Managing your code is like managing anything else.
To take back control of your code, you need to measure everything you can!
This talk is about my experience of wresting an unruly codebase into a well behaved one.
Well, better behaved, at least...
In this talk I'll cover the following, and how they affect your Python application:
Complexity :and how it differs from ease
Risk: not all code is equally important
Static analysis don't fear the pylint, whilst typing + mypy can save the day
Testing: why & when to write tests (hypothesis is awesome)
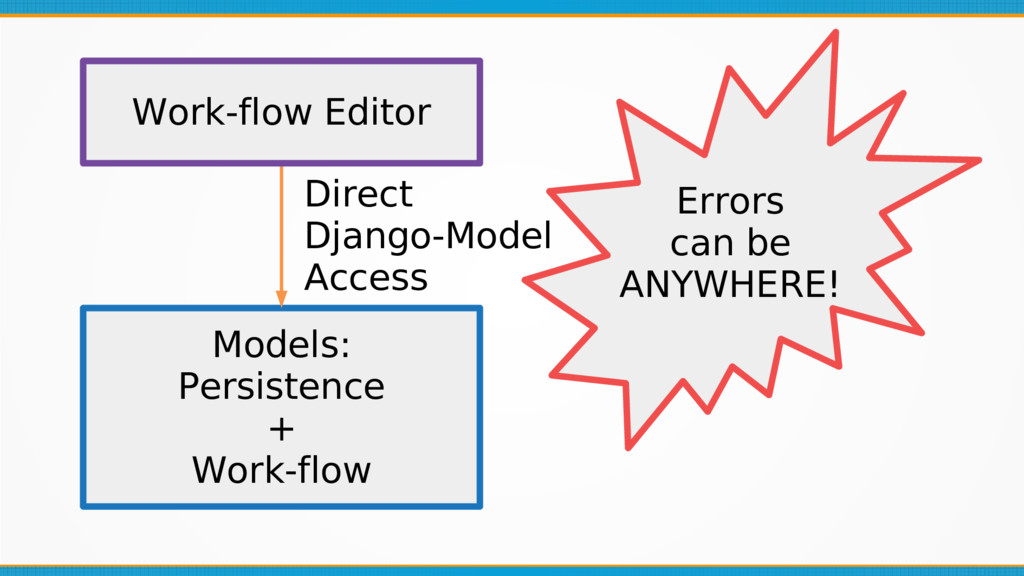
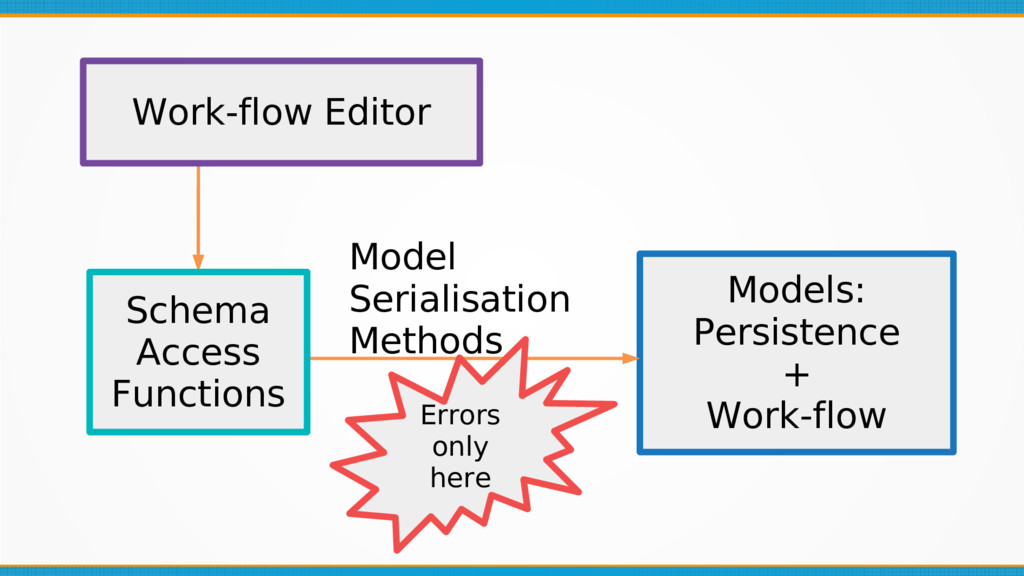
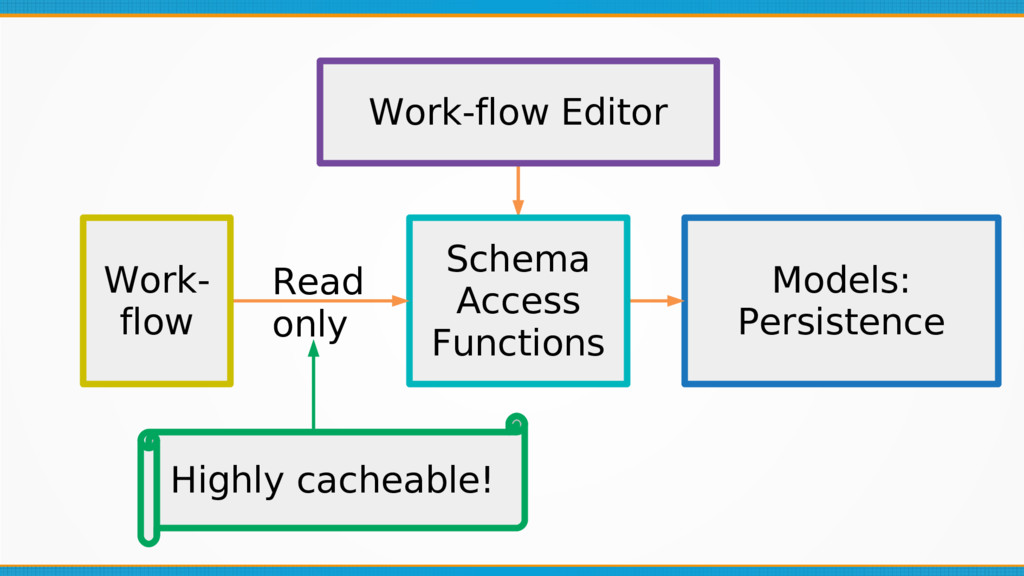
Formally design your internal data format: whilst it seems obvious, internal data formats are often left unchecked
Profiling: a good programmer with a profiler is better than one without
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Phew!! All done!! Thanks for listening :-) Nickolas Grigoriadis ([email protected])](https://files.speakerdeck.com/presentations/fea824f765c84ff689855bd2445222eb/slide_33.jpg){kind=link}