A walk-through of how we practically clean and use a public dataset that is changing people's lives.
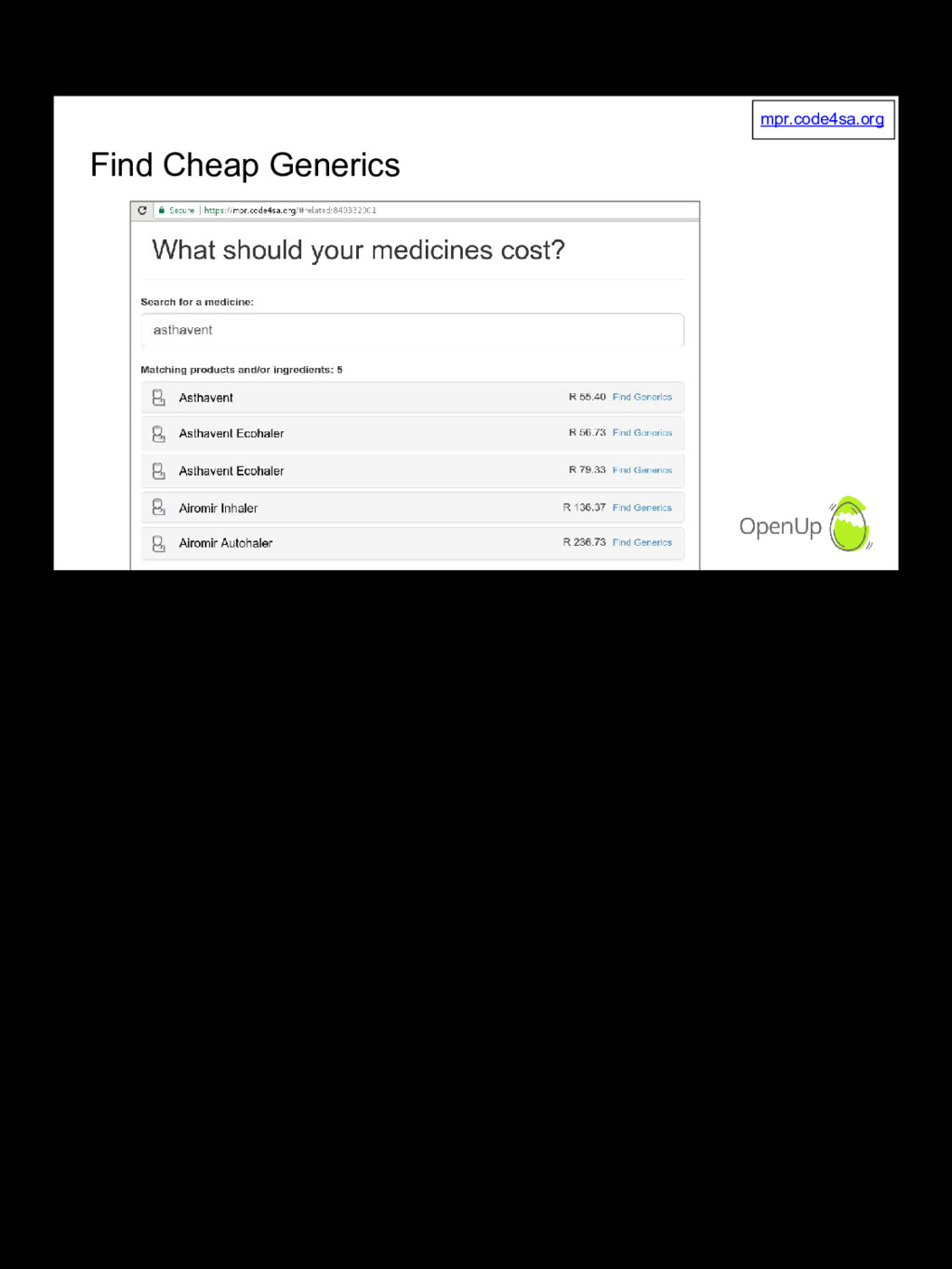
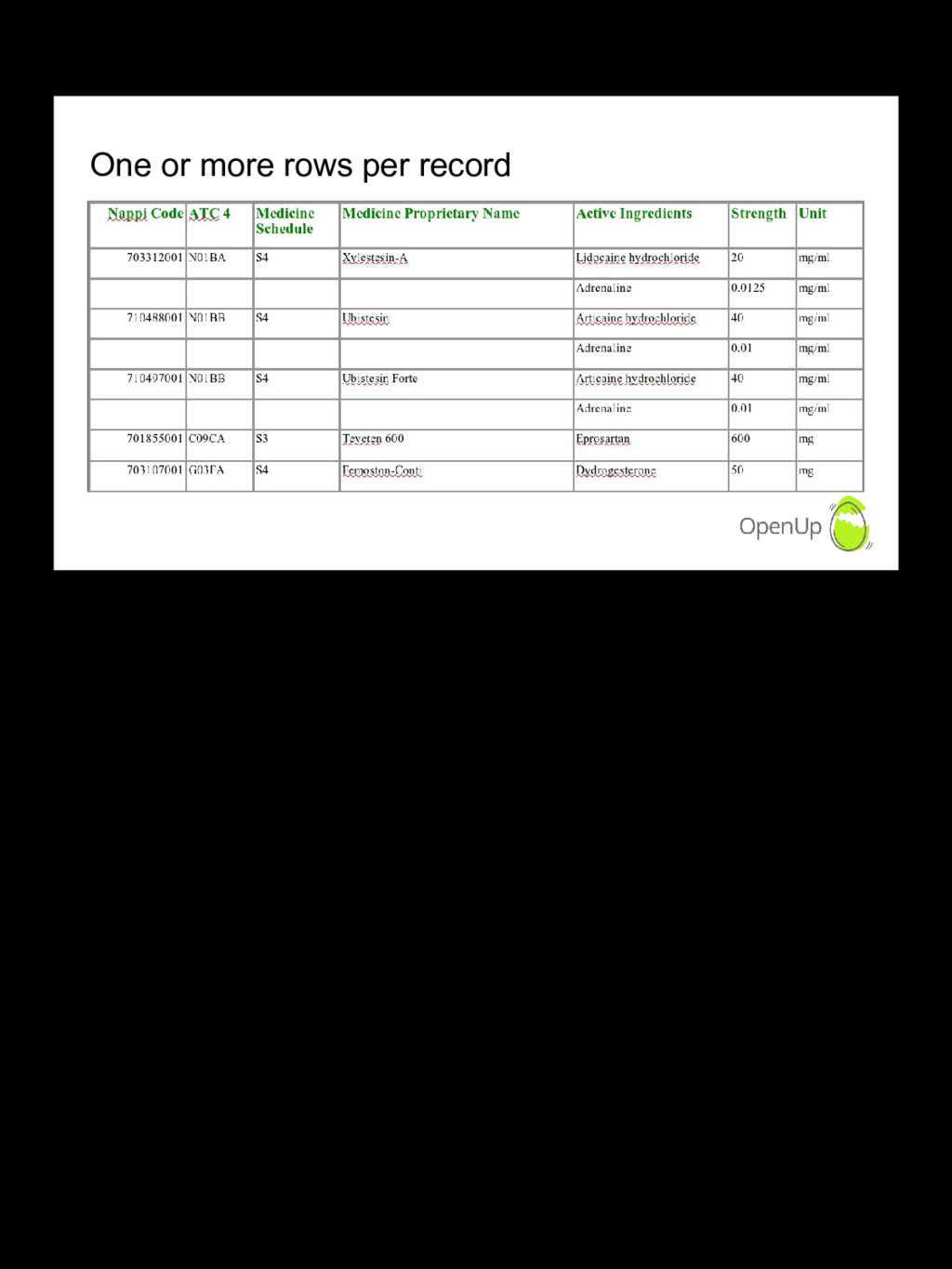
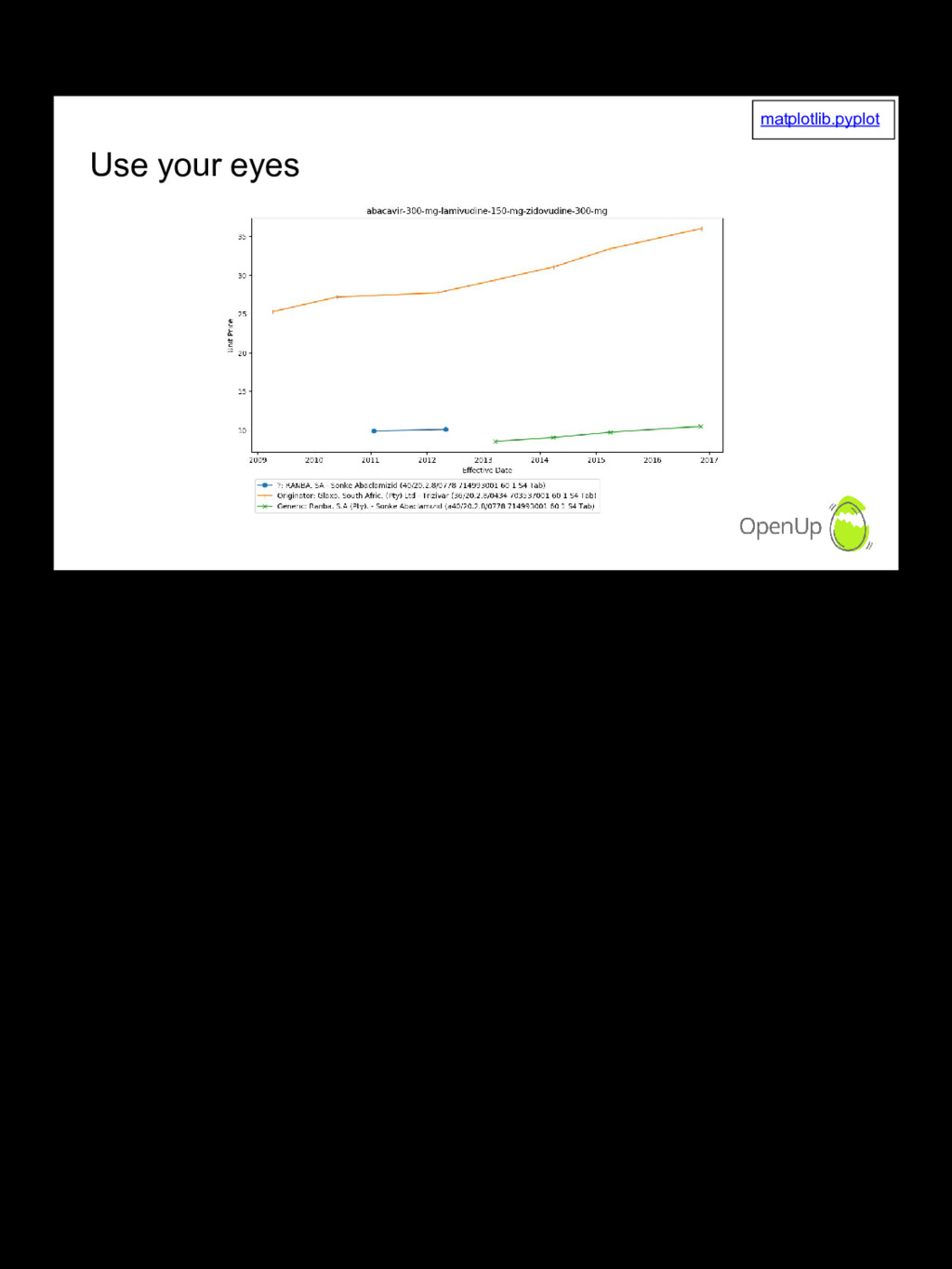
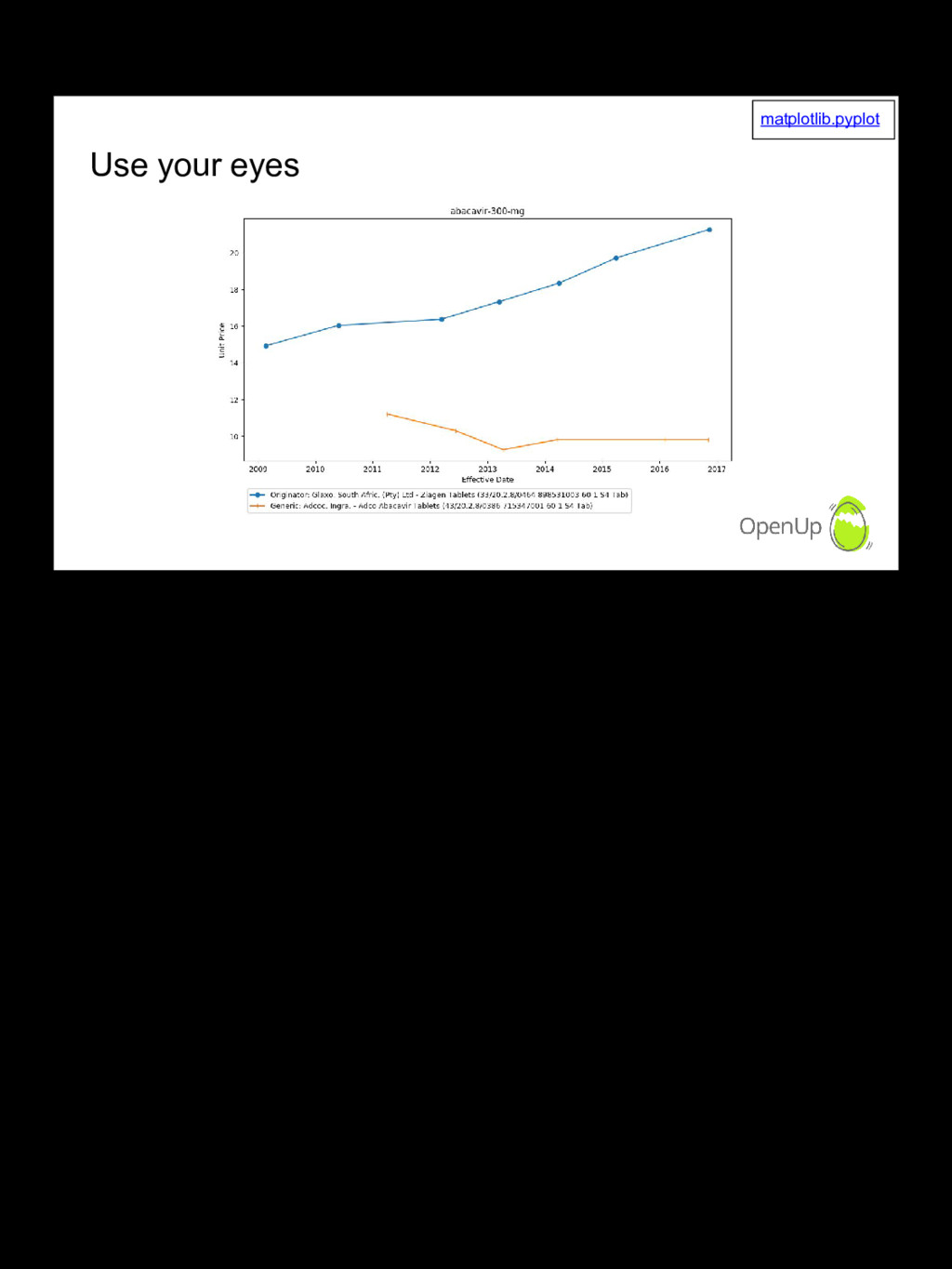
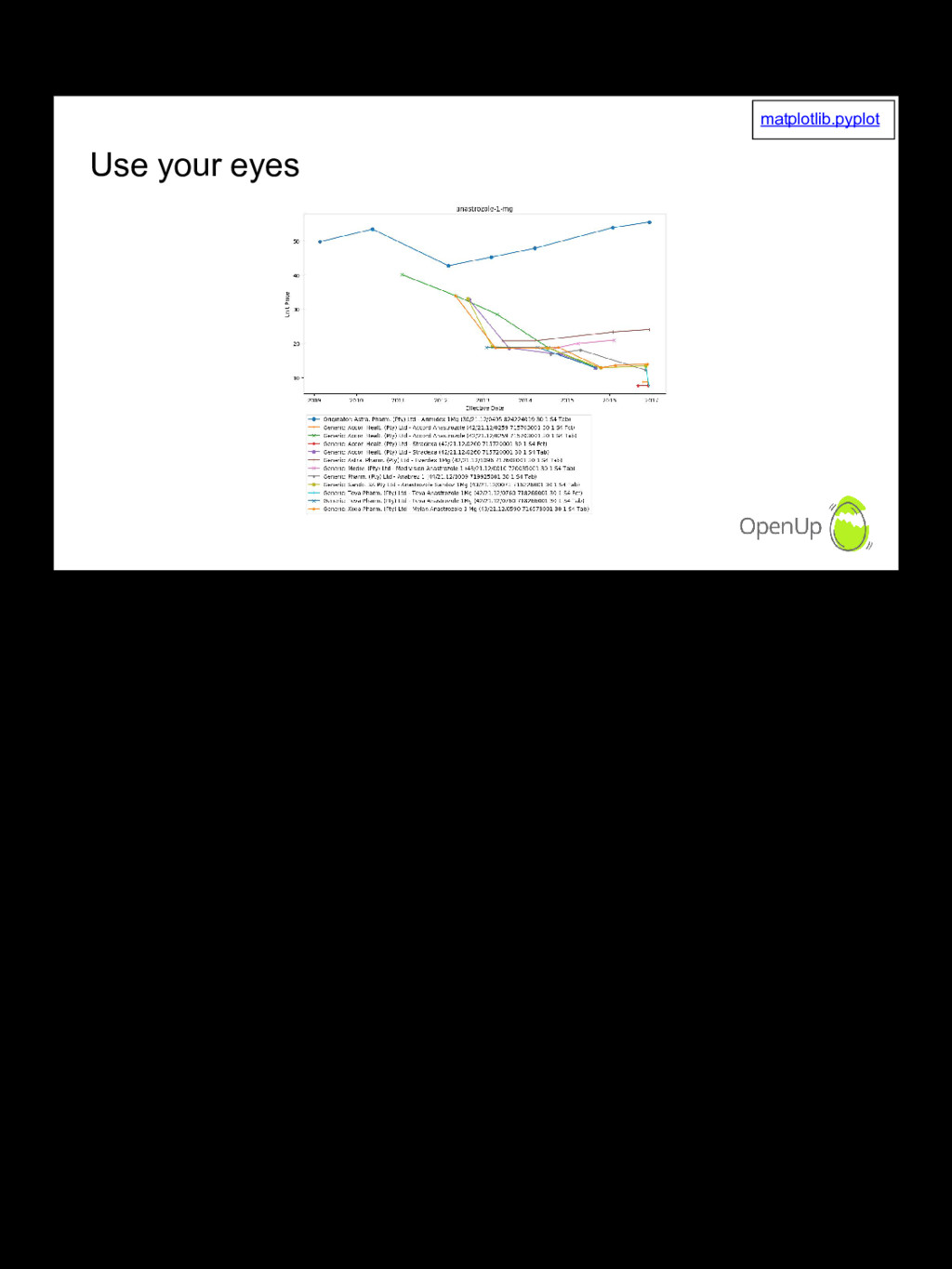
The Medicine Price Registry is a spreadsheet published one or more times per year, with the latest prices and active ingredients for medicines registered for sale in South Africa. Like most data, it's dirty and has limited usability in its original form. We take you through some of the practical steps we take to clean the data and make it easier to analyse and use. This allows us, for example, to analyse how price competition from generics lower medicine prices, or not!
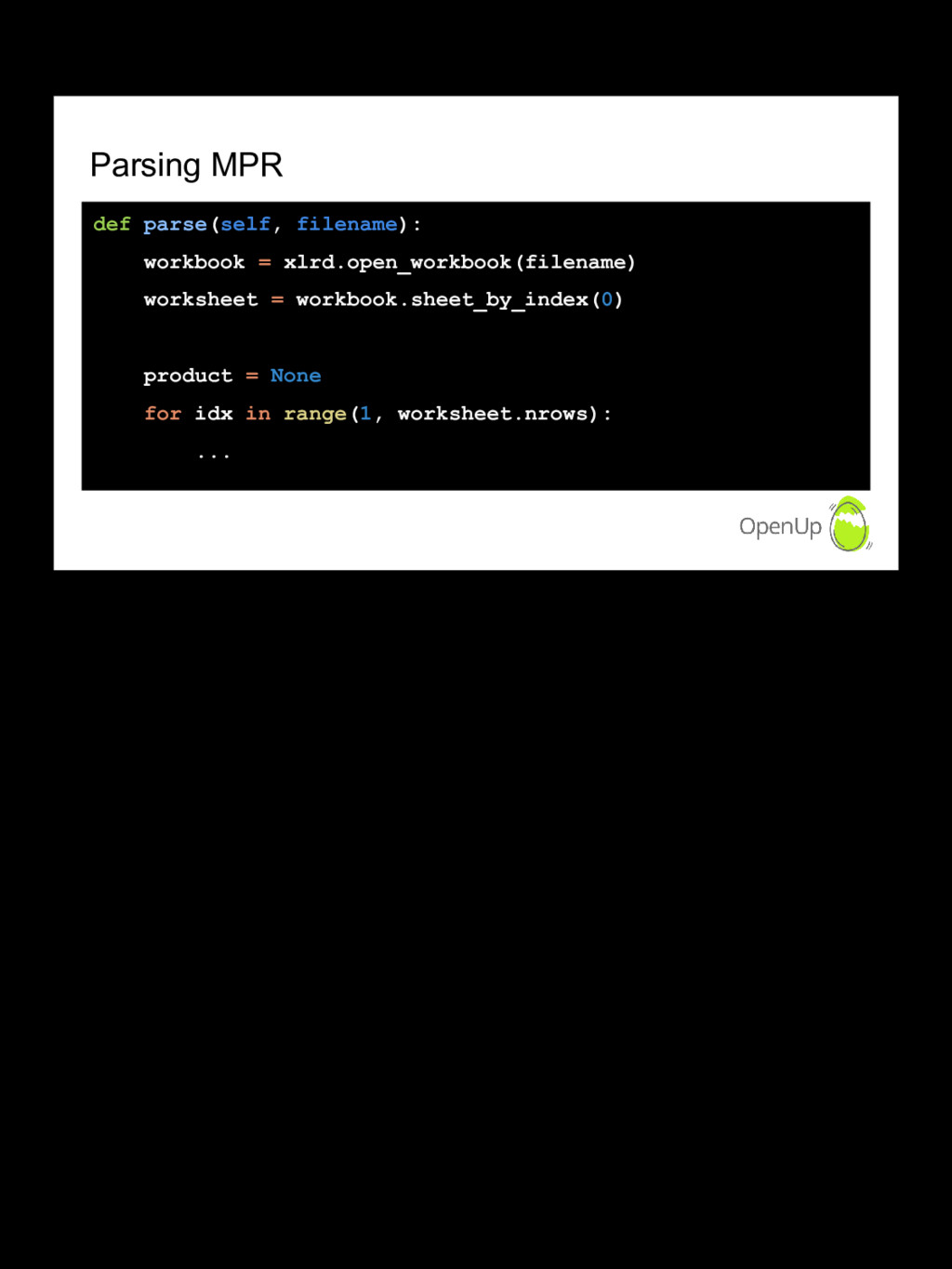
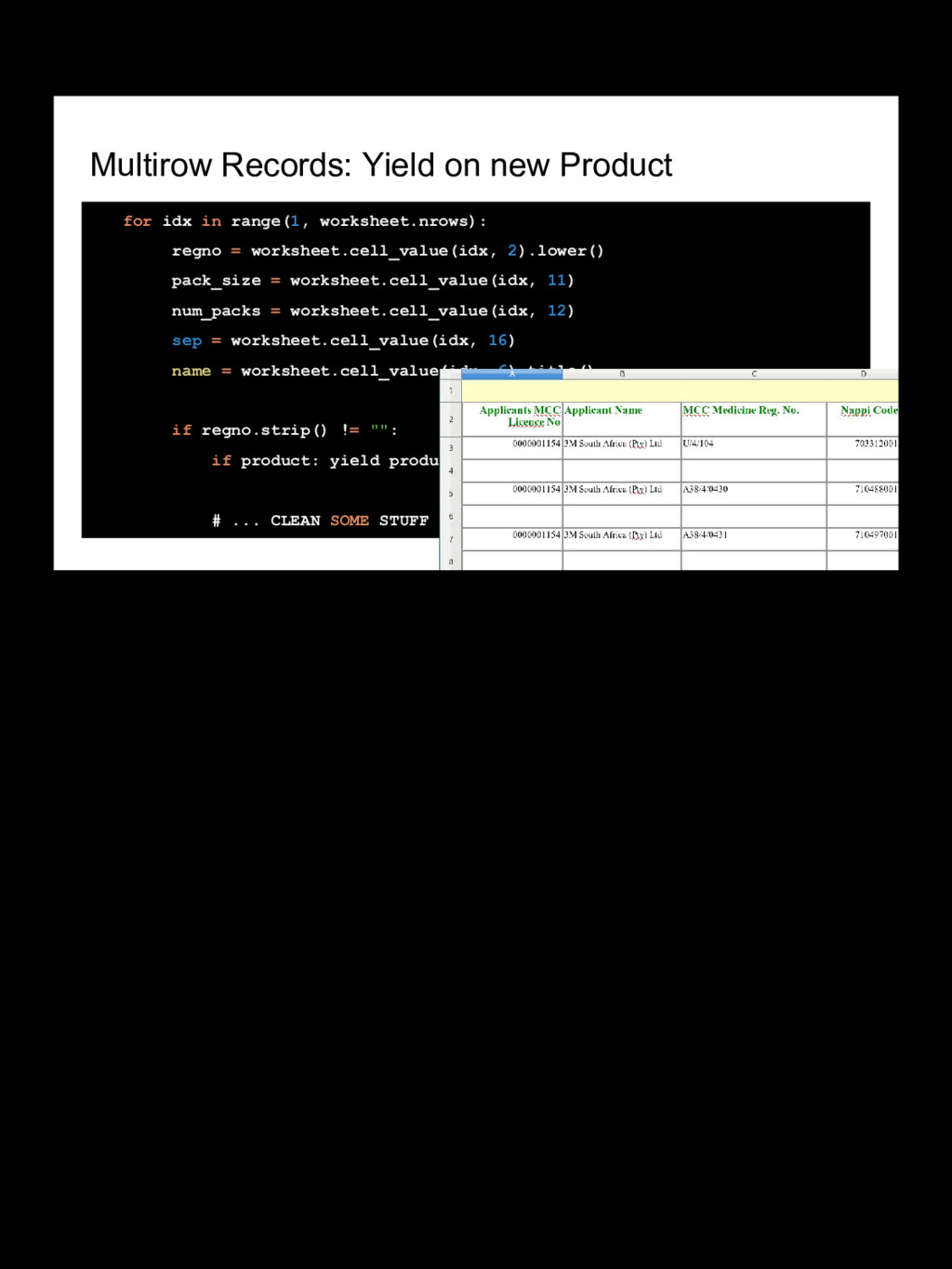
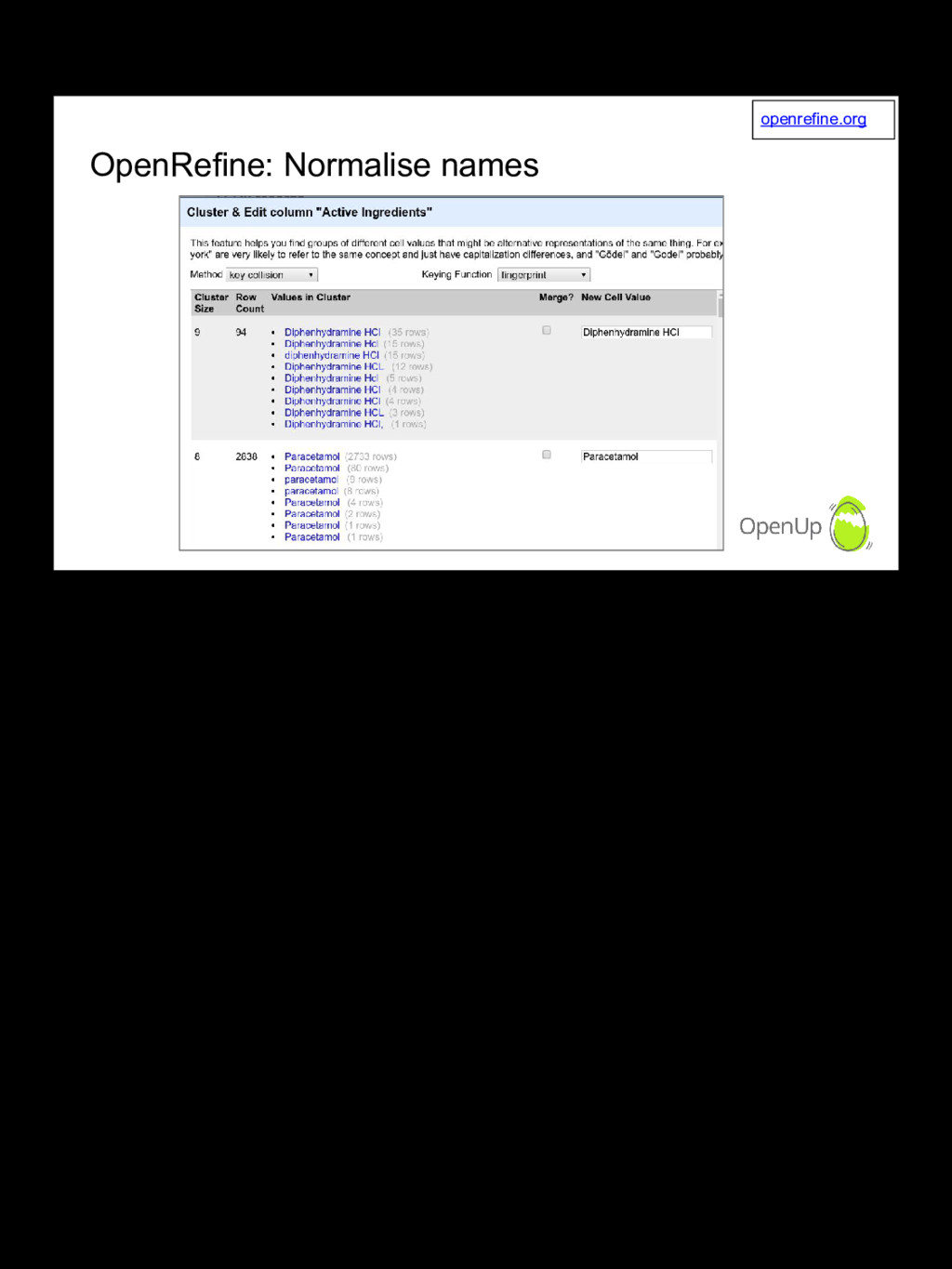
This is intended as a simple real-world example of how we work around the issues with a dataset using a few common tools. This could be done with any platform, but jupyter notebooks, sqlalchemy, alembic migrations and the brevity of python is a nice combination for the iteration needed to work with this data and adapt as we get to know it. We start with a GUI tool called OpenRefine but it pretty quickly becomes necessary to write just a bit of code to move quickly.
There's a lot of material out there on specific tools. I'd like to show the reality of dirty datasets, and the workarounds and approaches we use to get value from it nonetheless. One such example is using charts and ordering to group related data and visually identify interesting events. I encourage people to ask questions and offer suggestions. The effort put into this project has been limited by time constraints but any improvements can have real world impact.
![Making man-made medicine price data more useful JD Bothma [email protected]](https://files.speakerdeck.com/presentations/271a720a26d94cbf90e38cecaab3a6ee/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
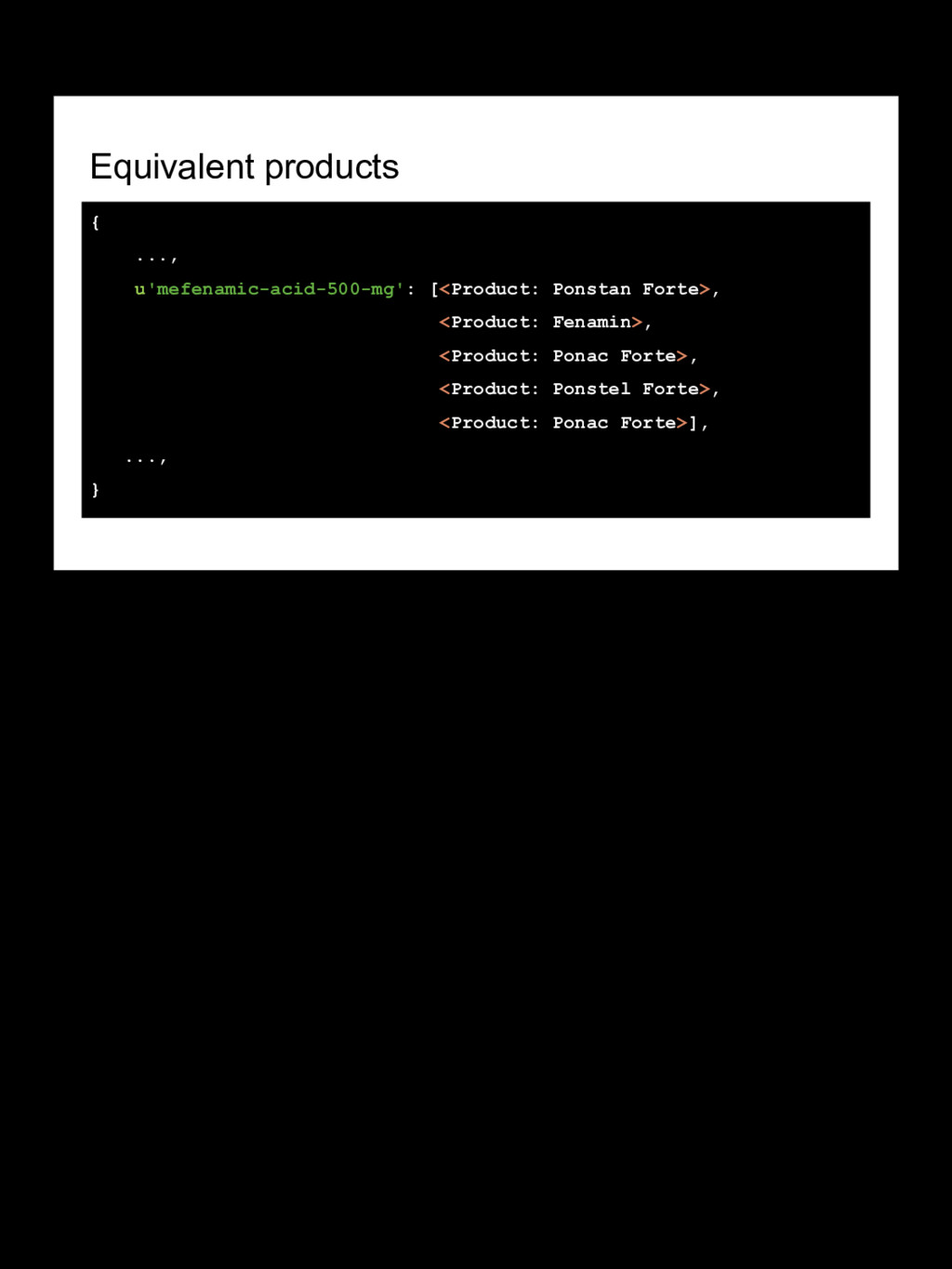{kind=link}
{kind=link}
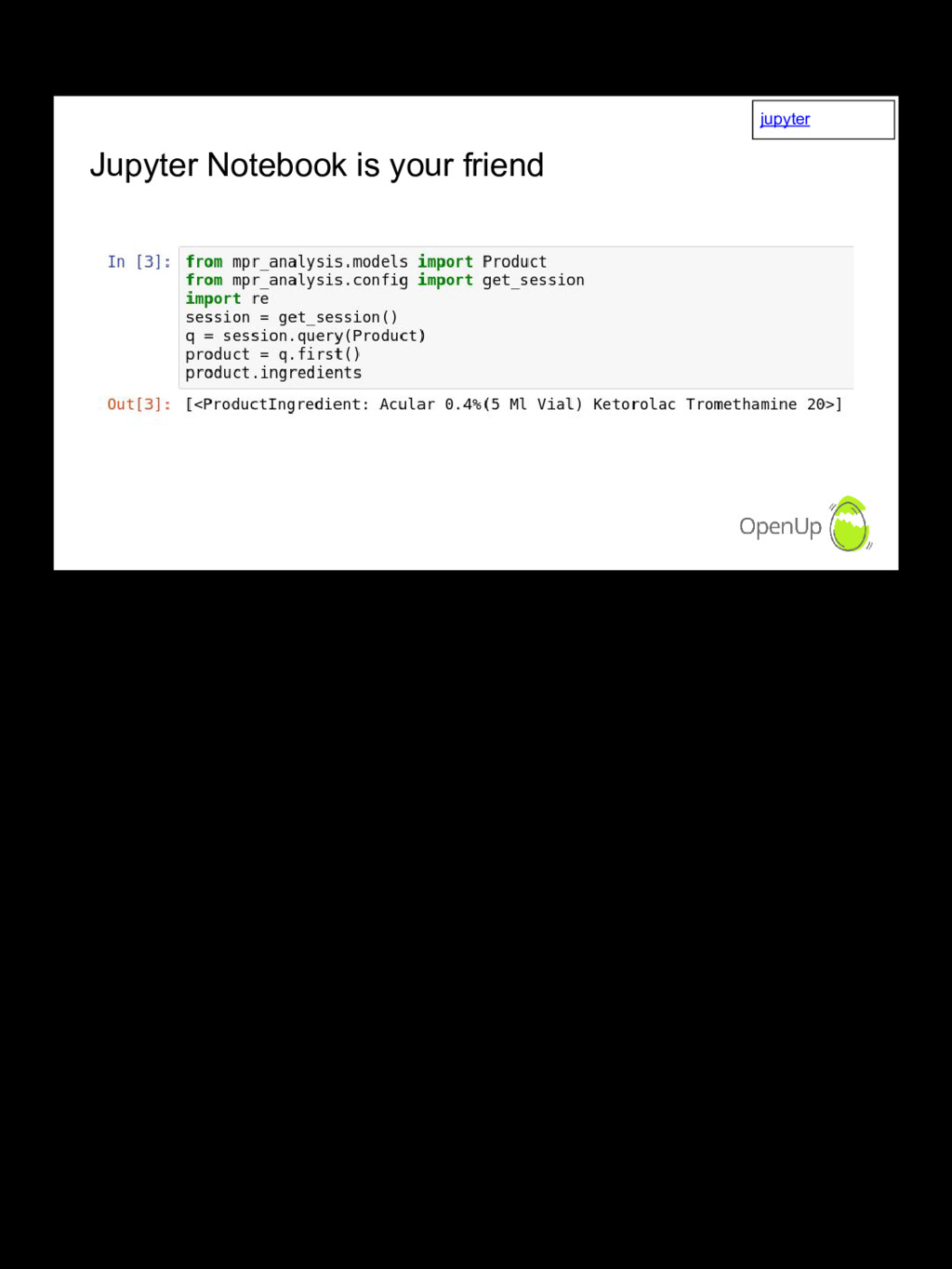{kind=link}
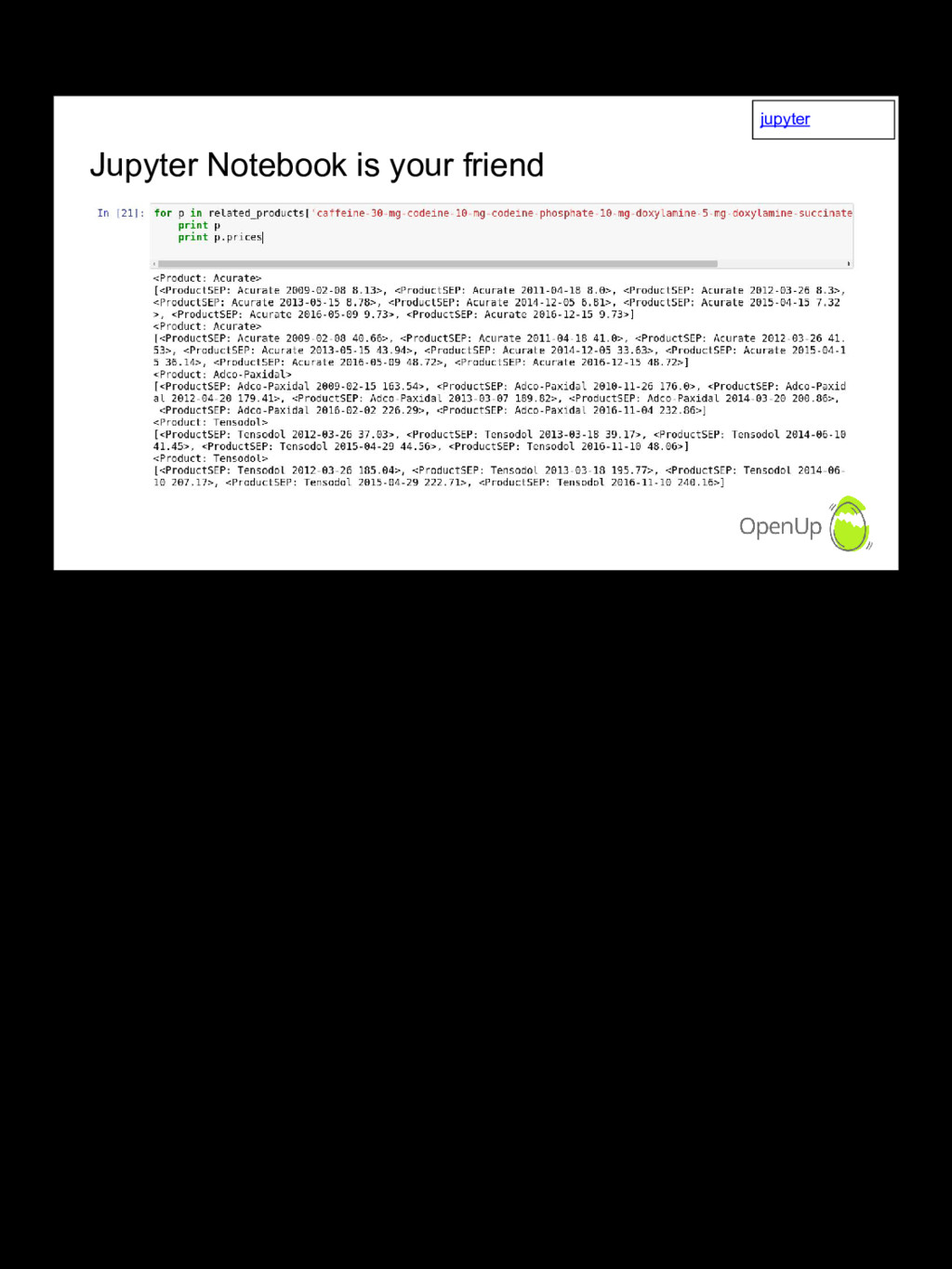{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}