В докладе будет попытка рассказать про хождение по граблям в различных СУБД, с которыми докладчик работал на протяжении своей карьеры. Попробуем ответить на вопросы:
* Какие особенности работы СУБД должен знать программист, чтобы лучше ориентироваться в ситуации „ой, у нас все сломалось“?
* Как вообще выбрать базу данных для нового проекта?
* Как лучше комбинировать разные СУБД?
* Стоит ли переносить бизнес-логику в СУБД?
* ORM vs Plain SQL vs NoSQL для простых смертных
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
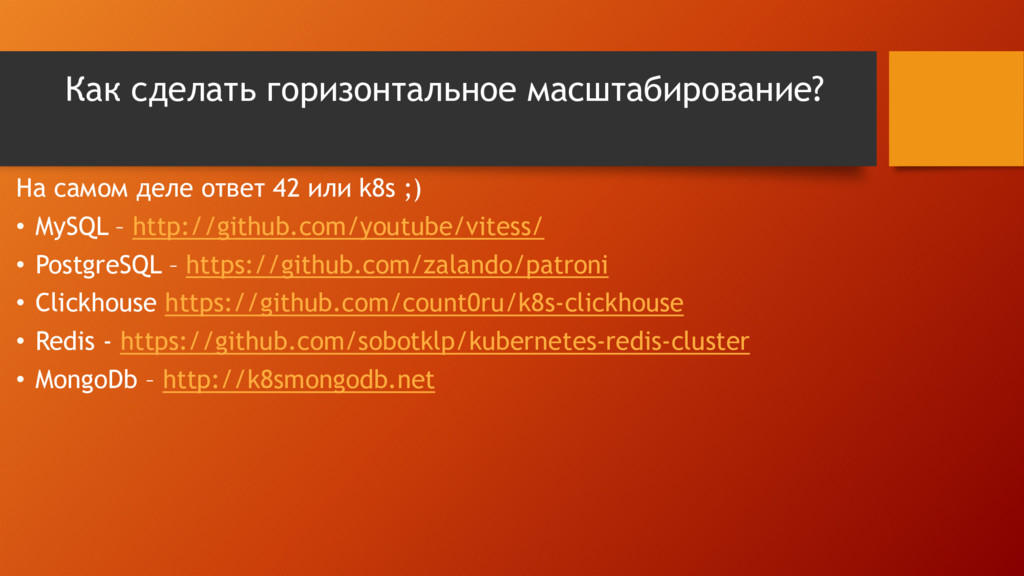{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
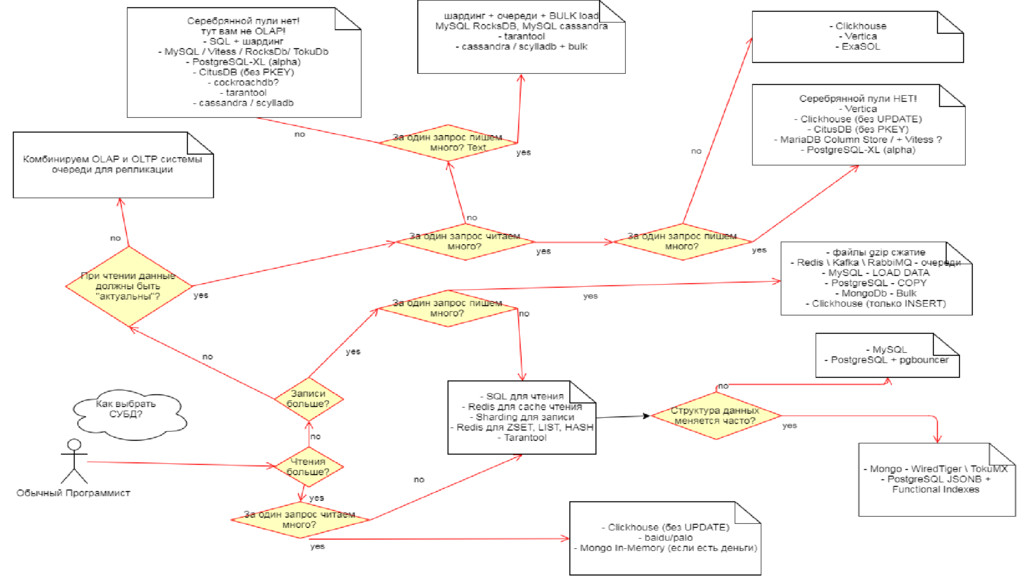{kind=link}
{kind=link}
{kind=link}
{kind=link}