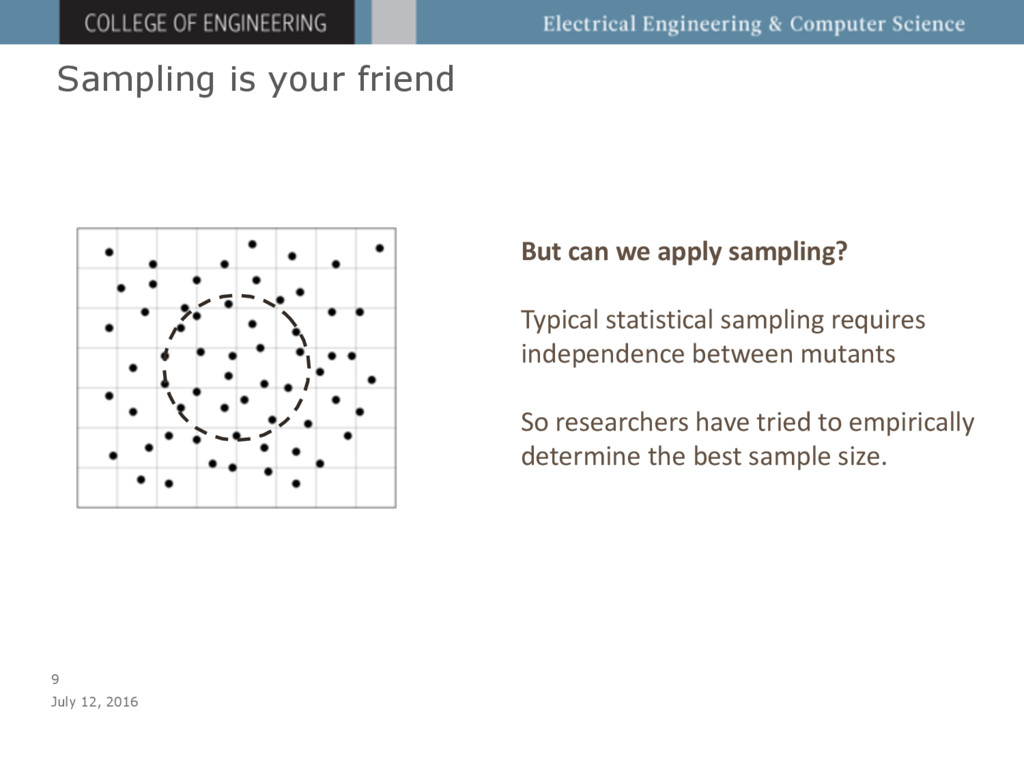
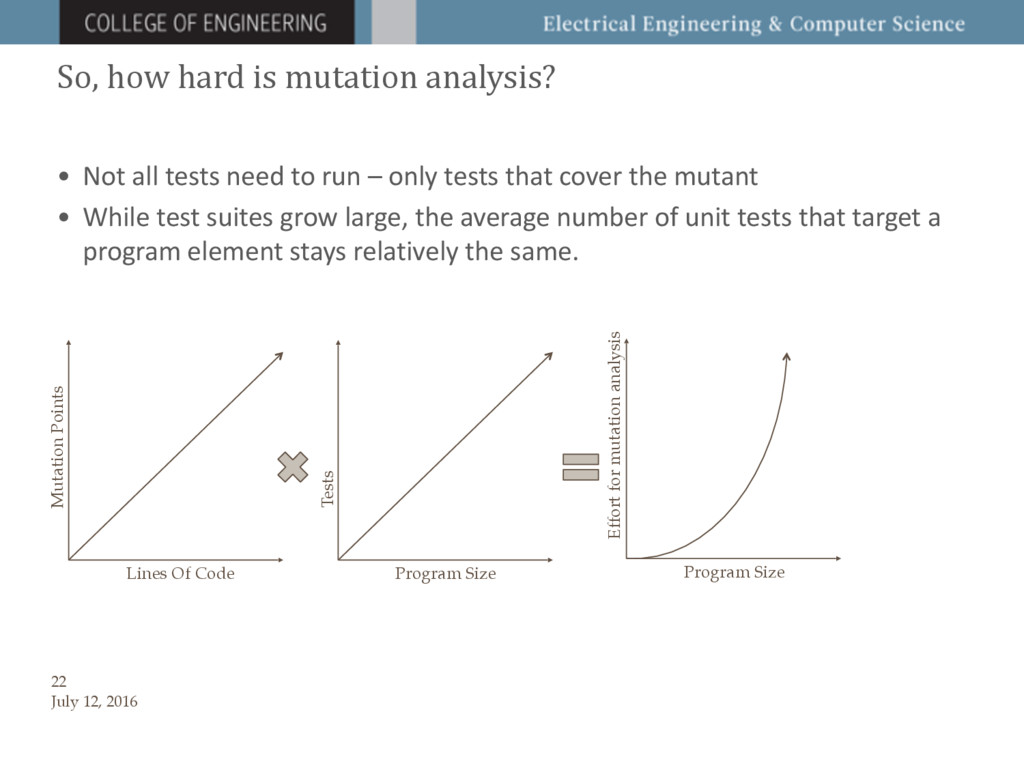
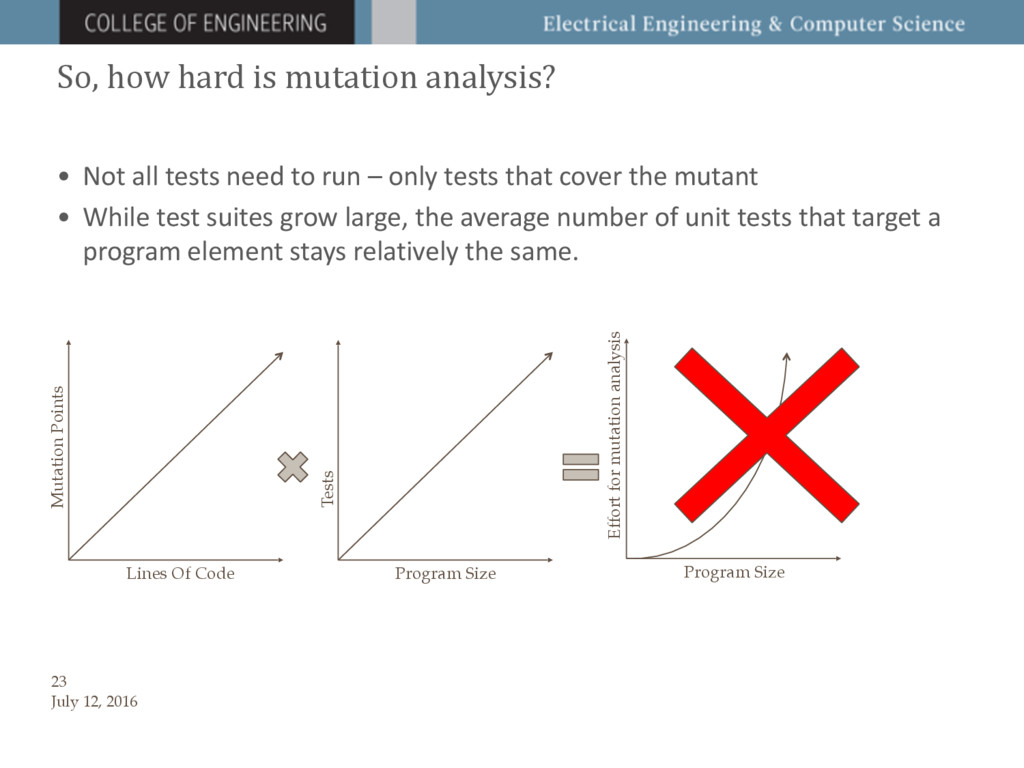
We provide both theoretical analysis and
empirical evidence that a small constant sample of mutants yields
statistically similar results to running a full mutation analysis,
regardless of the size of the program or similarity between
mutants. We show that a similar approach, using a constant
sample of inputs can estimate the degree of stubbornness in
mutants remaining to a high degree of statistical confidence,
and provide a mutation analysis framework for Python that
incorporates the analysis of stubbornness of mutants.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}