ist über eine Sicherheitslücke eingebrochen worden; Ende Dezember CVE-2012-6081, Maßnahmenkatalog gegen die Lücke veröffentlicht; Ende Dezember Security Fix veröffentlicht, Bug Fix Release Anfang Januar 2013 ist die Lücke ausgenutzt worden alle Daten zu löschen; Backup / Restore ? ; Das Netz weis einiges; Restauration der Inhalte aus dem Cache der Suchmaschinen;
an MoinMoin: Thomas Waldmann, Implementierung von passlib in MoinMoin, damit SSHA password hashes abgelöst werden; Marc-Andre Lemburg organisiert den Recovery Prozess, Serversetup, usw. Cache Files werden in Wiki Markup zurückübersetzt und auf dem neuen System eingespielt, Reimar Bauer;
uns Suchmaschinen präsentieren sind als content zugänglich, z.B.: http://wiki.python.org/moin/TitelIndex; TitelIndex aus dem Cache speichern; Sichtung der Seiten, Verfahren möglichst viele in kurzer Zeit zu retten;
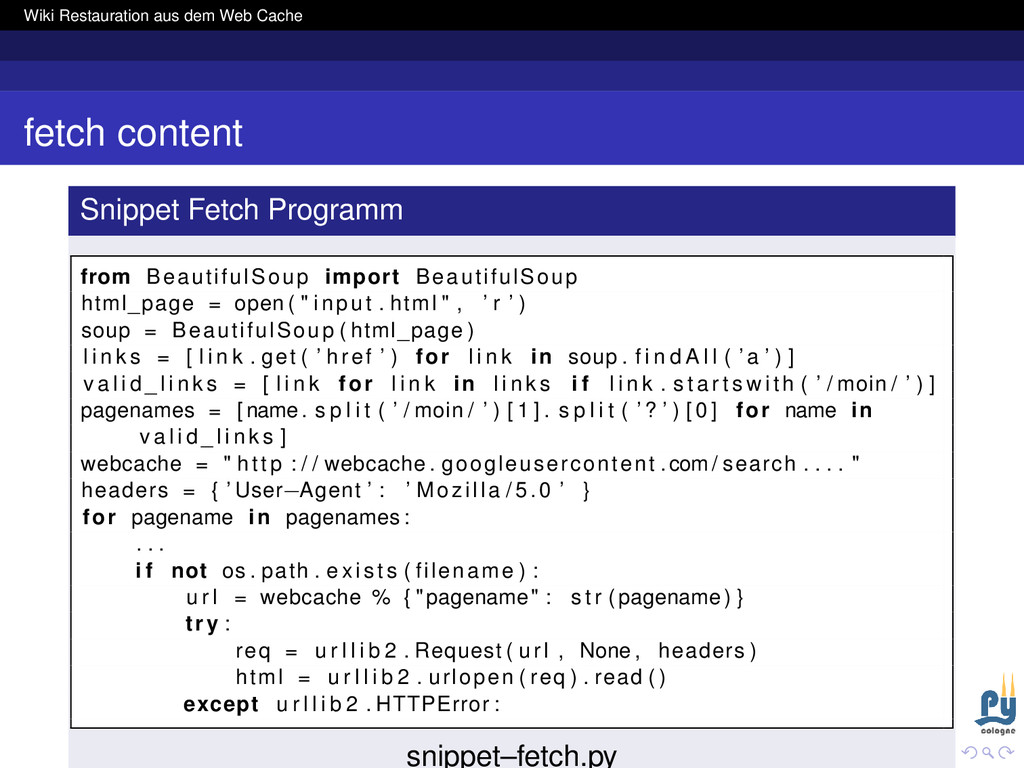
Programm from BeautifulSoup import BeautifulSoup html_page = open ( " input . html " , ’ r ’ ) soup = BeautifulSoup ( html_page ) l i n k s = [ l i n k . get ( ’ href ’ ) for l i n k in soup . f i n d A l l ( ’a ’ ) ] v a l i d _ l i n k s = [ l i n k for l i n k in l i n k s i f l i n k . s t a r t s w i t h ( ’ / moin / ’ ) ] pagenames = [name. s p l i t ( ’ / moin / ’ ) [ 1 ] . s p l i t ( ’? ’ ) [ 0 ] for name in v a l i d _ l i n k s ] webcache = " http : / / webcache . googleusercontent .com/ search . . . . " headers = { ’ User−Agent ’ : ’ Mozilla /5.0 ’ } for pagename in pagenames : . . . i f not os . path . exi sts ( filename ) : u r l = webcache % { "pagename" : s t r (pagename) } try : req = u r l l i b 2 . Request ( url , None , headers ) html = u r l l i b 2 . urlopen ( req ) . read ( ) except u r l l i b 2 . HTTPError : snippet–fetch.py
kann (x)html vom ckeditor in Wiki Markup speichern MoinMoin: text_html_text_moin_wiki.py Coconuts: Wrapper Object das den Converter nutzt Coconuts: CLI moin_html2_wiki_markup.py
MoinMoin eine Versionsverwaltung der einzelnen Seiten hat kann man Seiten nacheinander sortiert einspielen. Snippet CLI Upload pagename , date , author = i n f o ( l a s t _ e d i t _ i n f o ) pagename = pagename . s t r i p ( ) i f author . s t a r t s w i t h ( ’ [ [ ’ ) : author = author [ 2 : ] . s p l i t ( ’ | ’ ) [ 0 ] write_content ( wiki_url , pagename , rawtext , author , date , comment) snippet–cli–store.py upload_conten2wiki.py
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}