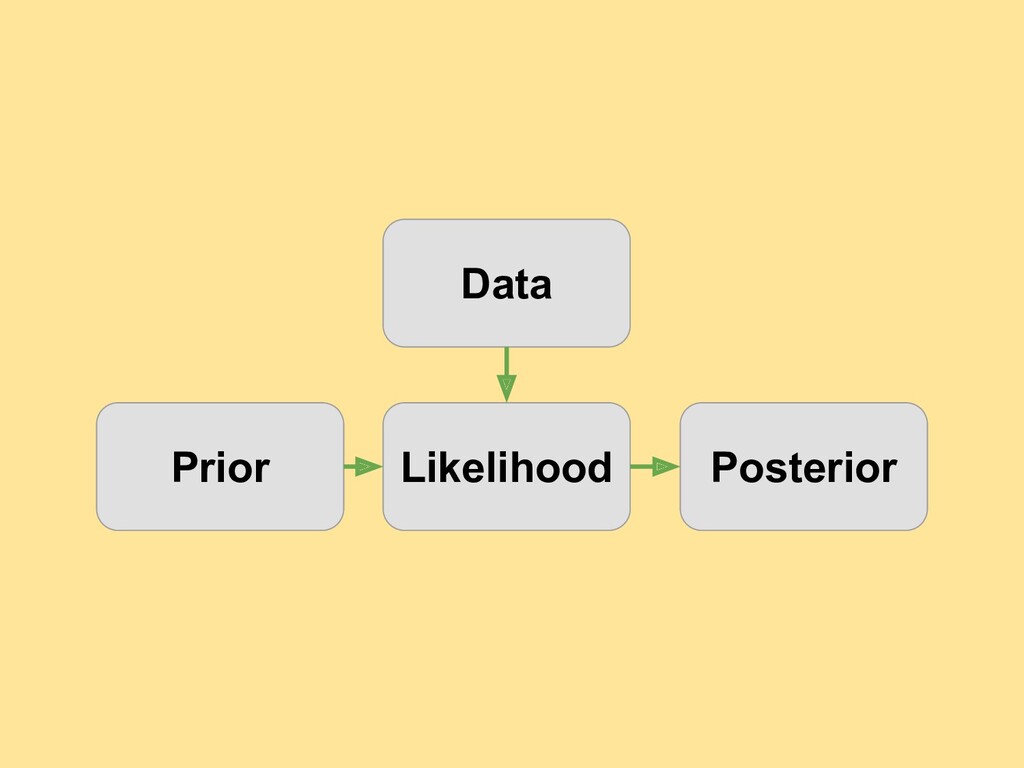
This is a presentation targeted at Data Scientists who want to get started with Bayesian Analysis. The focus is on an intuitive understanding. 3 fully worked-out examples are included. The accompanying notebooks can be found at: https://github.com/Ram-N/Bayesian_PyMC3
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
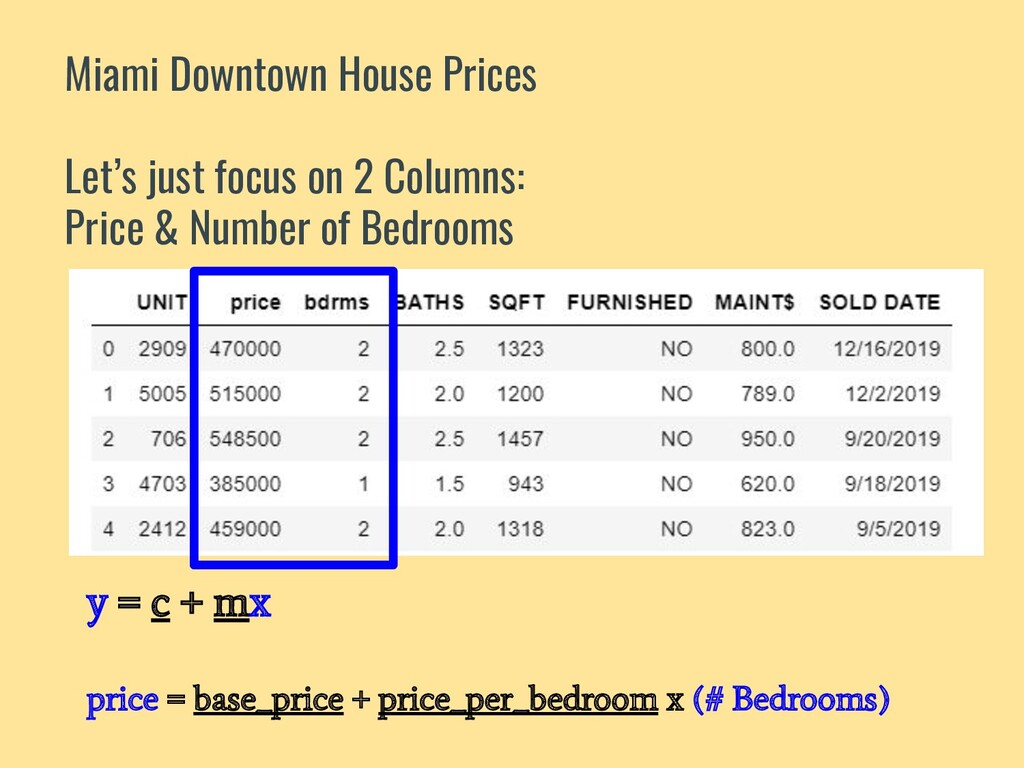
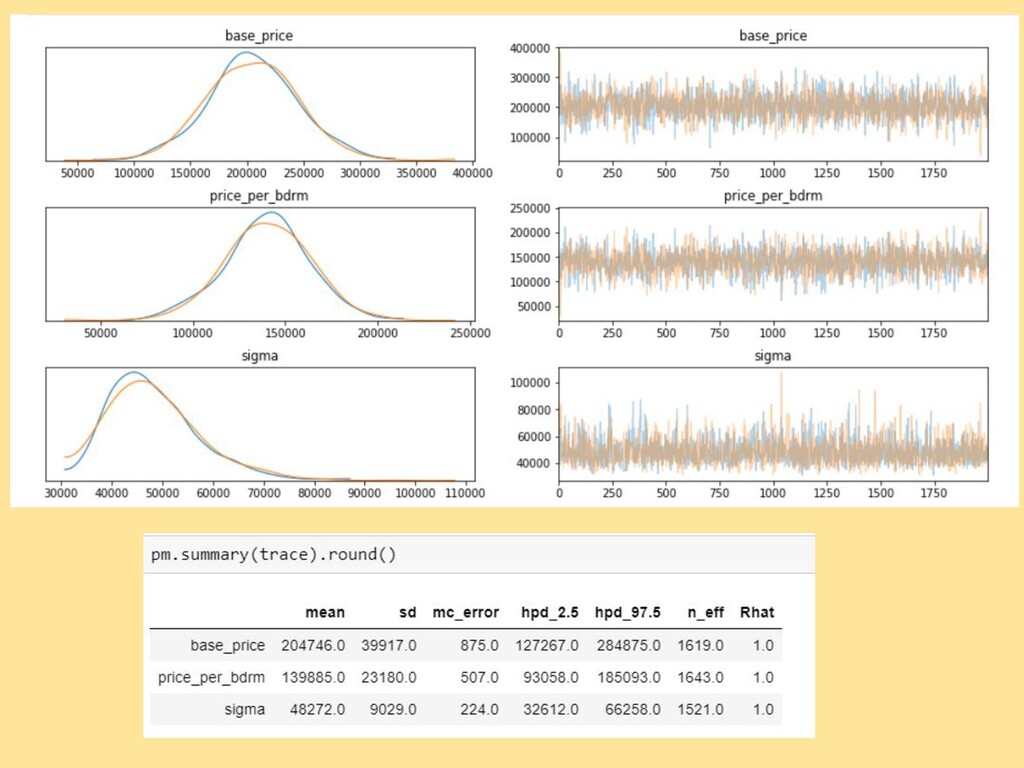
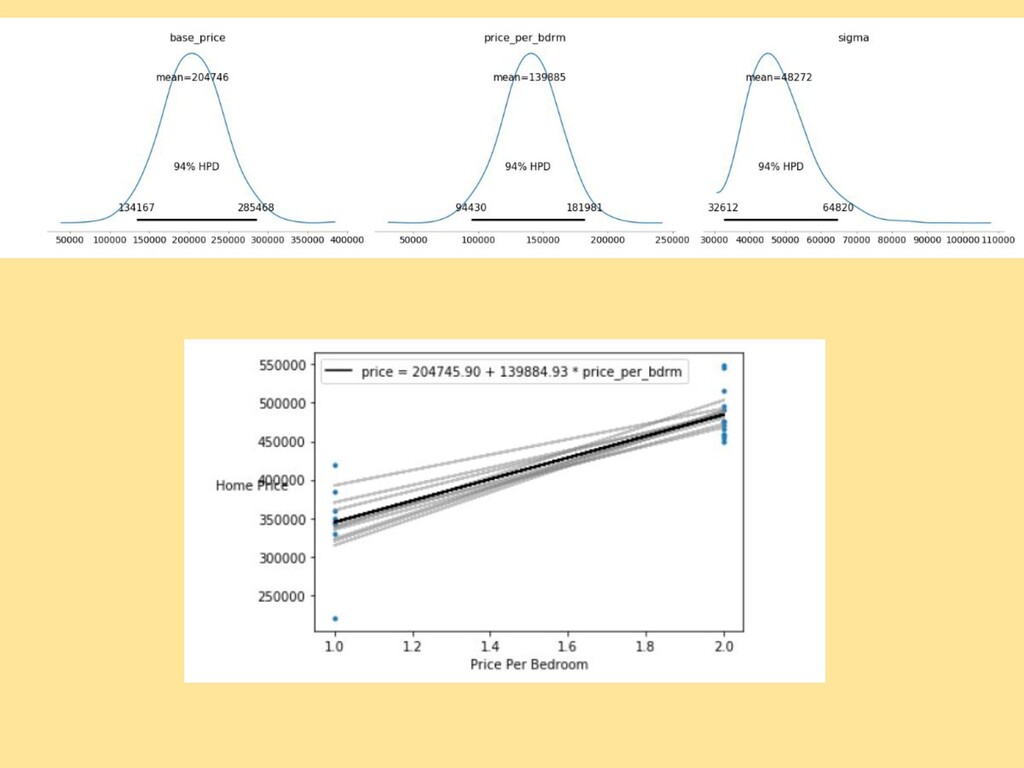
![#Read data using Pandas df = pd.read_csv('../data/home_sales.csv') bdrms = df['bdrms'].values](https://files.speakerdeck.com/presentations/d3dfbf9f11664eeb9fa096468ad759bc/slide_28.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
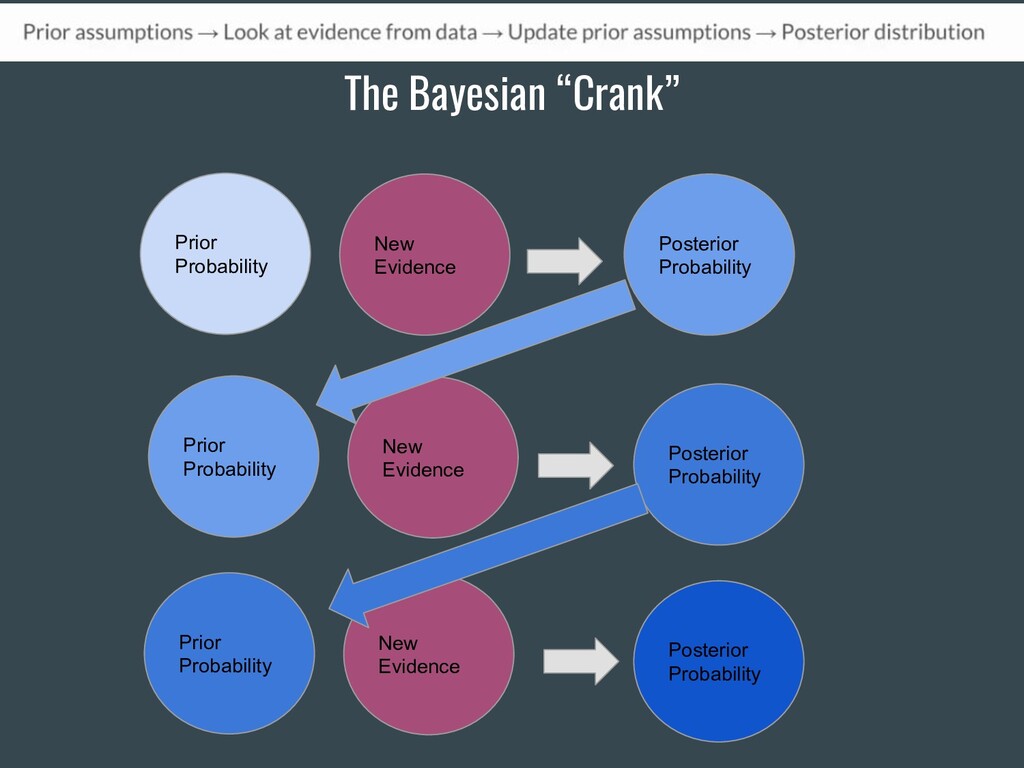{kind=link}
{kind=link}
{kind=link}
{kind=link}
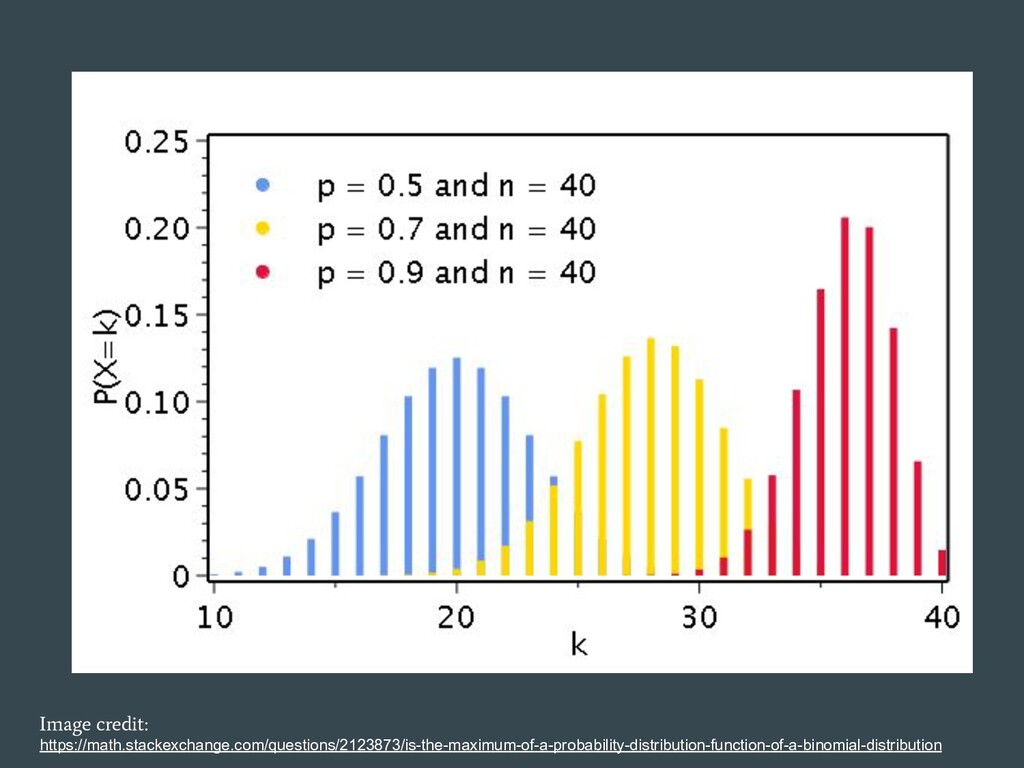{kind=link}
{kind=link}
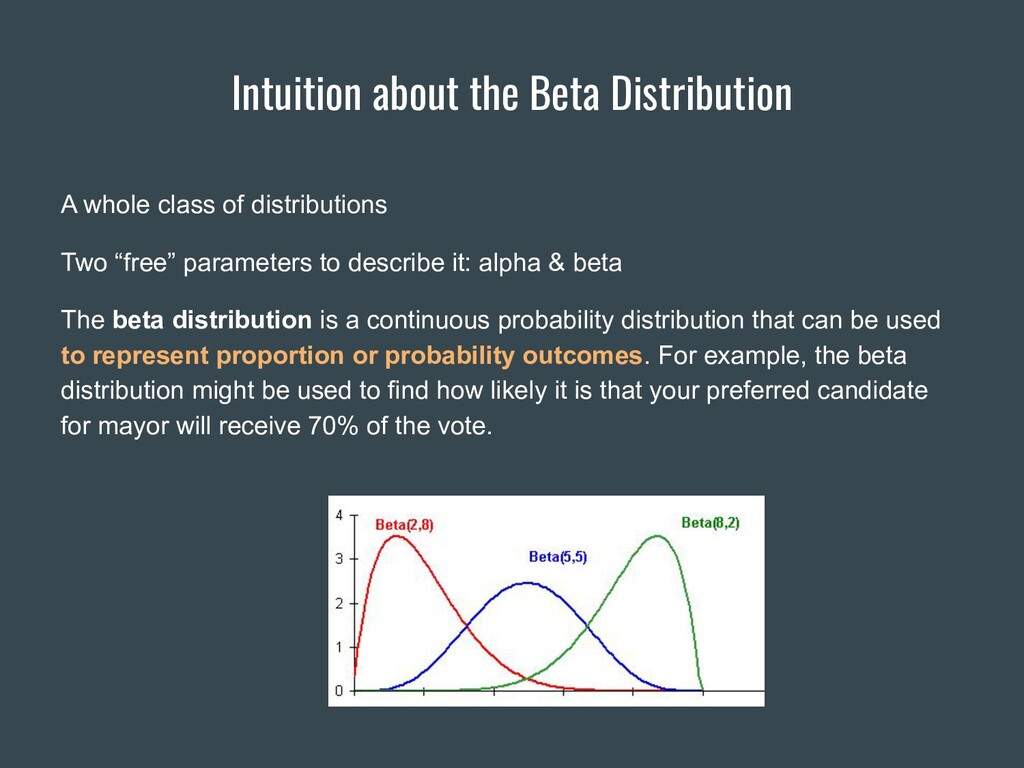{kind=link}
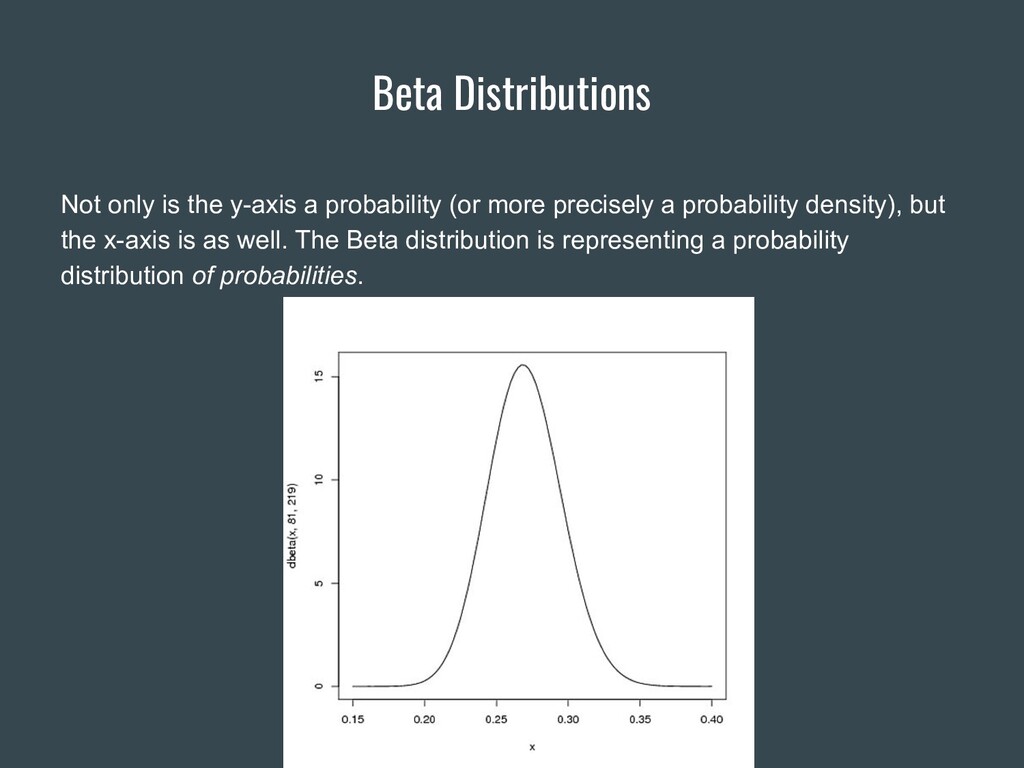{kind=link}
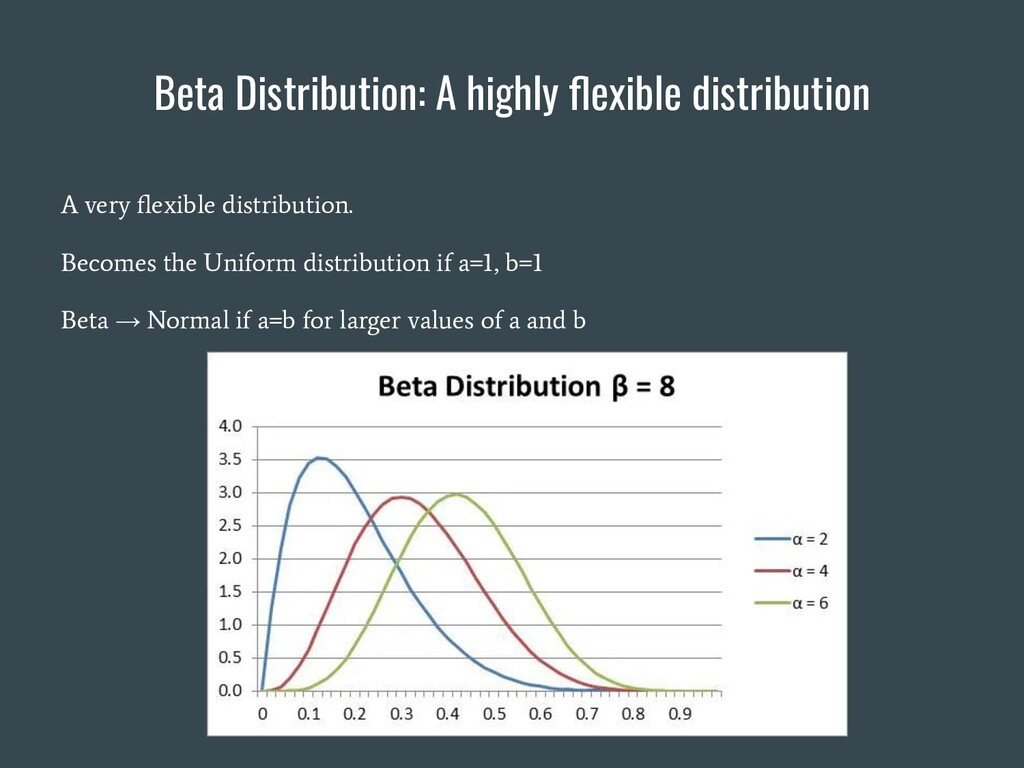{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![exploration_data = [0,0,0,1,0,0,0,0,0, 0,0,0,0,1,0,0,0,0] with pm.Model() as oil_exploration_model: θ =](https://files.speakerdeck.com/presentations/d3dfbf9f11664eeb9fa096468ad759bc/slide_52.jpg){kind=link}
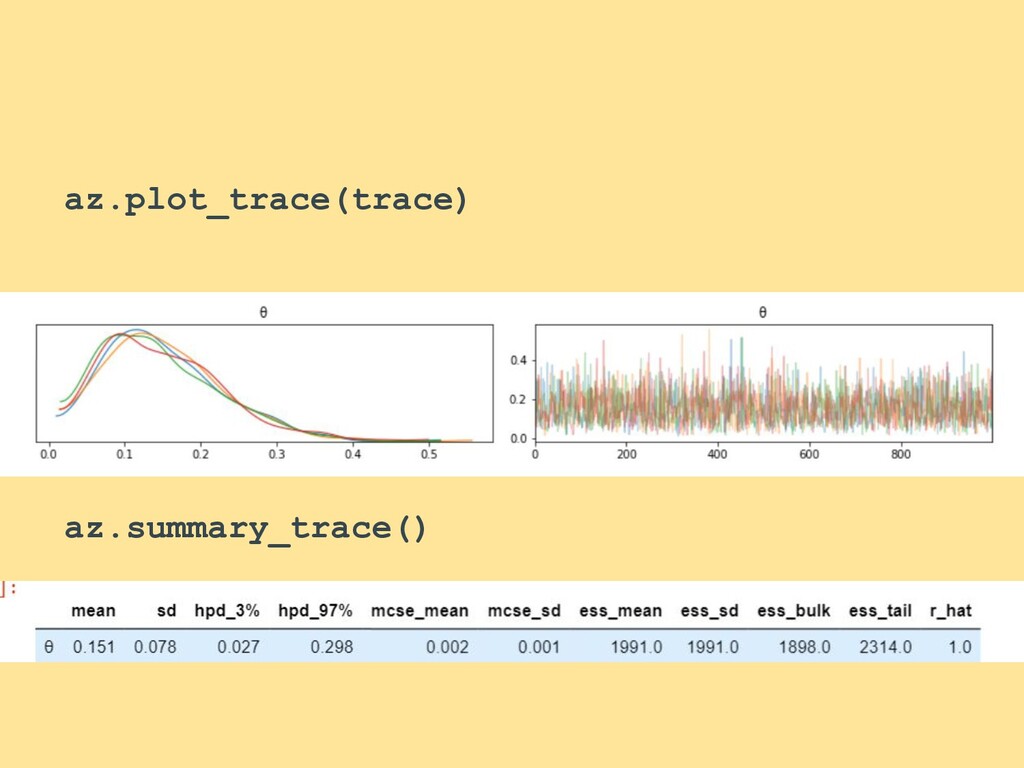{kind=link}
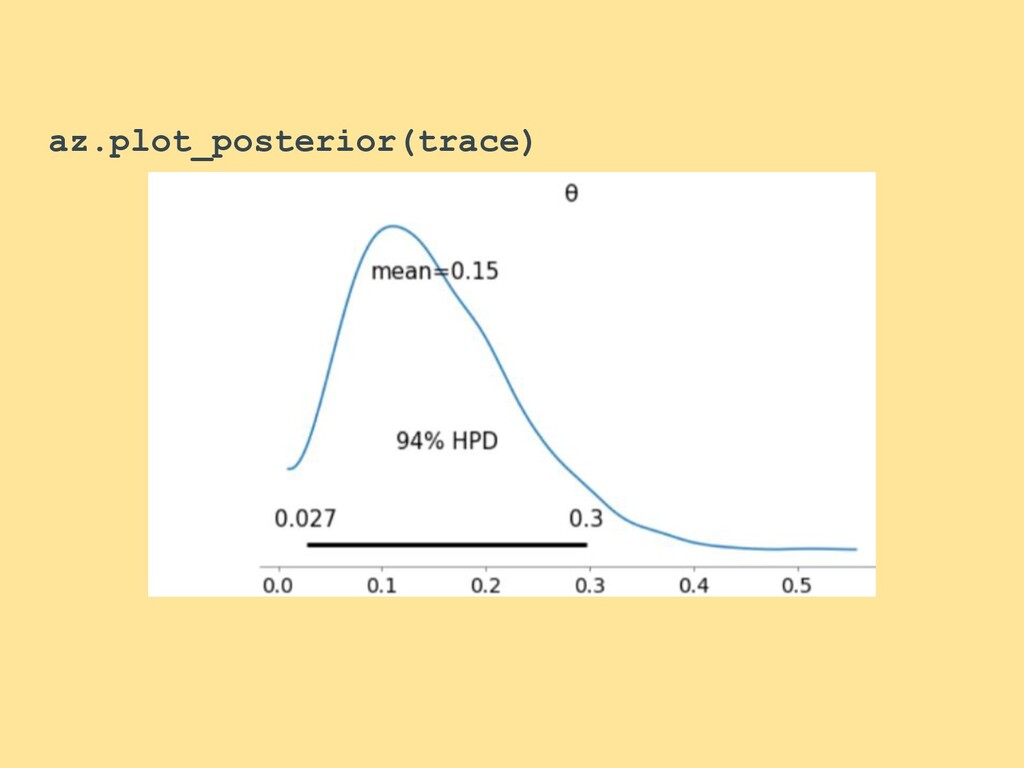{kind=link}
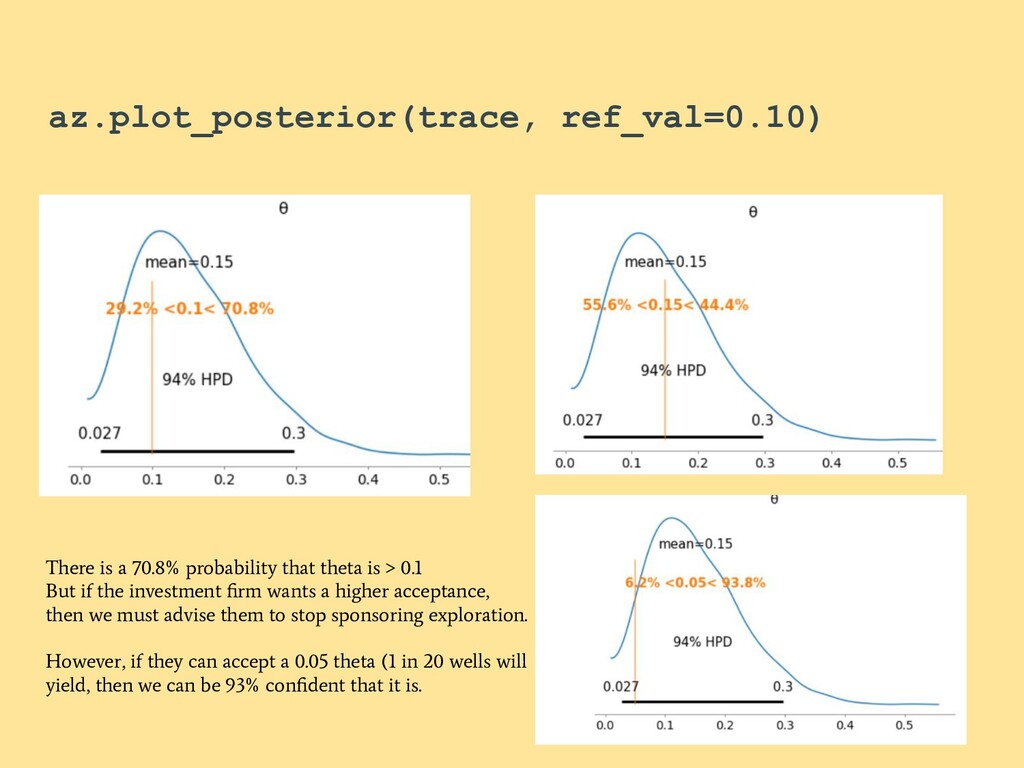{kind=link}
{kind=link}
{kind=link}
{kind=link}
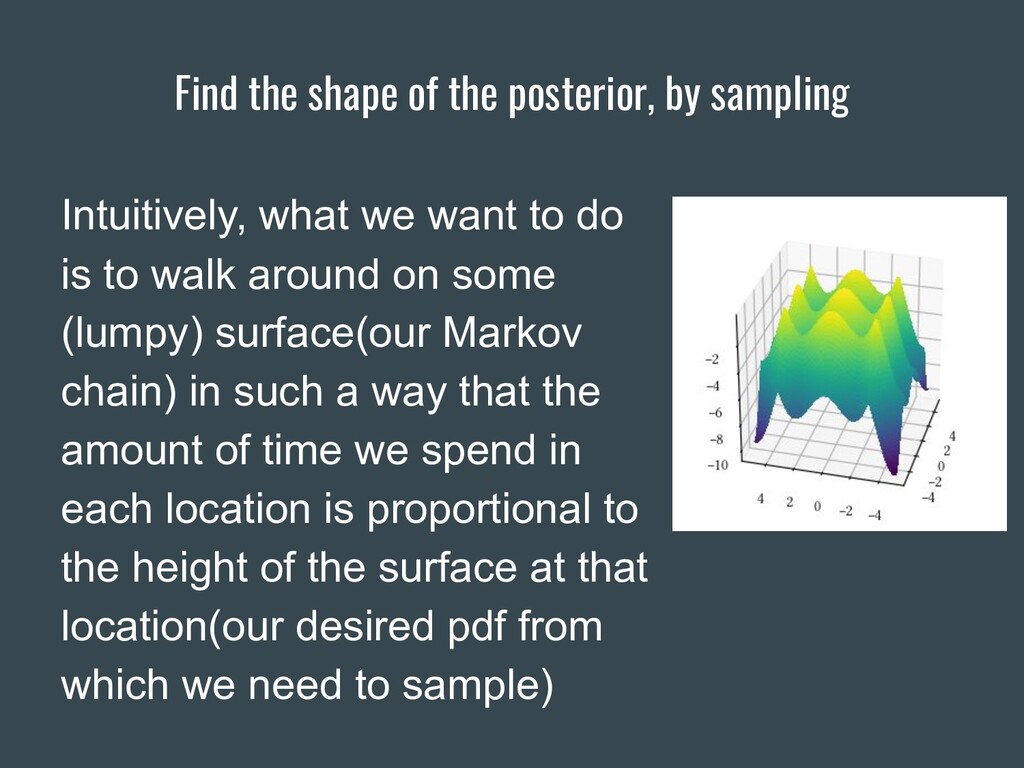{kind=link}
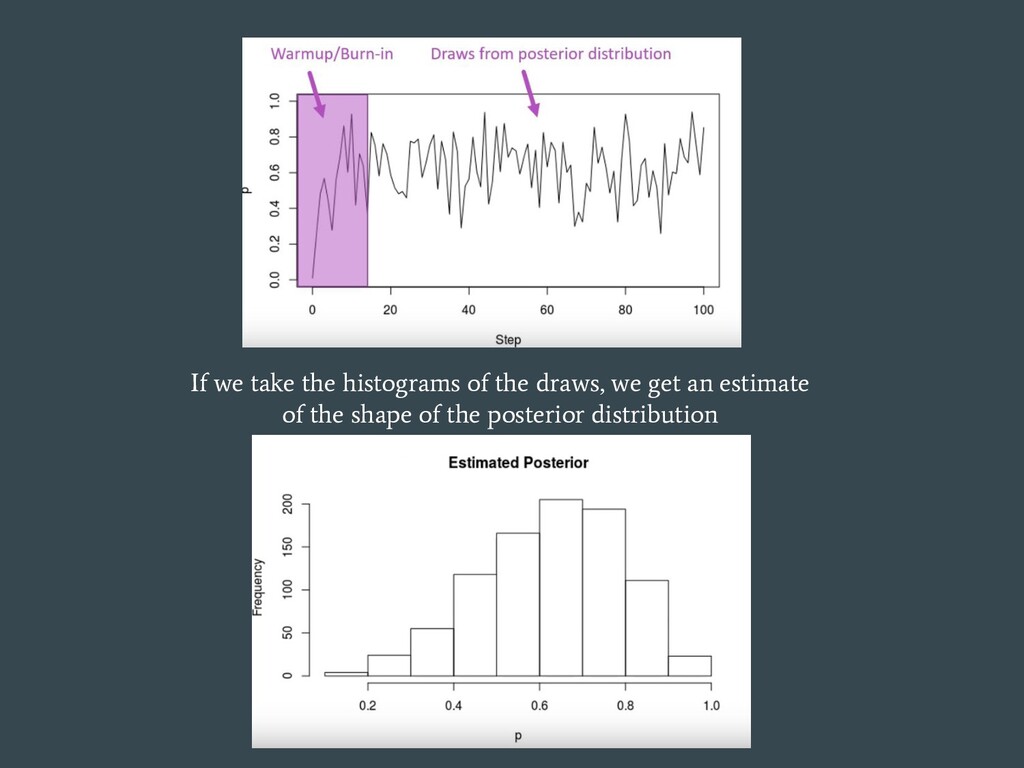{kind=link}
{kind=link}
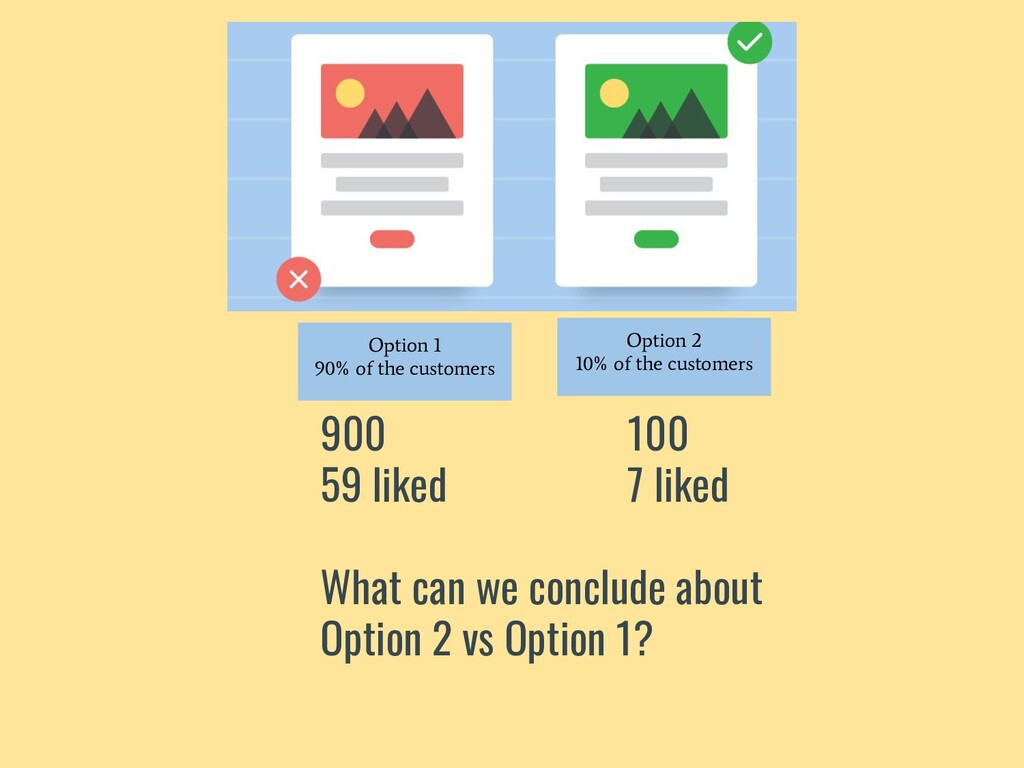{kind=link}
{kind=link}
{kind=link}
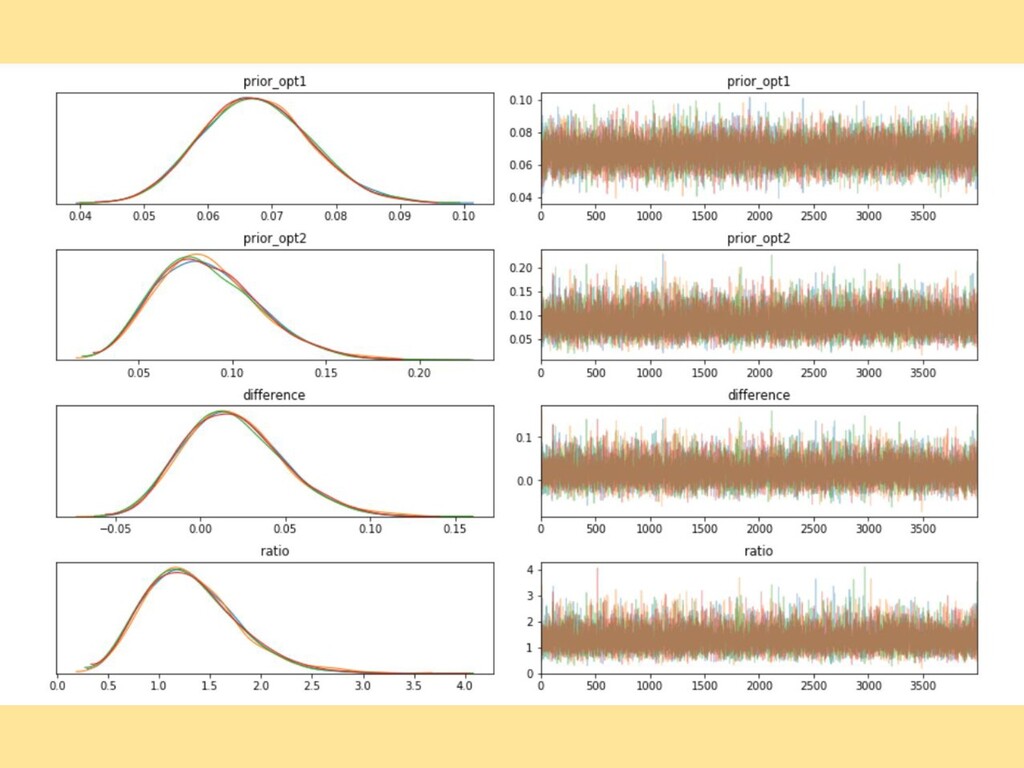{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
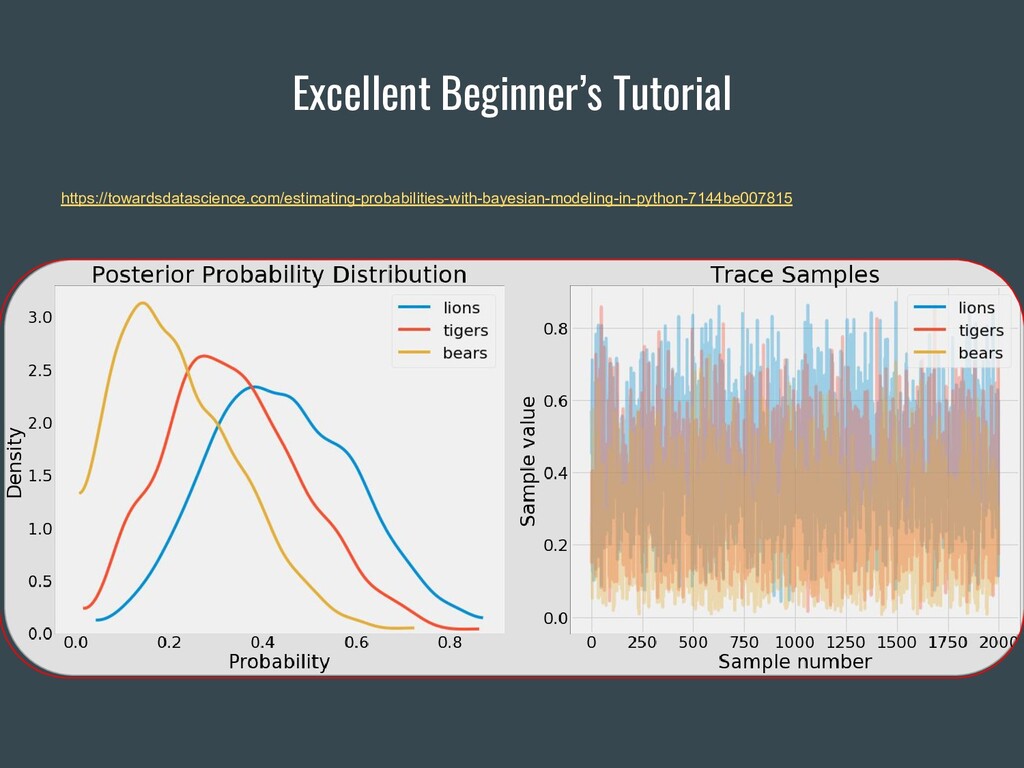{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}