Description
In this talk, we present the new Python SDK for Apache Beam - a parallel programming model that allows one to implement batch and streaming data processing jobs that can run on a variety of execution engines like Apache Spark and Google Cloud Dataflow.
Abstract
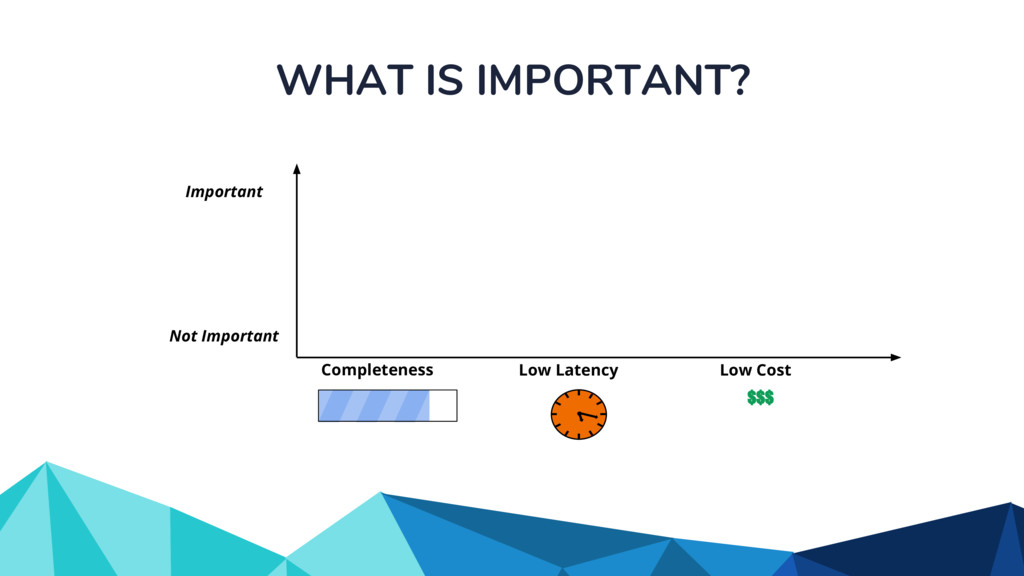
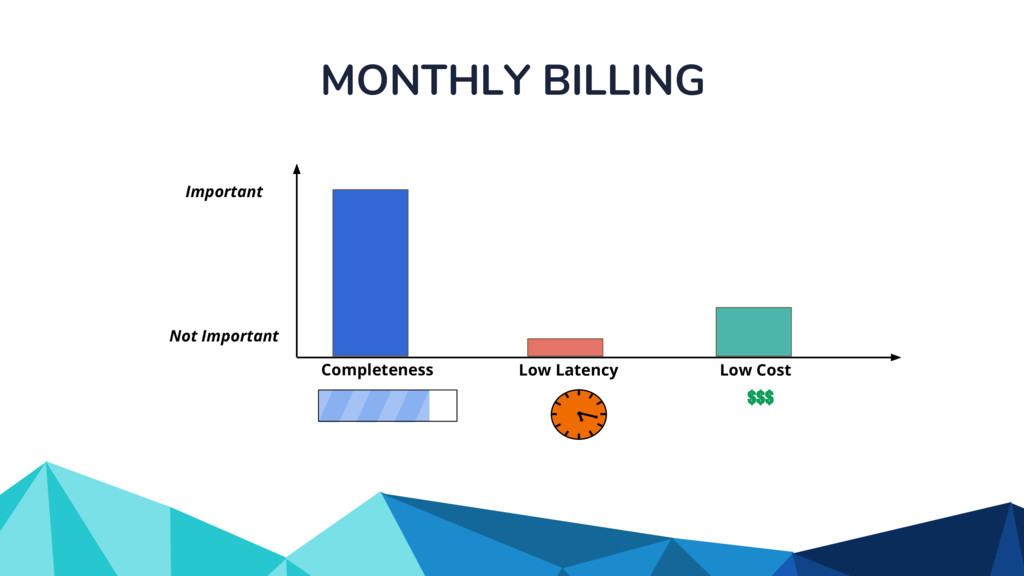
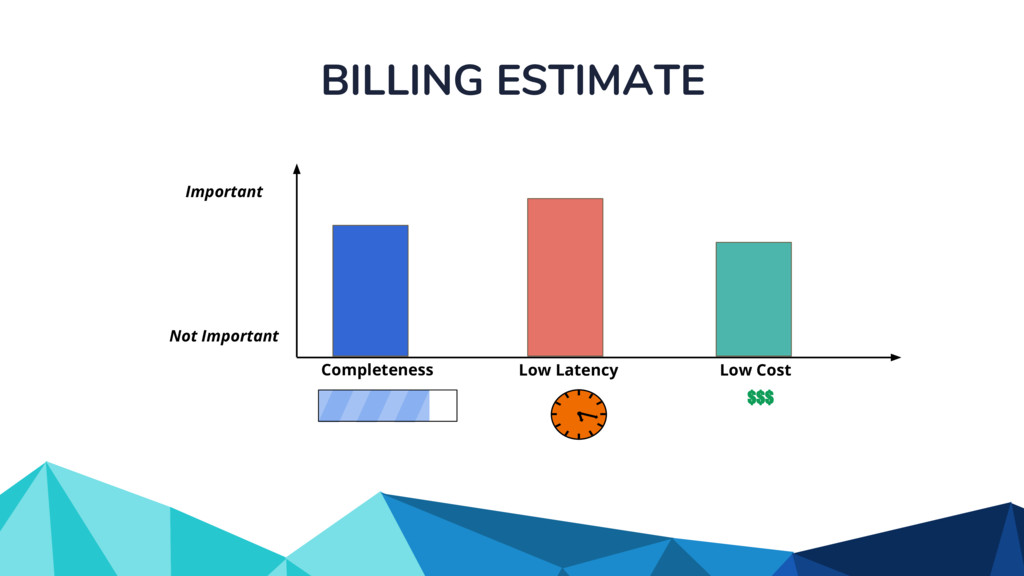
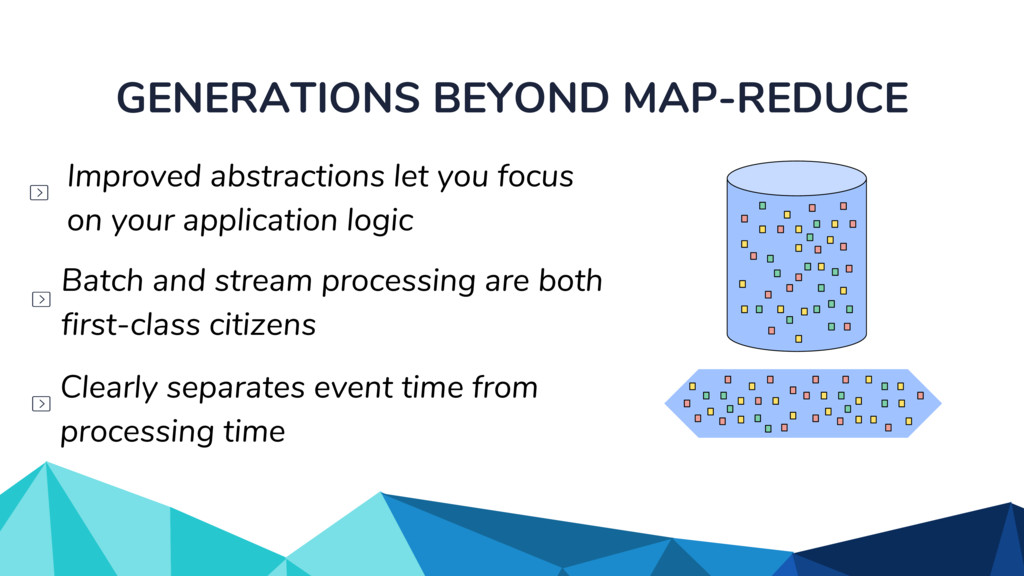
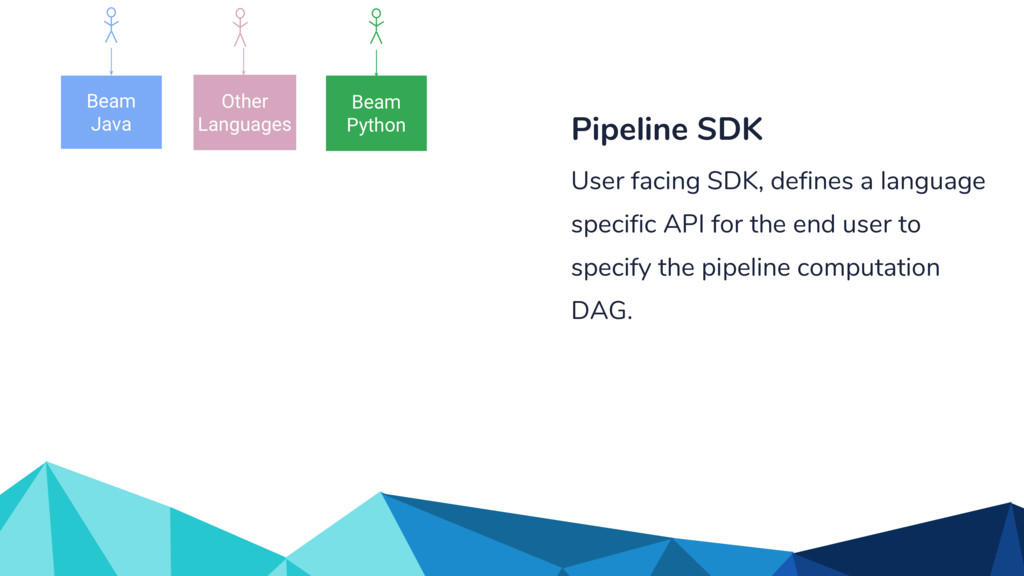
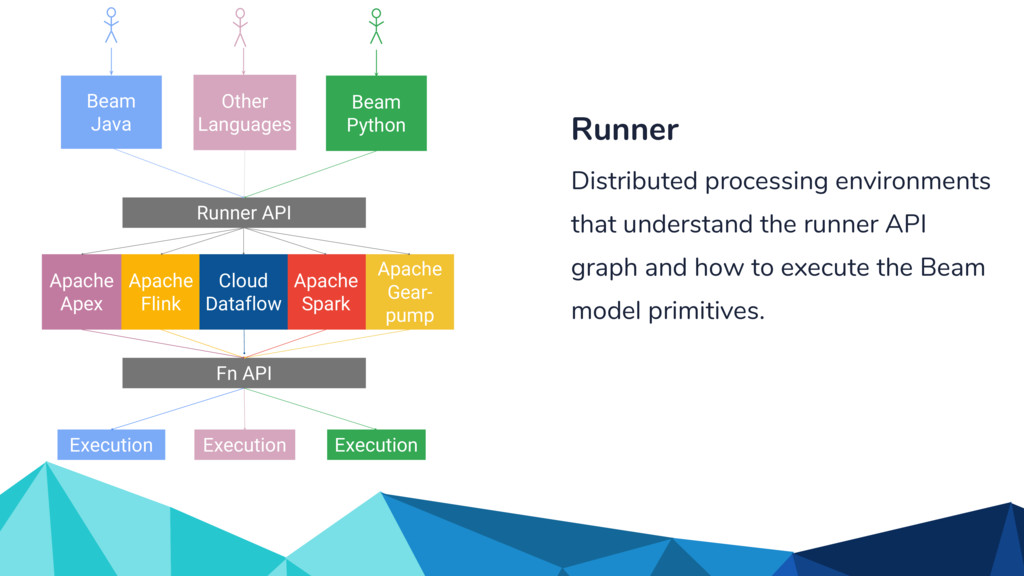
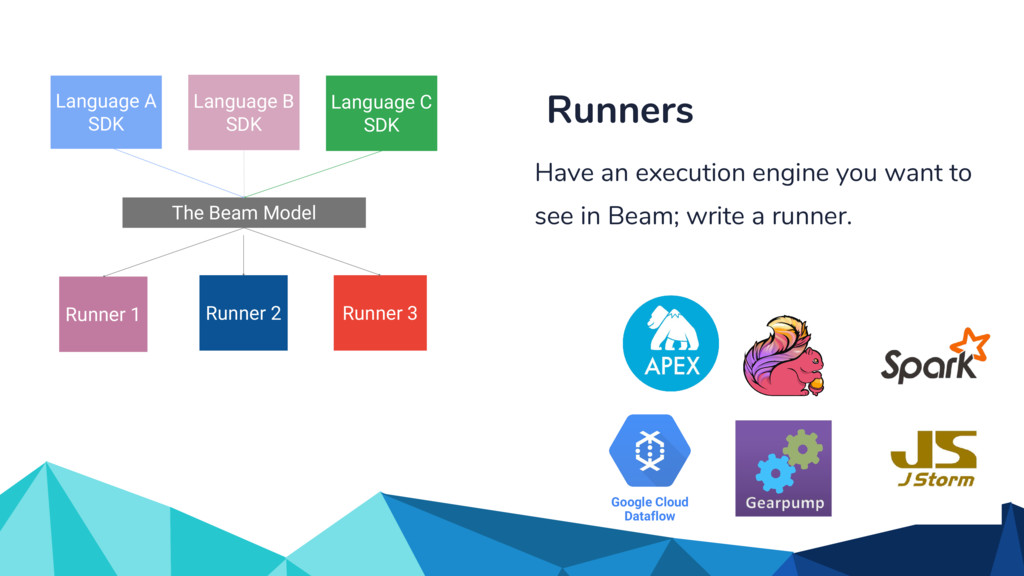
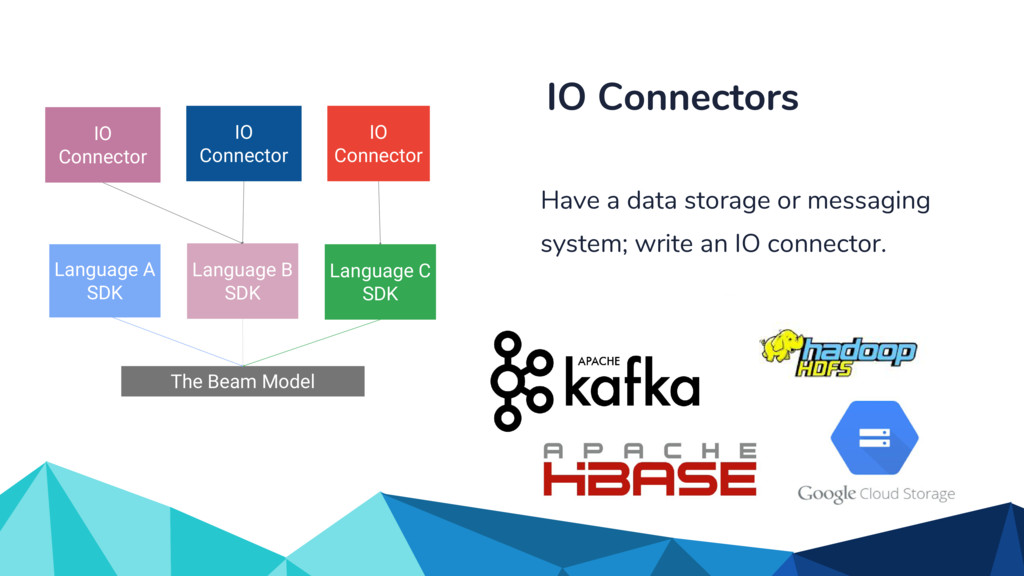
Currently, some popular data processing frameworks such as Apache Spark consider batch and stream processing jobs independently. The APIs across different processing systems such as Apache Spark or Apache Flink are also different. This forces the end user to learn a potentially new system every time. Apache Beam [1] addresses this problem by providing a unified programming model that can be used for both batch and streaming pipelines. The Beam SDK allows the user to execute these pipelines against different execution engines. Currently, Apache Beam provides a Java and Python SDK.
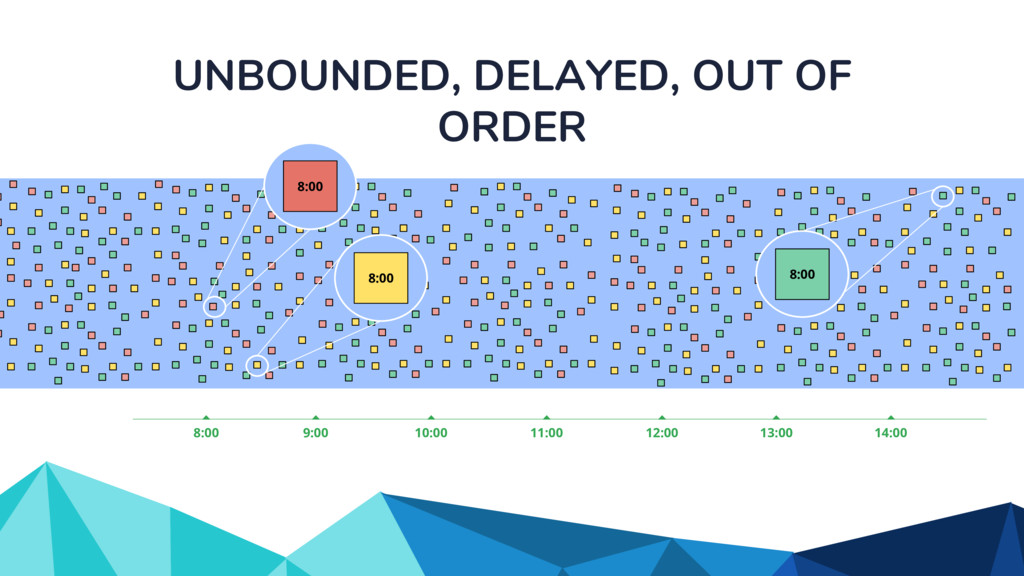
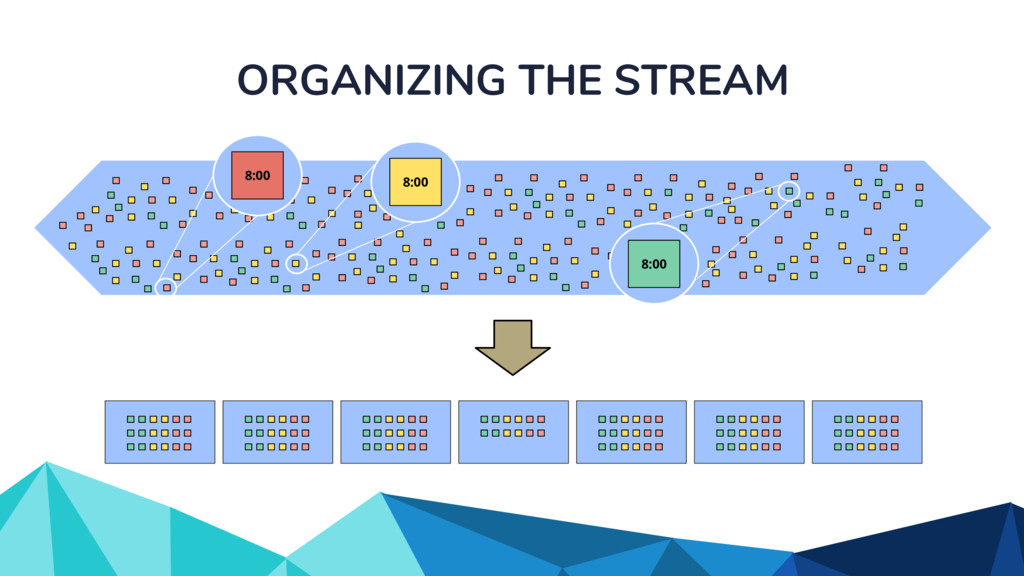
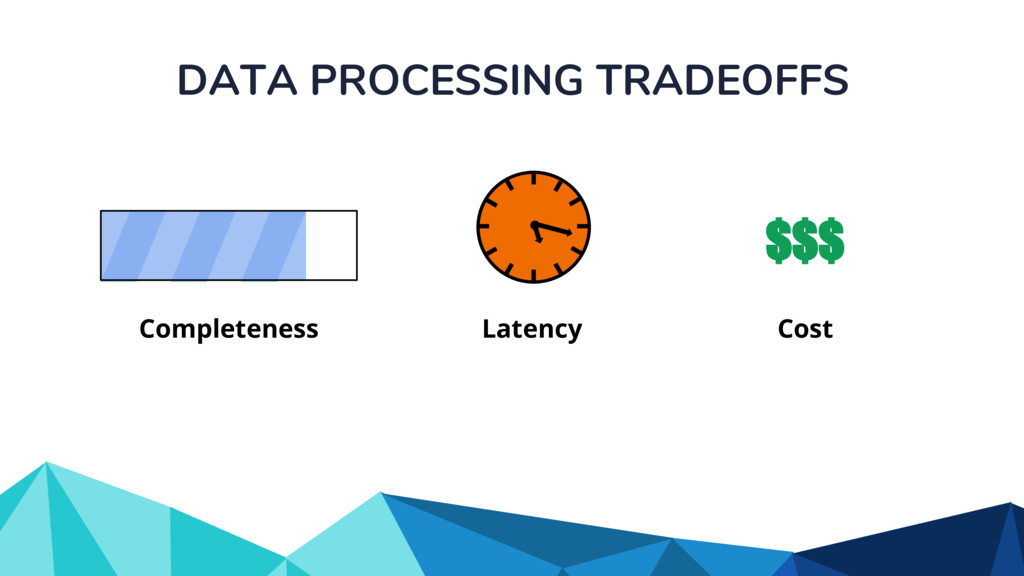
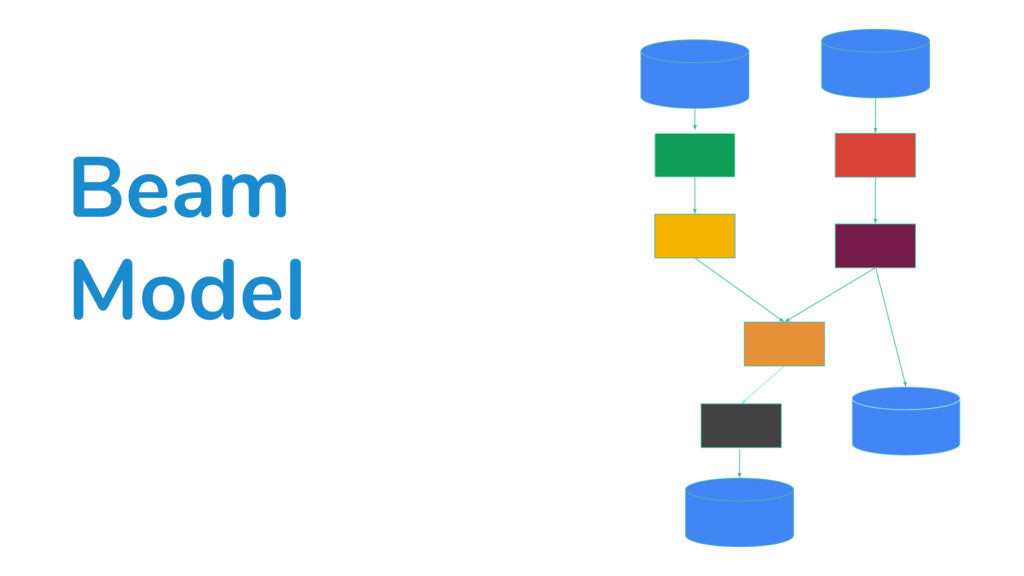
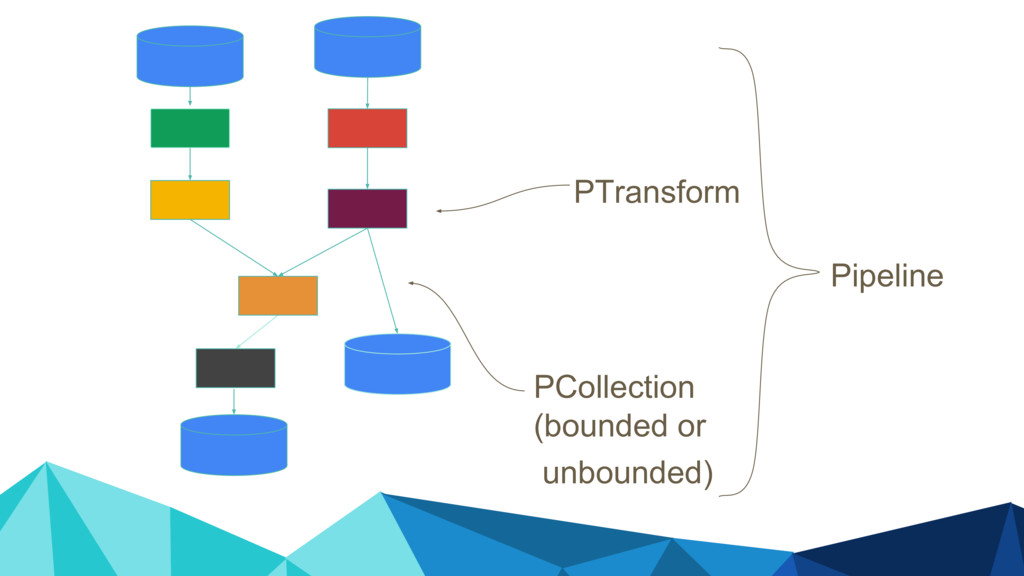
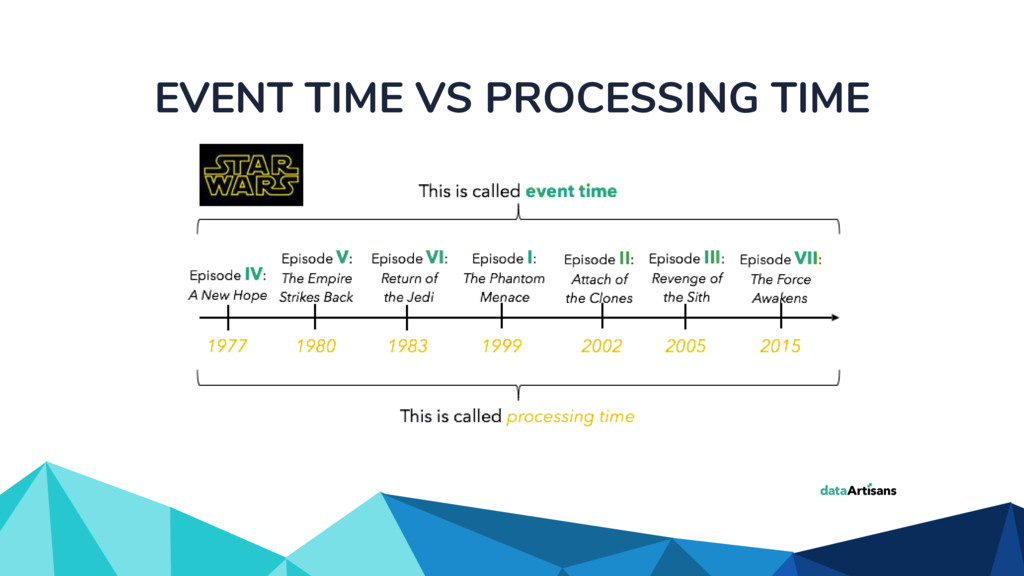
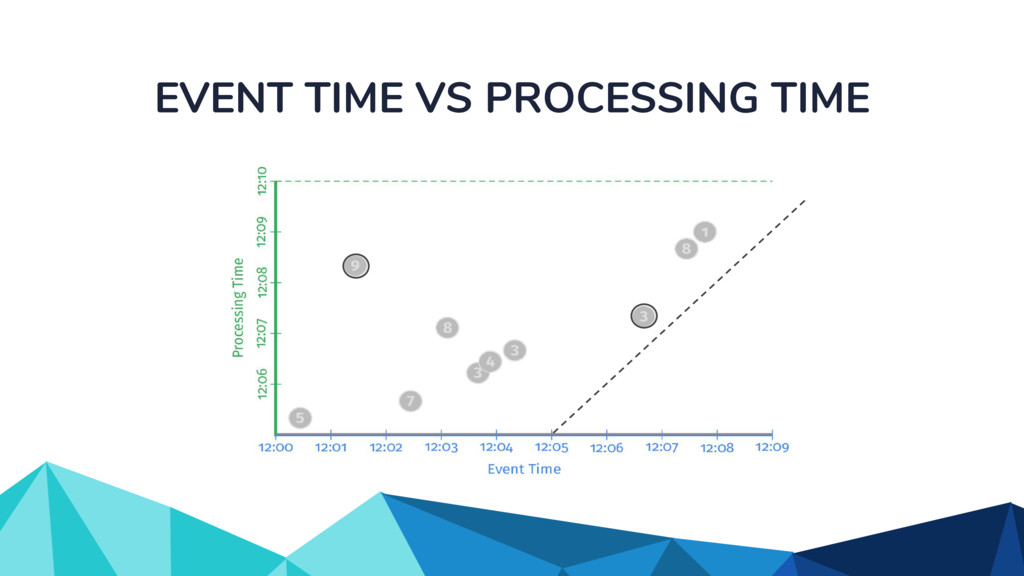
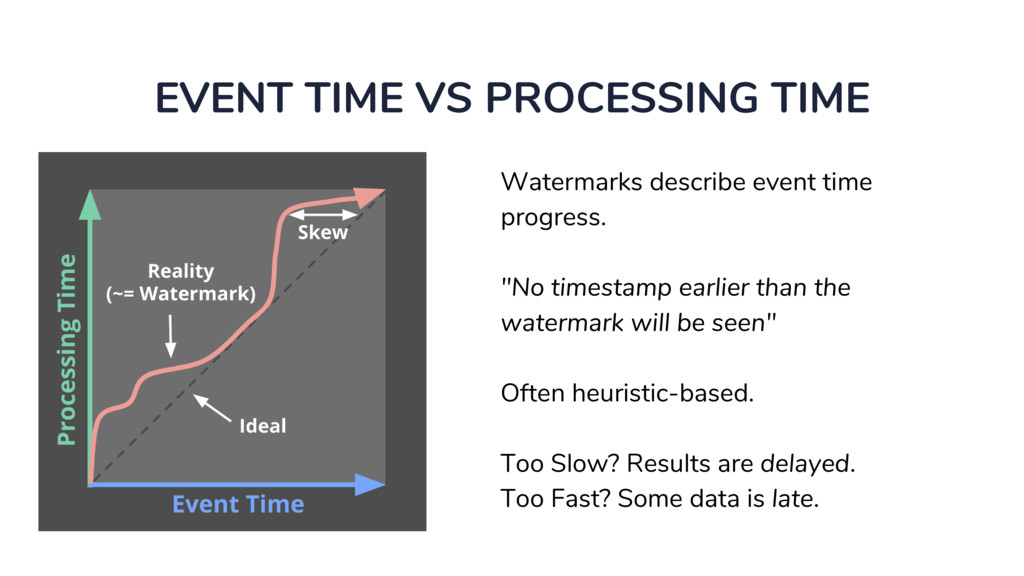
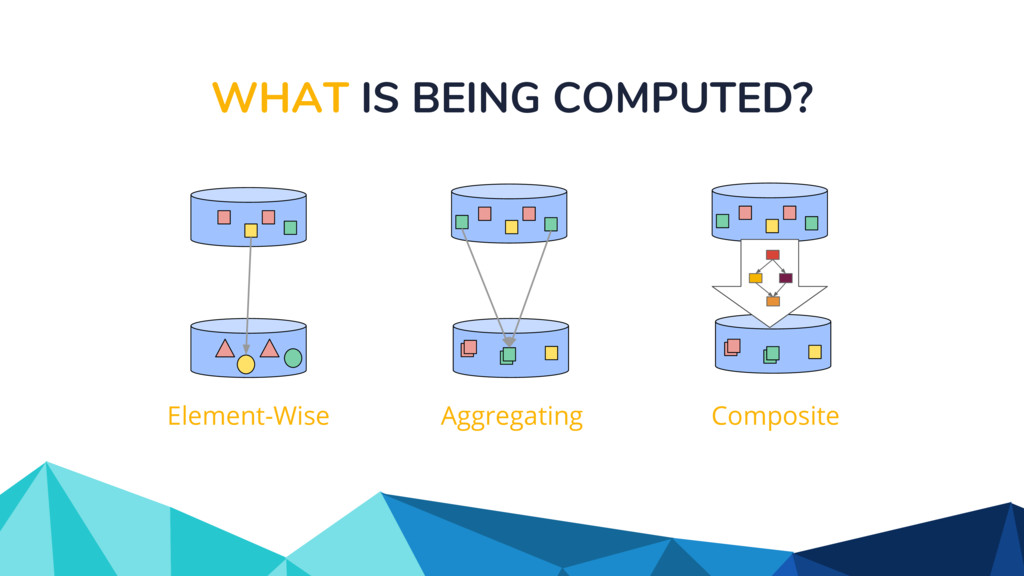
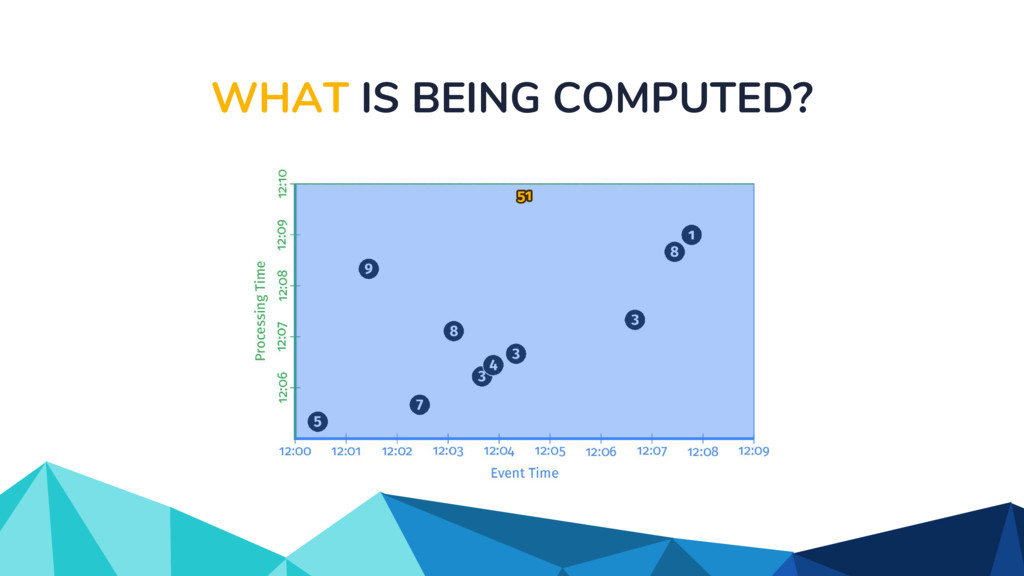
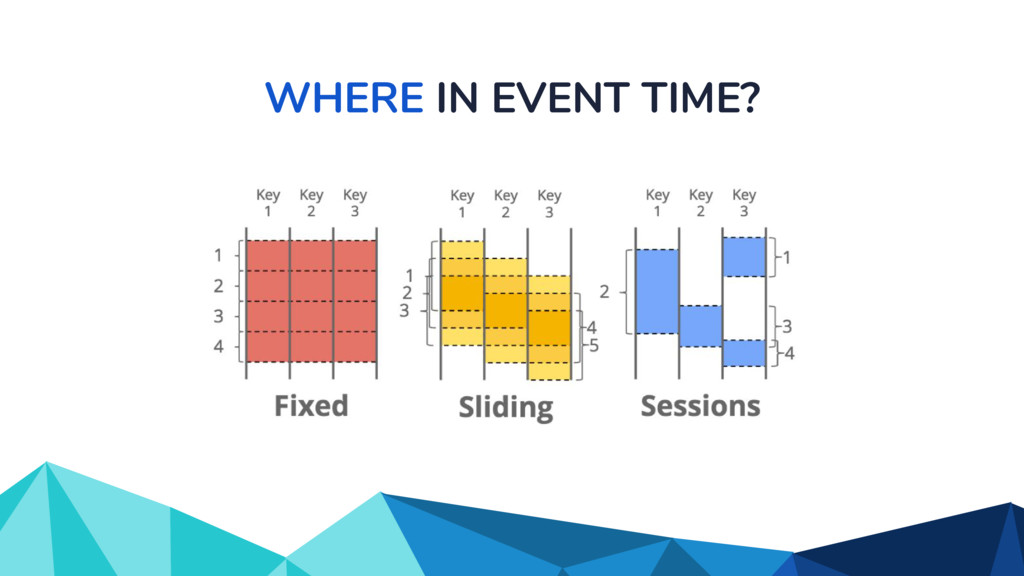
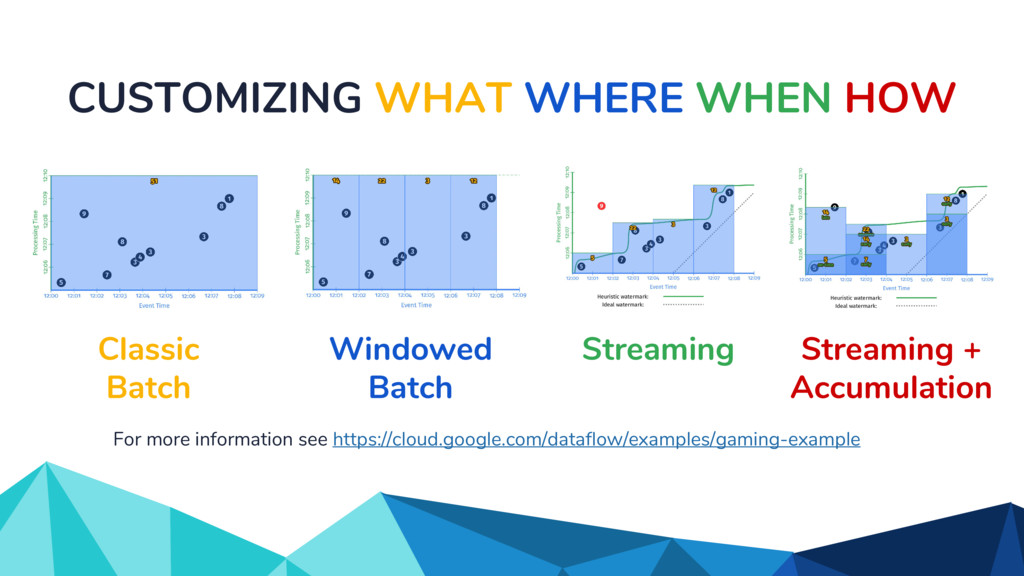
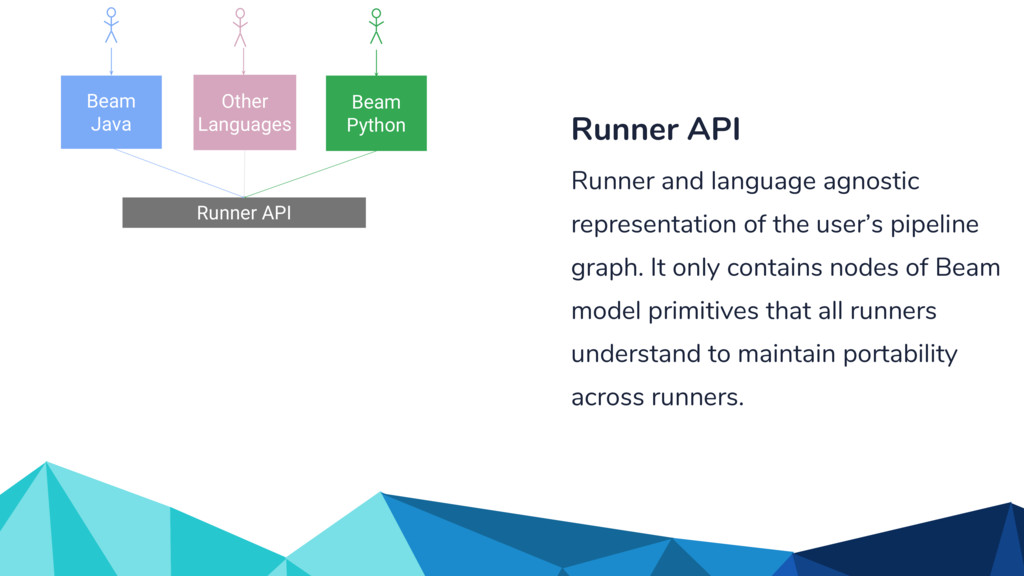
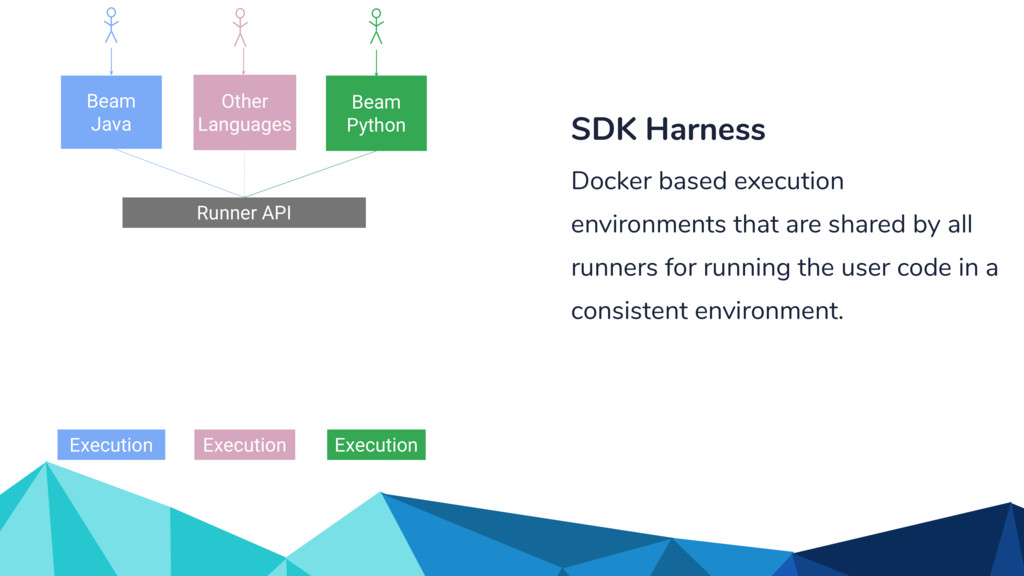
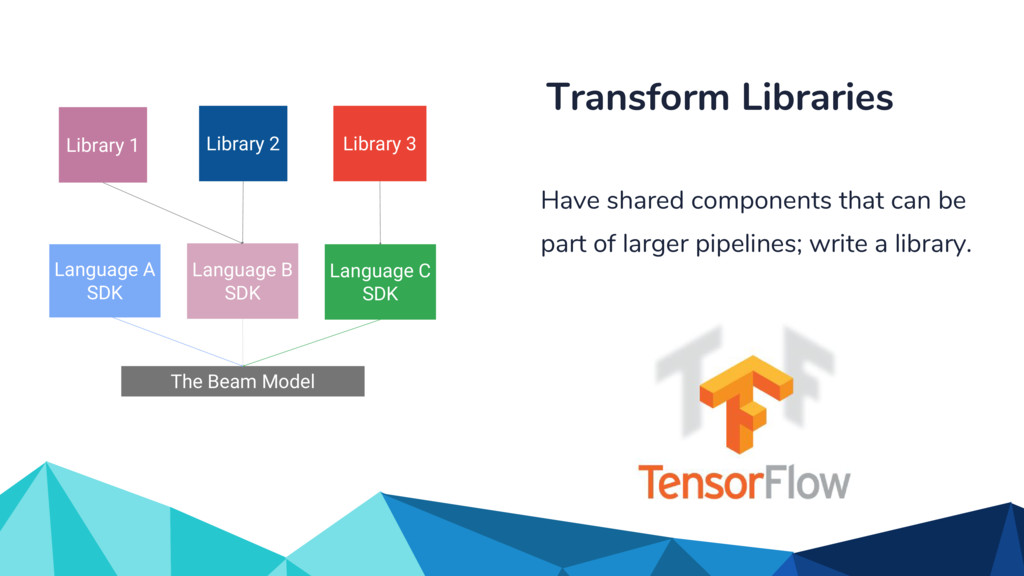
In the talk, we start off by providing an overview of Apache Beam using the Python SDK and the problems it tries to address from an end user’s perspective. We cover the core programming constructs in the Beam model such as PCollections, ParDo, GroupByKey, windowing, and triggers. We describe how these constructs make it possible for pipelines to be executed in a unified fashion in both batch and streaming. Then we use examples to demonstrate these capabilities. The examples showcase using Beam for stream processing and real-time data analysis, and how Beam can be used for feature engineering in some Machine Learning applications using Tensorflow. Finally, we end with Beam's vision of creating runner and execution independent graphs using the Beam FnApi [2].
Apache Beam [1] is a top-level Apache project and is completely open source. The code for Beam can be found on Github [3].
[1] https://beam.apache.org/ [2] http://s.apache.org/beam-fn-api [3] https://github.com/apache/beam
Bio
Sourabh is a software engineer at Google interested in Data Infrastructure and Machine Learning. He currently works on Apache Beam. Prior to Google he was part of the Data Science team at Coursera working on everything from Recommendation System to Data warehousing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WHAT IS BEING COMPUTED? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/b51eba00fa6e4534921ec9d2f9982ae0/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![WHERE IN EVENT TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/b51eba00fa6e4534921ec9d2f9982ae0/slide_27.jpg){kind=link}
{kind=link}
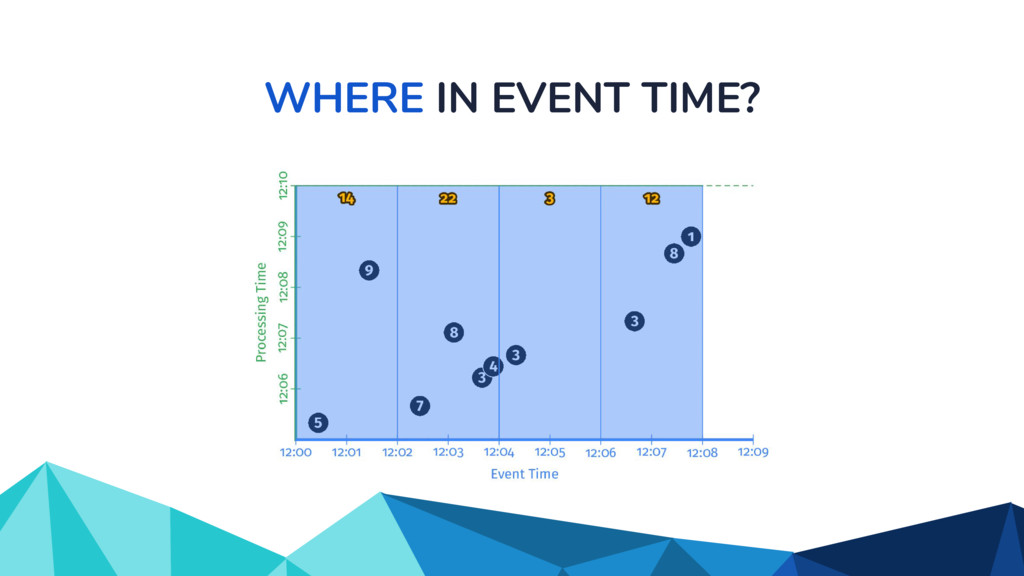{kind=link}
![WHERE IN EVENT TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/b51eba00fa6e4534921ec9d2f9982ae0/slide_30.jpg){kind=link}
![WHEN IN PROCESSING TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/b51eba00fa6e4534921ec9d2f9982ae0/slide_31.jpg){kind=link}
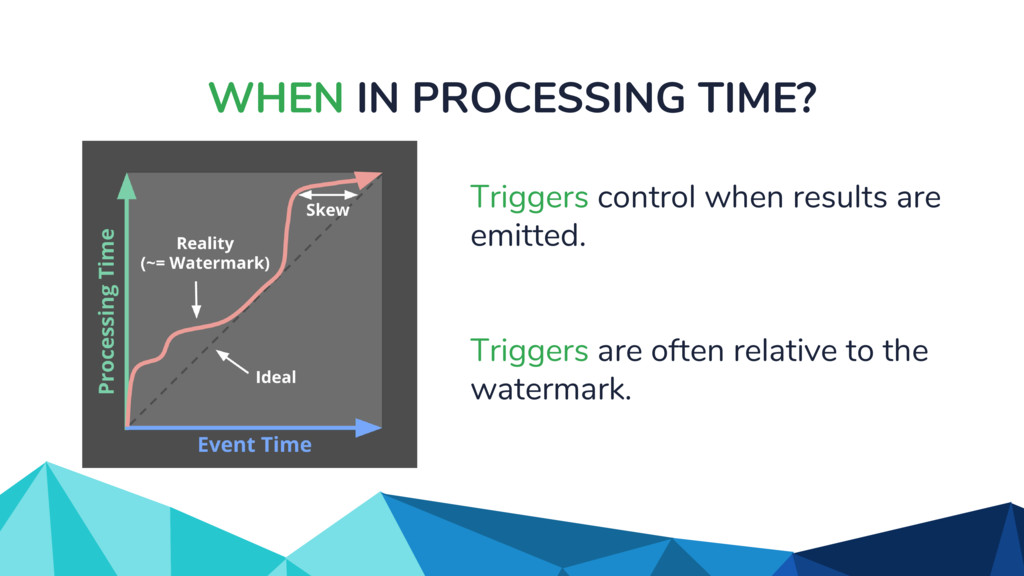{kind=link}
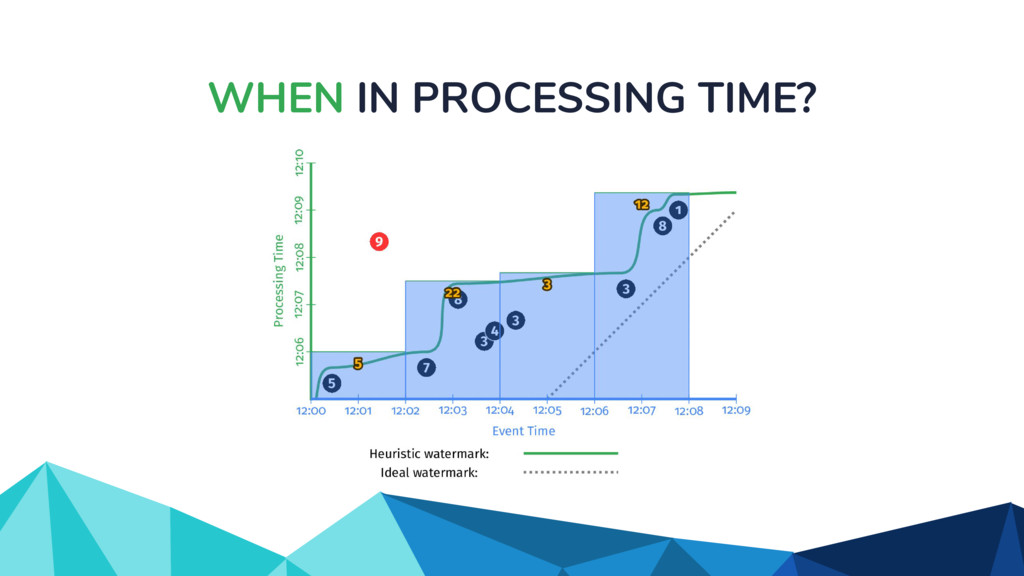{kind=link}
![HOW DO REFINEMENTS HAPPEN? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/b51eba00fa6e4534921ec9d2f9982ae0/slide_34.jpg){kind=link}
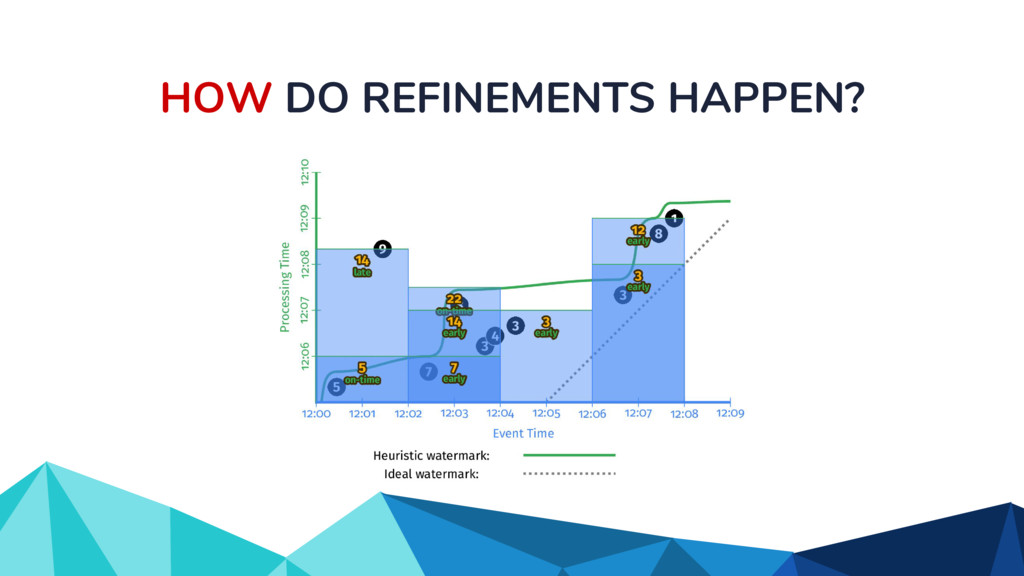{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}