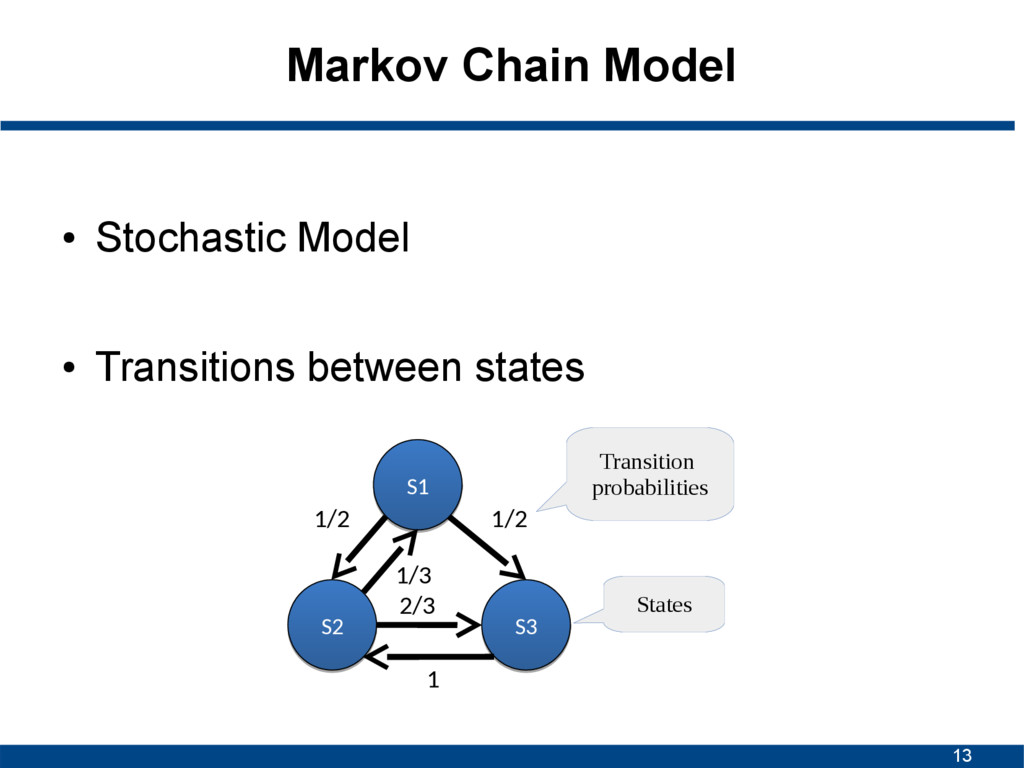
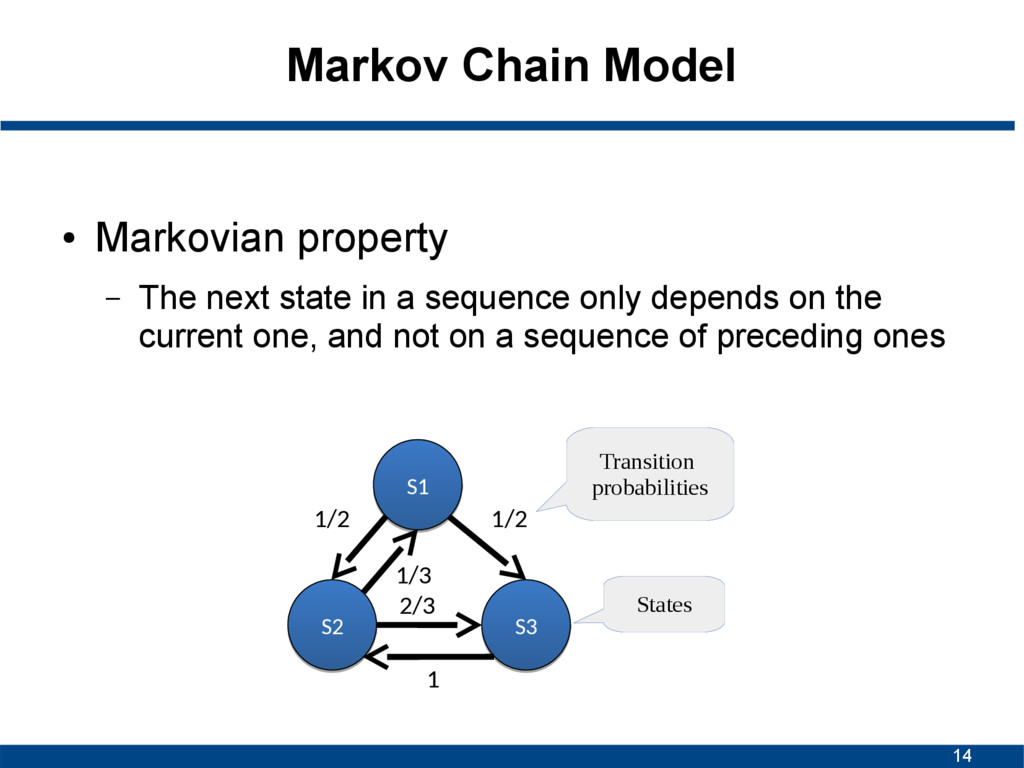
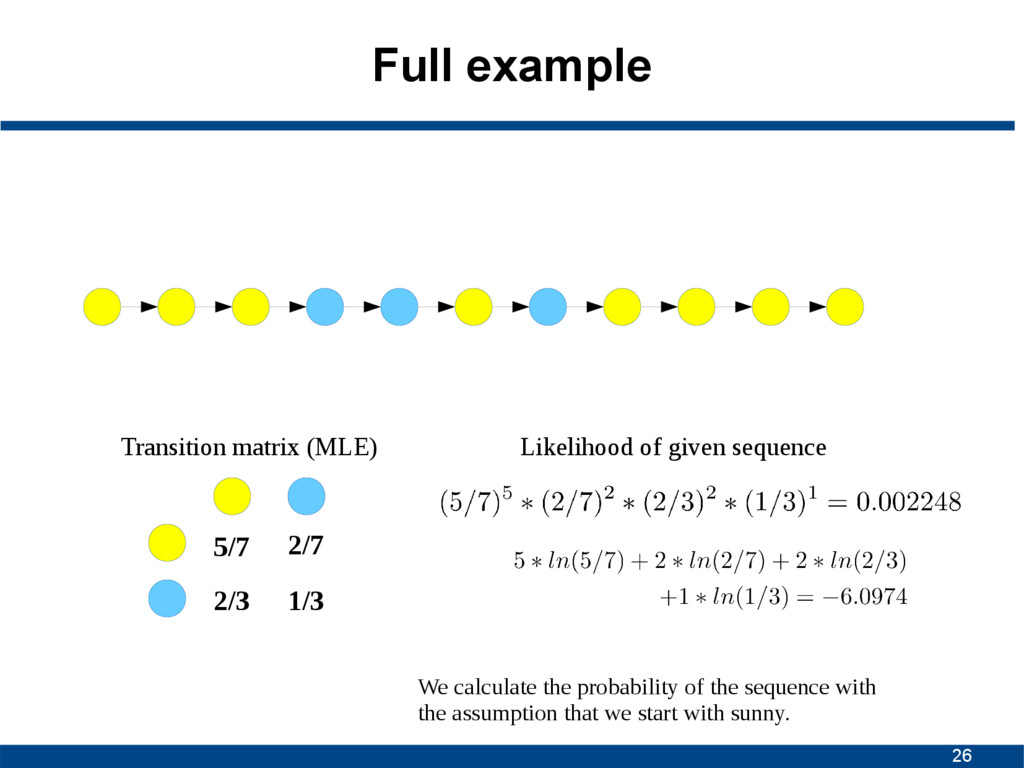
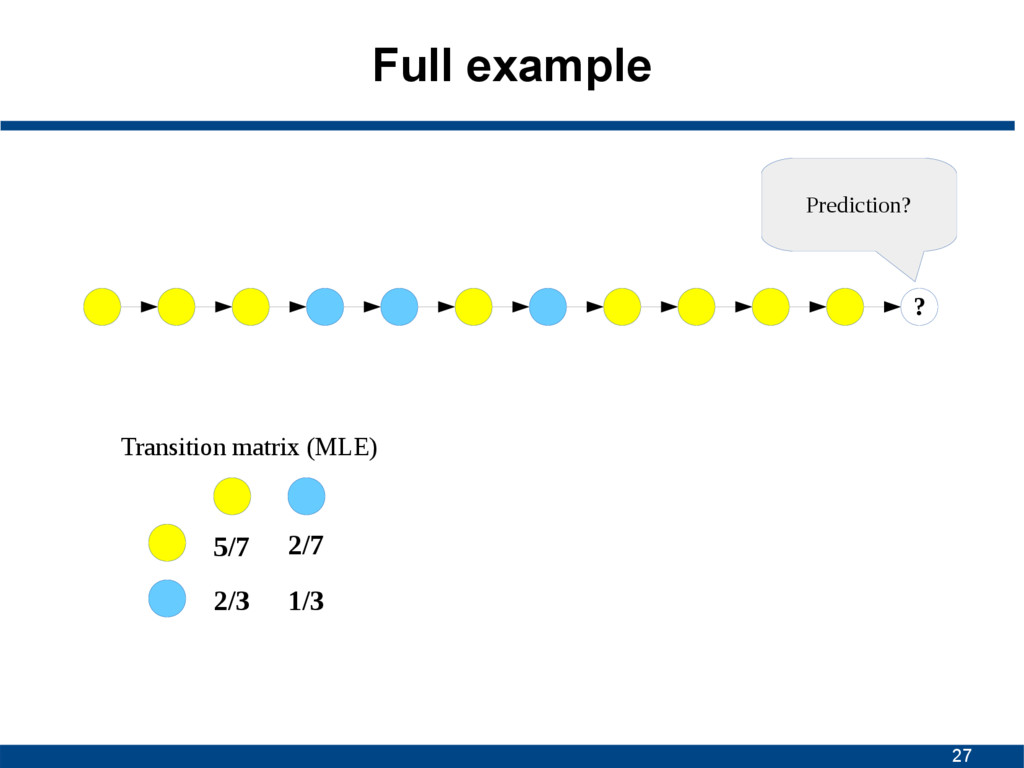
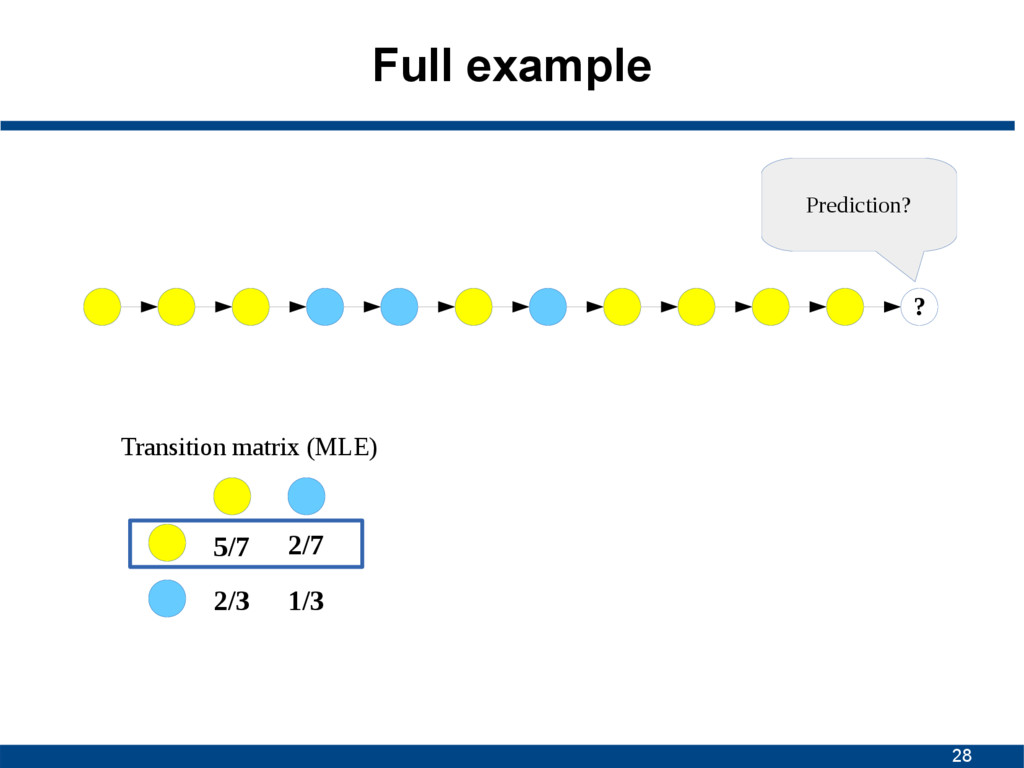
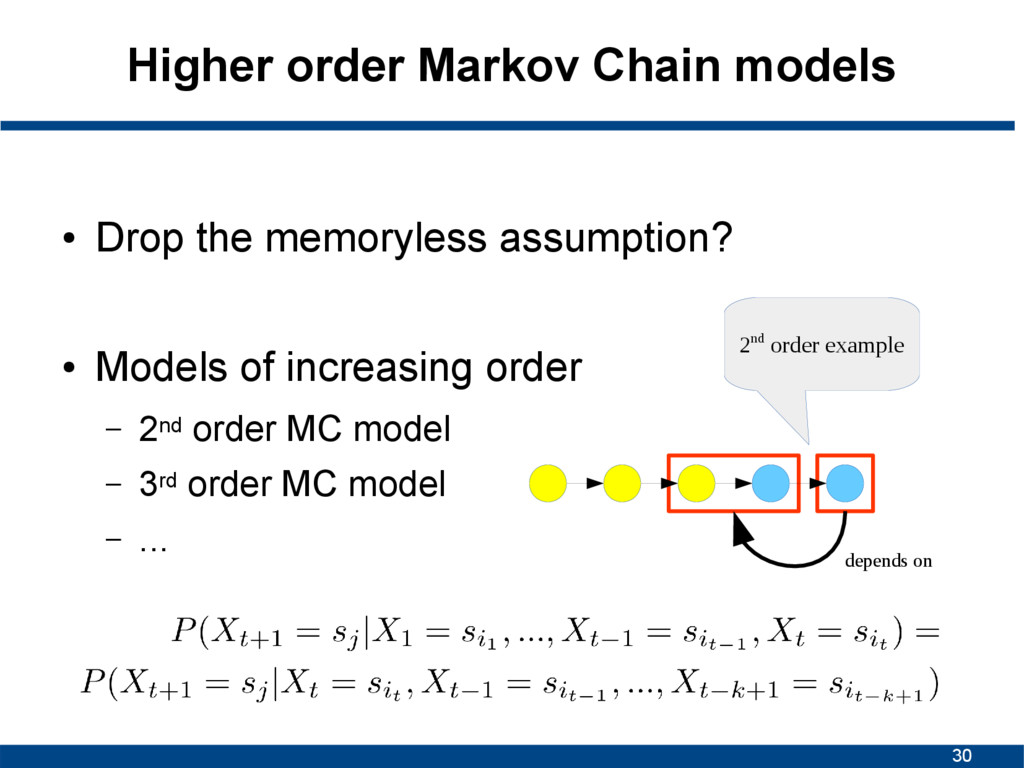
state in a sequence only depends on the current one, and not on a sequence of preceding ones S1 S1 S2 S2 S3 S3 1/2 1/2 1/3 2/3 1 States Transition probabilities
likelihoods for order m and k – Follows a Chi2 distribution with degrees of freedom – Only for nested models • Akaike Information Criterion (AIC) – – The lower the better • Bayesian Information Criterion (BIC) – • Bayes Factors – Ratio of evidences (marginal likelihoods) • Cross validation See http://journals.plos.org/plosone/articleid=10.1371/journal.pone.0102070
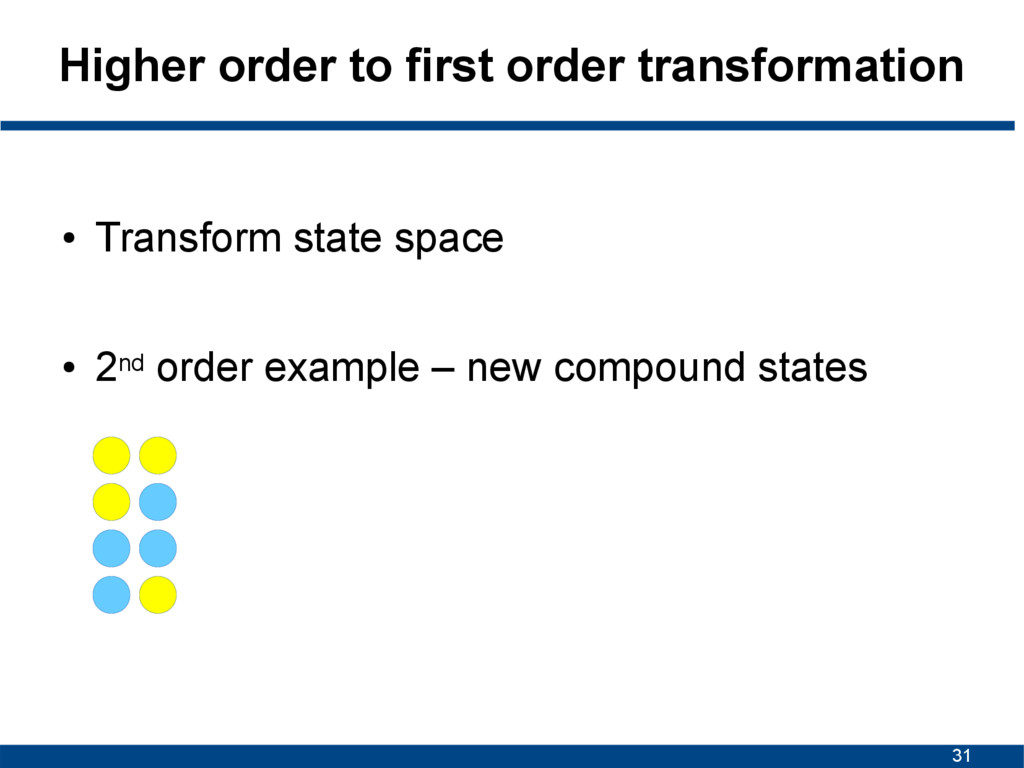
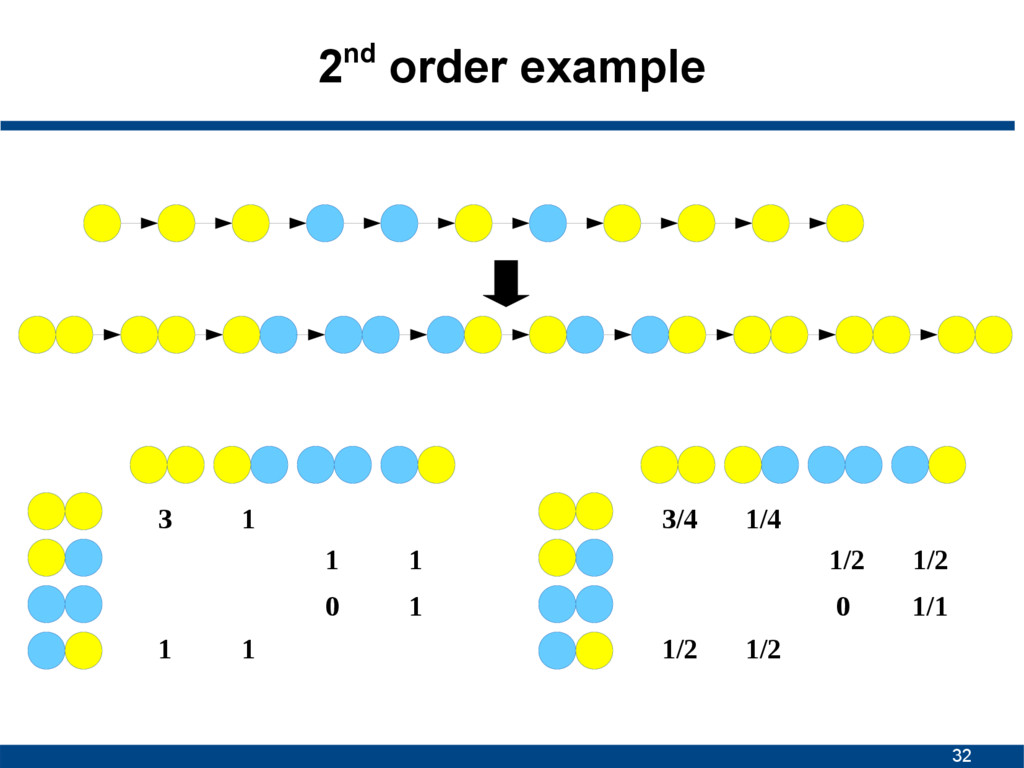
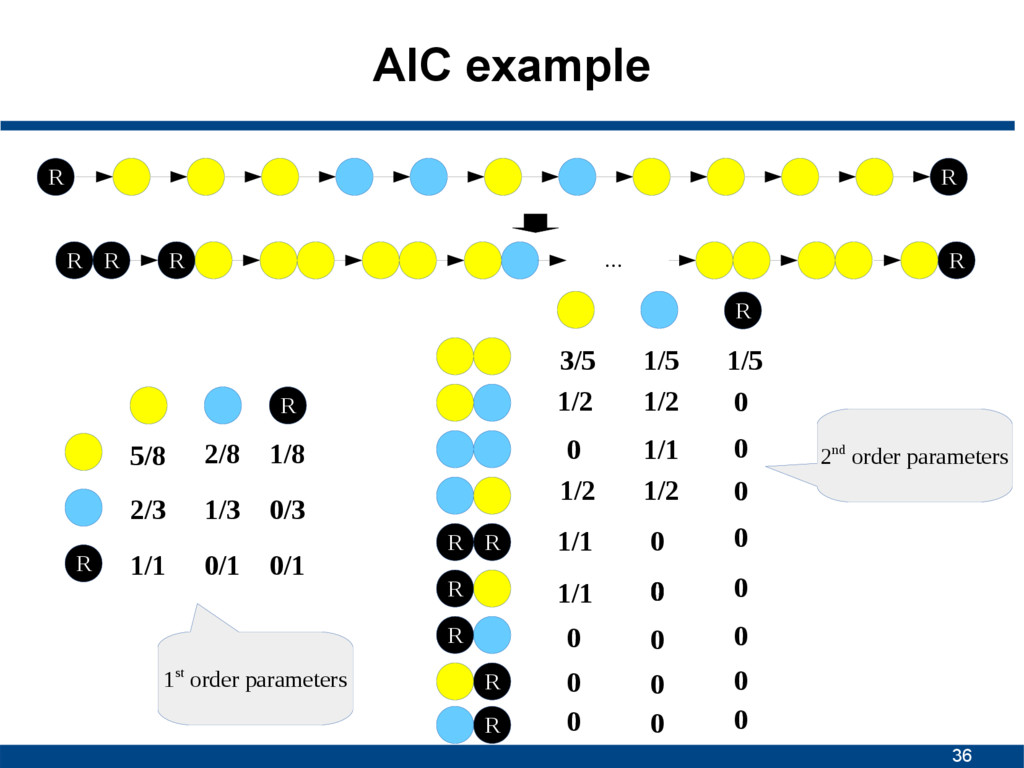
5/8 2/8 2/3 1/3 R R 1/8 0/3 1/1 0/1 0/1 3/5 1/5 1/2 1/2 0 1/2 1/2 R R R R R R R 1/5 0 1/1 0 0 1/1 0 0 1/1 0 0 0 0 0 0 0 0 0 0 0 0 0 1st order parameters 2nd order parameters
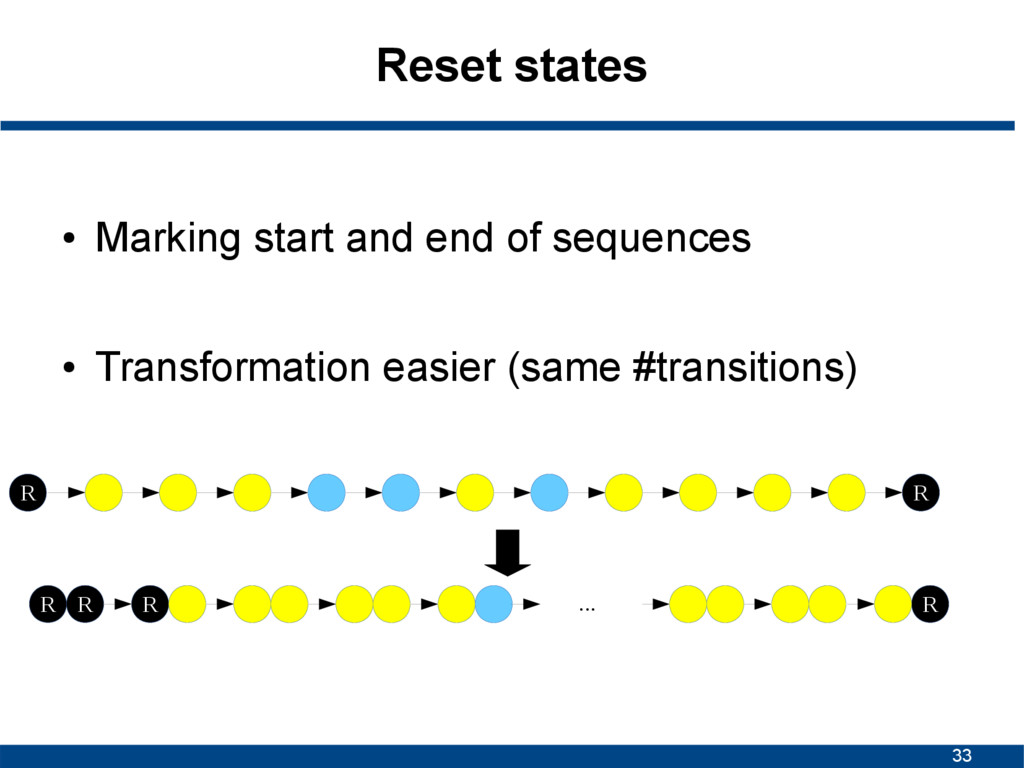
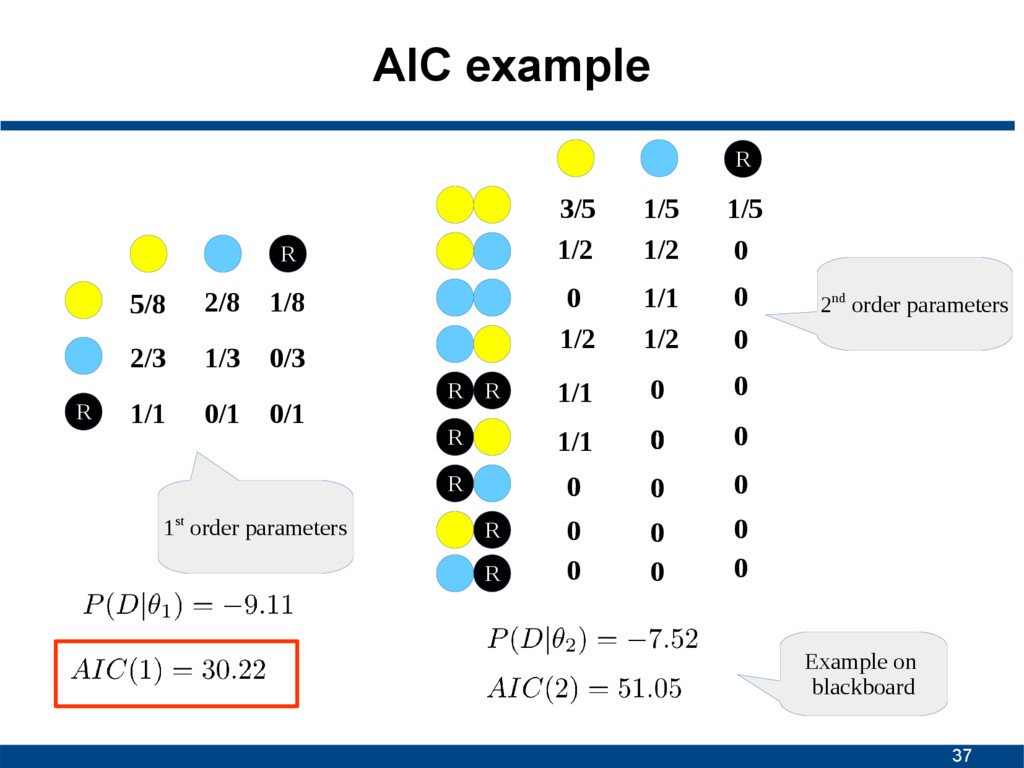
0/3 1/1 0/1 0/1 3/5 1/5 1/2 1/2 0 1/2 1/2 R R R R R R R 1/5 0 1/1 0 0 1/1 0 0 1/1 0 0 0 0 0 0 0 0 0 0 0 0 0 1st order parameters 2nd order parameters Example on blackboard
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![58 Questions? Philipp Singer [email protected]](https://files.speakerdeck.com/presentations/340646c176704d8a989b4bd57c4ef010/slide_57.jpg){kind=link}