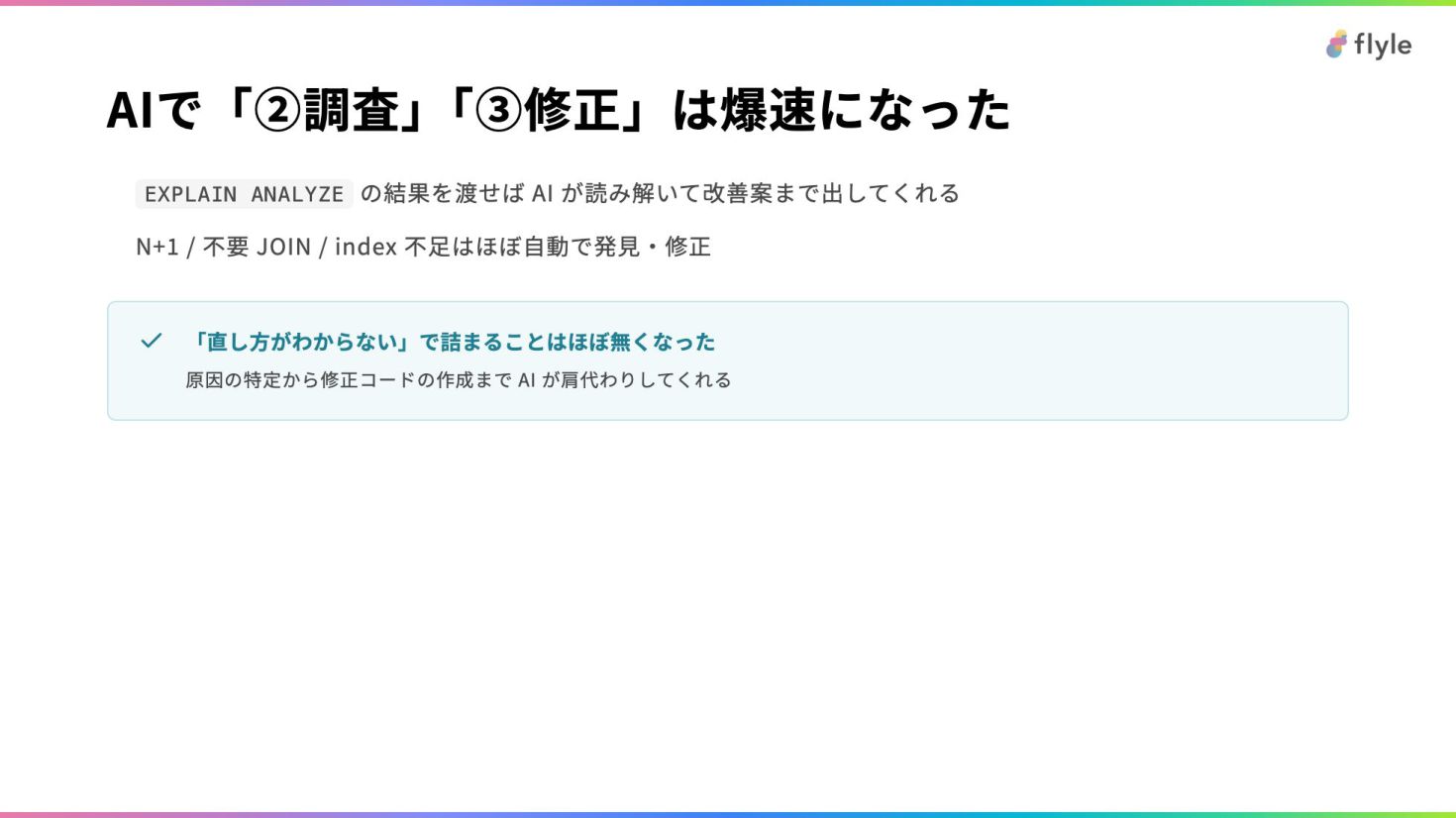
# AIで「②調査」「③修正」は爆速になった
- `EXPLAIN ANALYZE` の結果を渡せば AI が読み解いて改善案まで出してくれる
- N+1 / 不要 JOIN / index 不足はほぼ自動で発見・修正
> **「直し方がわからない」で詰まることはほぼ無くなった**
>
> 原因の特定から修正コードの作成まで AI が肩代わりしてくれる
---
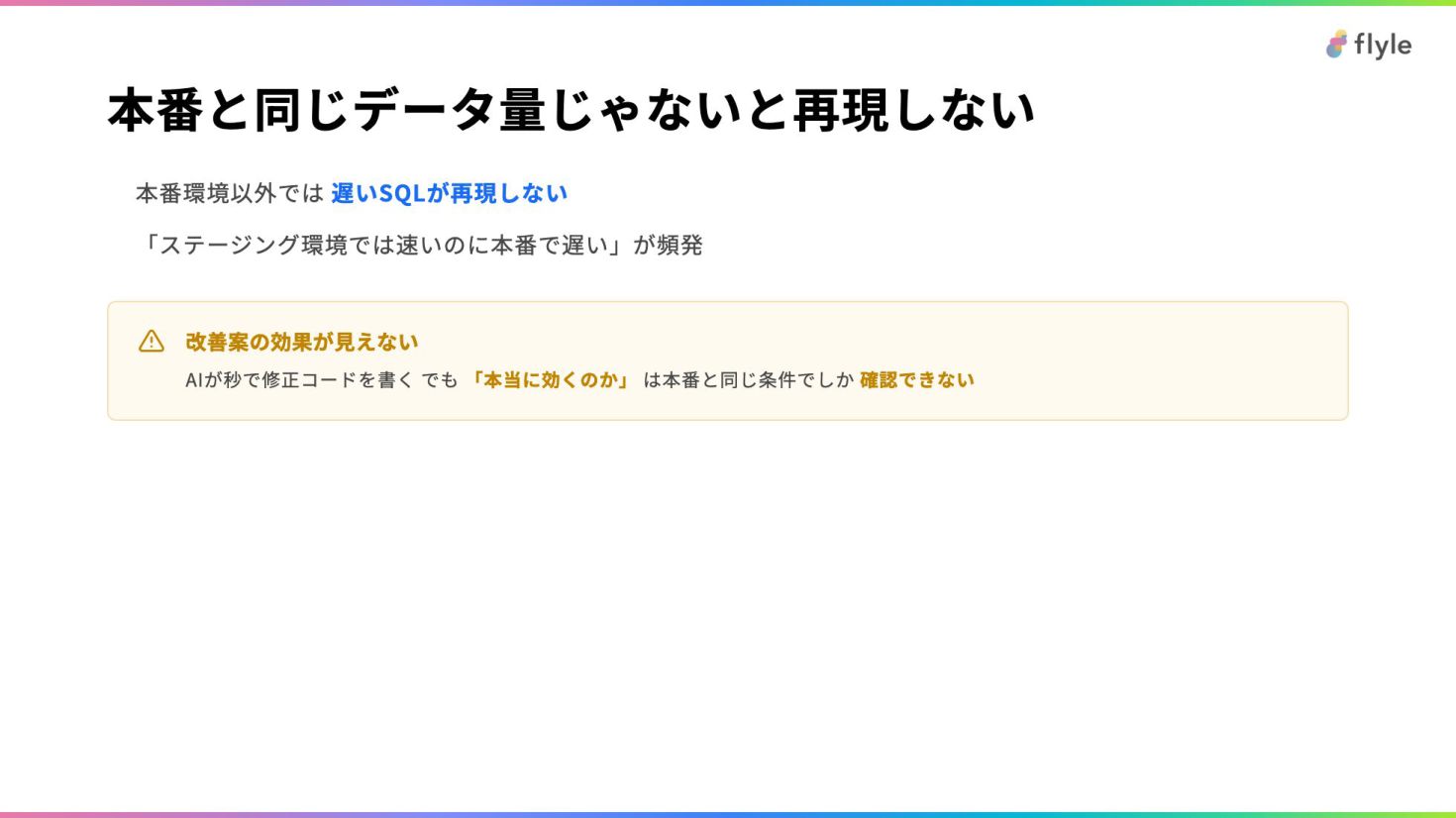
# 本番と同じデータ量じゃないと再現しない
- 本番環境以外では **遅いSQLが再現しない**
- 「ステージング環境では速いのに本番で遅い」が頻発
> **改善案の効果が見えない**
>
> AIが秒で修正コードを書く
> でも **「本当に効くのか」** は本番と同じ条件でしか **確認できない**
---
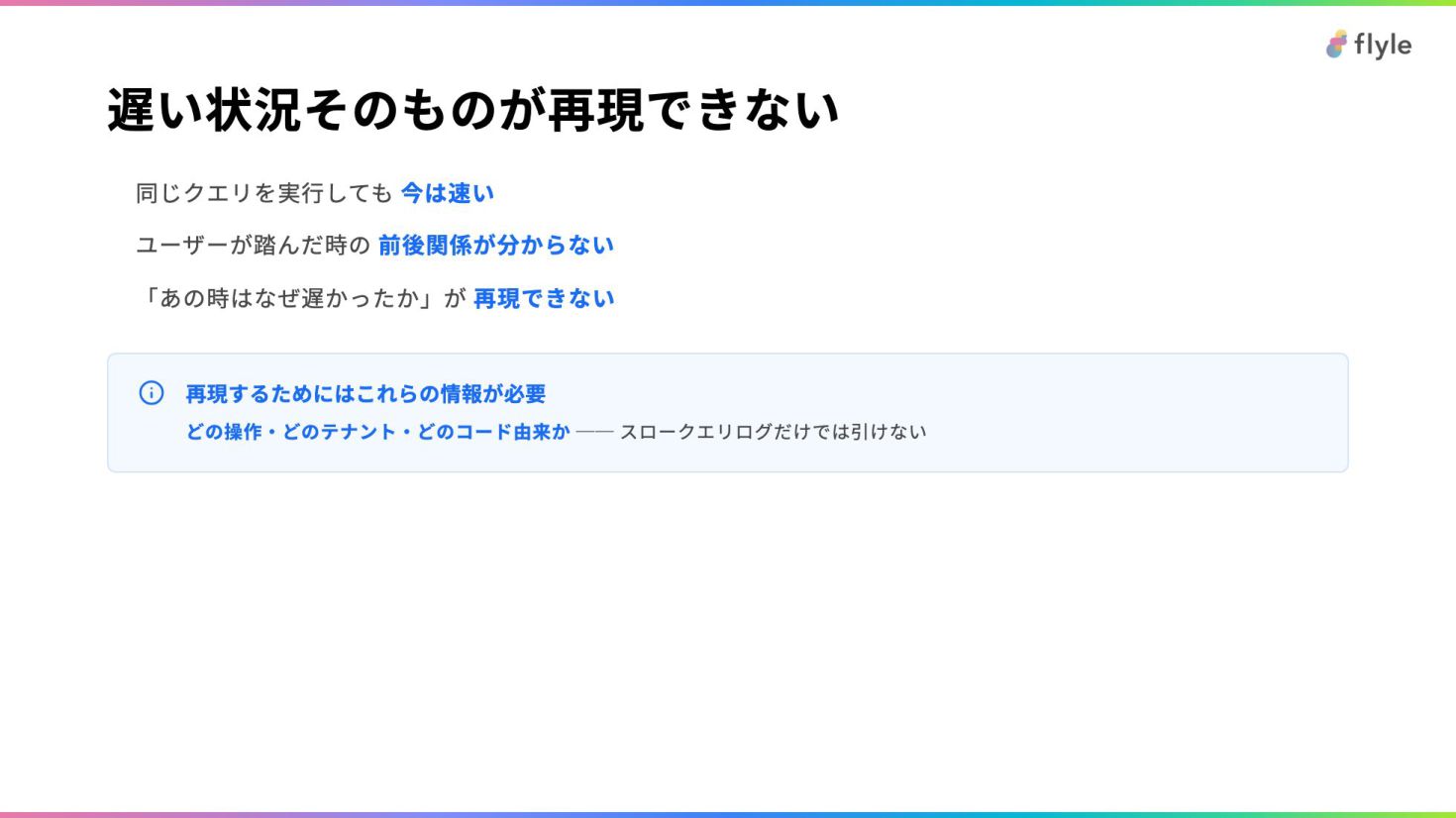
# 遅い状況そのものが再現できない
- 同じクエリを実行しても **今は速い**
- ユーザーが踏んだ時の **前後関係が分からない**
- 「あの時はなぜ遅かったか」が **再現できない**
> **再現するためにはこれらの情報が必要**
>
> **どの操作・どのテナント・どのコード由来か** ── スロークエリログだけでは引けない
---
# AIに任せられない(セキュリティ)
### データを渡せない
- **生データ** をそのまま AI に渡せない
- ログにも個人情報・センシティブ情報が含まれ、マスキングを毎回やるのは現実的でない
### 操作を任せられない
- AI に **本番権限** を渡すこと自体が許容できない
- 本番環境への **破壊的な変更** を AI が実行するのは絶対NG
> **検証は人間がやらざるを得ない**
>
> 「データを渡せない」と「操作を任せられない」の両方で詰まり、最後は **人間の試行錯誤** に戻ってくる
---
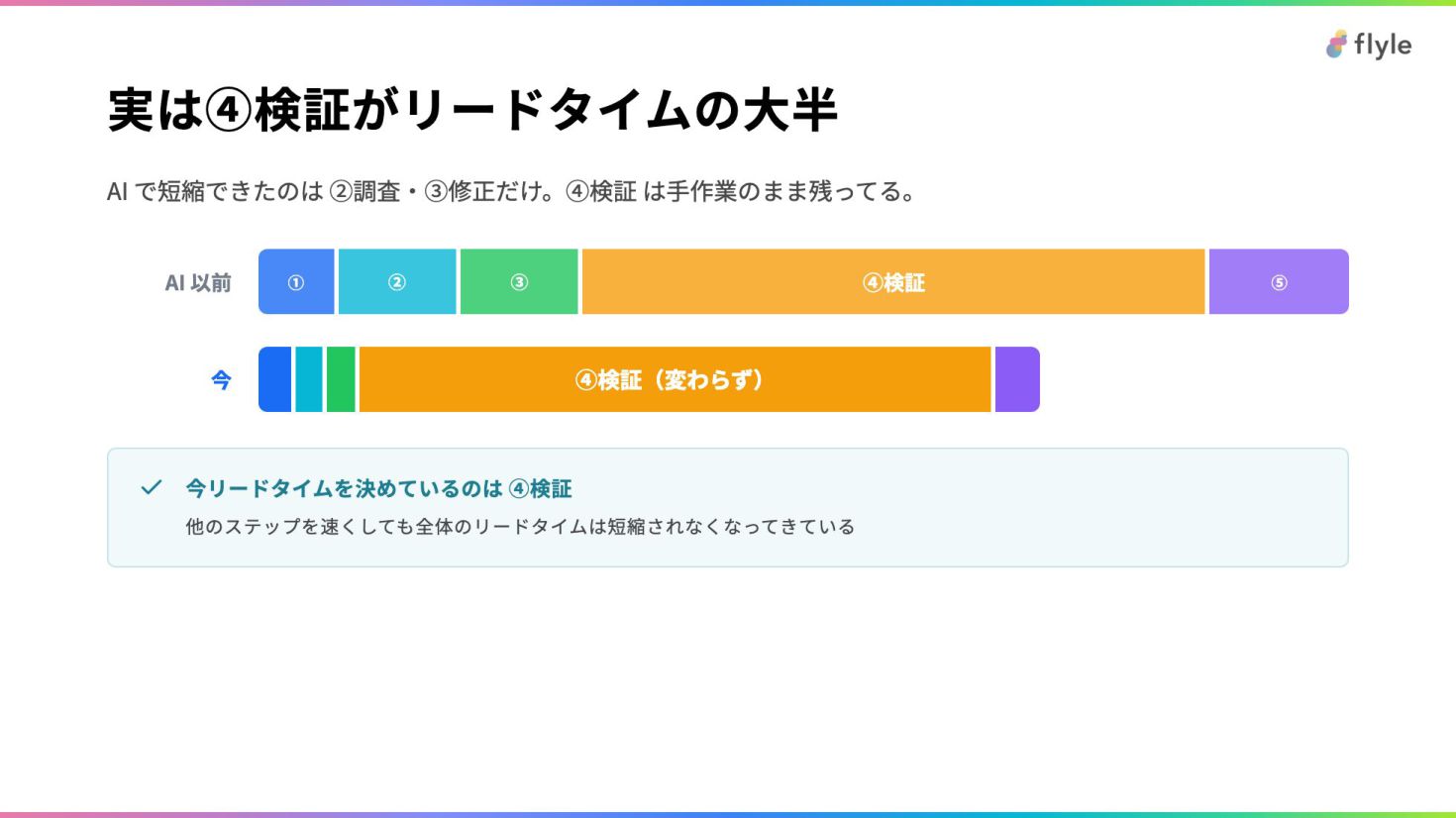
# 実は④検証がリードタイムの大半
AI で短縮できたのは ②調査・③修正だけ。④検証 は手作業のまま残ってる。
AI 以前 ① ② ③ ④検証 ⑤ 今
④検証(変わらず)
> **今リードタイムを決めているのは ④検証**
>
> 他のステップを速くしても全体のリードタイムは短縮されなくなってきている
---
# **Platform Engineering** で扱うべき問題
手作業で残った工程を自前のツールで効率化する
改善のリードタイムの内訳(いま)
① ② ③ ④検証 ⑤
残った人手のほとんどが ④検証 ── ここを最優先で効率化する
①発見・②調査・③修正・⑤リリースは AI・自動化で大きく短縮済み
> **AI で Platform Engineering 自体の構築コストも下がってきた**
>
> カスタムCLI・静的解析・観測タグ付与など、**工数の都合で諦めていた仕組み** も AI と一緒に作れる
---
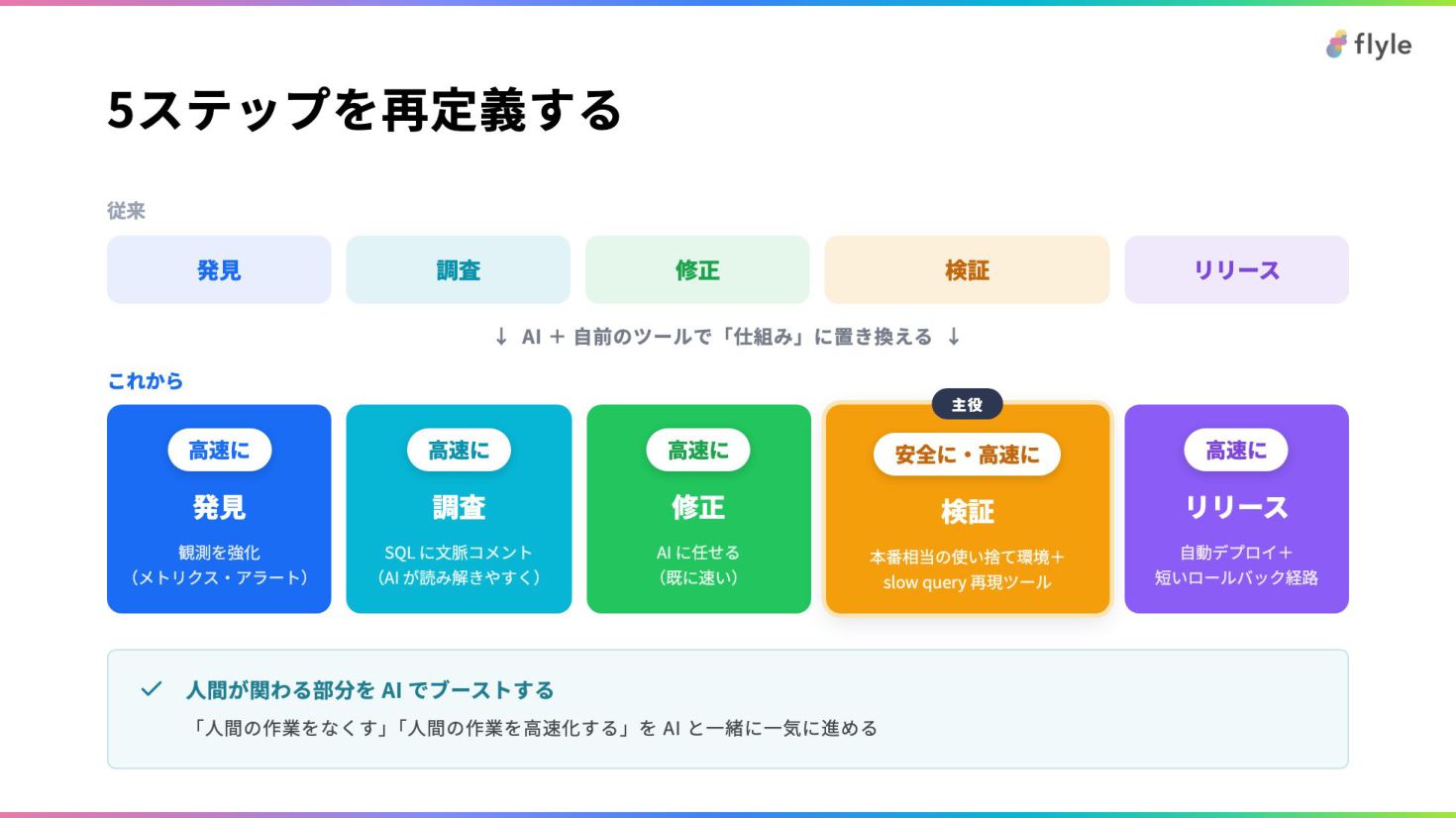
# 5ステップを再定義する
従来 発見 調査 修正 検証 リリース
↓ AI + 自前のツールで「仕組み」に置き換える ↓
これから 高速に 発見
観測を強化
(メトリクス・アラート)
高速に 調査
SQL に文脈コメント
(AI が読み解きやすく)
高速に 修正
AI に任せる
(既に速い)
主役
安全に・高速に
検証
本番相当の使い捨て環境+
slow query 再現ツール
高速に リリース
自動デプロイ+
短いロールバック経路
> **人間が関わる部分を AI でブーストする**
>
> 「人間の作業をなくす」「人間の作業を高速化する」を AI と一緒に一気に進める
---
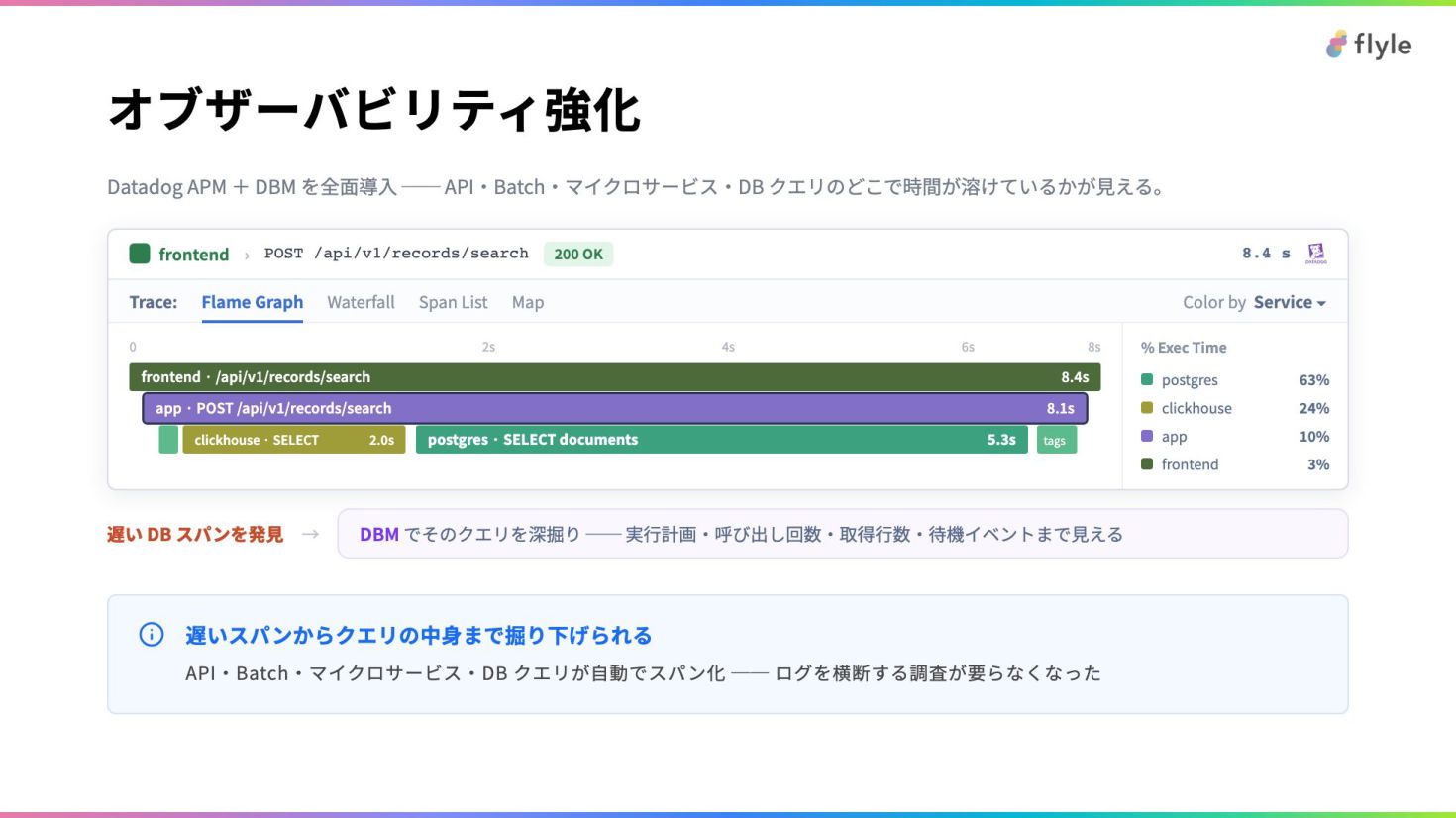
# オブザーバビリティ強化
Datadog APM + DBM を全面導入 ── API・Batch・マイクロサービス・DB クエリのどこで時間が溶けているかが見える。
frontend › POST /api/v1/records/search 200 OK 8.4 s
Trace: Flame Graph Waterfall Span List Map Color by Service ▾
0 2s 4s 6s 8s
frontend · /api/v1/records/search 8.4s
app · POST /api/v1/records/search 8.1s
clickhouse · SELECT 2.0s
postgres · SELECT documents 5.3s
tags
% Exec Time
postgres 63%
clickhouse 24%
app 10%
frontend 3%
遅い DB スパンを発見 →
DBM でそのクエリを深掘り ── 実行計画・呼び出し回数・取得行数・待機イベントまで見える
> **遅いスパンからクエリの中身まで掘り下げられる**
>
> API・Batch・マイクロサービス・DB クエリが自動でスパン化 ── ログを横断する調査が要らなくなった
---
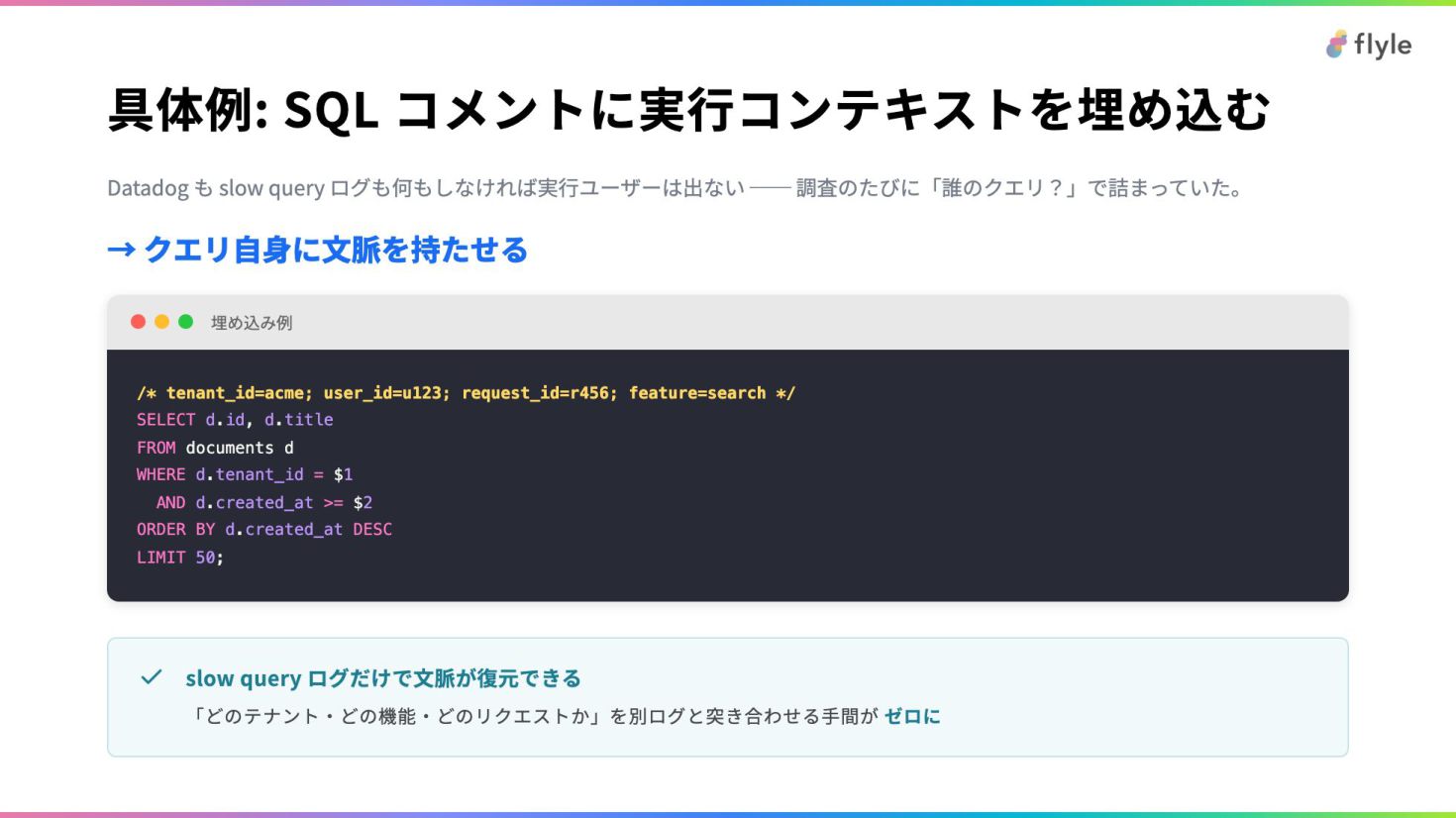
# 具体例: SQL コメントに実行コンテキストを埋め込む
Datadog も slow query ログも何もしなければ実行ユーザーは出ない ── 調査のたびに「誰のクエリ?」で詰まっていた。
→ クエリ自身に文脈を持たせる
**埋め込み例**
```sql
/* tenant_id=acme; user_id=u123; request_id=r456; feature=search */
…
```
> **slow query ログだけで文脈が復元できる**
>
> 「どのテナント・どの機能・どのリクエストか」を別ログと突き合わせる手間が **ゼロに**
---
# 遅いクエリを安全に再現する仕組み
本番の slow query を本番相当の使い捨て環境で再現して測る ── 本番 DB には一切触れない。
本番環境
RDS(マルチテナント / RLS)
slow query ログ
Datadog APM
cw-slowq CLI
遅い SQL +実パラメータ
を抽出
使い捨て検証 DB
隔離 VPC・専用 IAM/SSO
本番スナップショットから起動 / readonly
検証が終わったら破棄
explain-query CLI
EXPLAIN ANALYZE
→ 自動 ROLLBACK
原因が判明
実データ量での実行計画
seq scan / index 不足
が具体的に見える
> **本番に触れずに本番と同じ条件で検証できる**
>
> クエリを実行するのは人間(開発者)。AI には EXPLAIN 結果の解析や修正案づくりだけ任せる
---
# 本番と同等の環境を用意する
- 元々あった「**マイグレーション時間計測**」の仕組みを発展
- 本番と同量のデータを **サービスに影響を与えずに** 触れる環境
- 必要時に **1コマンドで作成・破棄** できるよう自動化
- 検証用の **独自スクリプト・ツール** を整備
> **既存資産から育てる**
>
> ゼロから作らず **既存の運用ツール** を拡張
> 時間もコストも抑えながら検証品質を上げる
---
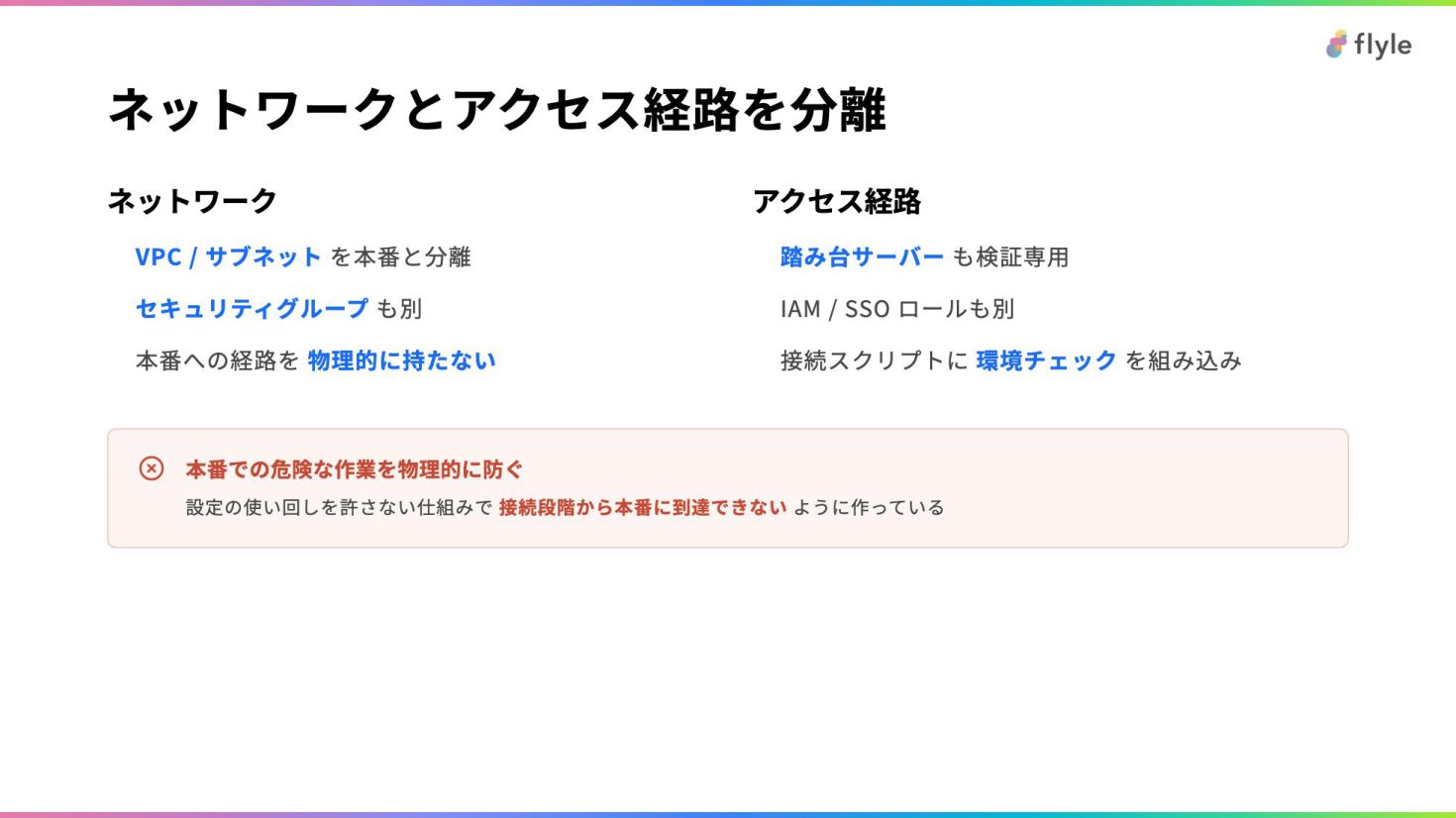
# ネットワークとアクセス経路を分離
### ネットワーク
- **VPC / サブネット** を本番と分離
- **セキュリティグループ** も別
- 本番への経路を **物理的に持たない**
### アクセス経路
- **踏み台サーバー** も検証専用
- IAM / SSO ロールも別
- 接続スクリプトに **環境チェック** を組み込み
> **本番での危険な作業を物理的に防ぐ**
>
> 設定の使い回しを許さない仕組みで **接続段階から本番に到達できない** ように作っている
---
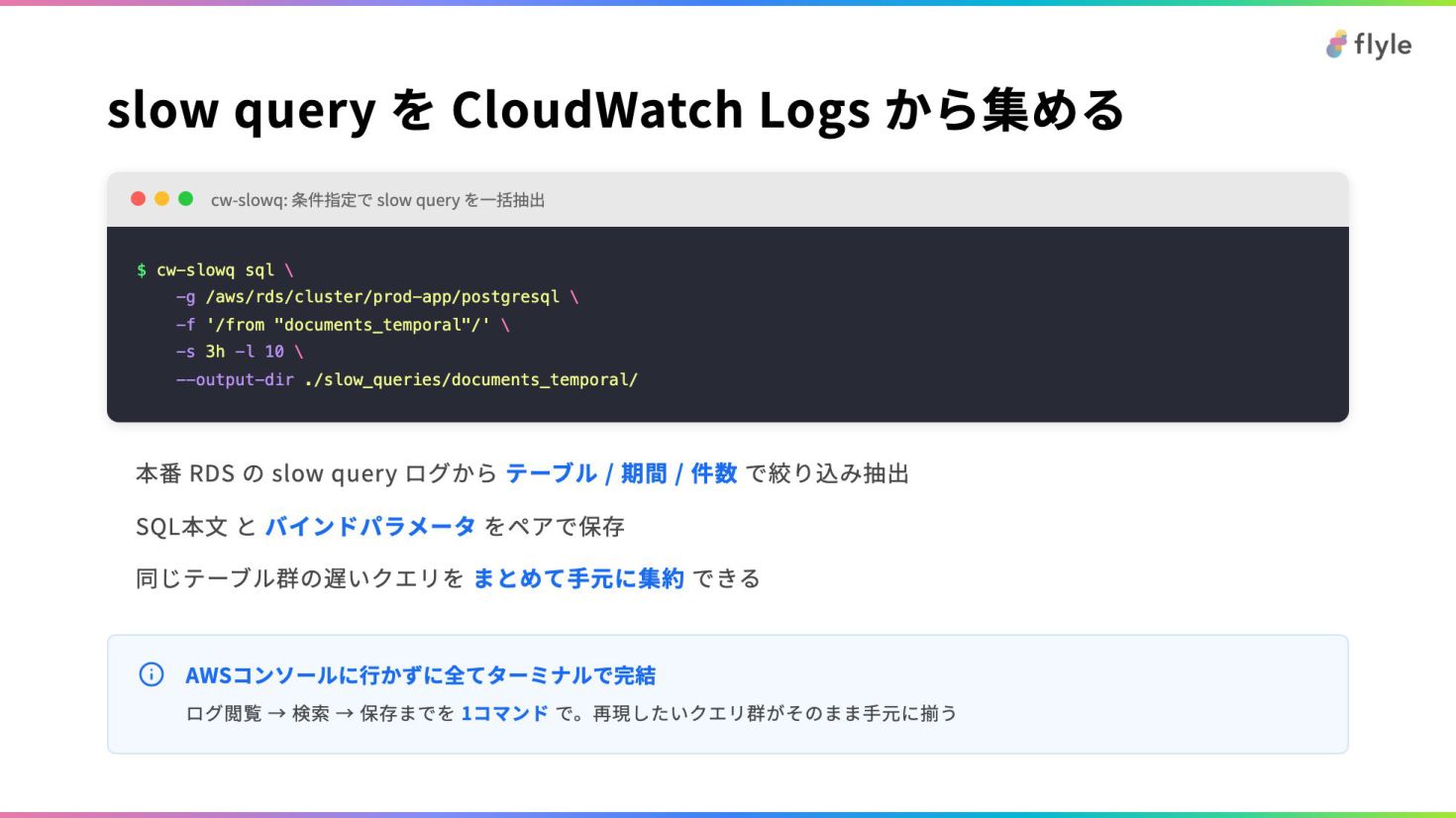
# slow query を CloudWatch Logs から集める
**cw-slowq: 条件指定で slow query を一括抽出**
```bash
$ cw-slowq sql \
…
```
- 本番 RDS の slow query ログから **テーブル / 期間 / 件数** で絞り込み抽出
- SQL本文 と **バインドパラメータ** をペアで保存
- 同じテーブル群の遅いクエリを **まとめて手元に集約** できる
> **AWSコンソールに行かずに全てターミナルで完結**
>
> ログ閲覧 → 検索 → 保存までを **1コマンド** で。再現したいクエリ群がそのまま手元に揃う
---
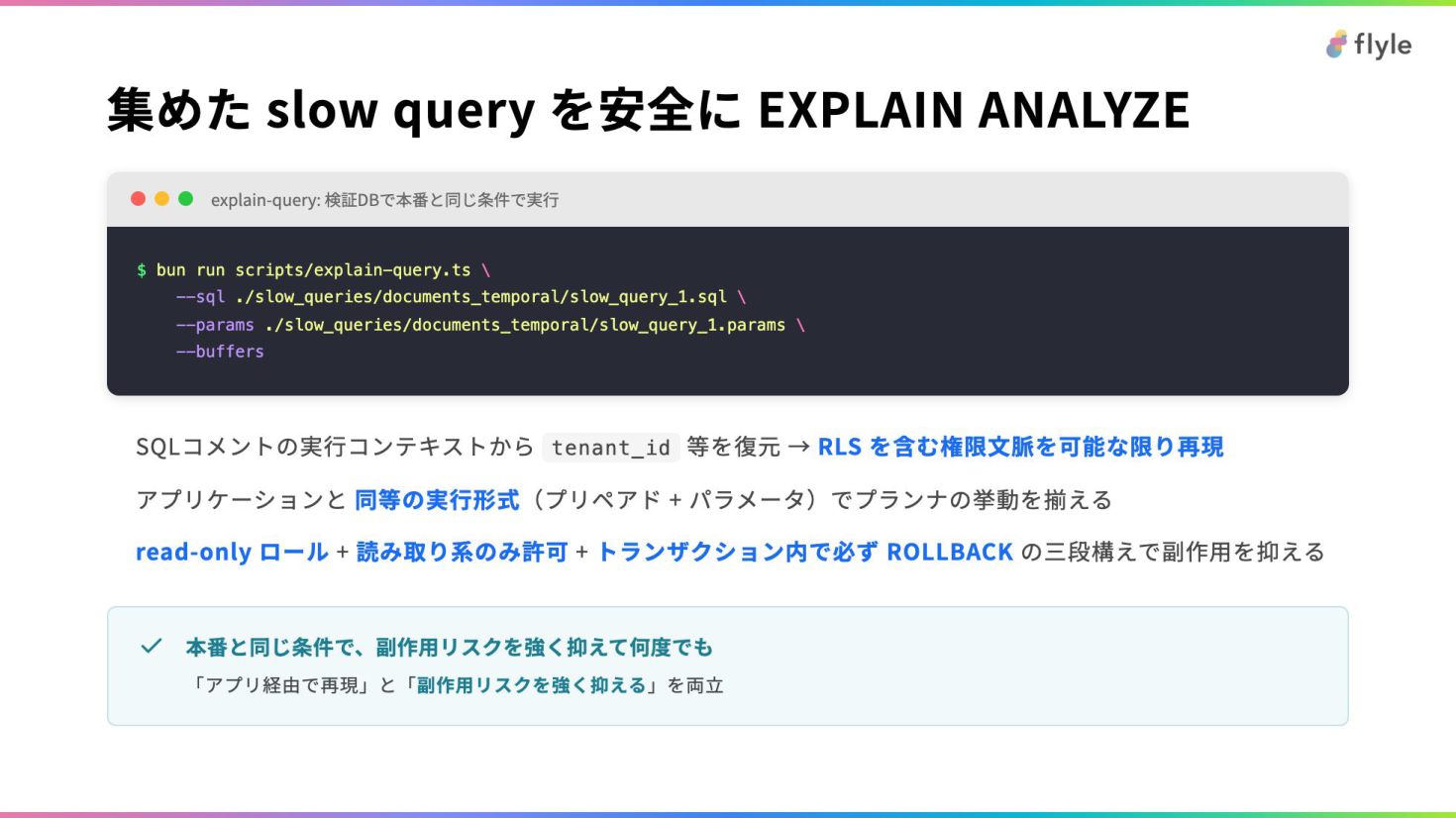
# 集めた slow query を安全に EXPLAIN ANALYZE
**explain-query: 検証DBで本番と同じ条件で実行**
```bash
$ bun run scripts/explain-query.ts \
…
```
- SQLコメントの実行コンテキストから `tenant_id` 等を復元 → **RLS を含む権限文脈を可能な限り再現**
- アプリケーションと **同等の実行形式**(プリペアド + パラメータ)でプランナの挙動を揃える
- **read-only ロール** + **読み取り系のみ許可** + **トランザクション内で必ず ROLLBACK** の三段構えで副作用を抑える
> **本番と同じ条件で、副作用リスクを強く抑えて何度でも**
>
> 「アプリ経由で再現」と「**副作用リスクを強く抑える**」を両立
---
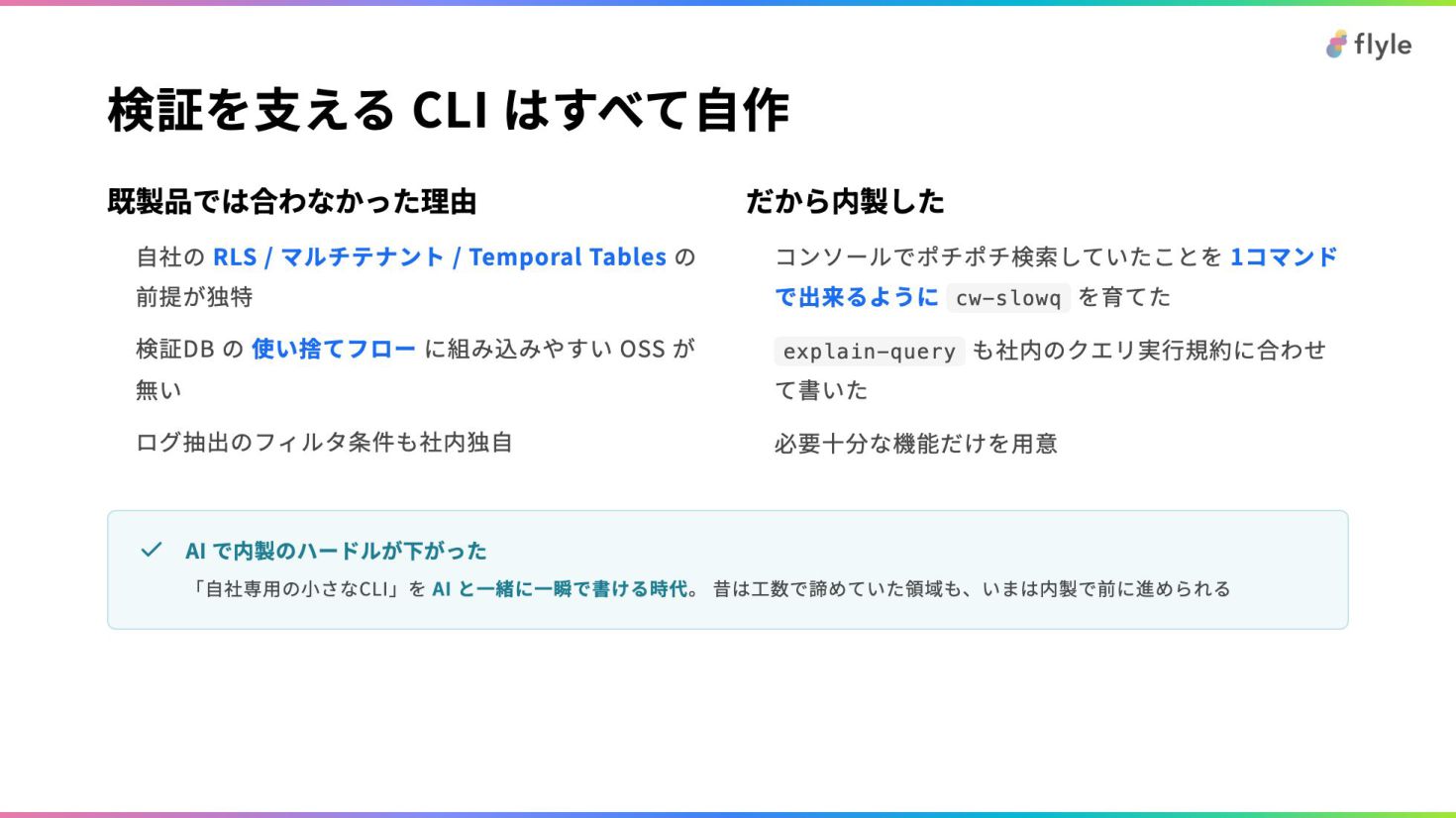
# 検証を支える CLI はすべて自作
### 既製品では合わなかった理由
- 自社の **RLS / マルチテナント / Temporal Tables** の前提が独特
- 検証DB の **使い捨てフロー** に組み込みやすい OSS が無い
- ログ抽出のフィルタ条件も社内独自
### だから内製した
- コンソールでポチポチ検索していたことを **1コマンドで出来るように** `cw-slowq` を育てた
- `explain-query` も社内のクエリ実行規約に合わせて書いた
- 必要十分な機能だけを用意
> **AI で内製のハードルが下がった**
>
> 「自社専用の小さなCLI」を **AI と一緒に一瞬で書ける時代**。
> 昔は工数で諦めていた領域も、いまは内製で前に進められる
---
# 性能改善を「最重要課題」のまま回し続ける
「重要だけど急ぎではない」に落ちないよう、時間・経路・コスト・優先度を仕組みにしておく。
リリース時間の短縮
CI・テスト・デプロイの所要時間を継続的に削る。**通常のリリースが速い** ほど、性能改善も小さく頻繁に試せる
リリース経路を短く保つ
通常リリースとは別に **hotfix 経路** を整備。手順は **コード化** して、緊急時でも誰でも安全に流せる状態を保つ
コストで語る
重いクエリはそのまま **Aurora の I/O・コンピュートコスト** に乗る。直せば月々の運用費も下がる ── 「やる理由」を金額で示せる
影響ベースで優先度を決める
どのテナント・どの機能に効くか、商談やリニューアルが近いか ── **CS・Sales と連携** して影響の大きい順に並べる
> **「重要だけど急ぎではない」に落とさない**
>
> やる理由(コスト)と順番(影響)をはっきりさせ、時間と経路を短く保つ
---
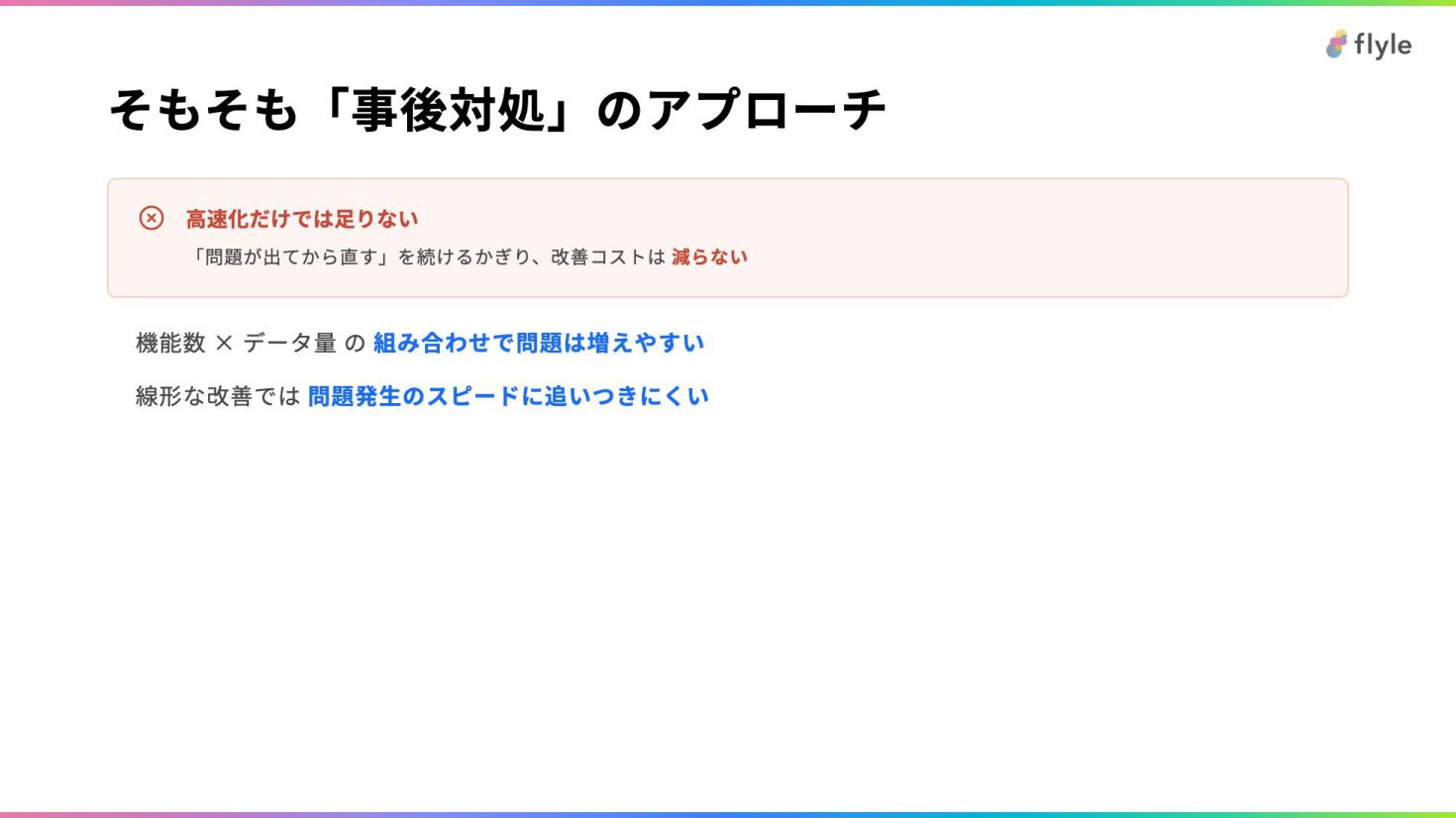
# そもそも「事後対処」のアプローチ
> **高速化だけでは足りない**
>
> 「問題が出てから直す」を続けるかぎり、改善コストは **減らない**
- 機能数 × データ量 の **組み合わせで問題は増えやすい**
- 線形な改善では **問題発生のスピードに追いつきにくい**
---
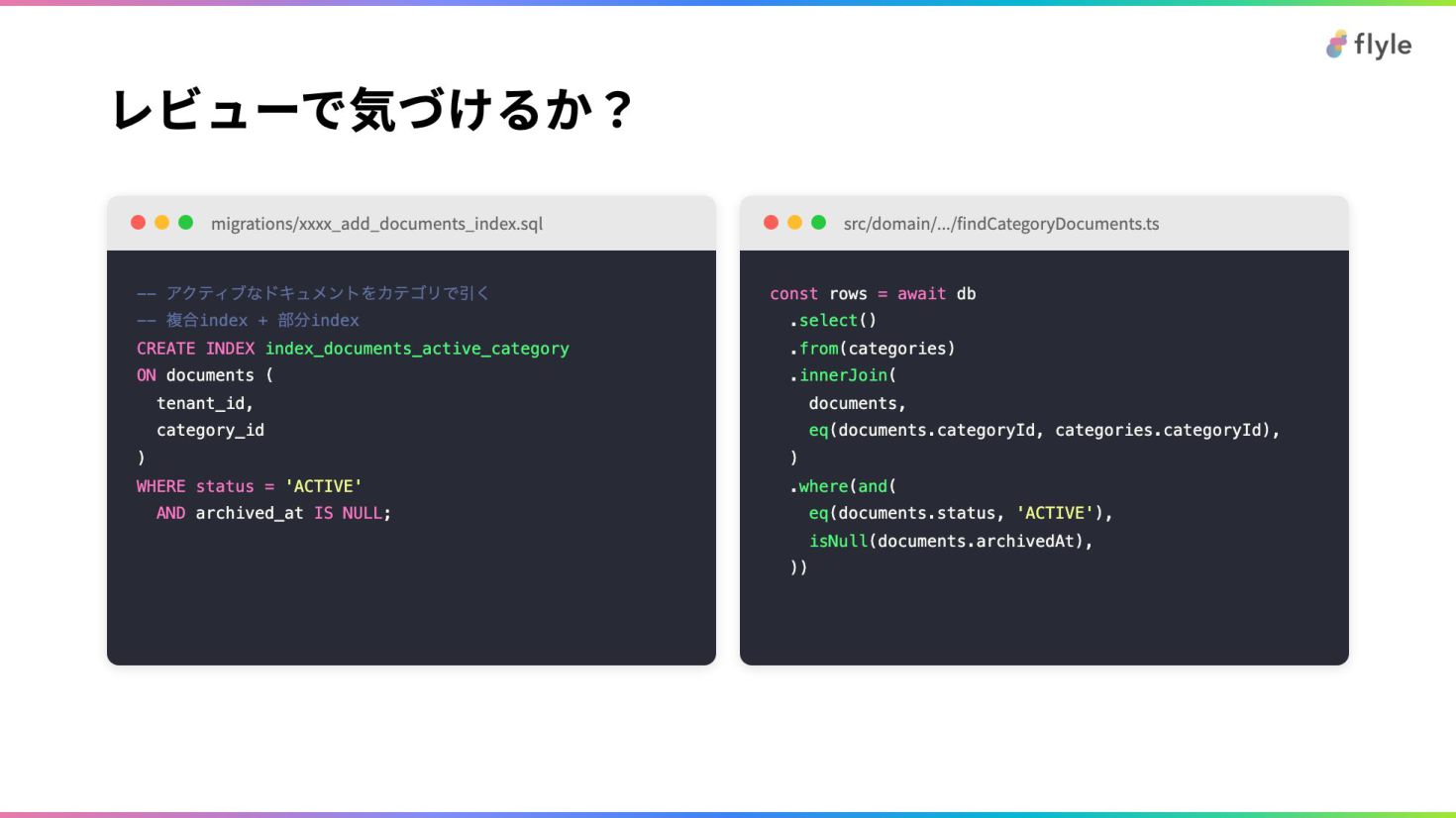
# レビューで気づけるか?
**migrations/xxxx_add_documents_index.sql**
```sql
-- アクティブなドキュメントをカテゴリで引く
…
```
**src/domain/.../findCategoryDocuments.ts**
```ts
const rows = await db
…
```
---
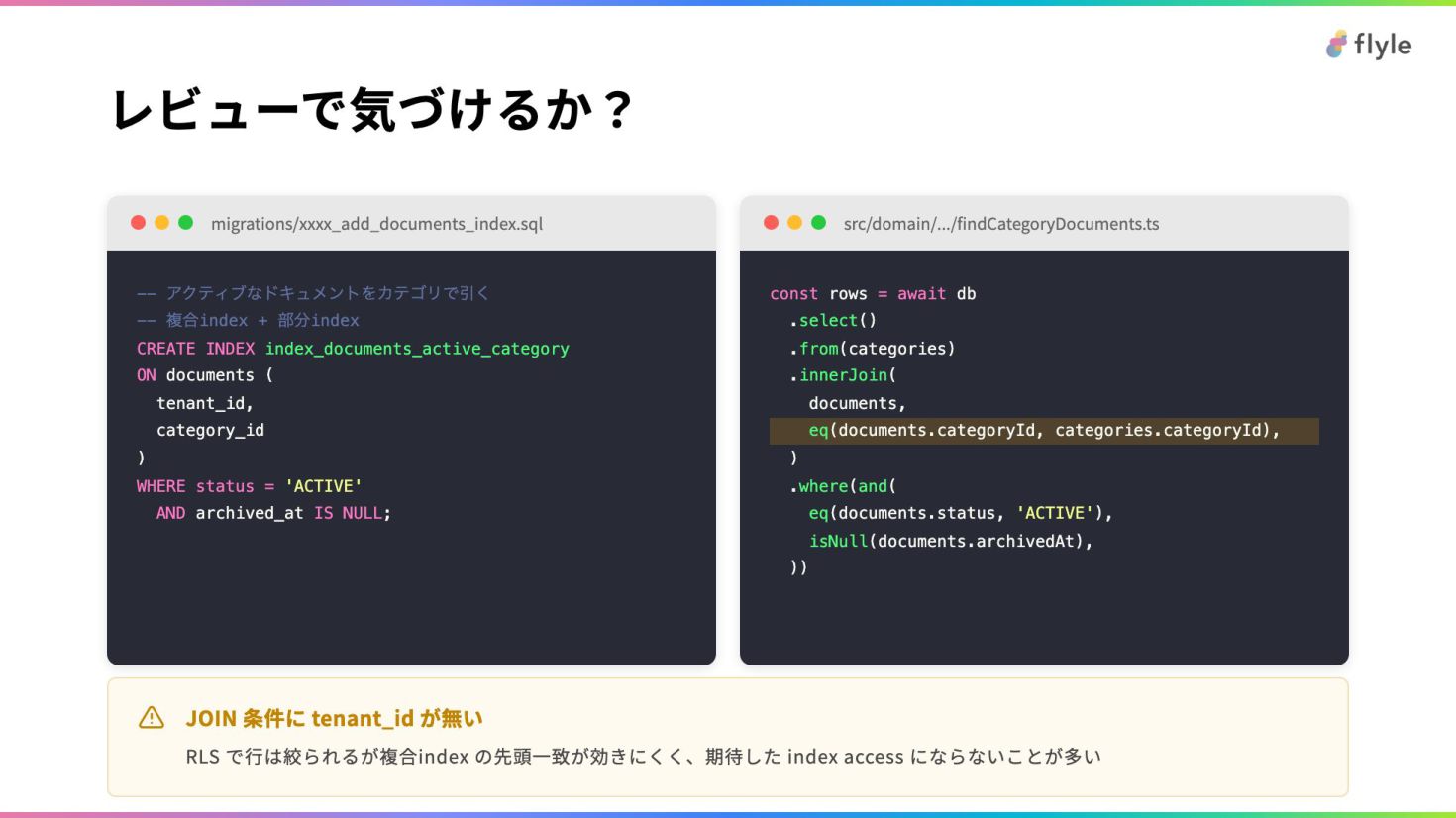
# レビューで気づけるか?
**migrations/xxxx_add_documents_index.sql**
```sql
-- アクティブなドキュメントをカテゴリで引く
…
```
**src/domain/.../findCategoryDocuments.ts**
```ts {6}
const rows = await db
.select()
.from(categories)
.innerJoin(
documents,
eq(documents.categoryId, categories.categoryId),
)
.where(and(
eq(documents.status, 'ACTIVE'),
isNull(documents.archivedAt),
))
```
> **JOIN 条件に tenant_id が無い**
>
> RLS で行は絞られるが複合index の先頭一致が効きにくく、期待した index access にならないことが多い
---
# 正しくはこう
**migrations/xxxx_add_documents_index.sql**
```sql
-- アクティブなドキュメントをカテゴリで引く
…
```
**src/domain/.../findCategoryDocuments.ts**
```ts {5}
const rows = await db
.select()
.from(categories)
.innerJoin(documents, and(
eq(documents.tenantId, categories.tenantId),
eq(documents.categoryId, categories.categoryId),
))
.where(and(
eq(documents.status, 'ACTIVE'),
isNull(documents.archivedAt),
))
```
> **実際には数千行の diff からこの一行を見抜く必要がある**
>
> 複雑な JOIN や条件式の中で正しいindexが使われているかを人力で発見するのは現実的ではない
---
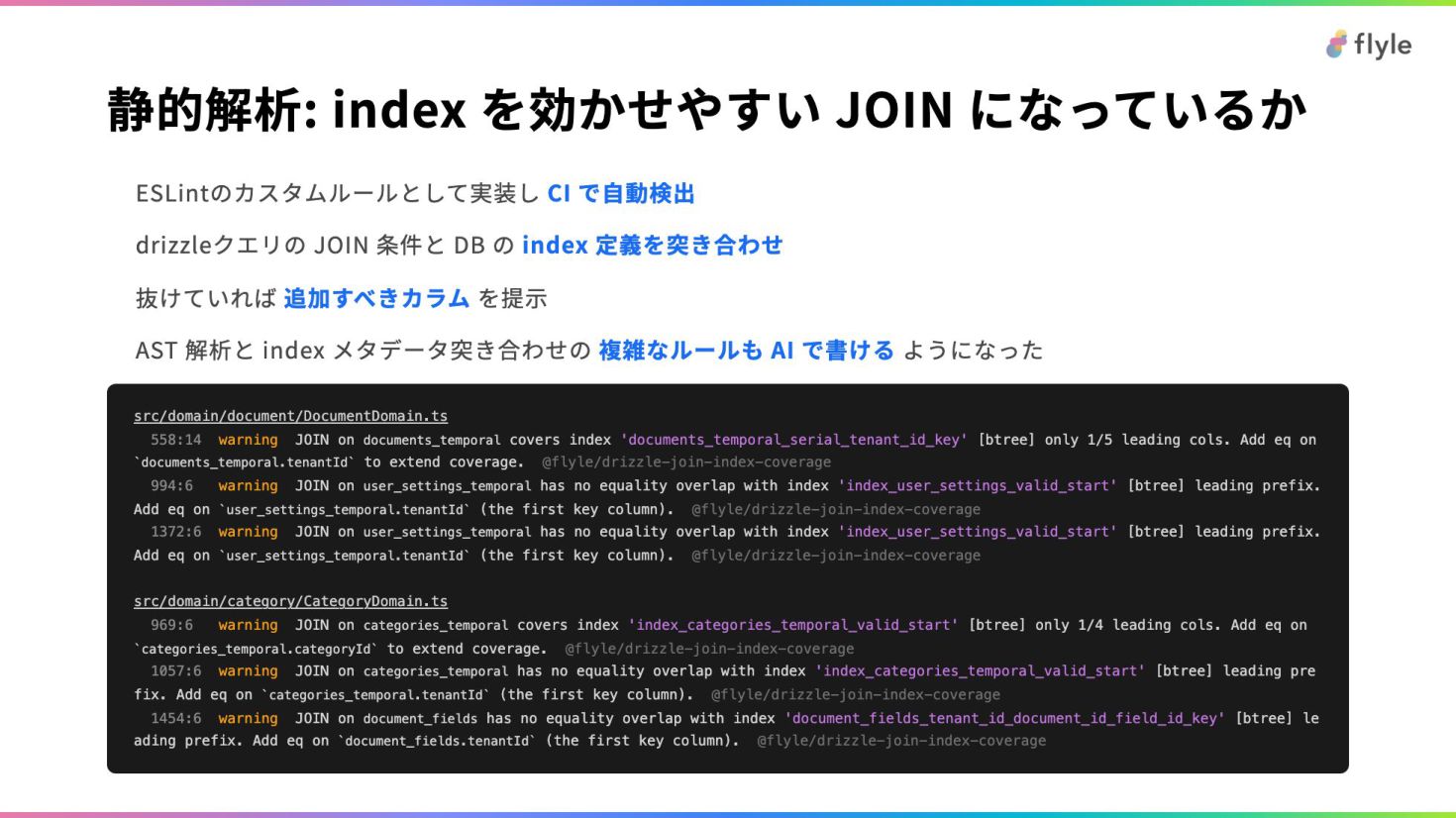
# 静的解析: index を効かせやすい JOIN になっているか
- ESLintのカスタムルールとして実装し **CI で自動検出**
- drizzleクエリの JOIN 条件と DB の **index 定義を突き合わせ**
- 抜けていれば **追加すべきカラム** を提示
- AST 解析と index メタデータ突き合わせの **複雑なルールも AI で書ける** ようになった
src/domain/document/DocumentDomain.ts
558:14 warning JOIN on `documents_temporal` covers index 'documents_temporal_serial_tenant_id_key' [btree] only 1/5 leading cols. Add eq on ``documents_temporal.tenantId`` to extend coverage. @flyle/drizzle-join-index-coverage
994:6 warning JOIN on `user_settings_temporal` has no equality overlap with index 'index_user_settings_valid_start' [btree] leading prefix. Add eq on ``user_settings_temporal.tenantId`` (the first key column). @flyle/drizzle-join-index-coverage
1372:6 warning JOIN on `user_settings_temporal` has no equality overlap with index 'index_user_settings_valid_start' [btree] leading prefix. Add eq on ``user_settings_temporal.tenantId`` (the first key column). @flyle/drizzle-join-index-coverage
src/domain/category/CategoryDomain.ts
969:6 warning JOIN on `categories_temporal` covers index 'index_categories_temporal_valid_start' [btree] only 1/4 leading cols. Add eq on ``categories_temporal.categoryId`` to extend coverage. @flyle/drizzle-join-index-coverage
1057:6 warning JOIN on `categories_temporal` has no equality overlap with index 'index_categories_temporal_valid_start' [btree] leading prefix. Add eq on ``categories_temporal.tenantId`` (the first key column). @flyle/drizzle-join-index-coverage
1454:6 warning JOIN on `document_fields` has no equality overlap with index 'document_fields_tenant_id_document_id_field_id_key' [btree] leading prefix. Add eq on ``document_fields.tenantId`` (the first key column). @flyle/drizzle-join-index-coverage
---
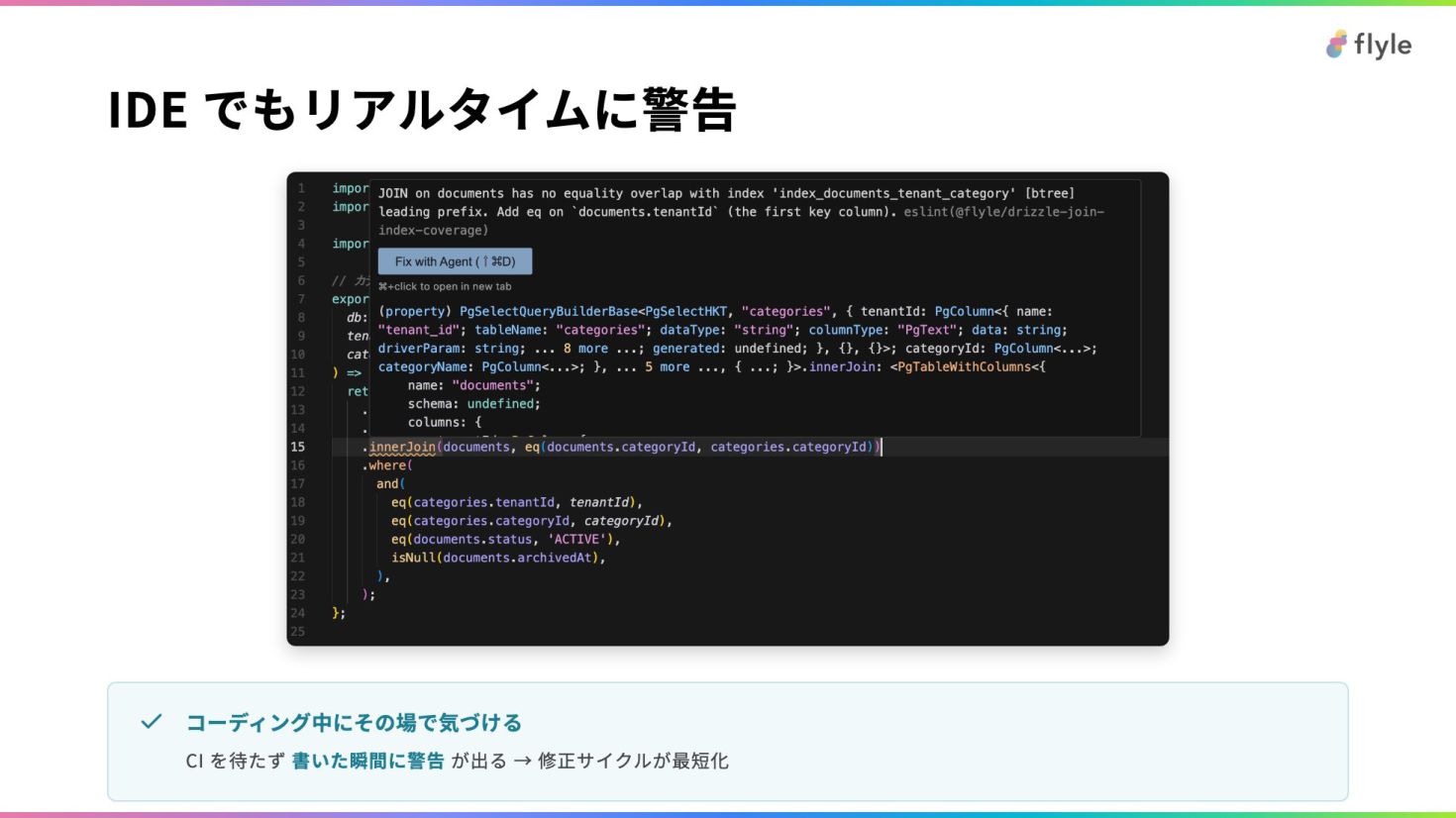
# IDE でもリアルタイムに警告
> **コーディング中にその場で気づける**
>
> CI を待たず **書いた瞬間に警告** が出る → 修正サイクルが最短化
---
# 静的解析でも拾えないものがある
- 動的に組み立てられるクエリ条件
- 正しくカラムを指定しても **index が使われない** ケース
- 過去のインシデントから学んだ **特殊な落とし穴**
> **ルールに落とし切れない知見が残る**
>
> 静的解析は **構造的な抜け** は検出できるが、**文脈に依存する判断** までは難しい
---
# 残った知見を **SKILL.md** に蓄積する
- 過去の **性能改善 PR・インシデント** から学んだパターンを SKILL.md に書き出す
- AI レビュアー(Claude Code 等)が **PRごとに自動参照**
- 静的解析と組み合わせて **構造 + 文脈** の両面を網羅
- 弊社では Claude Code の **`SKILL.md`** として実装している
> **ナレッジを「コード化」する**
>
> 個人の経験を **チーム全員の出発点** に
> 新メンバーも初日から同じレベルでレビューできる
---
# 本日のまとめ
1. AIの進化で機能開発は爆速 → 性能問題も急増した
2. 性能改善5ステップのうち、AIで速くなったのは「調査・修正」だけ
3. 「検証」は本番データとセキュリティの壁で AI に任せきれない
4. 遅い工程を仕組みで短縮するのが Platform Engineering の役割
5. 事後対処だけでは足りない → 静的解析と SKILL.md で事前に止める
---
# パフォーマンス改善に終わりはない
- 機能開発のスピードは **まだ上がる**
- データ量も **まだ増える**
- 人間がやる作業を **効率化し続ける**
> **AI が「調査・修正」を速くした分、「検証」や「事前検出」を仕組みで短縮する**
>
> ここを Platform Engineering の重心として持ち続けることが、**改善のリードタイムを止めない** 鍵
---
# まだまだ課題はある
- 簡単な改善は一通り終わった
- 改善で一部は速くなるが、逆に遅くなるケースも出てくる
- 今回紹介した PostgreSQL 周りの改善はほんの一部
- アプリケーションのロジック
- 他のDBの高速化
- アーキテクチャの変更...etc
- やることは山ほどある
> **効率化で減った人手をより難しい問題に投じる**
>
> 「速く作れる × 速く改善できる」のサイクルをもう一段回す
---
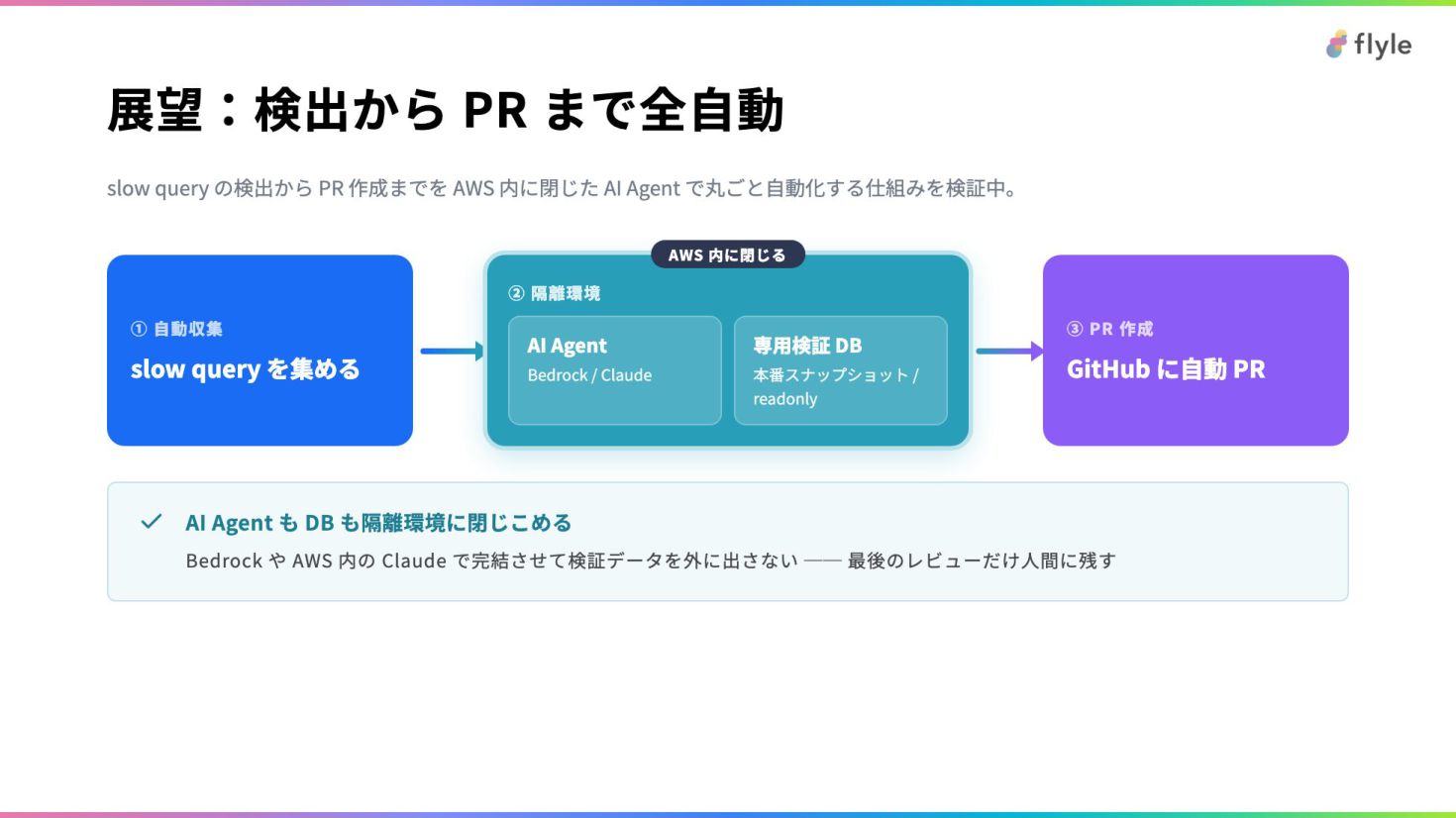
# 展望:検出から PR まで全自動
slow query の検出から PR 作成までを AWS 内に閉じた AI Agent で丸ごと自動化する仕組みを検証中。
① 自動収集
slow query を集める
AWS 内に閉じる
② 隔離環境
AI Agent
Bedrock / Claude
専用検証 DB
本番スナップショット / readonly
③ PR 作成
GitHub に自動 PR
> **AI Agent も DB も隔離環境に閉じこめる**
>
> Bedrock や AWS 内の Claude で完結させて検証データを外に出さない ── 最後のレビューだけ人間に残す
---
# 一緒にパフォーマンス改善を進める仲間を募集中
ここまで話してきた課題を一緒に解いていける人を探しています
### こんな人に来てほしい
- **大規模データ・マルチテナント** のスケール課題に挑みたい
- 個人技より **仕組みや道具で解く** のが好き
- **DB・API・キャッシュ・フロント** など領域をまたいで動ける
- **実験して試して進めていく** のを楽しめる
recruit.flyle.io
QR コードからどうぞ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}