AUDIENCE
data scientists (current and aspiring)
those who want to know more about data processing
those who are intimidate by "big data" (java) frameworks and are interested in a simpler, pure python alternative
those interested in async and/or parallel programming
DESCRIPTION
Big data processing is all the rage these days. Heavyweight frameworks such as Spark, Storm, Kafka, Samza, and Flink have taken the spotlight despite their complex setup, java dependency, and intense computer resource usage.
Those interested in simple, pure python solutions have limited options. Most alternative software is synchronous, doesn't perform well on large data sets, or is poorly documented.
This talk aims to explain stream processing and its uses, and introduce riko: a pure python stream processing library built with simplicity in mind. Complete with various examples, you’ll get to see how riko lazily processes streams via its synchronous, asynchronous, and parallel processing APIs.
OBJECTIVES
Attendees will learn what streams are, how to process them, and the benefits of stream processing. They will also see that most data isn't "big data" and therefore doesn't require complex (java) systems (*cough* spark and storm *cough*) to process it.
DETAILED ABSTRACT
Stream processing?
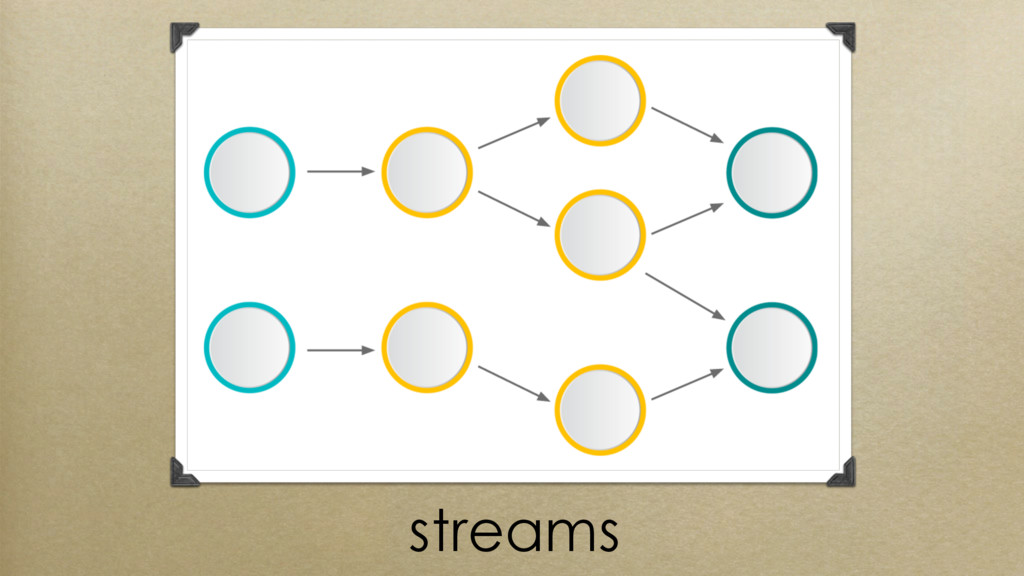
What are streams?
A stream is a sequence of data. The sequence can be as simple as a list of integers or as complex as a generator of dictionaries.
How do you process streams?
Stream processing is the act of taking a data stream through a series of operations that apply a (usually pure) function to each element in the stream. These operations are pipelined so that the output of one function is the input of the next one. By using pure functions, the processing becomes embarrassingly parallel: you can split the items of the stream into separate processes (or threads) which then perform the operations simultaneously (without the need for communicating between processes/threads).
What can stream processing do?
Stream processing allows you to efficiently manipulate large data sets. Through the use of lazy evaluation, you can process data stream too large to fit into memory all at once.
Additionally, stream processing has several real world applications including:
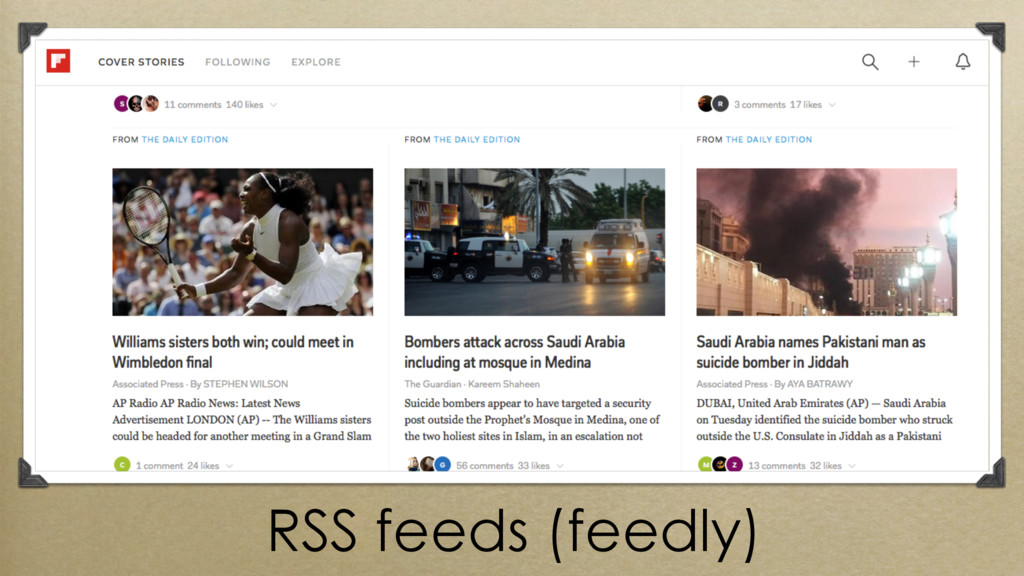
parsing rss feeds (rss readers, think feedly)
combining different types data from multiple sources in innovative ways (mashups, think trendsmap)
taking data from multiple sources, manipulating the data into a homogeneous structure, and storing the result in a database (extracting, transforming, and loading data; aka ETL, data wrangling...)
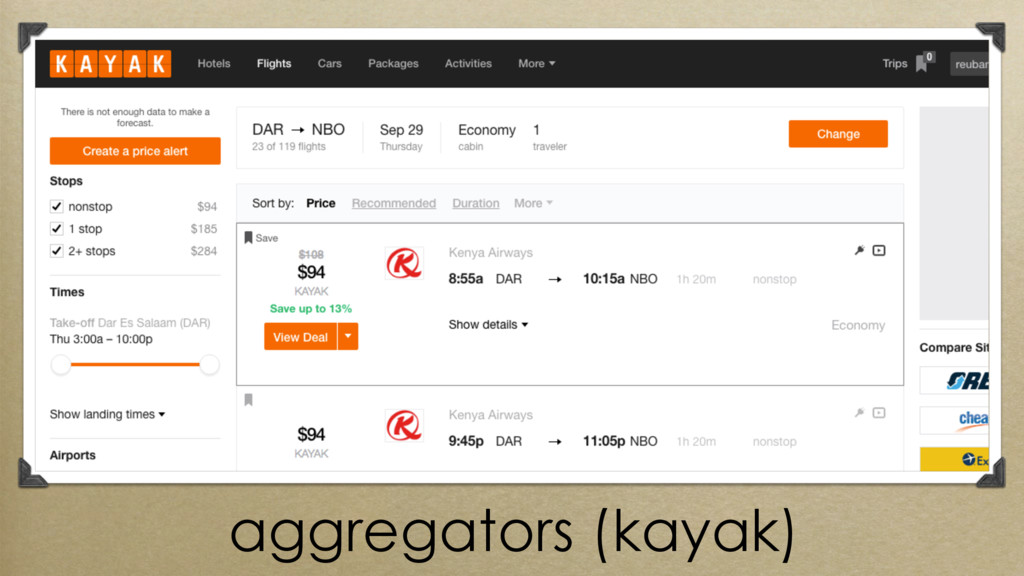
aggregating similarly structured data from siloed sources and presenting it via a unified interface (aggregators, think kayak)
Stream processing frameworks
If you've heard anything about stream processing, chances are you've also heard about frameworks such as Spark, Storm, Kafka, Samza, and Flink. While popular, these frameworks have a complex setup and installation process, and are usually overkill for the amount of data typical python users deal with. Using a few examples, I will show basic Storm usage and how it stacks up against BASH.
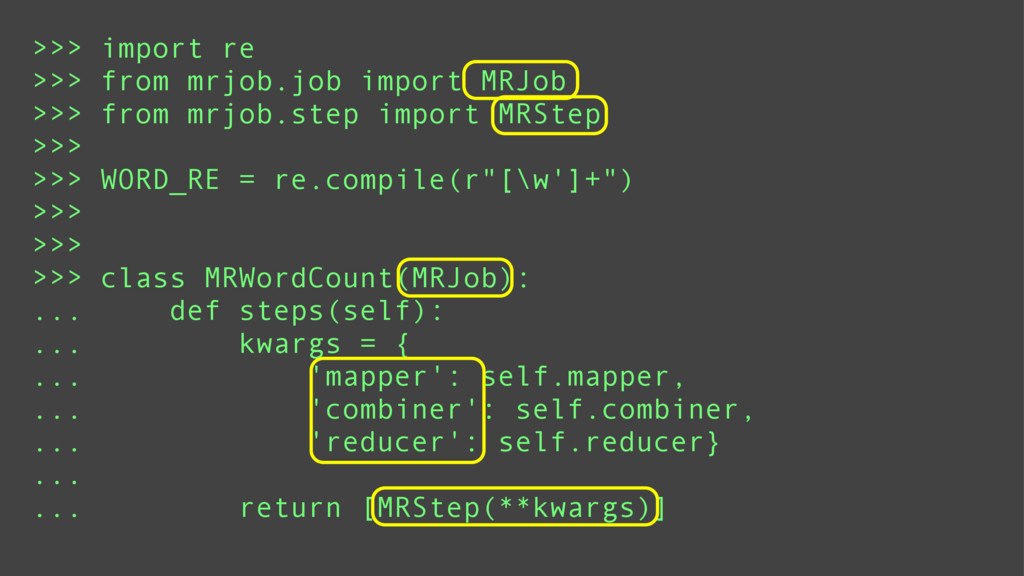
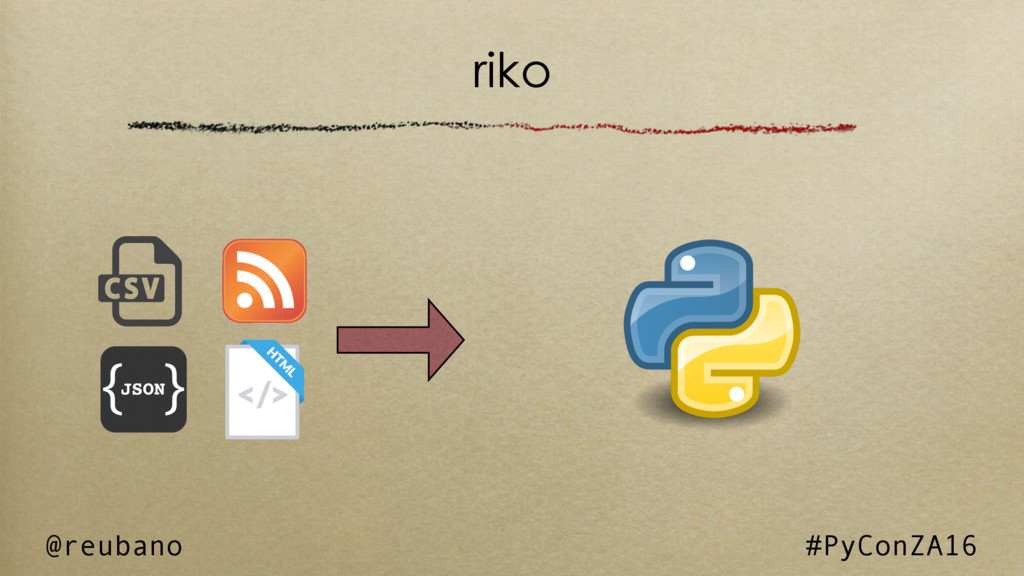
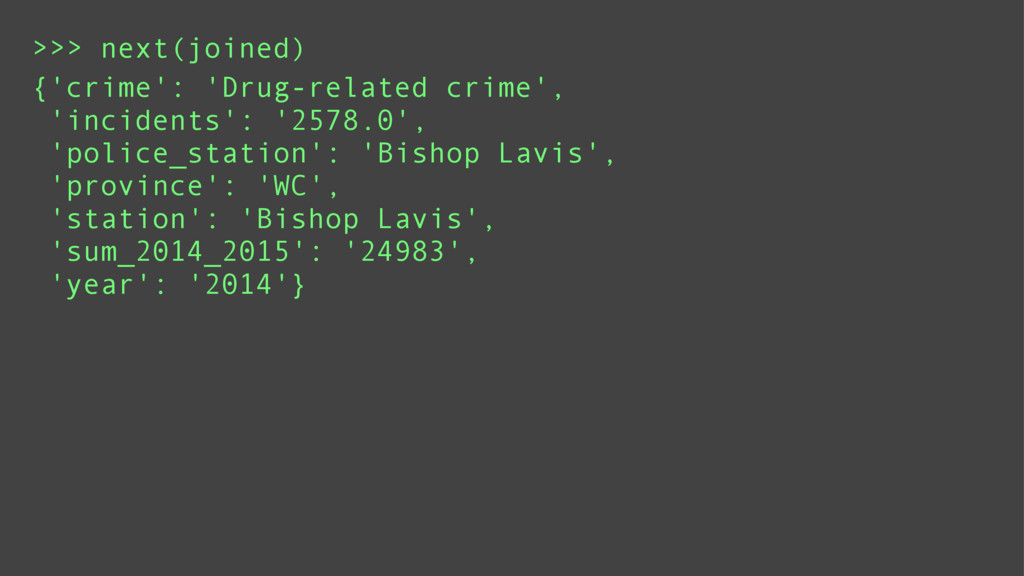
Introducing riko
Supporting both Python 2 and 3, riko is the first pure python stream processing library to support synchronous, asynchronous, and parallel processing. It's built using functional programming methodology and lazy evaluation by default.
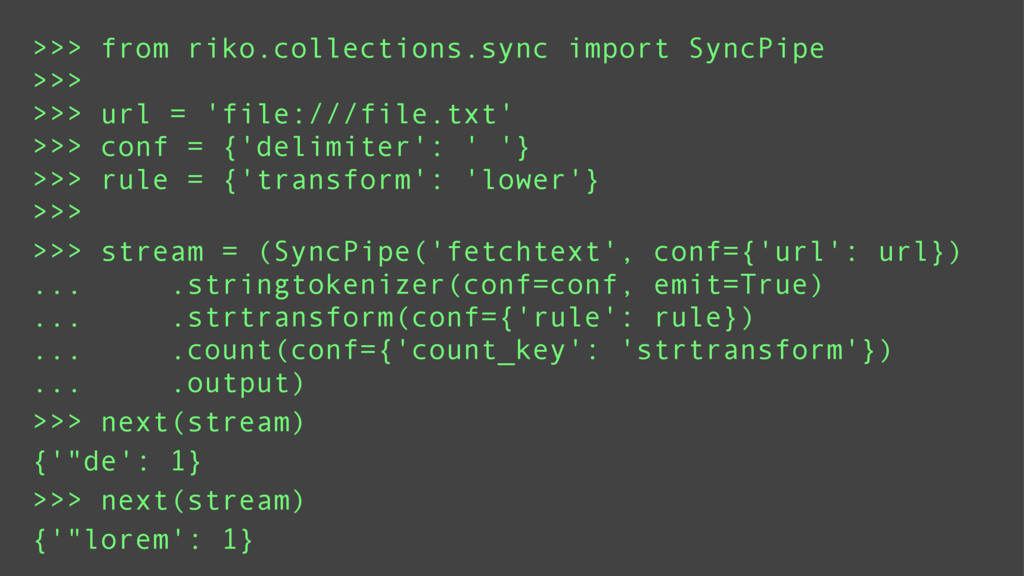
Basic riko usage
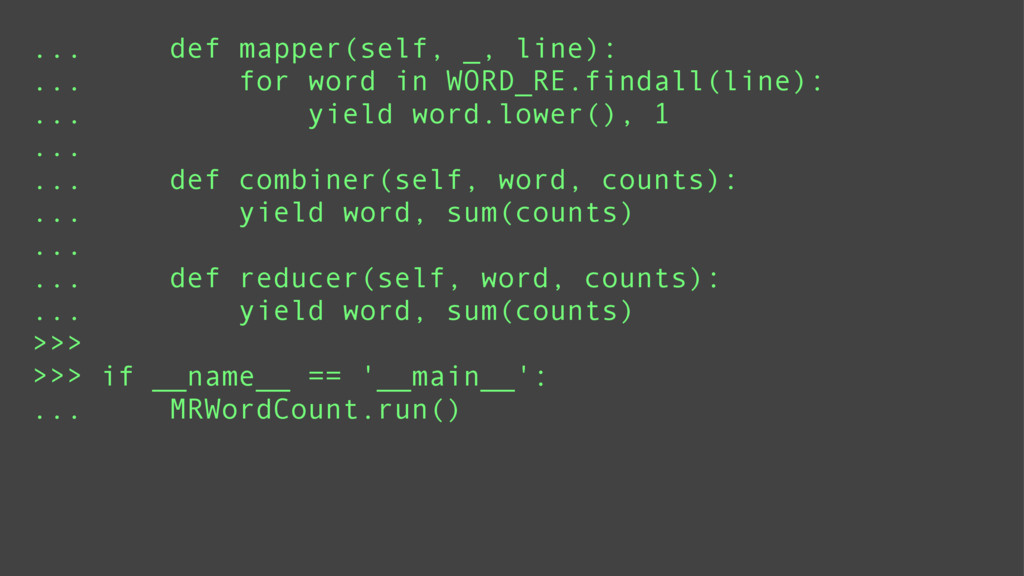
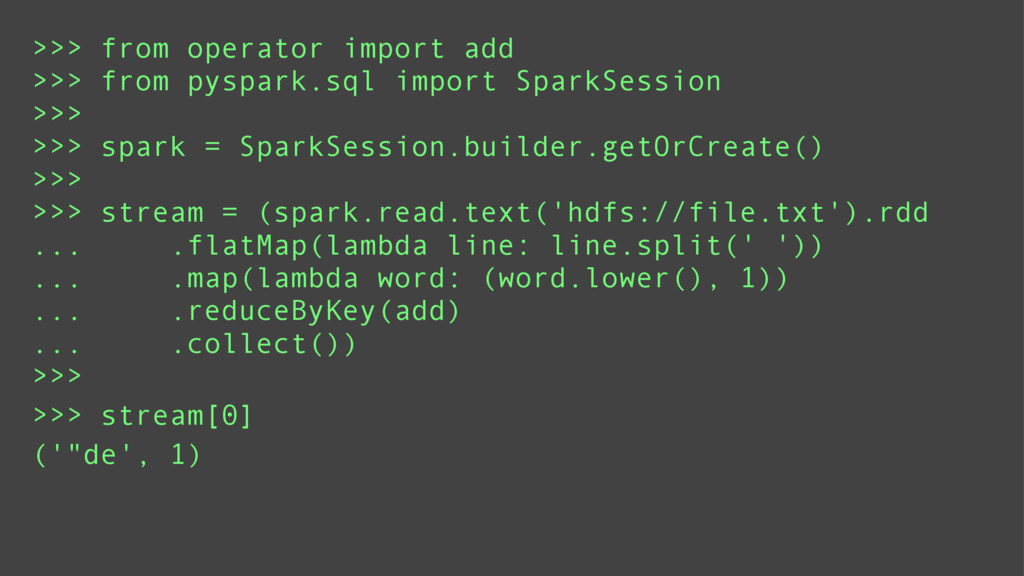
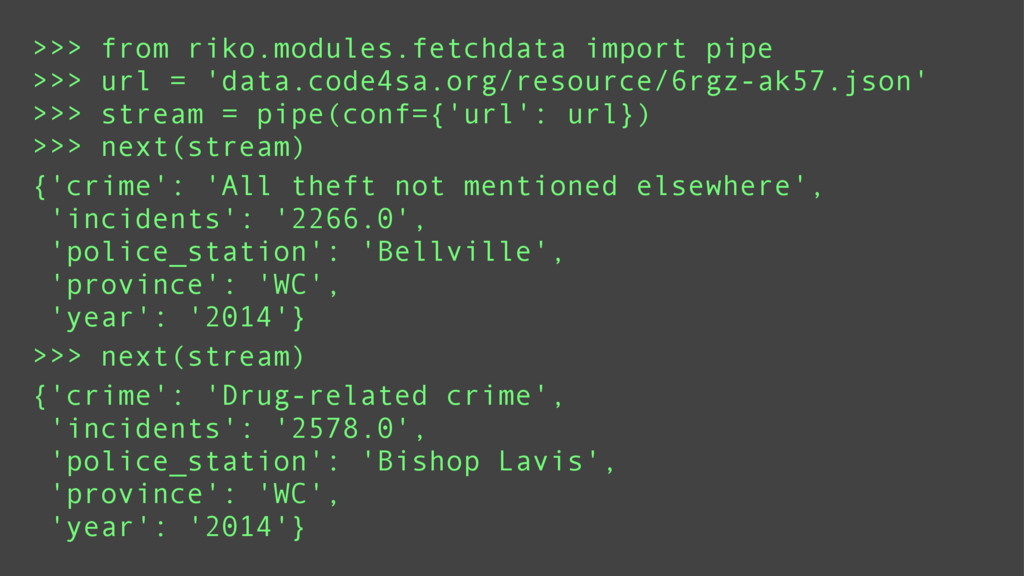
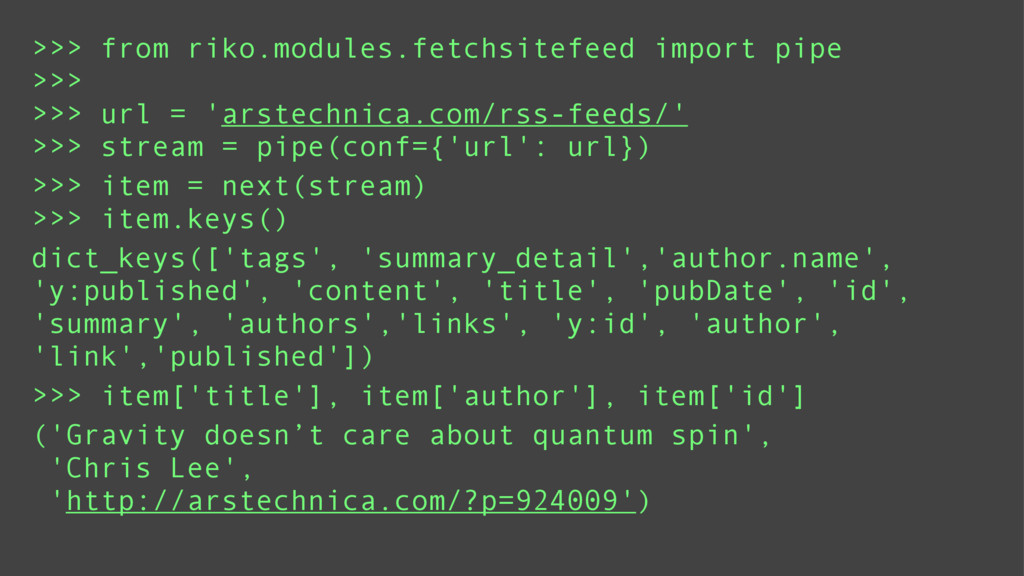
Using a series of examples, I will show basic riko usage. Examples will include counting words, fetching streams, and rss feed manipulation. I will highlight the key features which make riko a better stream processing alternative to Storm and the like.
riko's many paradigms
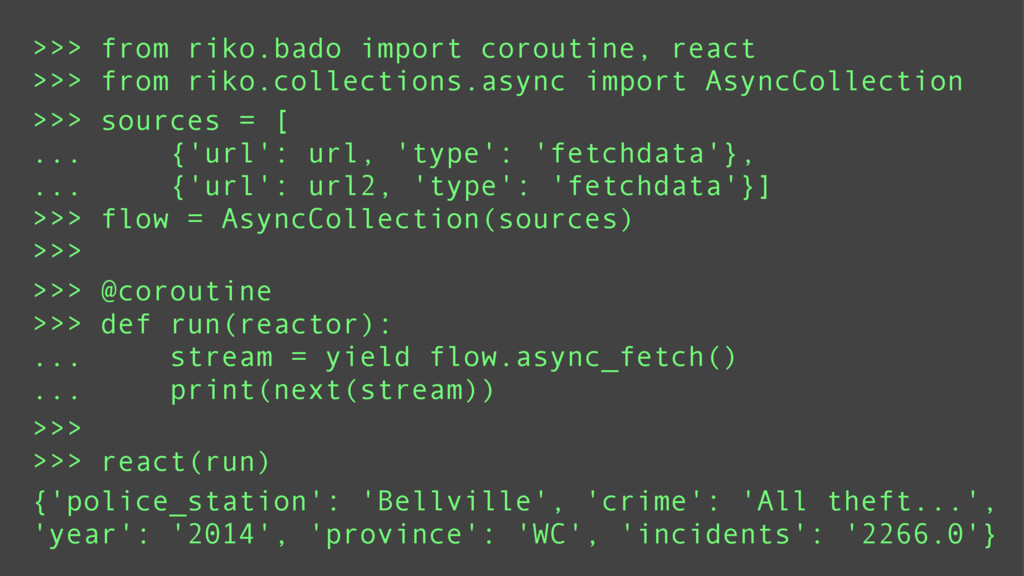
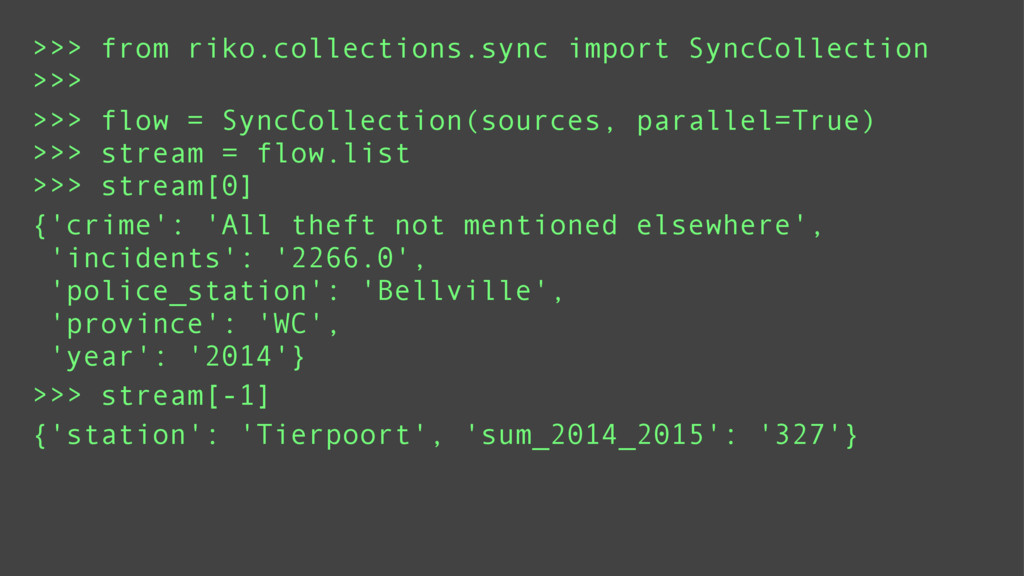
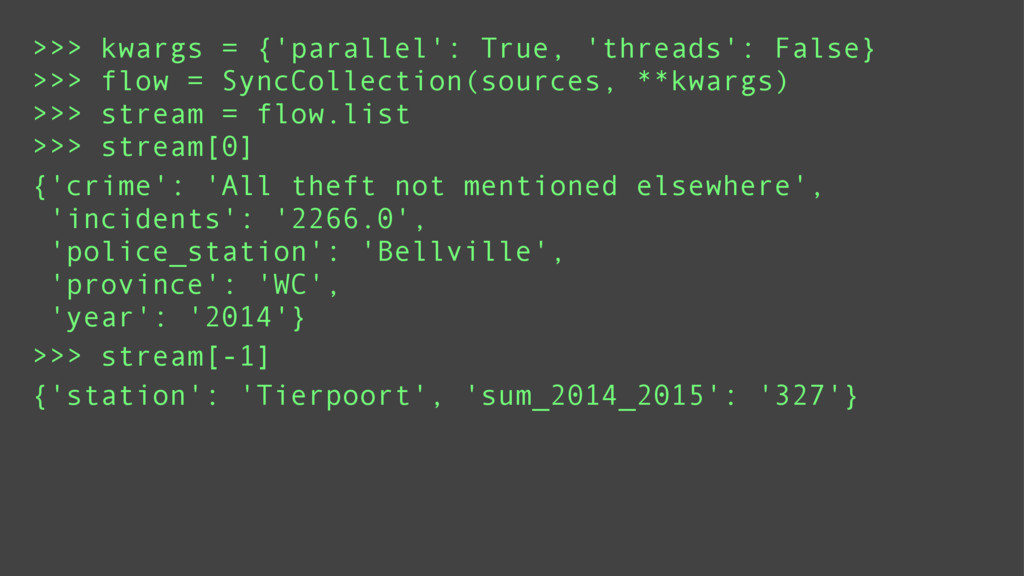
Depending on the type of data being processed; a synchronous, asynchronous, or parallel processing method may be ideal. Fetching data from multiple sources is suited for asynchronous or thread based parallel processing. Computational intensive tasks are suited for processor based parallel processing. And asynchronous processing is best suited for debugging or low latency environments.
riko is designed to support all of these paradigms using the same api. This means switching between paradigms requires trivial code changes such as adding a yield statement or changing a keyword argument.
Using a series of examples, I will show each of these paradigms in action.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![>>> 'abracadabra'[0] >>> range(1, 11)[0] >>> 'hello pycon attendees'.split(' ')[0]](https://files.speakerdeck.com/presentations/46795ec9d32f474db06955183143769e/slide_19.jpg){kind=link}
{kind=link}
![>>> [ord(x) for x in 'abracadabra'] >>> [2 * x](https://files.speakerdeck.com/presentations/46795ec9d32f474db06955183143769e/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pip install riko[async]](https://files.speakerdeck.com/presentations/46795ec9d32f474db06955183143769e/slide_55.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Reuben Cummings [email protected] https://github.com/nerevu/riko @reubano #PyConZA16 Thanks!](https://files.speakerdeck.com/presentations/46795ec9d32f474db06955183143769e/slide_62.jpg){kind=link}
{kind=link}
{kind=link}