From July 17, 2015, this is a recap of the lessons learnt from the 2015 Edge conference, featuring HTTPS, Security, Front End Data, ServiceWorker, Offline websites and more.
The server hasn’t been compromised The company is legitimate The database is secure, encrypted and safe from future intrusion Your machine isn’t compromised The connection isn’t wiretapped The security keys aren’t compromised
associate them with a level of trustworthiness which they can not represent 2. SSL certificates: a. cost money and time to obtain b. are difficult to configure on a server
callbacks • Lots of technologies available, with different features • Store flat or structured data, or file blobs • Can be queried like a database, or treated as a key-value store • Polyfils and libraries abstract away browser support issues and awkward low-level APIs
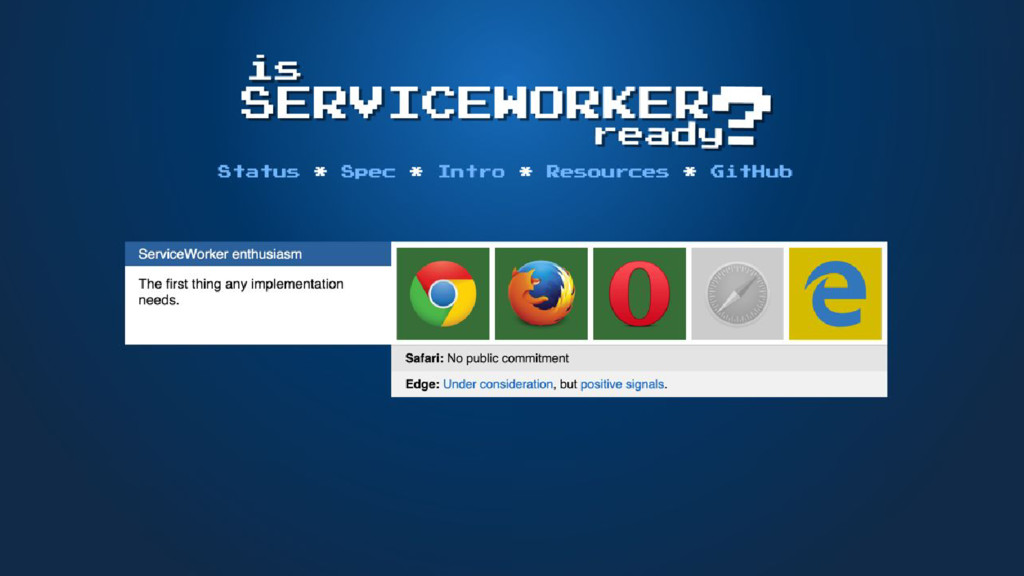
proxy - a background script with the ability to intercept and modify any request to the website • Combined with a scriptable cache, we can control how the website behaves without access to the internet
a concern for many people • No standard for managing syncs between servers and clients • Browser vendors which have implemented this have yet to make quotas and storage consumption/management transparent to users
or case studies from Amazon • Personalised comparisons against the competition works best • Filmstrip views from WebPageTest are great because they’re visual • Filmstrip functionality is coming in DevTools soon(?) • https://speedcurve.com/ is a paid-for, client-centric version of WebPageTest
network activity - but should it indicate content interactivity instead? • Would it help or hinder developers, and would it be beneficial for users? • Would it make the browser seem faster or slower? • To whom does the user attribute blame for janky content, stutters and poor performance?
ago (the first Edge Conference), but no closer to general adoption outside of specific frameworks. • [Browser vendors] can’t agree on standards to implement, which requires extensive libraries to support, and each of them has to reinvent the wheel with a virtual DOM • Frankly, it’s still too underexplored for a standard to emerge yet - many implementations are too specialised to be generally useful
even agree what it means and have a focussed discussion on it without repeatedly trying to define it • It’s not just about ‘making it work without JavaScript’ • It’s not about accessible content (or is it?) • What’s the starting point? Is the lowest common denominator too low?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}