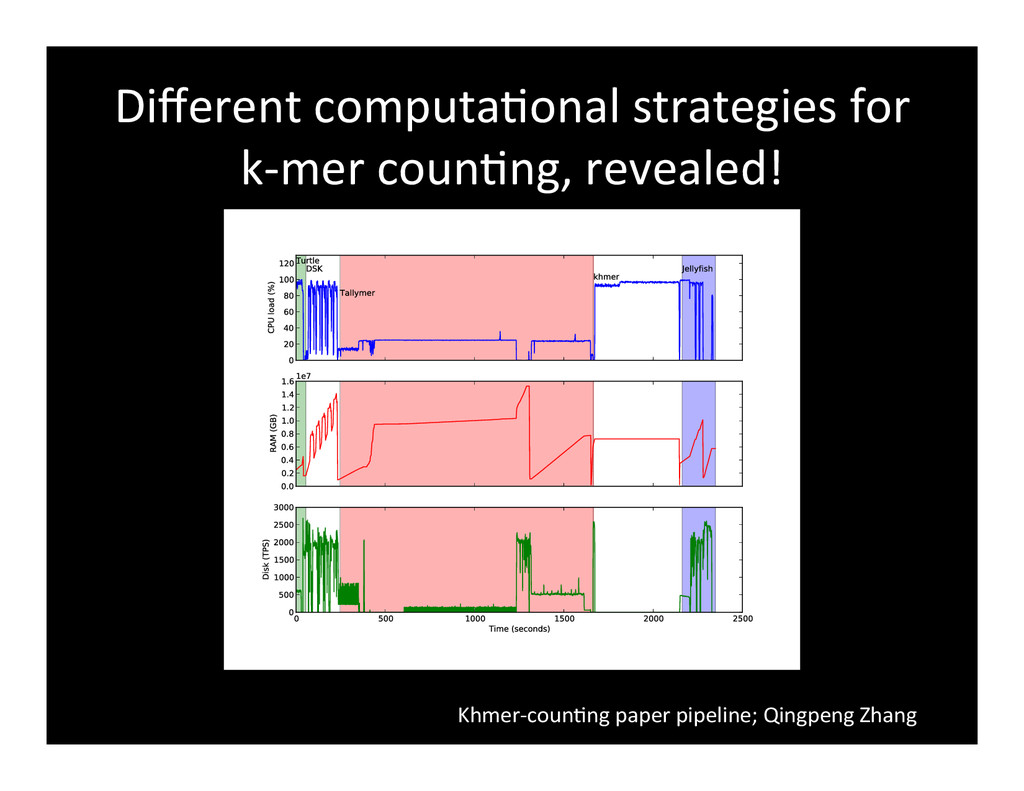
Cloud computing offers some great opportunities for science, but most cloud computing platforms are I/O and memory limited, and hence are poor matches for data-intensive computing. After 4 years of research software development we are now instrumenting and benchmarking our analysis pipelines; numbers, lessons learned, and future plans will be discussed. Everything is open source.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
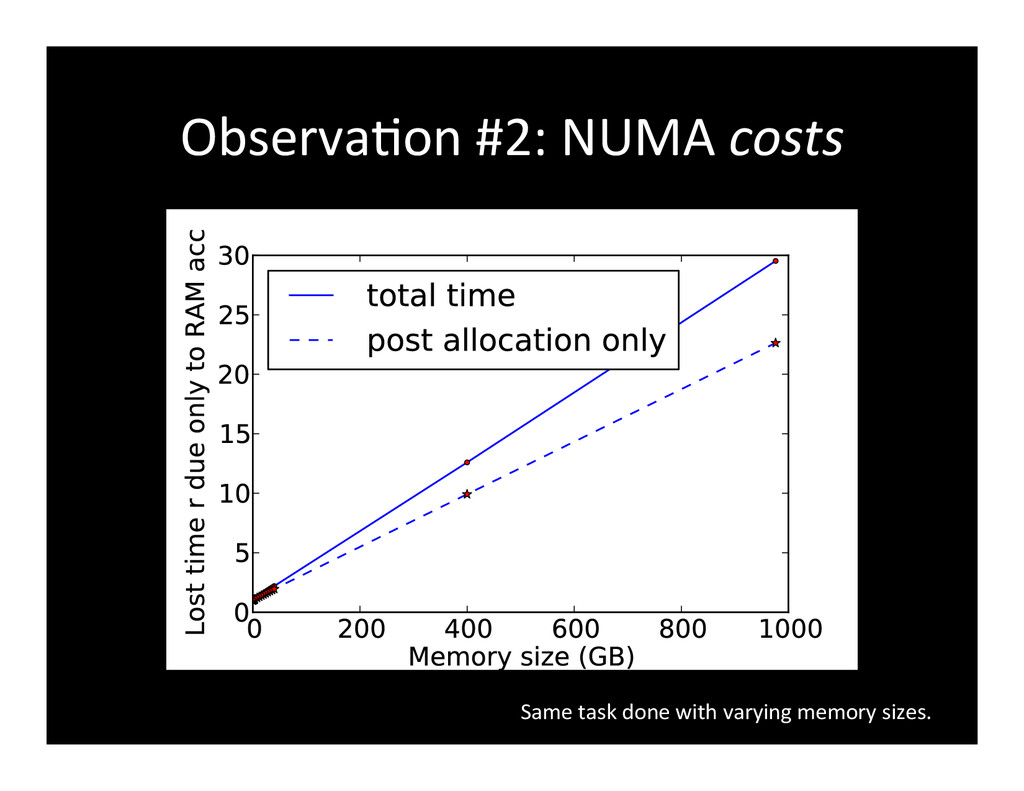{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
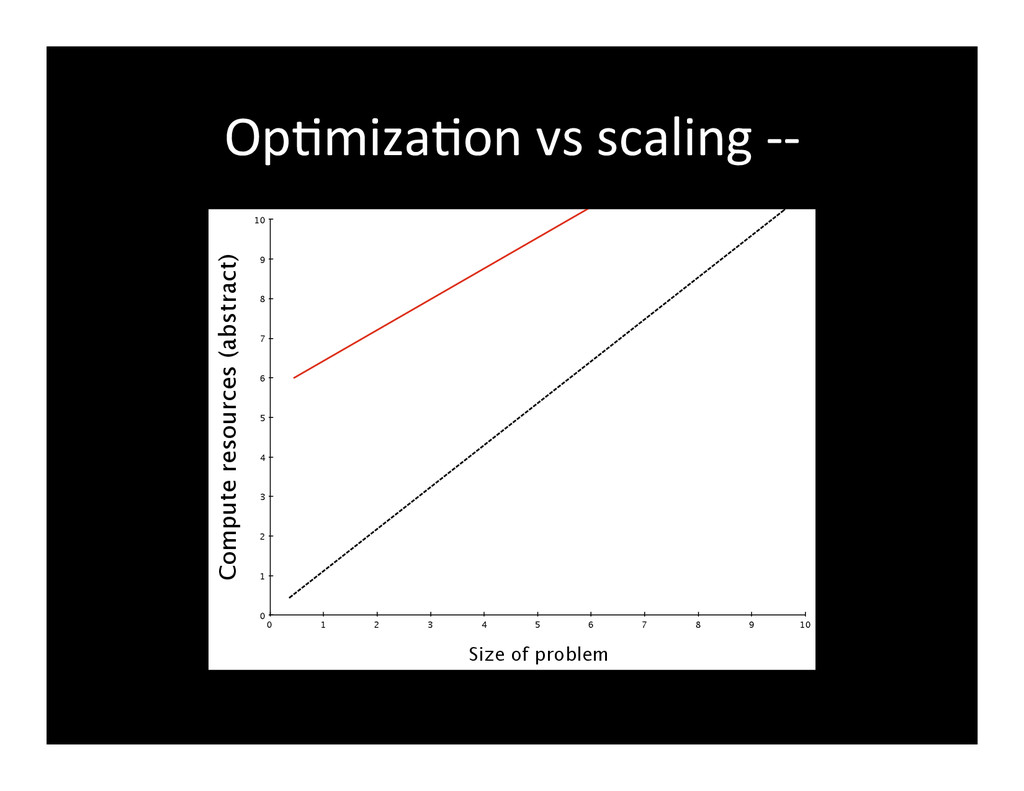{kind=link}
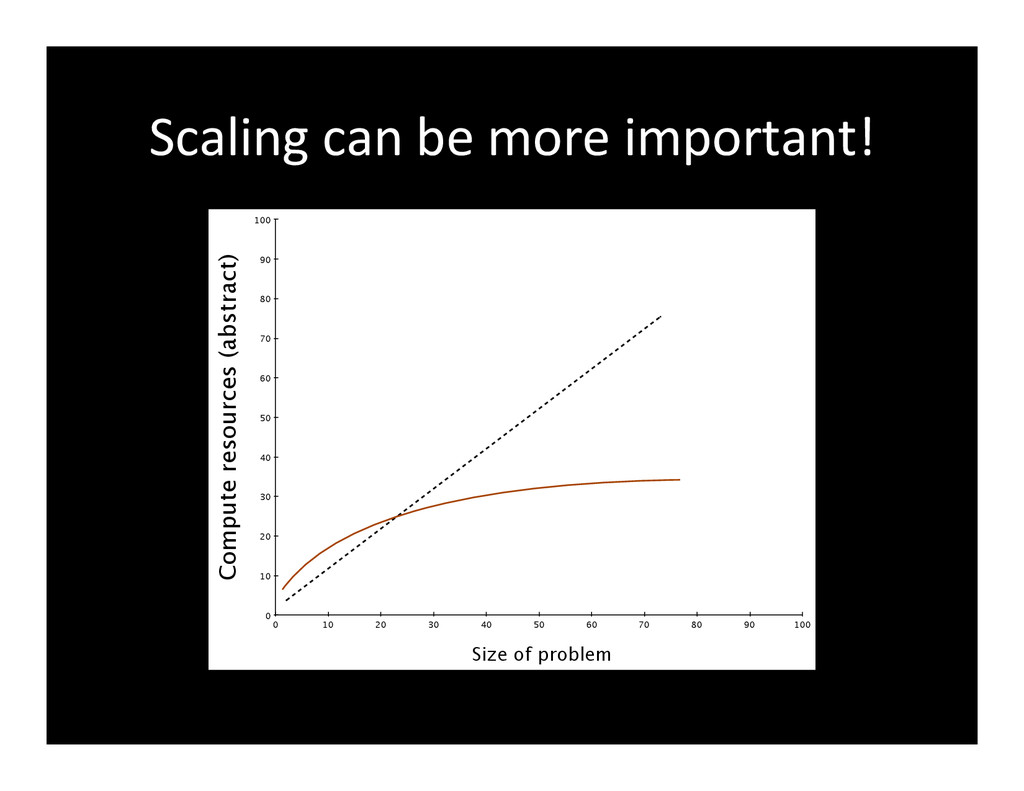{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}