One of the ways that changes enter the Python language is via their prior discussion on the python-ideas mailing list. Many core contributors read and contribute to this list, some do not, and a large number of other interested Python programmers also participate in the discussion. A recurring element of these fascinating discussions is that ideas which seem compelling at first blush, upon deeper discussion reveal the greater wisdom of doing things just the way Python already does. Not always, of course, but often.
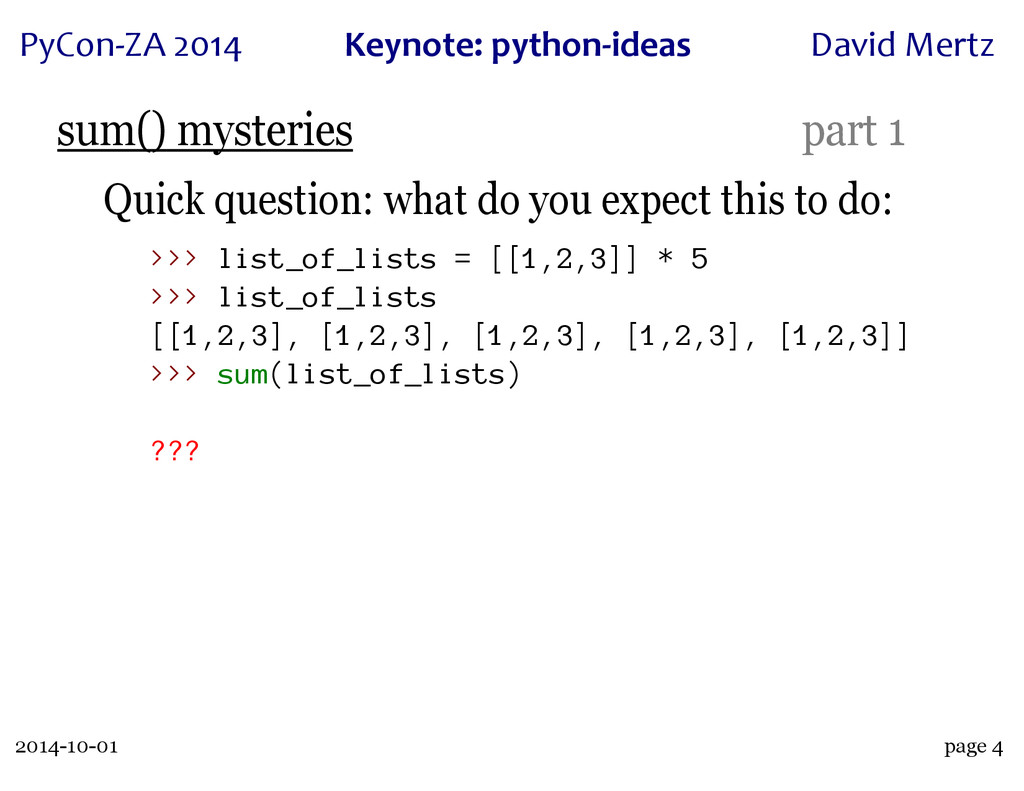
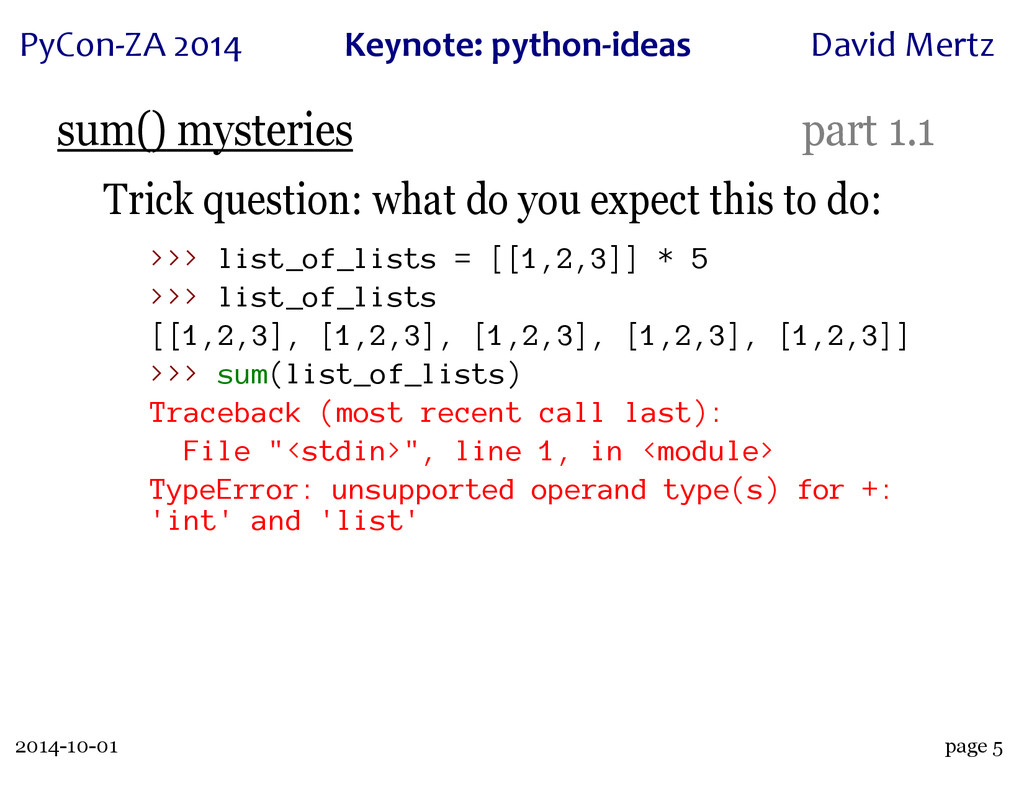
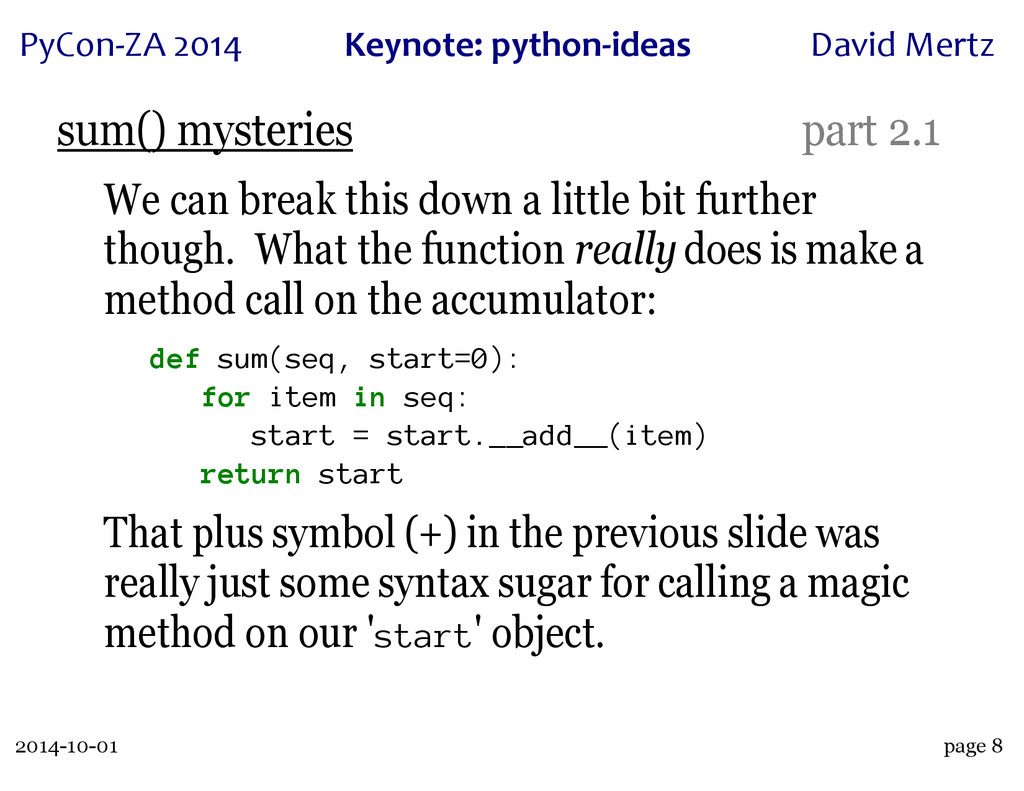
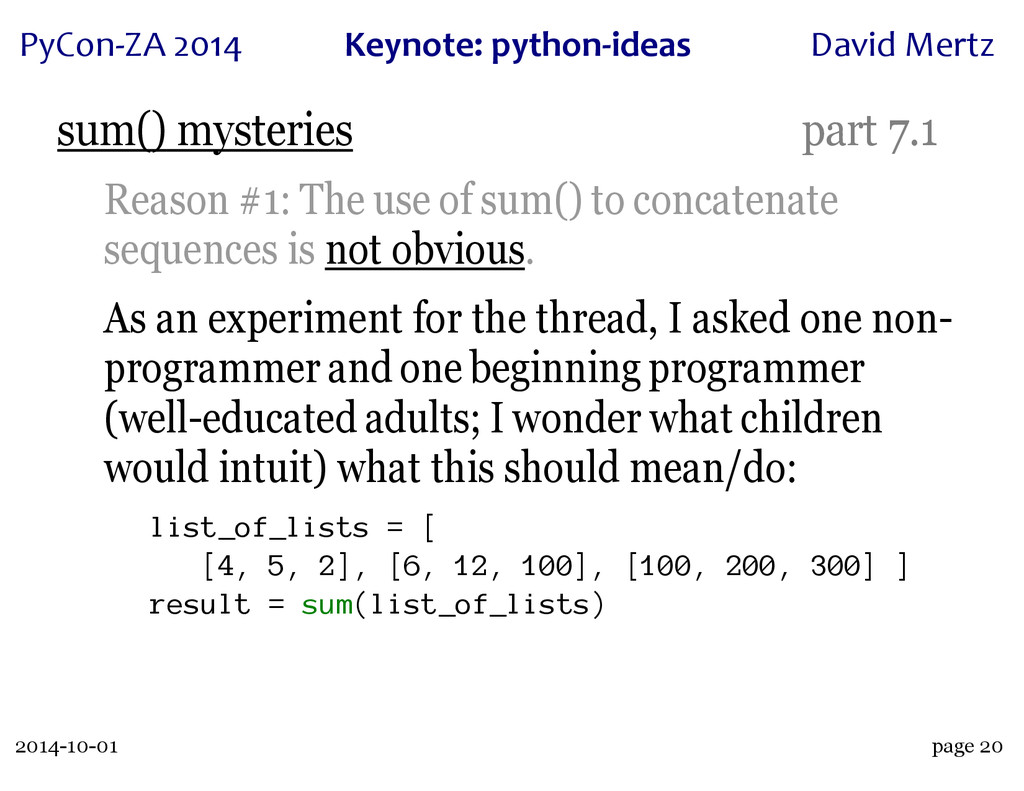
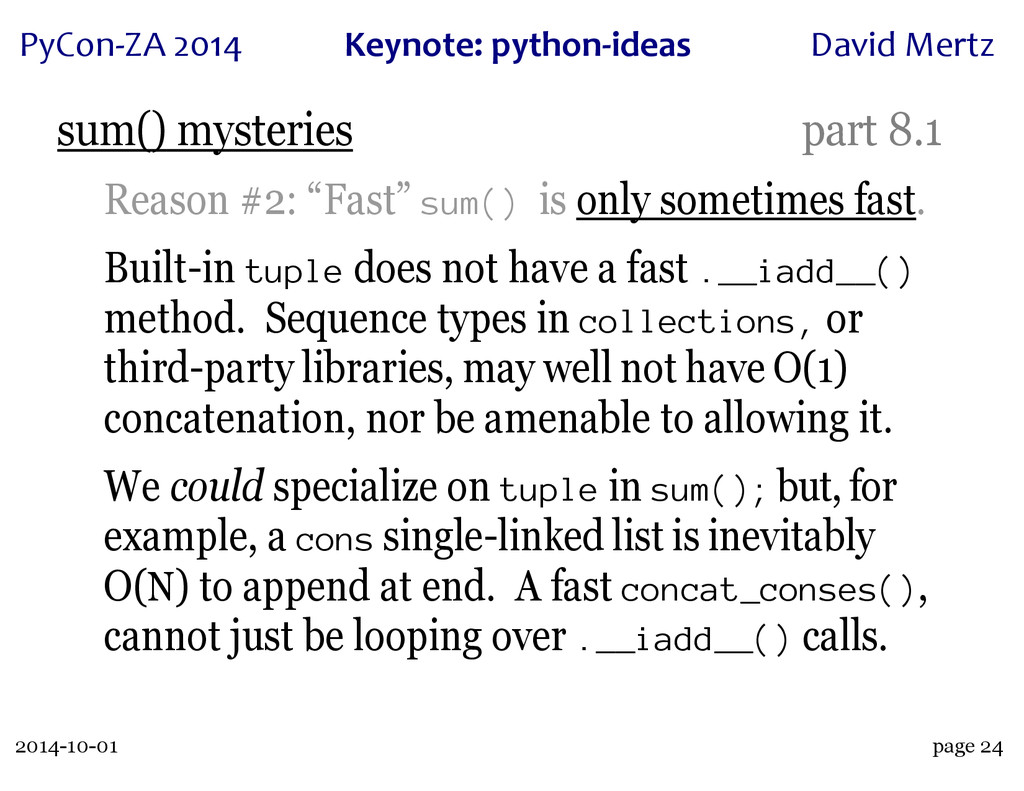
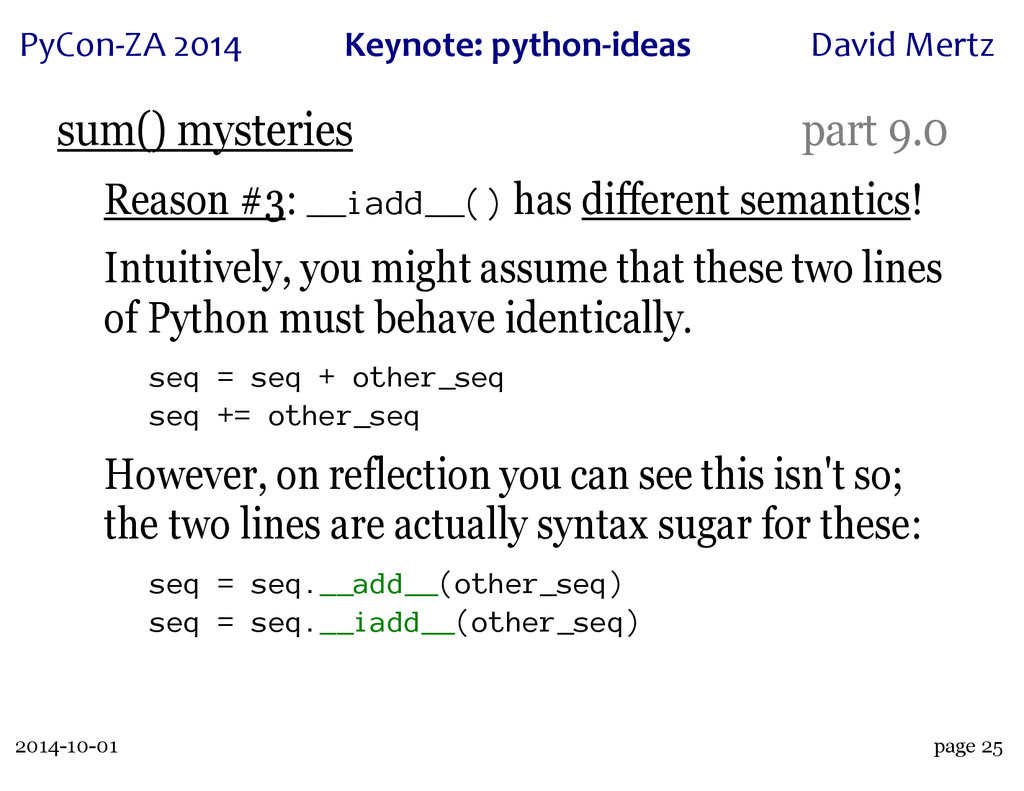
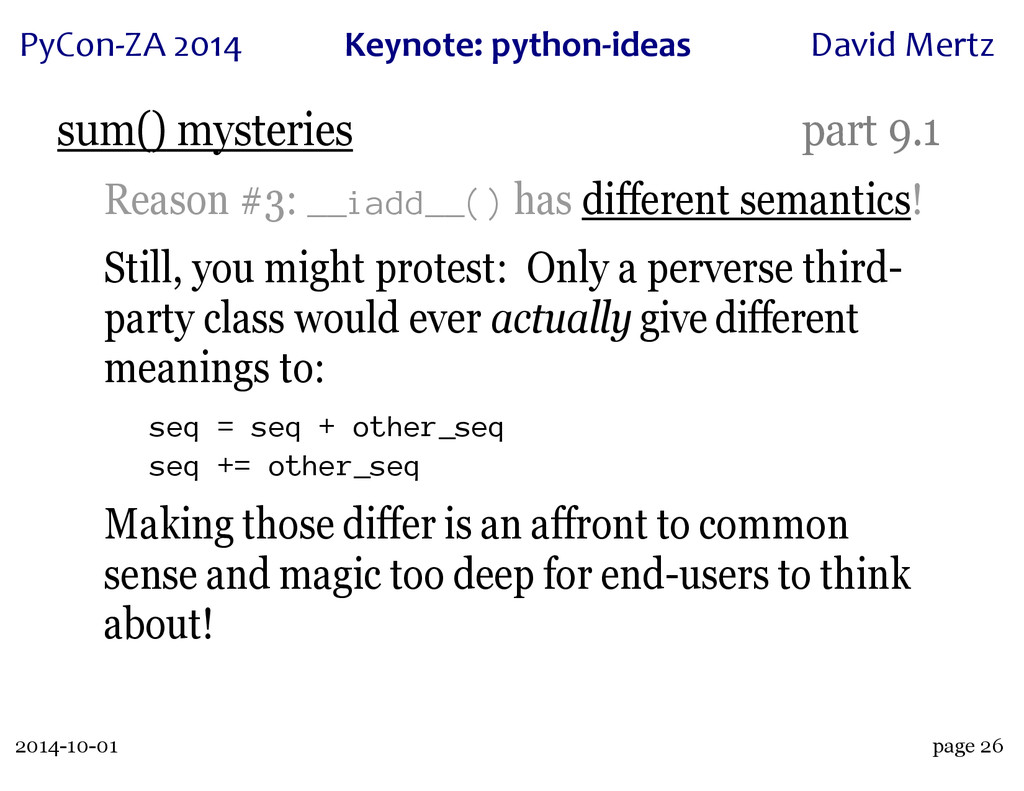
A wonderful case study of this process is the innocuous seeming built-in 'sum()'. This function has an intricate history, with a great deal of dispute over just what its semantics and performance characteristics can or should be. A particular thread on python-ideas, rich with discussions of use cases and subtle semantics, led both to the creation of the 'statistics' module in Python 3.4 (which contains a "private" version of the function, 'statistics._sum()') and to a rejection of performance "optimizations" when operating over collections of collections (which may or may not seem obvious to "sum" in the first place).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}