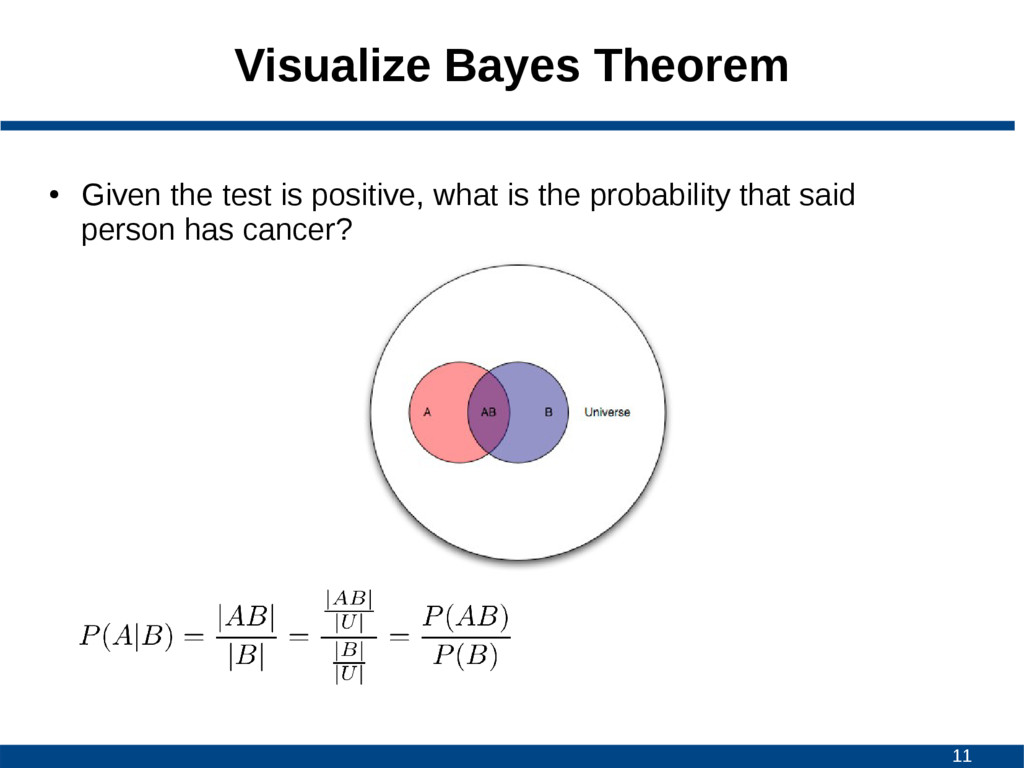
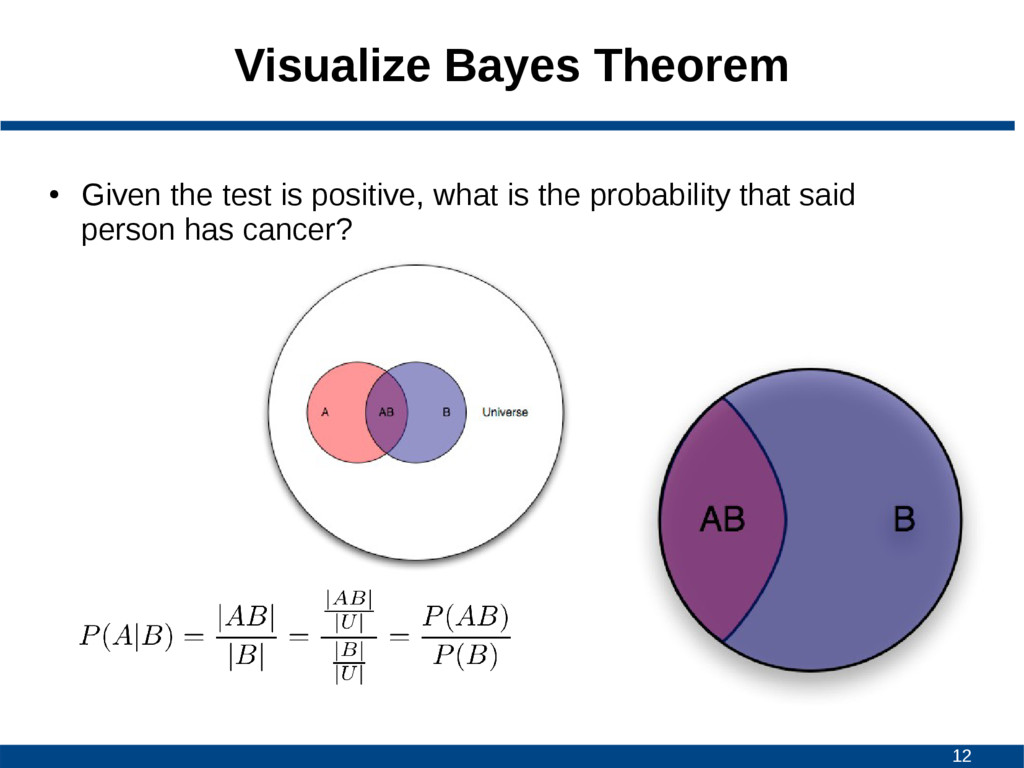
A given B is true • P(B|A) is conditional probability of observing B given A is true • P(A) and P(B) are probabilities of A and B without conditioning on each other
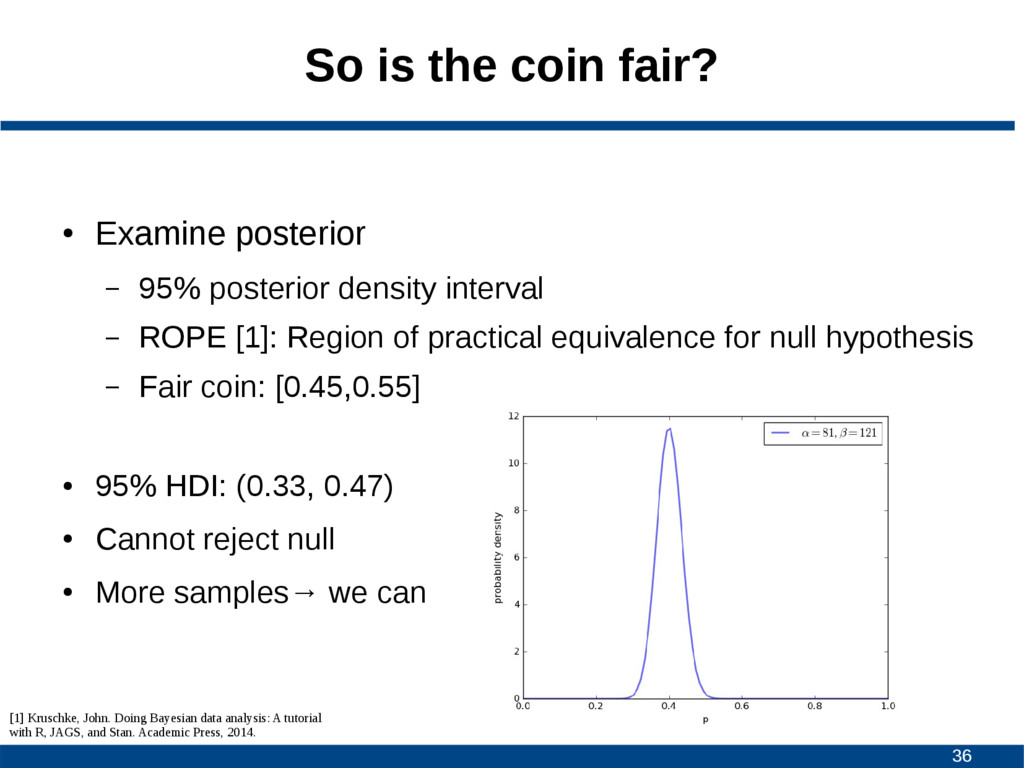
95% posterior density interval – ROPE [1]: Region of practical equivalence for null hypothesis – Fair coin: [0.45,0.55] • 95% HDI: (0.33, 0.47) • Cannot reject null • More samples→ we can [1] Kruschke, John. Doing Bayesian data analysis: A tutorial with R, JAGS, and Stan. Academic Press, 2014.
of marginal likelihoods • Interpretation table by Kass & Raftery [1] • >100 → decisive evidence against M2 [1] Kass, Robert E., and Adrian E. Raftery. "Bayes factors." Journal of the american statistical association 90.430 (1995): 773-795.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
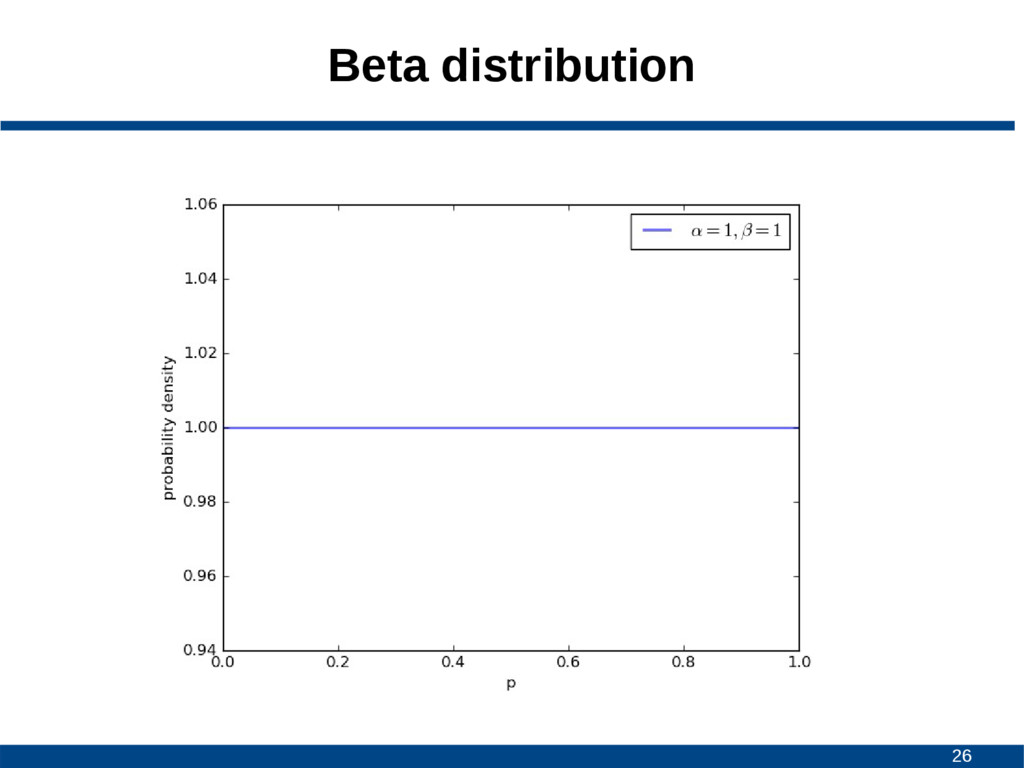
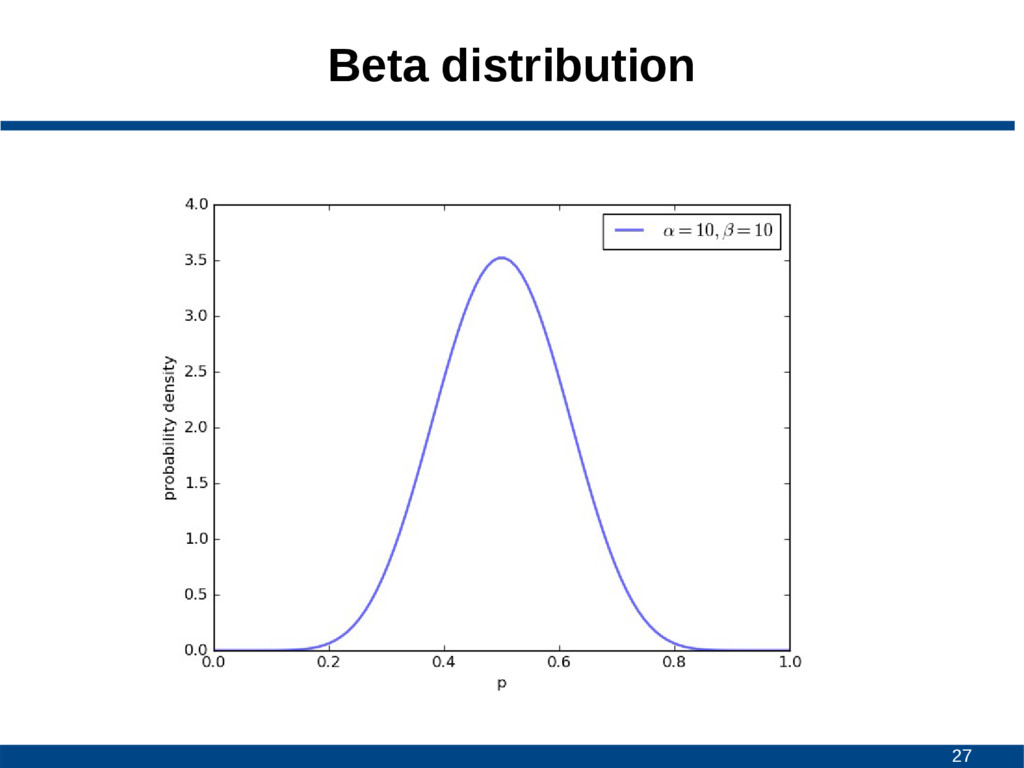
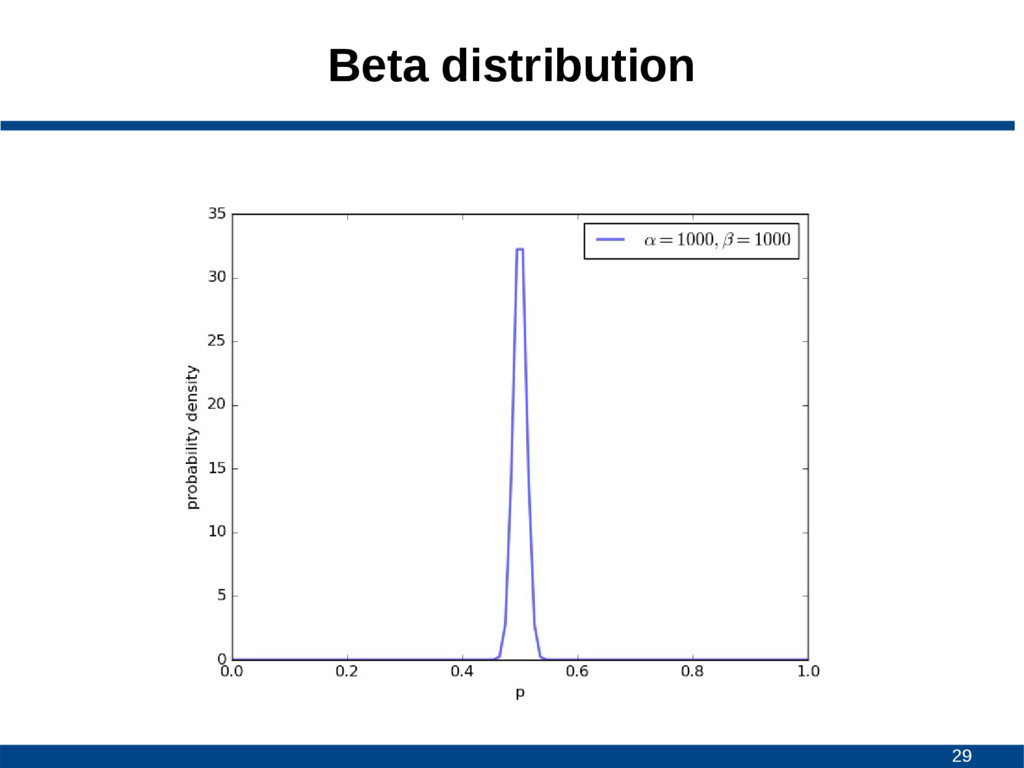
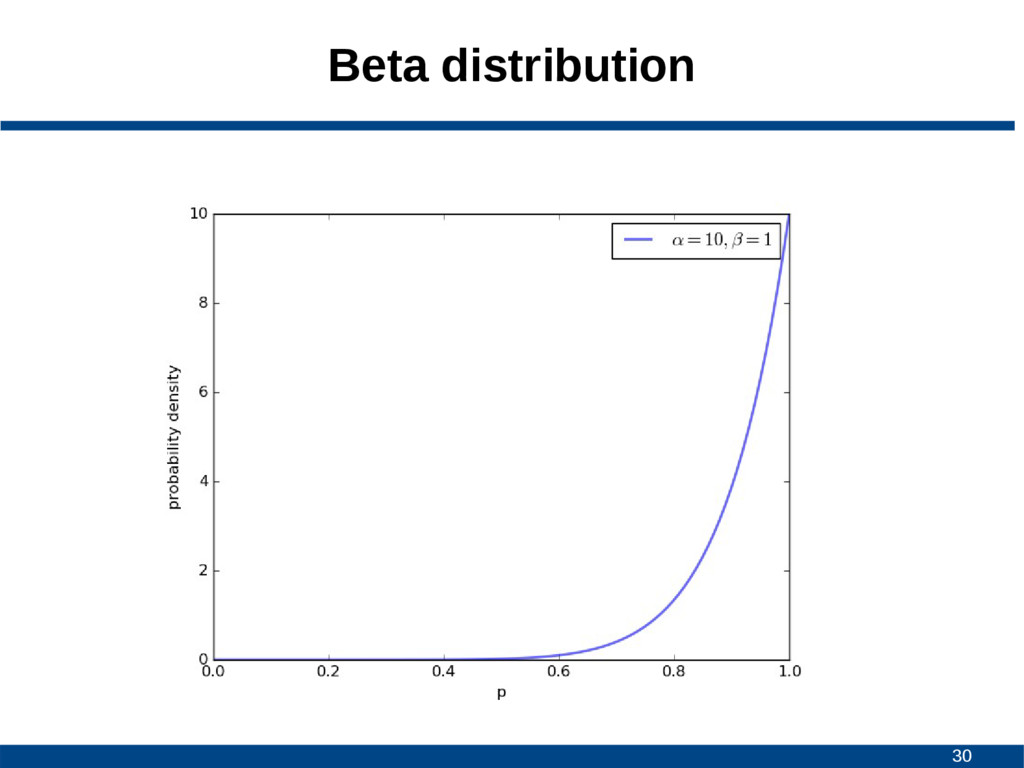
![25 Beta distribution • Continuous probability distribution • Interval [0,1]](https://files.speakerdeck.com/presentations/a1a381cb0d09431e9790b02e85bb2262/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![38 Bayesian Model Comparison • Bayes factors [1] • Ratio](https://files.speakerdeck.com/presentations/a1a381cb0d09431e9790b02e85bb2262/slide_36.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![50 Questions? Philipp Singer [email protected] Image credit: talk of Mike](https://files.speakerdeck.com/presentations/a1a381cb0d09431e9790b02e85bb2262/slide_48.jpg){kind=link}