Apache Spark is a fast and general engine for large-scale, distributed data processing. It offers high-level APIs in Java, Scala and Python as well as a rich set of libraries including stream processing, machine learning, and graph analytics. Spark is currently one of the most exciting and fastest-growing Apache open source projects.
This talk will give an overview of the Apache Spark project and introduce the basics of PySpark, the Python API for Spark. It will then dive a little deeper into PySpark internals, and finally show some examples and a live demo covering PySpark, Spark's SQL engine, and machine learning with Spark's built-in libraries as well as other Python libraries.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MapReduce: Counting Words public static void main(String[] args) throws Exception](https://files.speakerdeck.com/presentations/87d0c7f031ef0132ec4b32025bce2f7e/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SparkSQL • SparkSQL events = rdd.map(lambda row: Row(time = row[0],](https://files.speakerdeck.com/presentations/87d0c7f031ef0132ec4b32025bce2f7e/slide_21.jpg){kind=link}
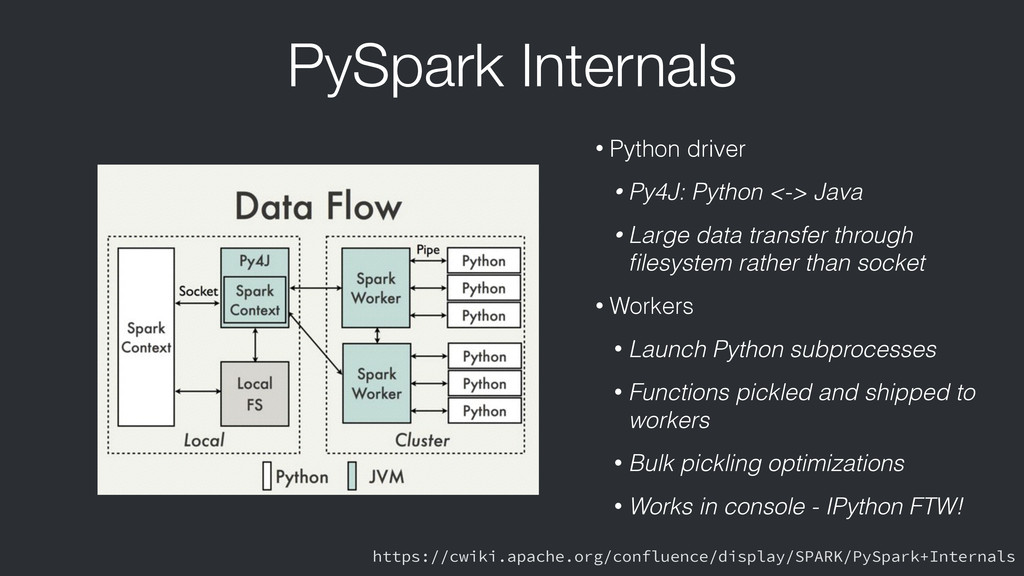{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}