Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
スタディサプリのデータ基盤を支えるETLとパイプラインの技術 / meetup_tanda
Search
Recruit
PRO
January 27, 2022
Technology
2.6k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
スタディサプリのデータ基盤を支えるETLとパイプラインの技術 / meetup_tanda
2022/01/27_スタディサプリのデータ基盤を支える技術 2022 -RECRUIT TECH MEET UP #3-での、丹田の講演資料になります
Recruit
PRO
January 27, 2022
More Decks by Recruit
See All by Recruit
開発が速く安くなった後の話 AI時代のソフトウェアエンジニアリング組織論 #devsumi
recruitengineers
PRO
4
890
双方向推薦システムにおける長期的マッチング最大化に向けた代理目的関数の設計と実証
recruitengineers
PRO
0
99
就職⽀援サービスにおけるキャリアアドバイザーのシフトスケジューリング
recruitengineers
PRO
1
180
Model Routerを使った逐次LLM選択による毀損低減効果の検証
recruitengineers
PRO
1
63
ストリーム処理基盤のFlink移行検証と適材適所の実践
recruitengineers
PRO
2
110
AI 時代の Platform Engineering
recruitengineers
PRO
2
460
巨大プラットフォームを進化させる「第3のROI」
recruitengineers
PRO
2
3.6k
データ戦略を加速させる プラットフォーム エンジニアリングと進化的アーキテクチャ
recruitengineers
PRO
2
110
まなび領域における生成AI活用事例
recruitengineers
PRO
2
320
Other Decks in Technology
See All in Technology
Zoom2Youtube.Claude
kawaguti
PRO
3
490
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
170
AICoEでAIネイティブ組織への進化
yukiogawa
0
160
Keeping applications secure by evolving OAuth 2.0 and OpenID Connect
ahus1
PRO
1
160
Claude Codeとハーネスについて考えてみる
oikon48
18
9.3k
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
290
プロンプト_きのこカンファレンス2026_LT
yurufuwahealer
0
150
Control Planeで育てるBtoB SaaSの認証基盤 - SRE NEXT 2026
pokohide
1
2.3k
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
2
170
Baseline対応のDOMの型定義を作った
uhyo
3
740
AI時代の EM への処方箋
staka121
PRO
0
130
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.6k
Featured
See All Featured
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
420
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
ピンチをチャンスに:未来をつくるプロダクトロードマップ #pmconf2020
aki_iinuma
128
56k
Un-Boring Meetings
codingconduct
0
340
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Paper Plane
katiecoart
PRO
2
52k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
GitHub's CSS Performance
jonrohan
1033
470k
Ethics towards AI in product and experience design
skipperchong
2
330
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
Transcript
#Rtech スタディサプリのデータ基盤を支える データパイプラインの技術と運用 丹田 尋 スタディサプリのデータ基盤を支える技術 2022 ーRECRUIT TECH MEET
UP #3ー
#Rtech 2020年リクルート新卒入社。 データ基盤の開発・運用、移管プロジェクト などに携わり、現在は MLOps 周りも担 当。 MLを用いた顧客スコア算出・活用のプロ ジェクトにも参画。 丹田
尋
#Rtech Agenda | 01 02 03 04 データ基盤を支えるデータパイプラインの概要 パフォーマンス面での4つの工夫 データ基盤運用面での4つの工夫
まとめと今後の展望
#Rtech データ基盤を支える データパイプラインの概要 01
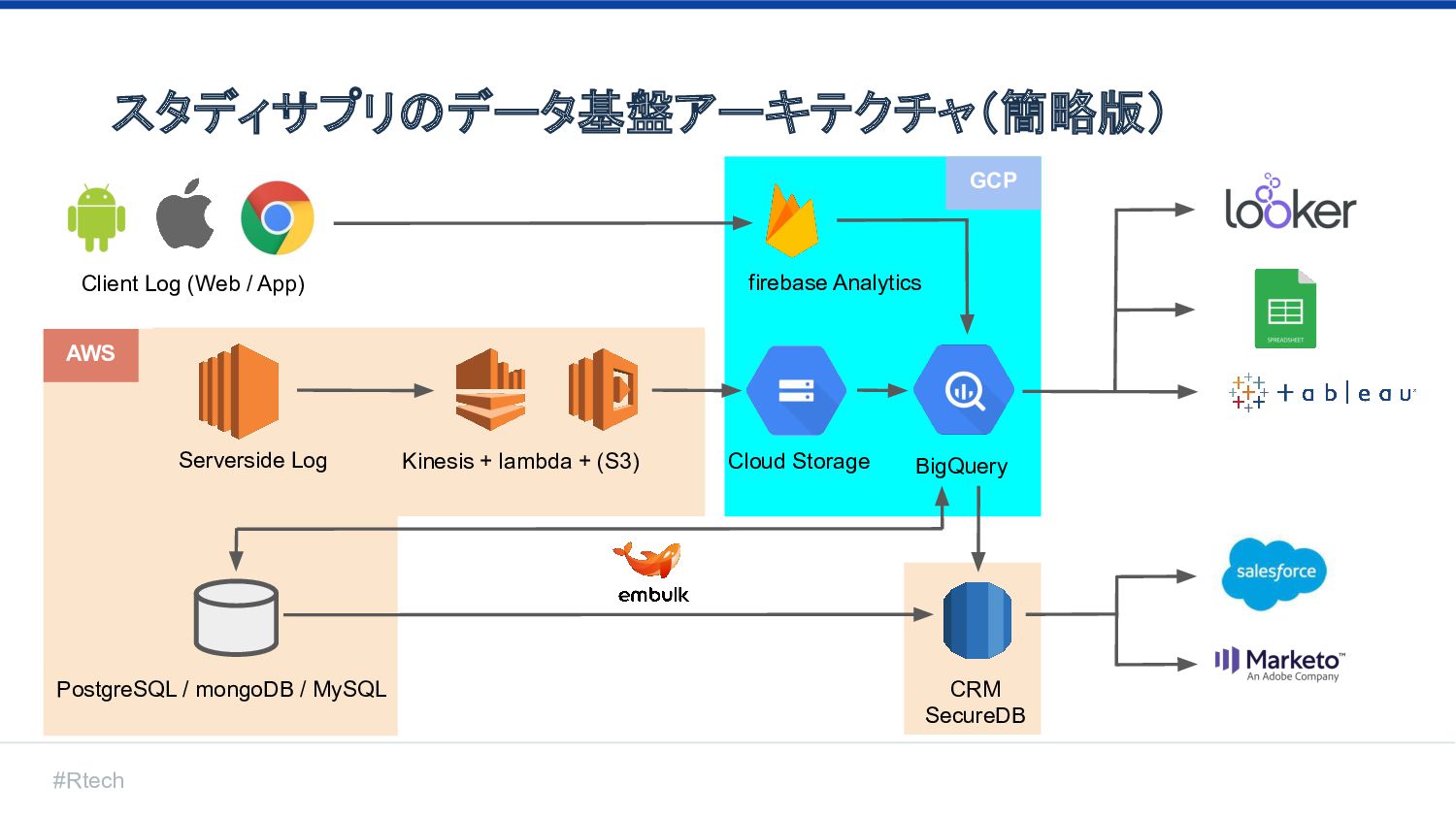
#Rtech スタディサプリのデータ基盤アーキテクチャ(簡略版) Kinesis + lambda + (S3) Serverside Log firebase
Analytics Client Log (Web / App) Cloud Storage BigQuery AWS GCP PostgreSQL / mongoDB / MySQL CRM SecureDB
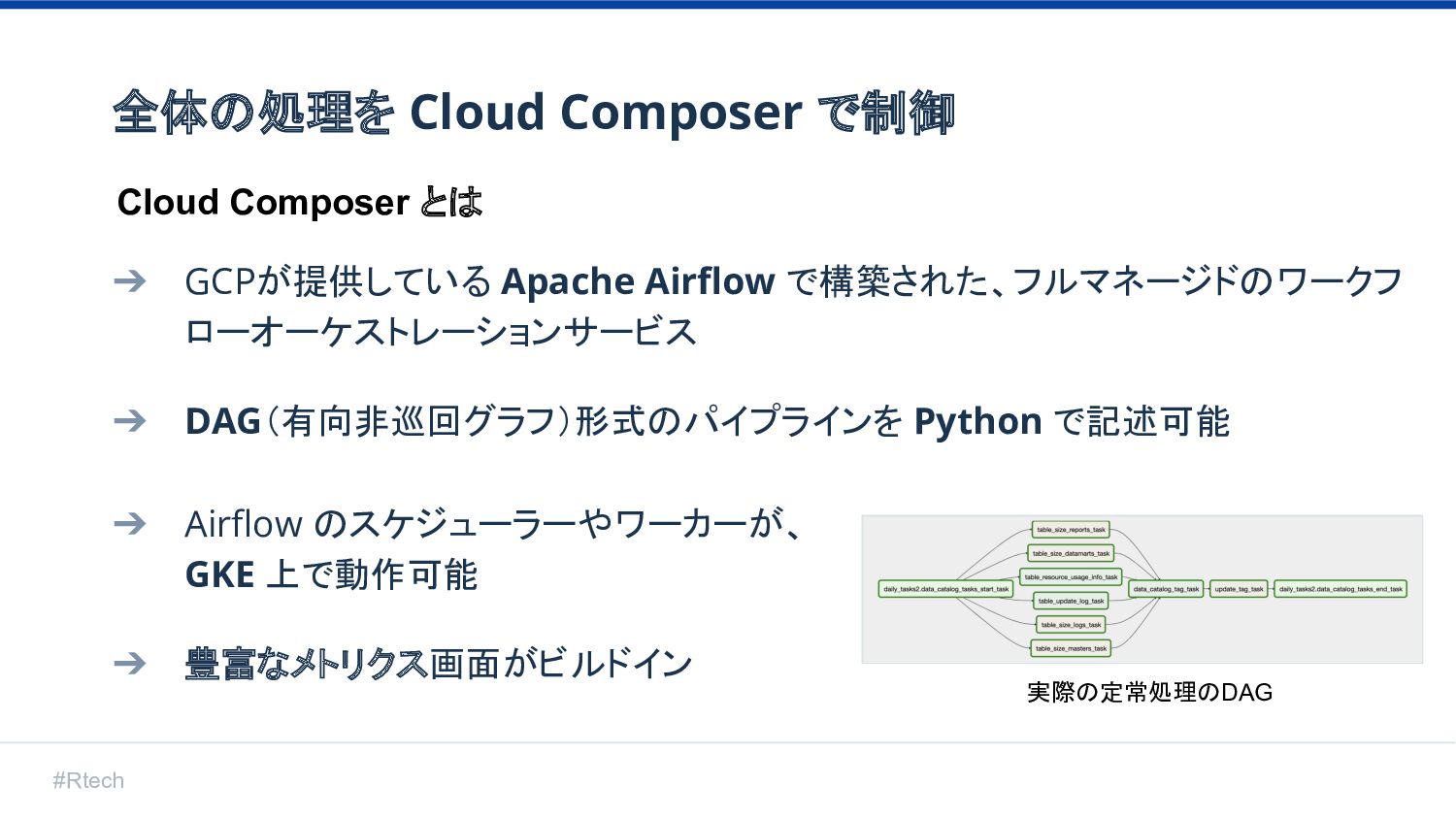
#Rtech 全体の処理を Cloud Composer で制御 ➔ GCPが提供している Apache Airflow で構築された、フルマネージドのワークフ
ローオーケストレーションサービス ➔ DAG(有向非巡回グラフ)形式のパイプラインを Python で記述可能 ➔ Airflow のスケジューラーやワーカーが、 GKE 上で動作可能 ➔ 豊富なメトリクス画面がビルドイン Cloud Composer とは 実際の定常処理のDAG
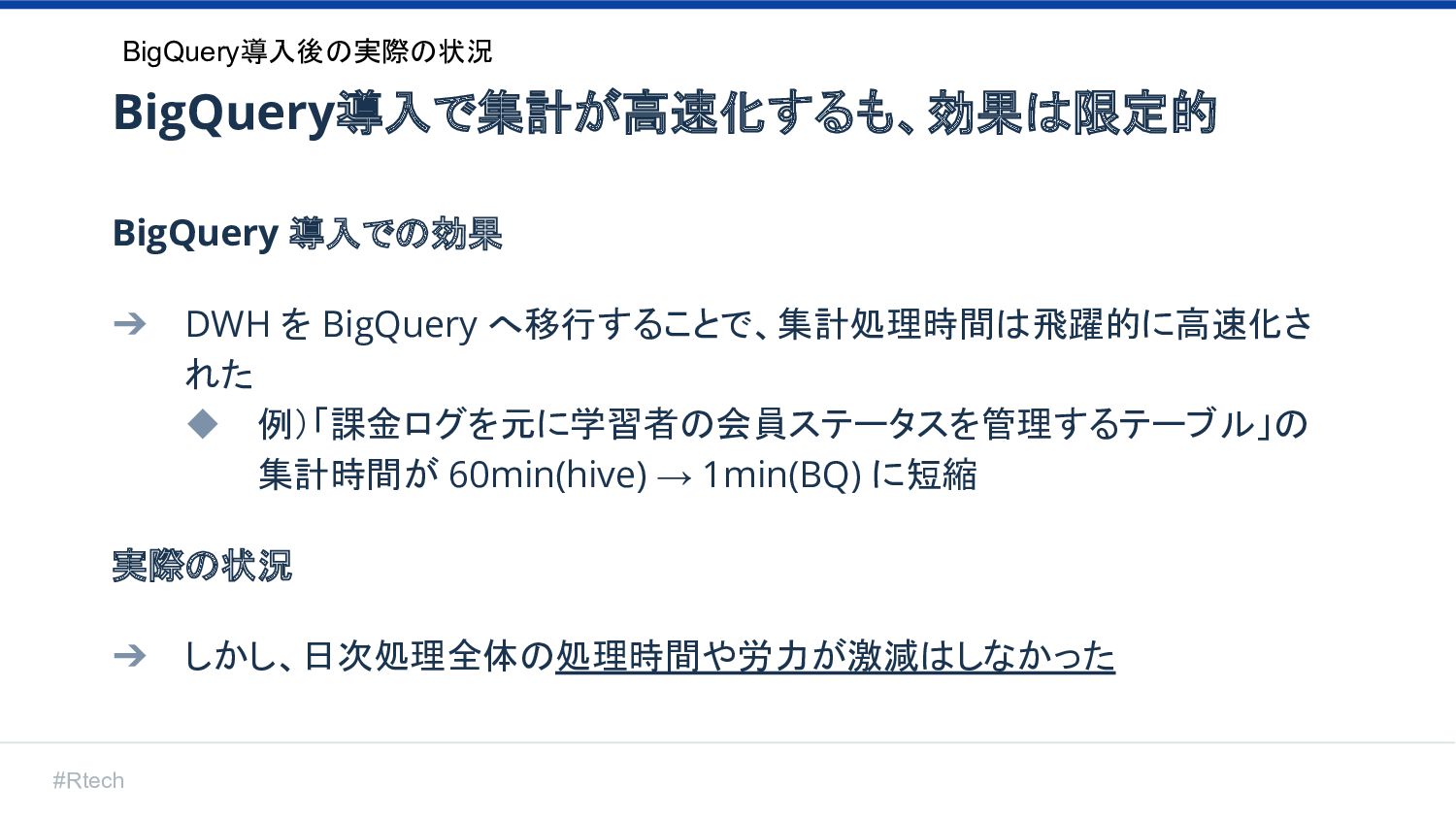
#Rtech BigQuery導入で集計が高速化するも、効果は限定的 BigQuery 導入での効果 ➔ DWH を BigQuery へ移行することで、集計処理時間は飛躍的に高速化さ れた
◆ 例)「課金ログを元に学習者の会員ステータスを管理するテーブル」の 集計時間が 60min(hive) → 1min(BQ) に短縮 実際の状況 ➔ しかし、日次処理全体の処理時間や労力が激減はしなかった BigQuery導入後の実際の状況
#Rtech データ転送処理がボトルネックになっている ➔ 日次処理時間の大半が BashOperator で 占めており、BigQueryOperator は短い ➔ BashOperator
は、データ転送のタスクがほ とんど データ転送処理のパフォーマンスが改善できれ ば、全体の高速化が見込める BashOperator(27.3h) BigQueryOperator(2.8h) Composer での 日次処理時間の内訳 パフォーマンス面での課題
#Rtech データ定常処理を支える運用の負担が大きい 運用面での課題 運用面での課題 実際に直面した苦労・失敗 ① 利用者との期待値調整ができておらず、 運用者も努力目標が不明確 • 集計が遅延した時、どのレベルで誰に周知していいか悩んだ
② リソース管理 や CI/CD が不十分で、 障害発生のリスクがあった • オペミスにより本番環境に不要なファイルがデプロイされ定常 処理が止まる • 新たなインスタンスを立てたらモジュールがインストールされて おらず処理が止まった ③ 障害の検知に遅れることがあった • 定常処理のステータスが瞬時に把握できない • ディスク不足やネットワークのポートの枯渇などの把握に遅 れ、障害が発生 ④ 障害対応がスムーズに行かない • 障害復旧が職人芸化され、属人化している部分があった
#Rtech データの定常処理を効率化する パフォーマンス面・運用面での Tips を紹介します 今回のテーマ
#Rtech パフォーマンス面での4つの工夫 02
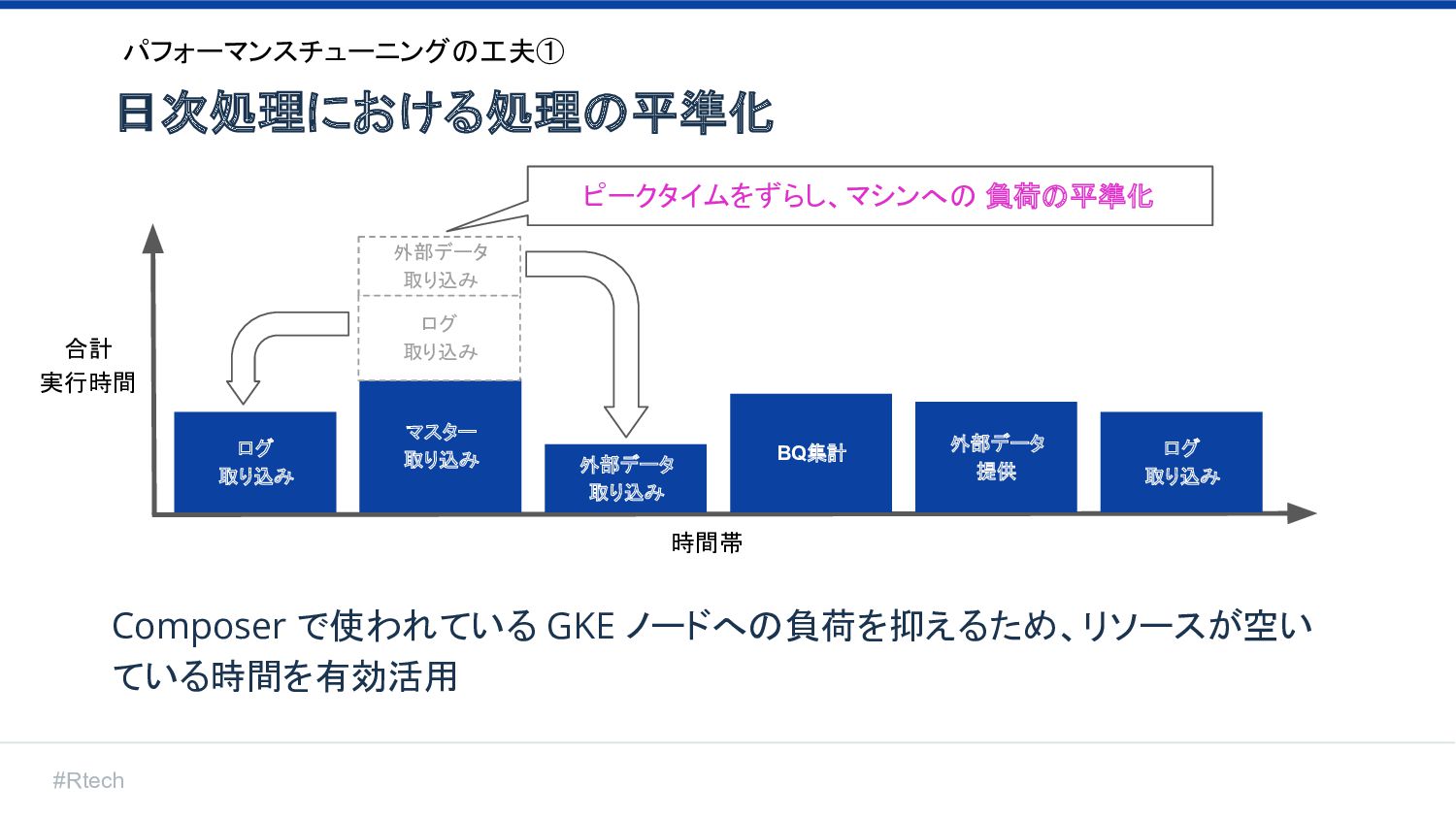
#Rtech 日次処理における処理の平準化 合計 実行時間 時間帯 ログ 取り込み マスター 取り込み 外部データ
取り込み BQ集計 外部データ 提供 ログ 取り込み ログ 取り込み 外部データ 取り込み ピークタイムをずらし、マシンへの 負荷の平準化 パフォーマンスチューニングの工夫① Composer で使われている GKE ノードへの負荷を抑えるため、リソースが空い ている時間を有効活用
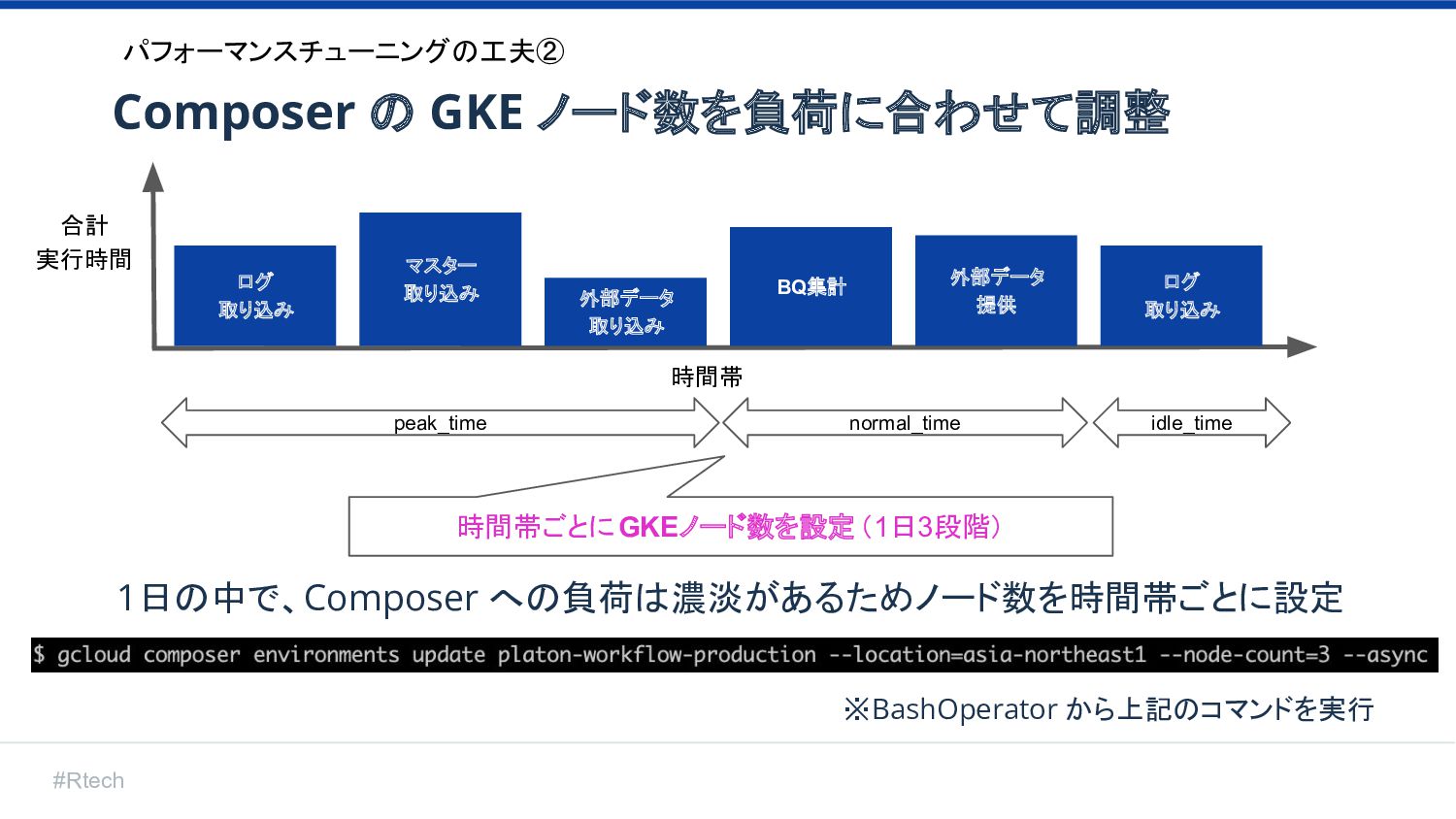
#Rtech 合計 実行時間 時間帯 ログ 取り込み マスター 取り込み 外部データ 取り込み
BQ集計 外部データ 提供 ログ 取り込み peak_time normal_time idle_time 時間帯ごとにGKEノード数を設定(1日3段階) パフォーマンスチューニングの工夫② 1日の中で、Composer への負荷は濃淡があるためノード数を時間帯ごとに設定 Composer の GKE ノード数を負荷に合わせて調整 ※BashOperator から上記のコマンドを実行
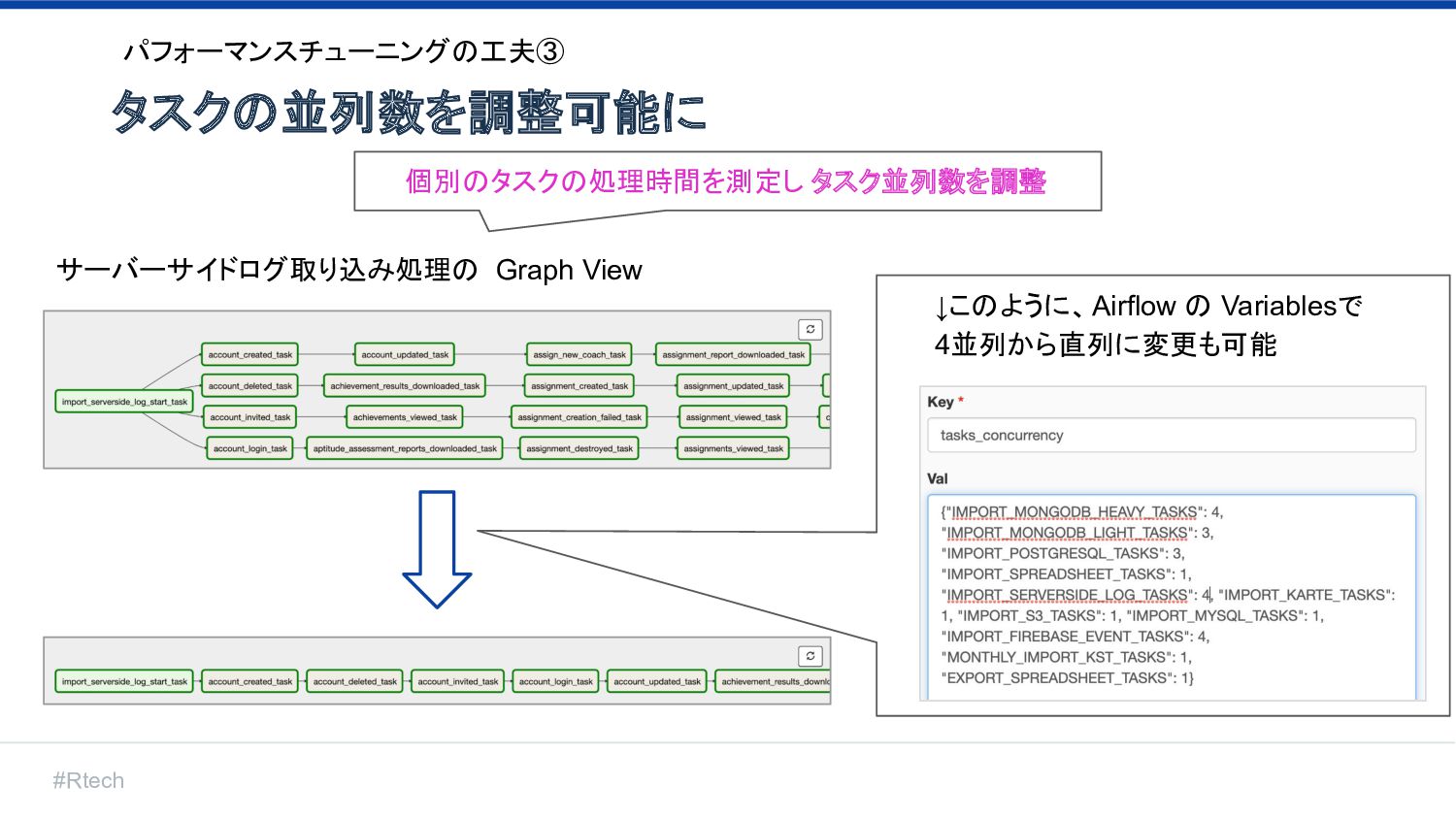
#Rtech タスクの並列数を調整可能に パフォーマンスチューニングの工夫③ 個別のタスクの処理時間を測定し タスク並列数を調整 ↓このように、Airflow の Variablesで 4並列から直列に変更も可能 サーバーサイドログ取り込み処理の
Graph View
#Rtech Embulk を Cloud Run で実行 パフォーマンスチューニングの工夫④ ➔ 複数処理による同一リソースの食い合いをサーバーレス化で解決 ◆
処理の高速化 ➔ 必要な時に必要な分だけリソースを確保してくれる ◆ コスト面での大幅削減 ◆ スケーラビリティの拡充 Cloud Run
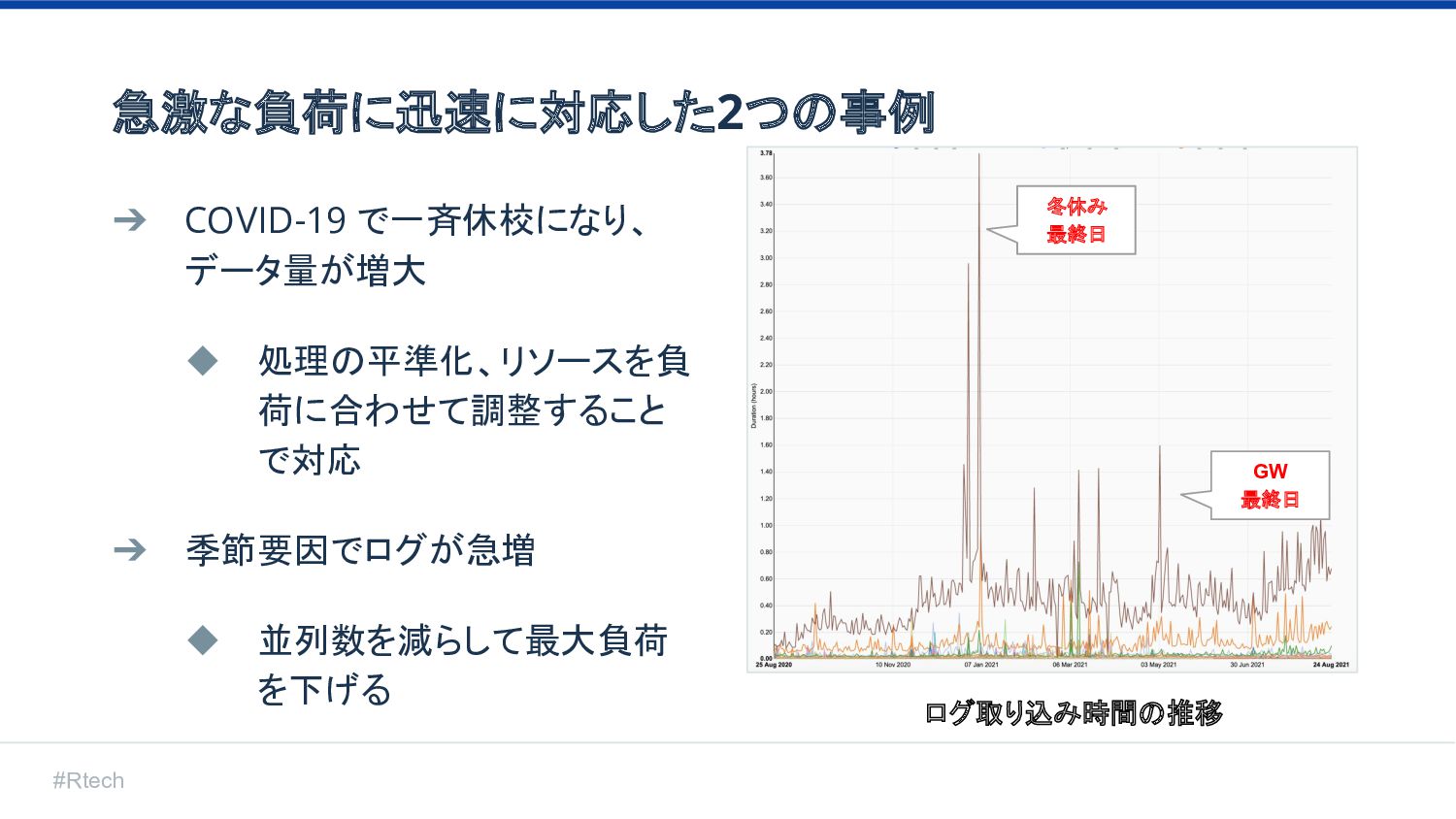
#Rtech 急激な負荷に迅速に対応した2つの事例 ➔ COVID-19 で一斉休校になり、 データ量が増大 ◆ 処理の平準化、リソースを負 荷に合わせて調整すること で対応
➔ 季節要因でログが急増 ◆ 並列数を減らして最大負荷 を下げる 冬休み 最終日 GW 最終日 ログ取り込み時間の推移
#Rtech データ基盤運用面での4つの工夫 03
#Rtech データ定常処理を支える運用の負担が大きい(再掲) 運用面での課題 運用面での課題 実際に直面した苦労・失敗 ① 利用者との期待値調整ができておらず、 運用者も努力目標が不明確 • 集計が遅延した時、どのレベルで誰に周知していいか悩んだ
② リソース管理 や CI/CD が不十分で、 障害発生のリスクがあった • オペミスにより本番環境に不要なファイルがデプロイされ定常 処理が止まる • 新たなインスタンスを立てたらモジュールがインストールされて おらず処理が止まった ③ 障害の検知に遅れることがあった • 定常処理のステータスが瞬時に把握できない • ディスク不足やネットワークのポートの枯渇などの把握に遅 れ、障害が発生 ④ 障害対応がスムーズに行かない • 障害復旧が職人芸化され、属人化している部分があった
#Rtech SLAを定め、モニタリングする データ基盤運用面の工夫① ➔ データのステークホルダーと協議し 主要データを何時までに提供する か合意し期待値調整をする ➔ 障害の条件を定義し、半年間のSLA をチームで決める
➔ 週次定例でチームメンバー全員で SLAの実績を確認 SLA (1) 10時時点で、Table Aが作成されていること (2) 12時時点で、spreadsheet吐き出しタスクが完了し ていること (3) 13時時点で、集計データの外部連携まで完了して いること
#Rtech CI/CDとインフラコード化を徹底し、障害を予防 ➔ CI/CDツールとして Cloud Build を導入 ◆ クエリチェック、パイプラインチェック、構文チェックを行う •
過去のしくじり:Python ファイルのエラーでDAGが壊れ定常処理 が走らない ◆ Composer , Cloud Run へのデプロイを自動で行う • 過去のしくじり:デプロイ先がファイルの変更箇所に応じて2箇所あ り、デプロイ忘れが発生 ➔ Terraform でのGCPコンポーネント管理 ◆ 構成の再現性を担保 データ基盤運用面の工夫②
#Rtech 監視項目を整理し、アラート設定をして障害を迅速に検知 データ基盤運用面の工夫③ ➔ Airflow の Operator の成功/失敗コールバックに Slack のPOST処理をか
ませる ➔ 重要なテーブルデータの整合性を検証するタスクを設け Slack 通知 ◆ 過去のしくじり • Operator は成功しているが、中身のデータが不整合だった ➔ DAGの重複依存関係や Composer でのエラーアラートを設定
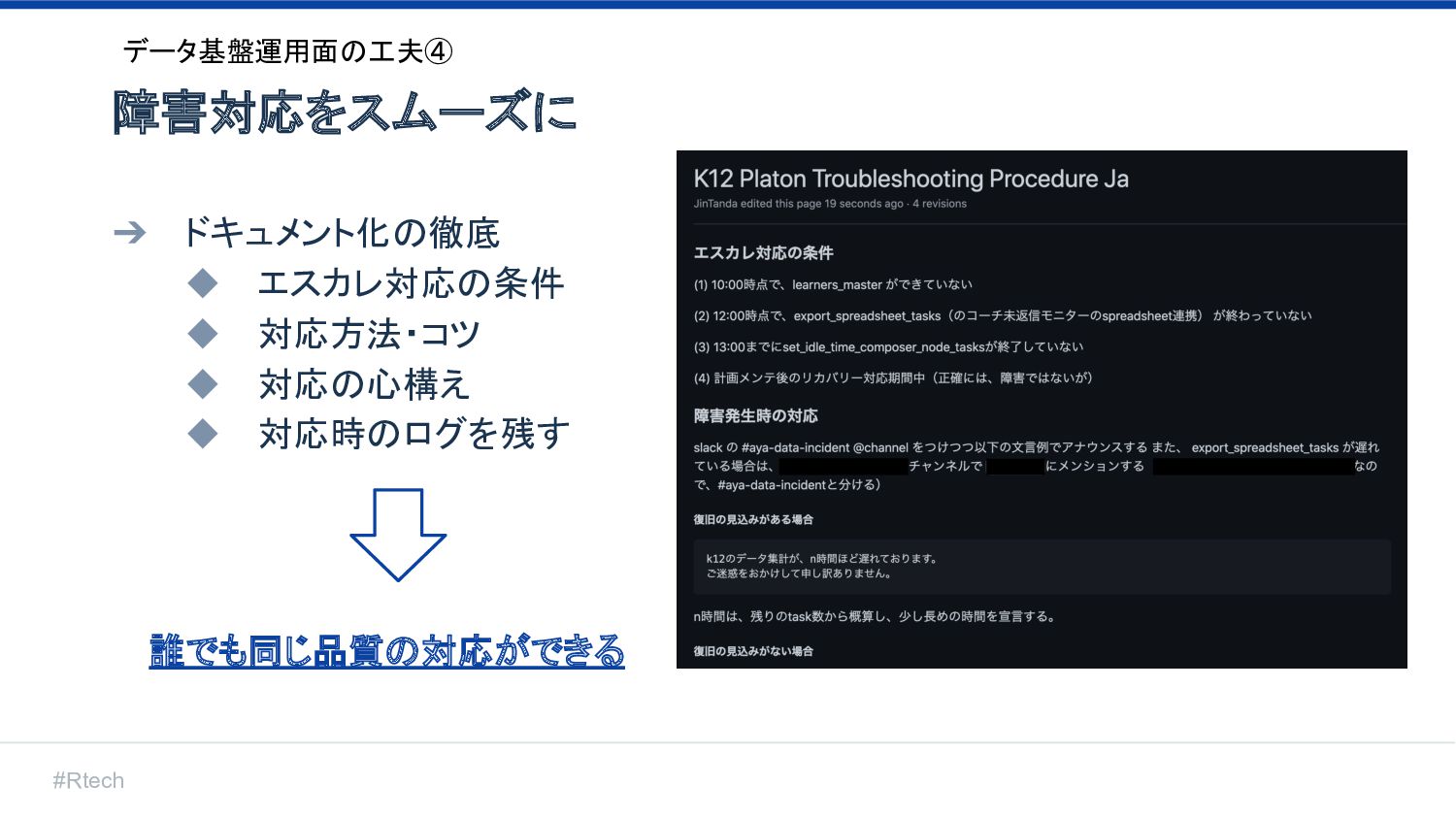
#Rtech 障害対応をスムーズに データ基盤運用面の工夫④ ➔ ドキュメント化の徹底 ◆ エスカレ対応の条件 ◆ 対応方法・コツ ◆
対応の心構え ◆ 対応時のログを残す 誰でも同じ品質の対応ができる
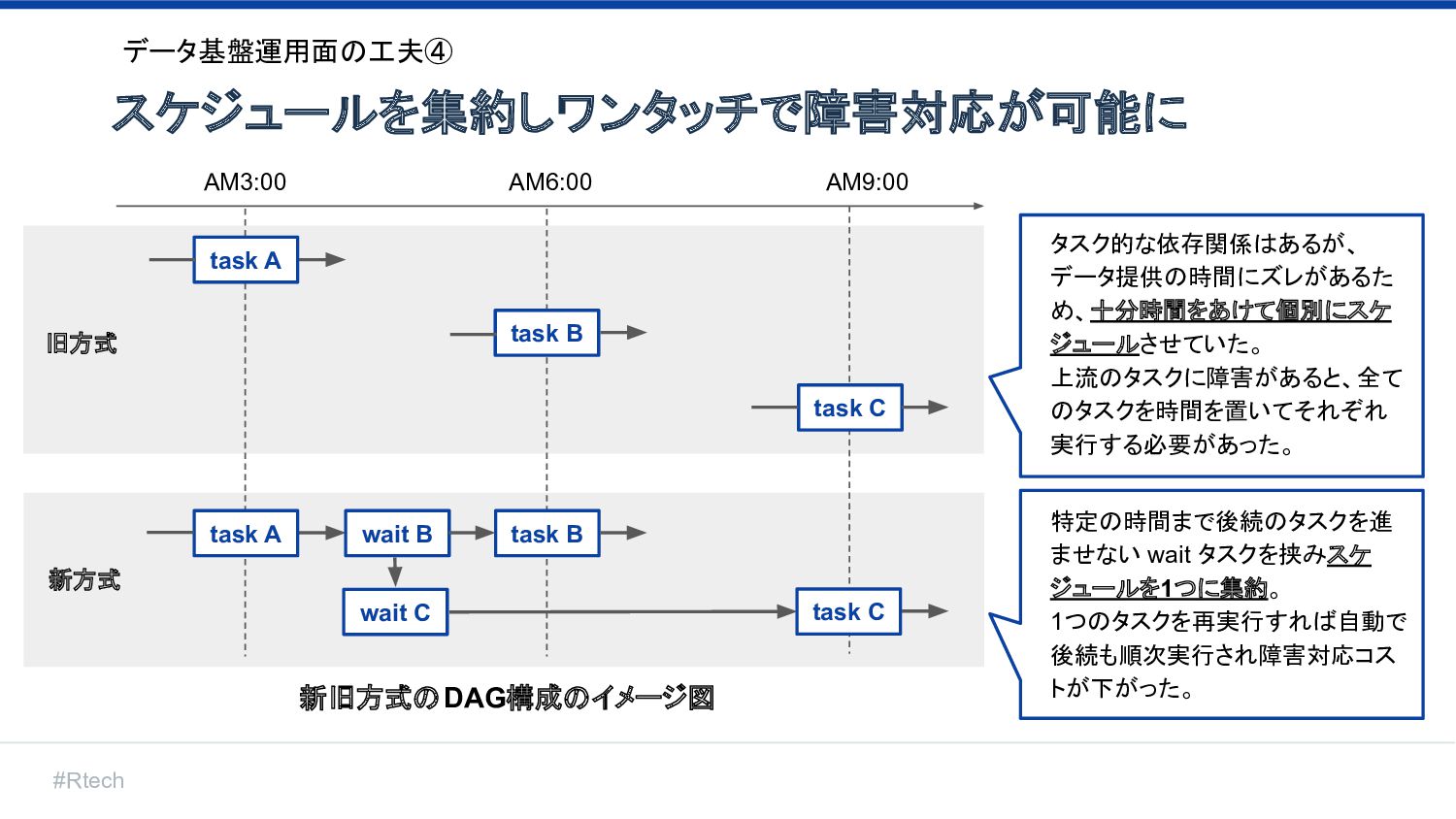
#Rtech スケジュールを集約しワンタッチで障害対応が可能に データ基盤運用面の工夫④ AM3:00 AM6:00 AM9:00 旧方式 新方式 タスク的な依存関係はあるが、 データ提供の時間にズレがあるた
め、十分時間をあけて個別にスケ ジュールさせていた。 上流のタスクに障害があると、全て のタスクを時間を置いてそれぞれ 実行する必要があった。 特定の時間まで後続のタスクを進 ませない wait タスクを挟みスケ ジュールを1つに集約。 1つのタスクを再実行すれば自動で 後続も順次実行され障害対応コス トが下がった。 task A task A wait B wait C task B task C task B task C 新旧方式のDAG構成のイメージ図
#Rtech 4つのポイントを仕組み化しPDCAをまわし属人化を解消 データ基盤運用面の工夫のまとめ ① SLA定義 & モニタリング整備 ② 障害の予防 ③
障害の検知 ④ 障害対応
#Rtech まとめと今後の展望 04
#Rtech データ処理のパフォーマンス面・運用面での改善を行った パフォーマンス面 運用面 ➔ 日次処理における処理の平準化 ➔ Composer のGKEノード数を負荷に合わせて 調整
➔ タスクの並列数を調整可能に ➔ Embulk を Cloud Run で実行 ➔ SLAを定め、モニタリングする ➔ CI/CDとインフラコード化を徹底し、障害を 予防 ➔ 監視項目を整理し、アラート設定をして障 害を迅速に通知 ➔ 障害をワンタッチで対応可能に まとめ
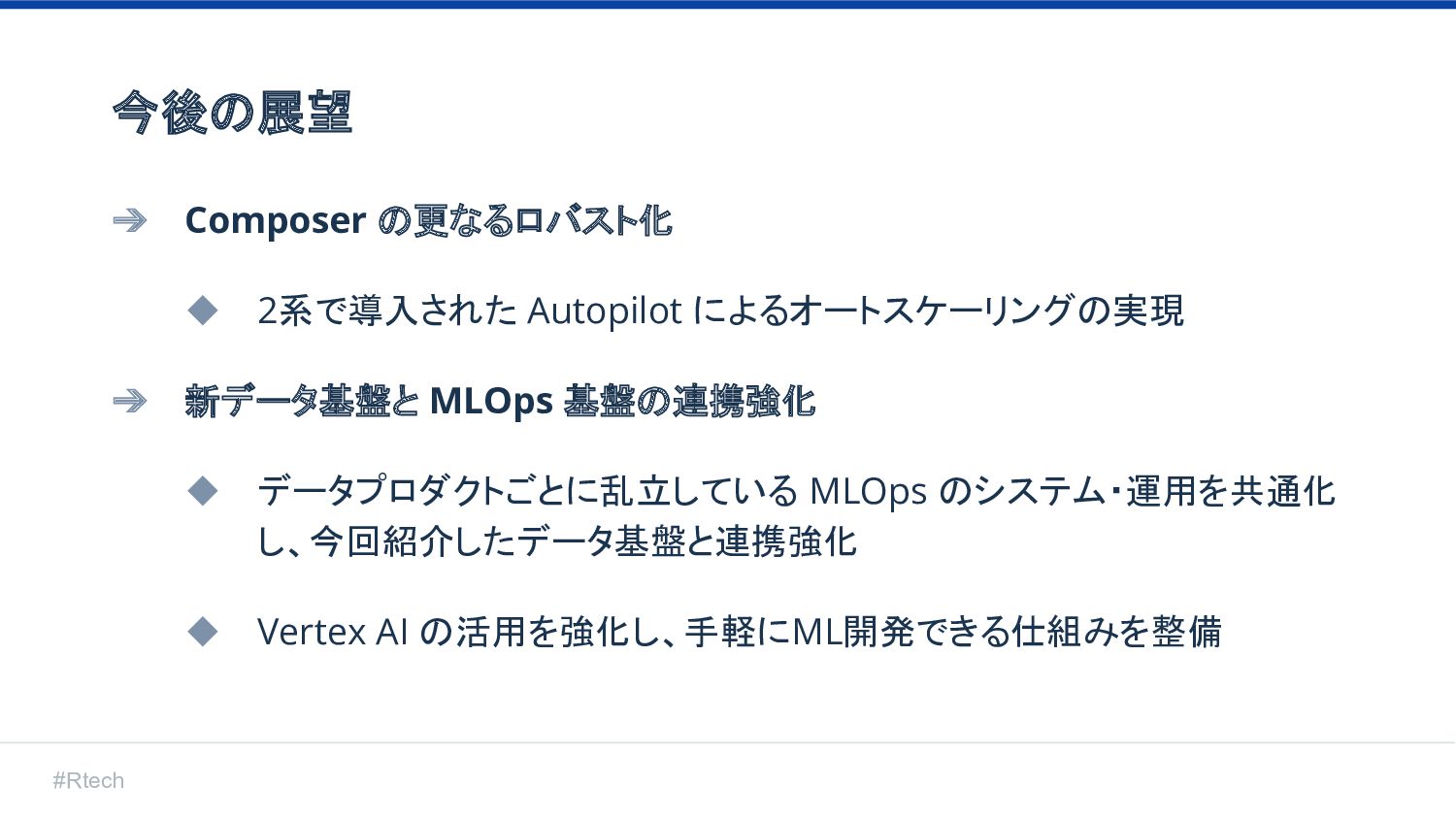
#Rtech 今後の展望 ➔ Composer の更なるロバスト化 ◆ 2系で導入された Autopilot によるオートスケーリングの実現 ➔
新データ基盤と MLOps 基盤の連携強化 ◆ データプロダクトごとに乱立している MLOps のシステム・運用を共通化 し、今回紹介したデータ基盤と連携強化 ◆ Vertex AI の活用を強化し、手軽にML開発できる仕組みを整備
#Rtech ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}