of a load balancing solution ◦ ELB routes incoming application request across multiple EC2 instances • Pull mode: async event-driven workloads do not require a load balancing solution. ◦ tasks that need to be performed or data that need to be processed could be stored as messages in a queue using Amazon Simple Queue Service (Amazon SQS) or as a streaming data solution like Amazon Kinesis. Stateless Applications 9
a resource fails, functionality is recovered on a 2nd resource using a process call failover • Detect Failure ◦ Route53 Health Check ◦ EC2 auto recovery ◦ Auto Scaling Removing Single Points of Failure (SPOF) 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
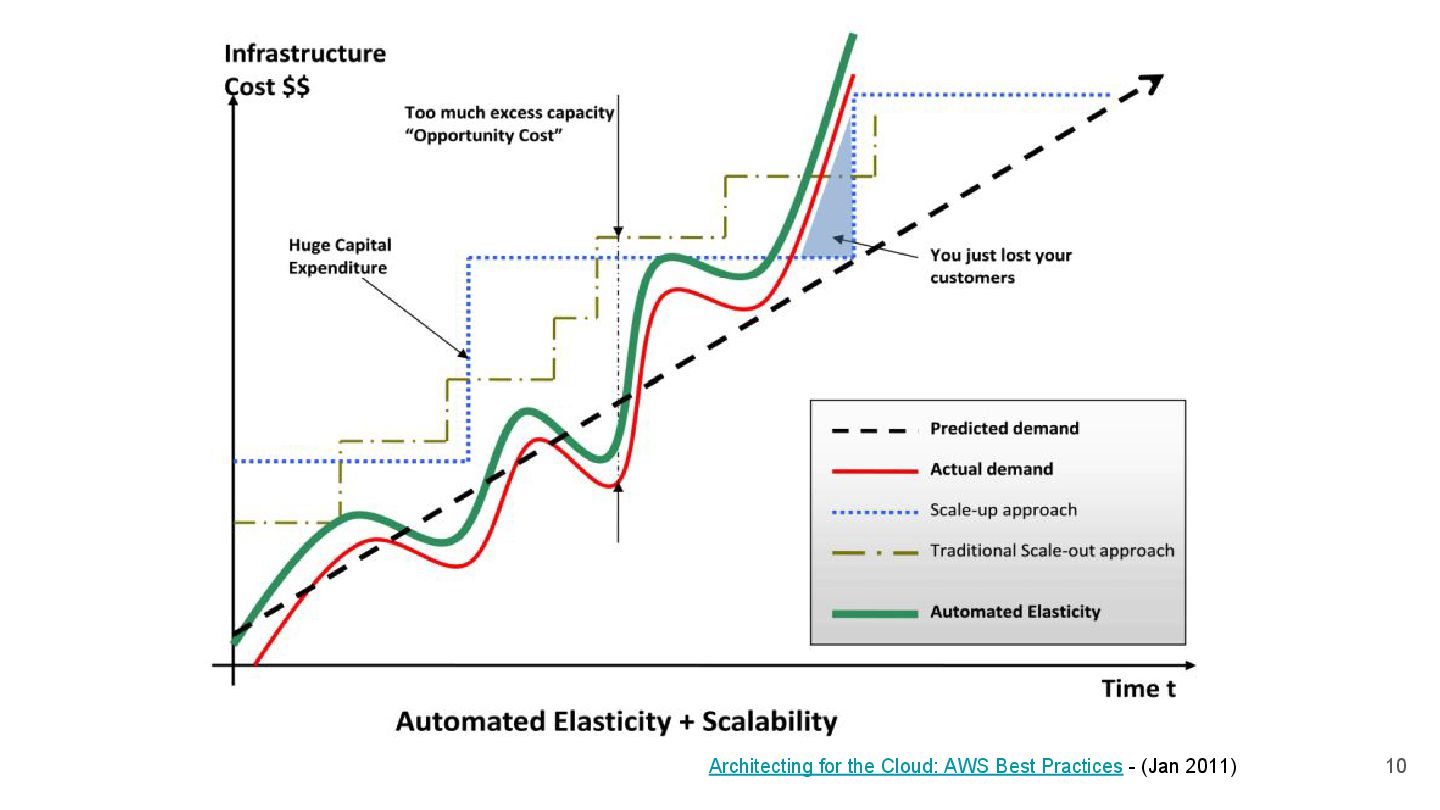{kind=link}
{kind=link}
{kind=link}
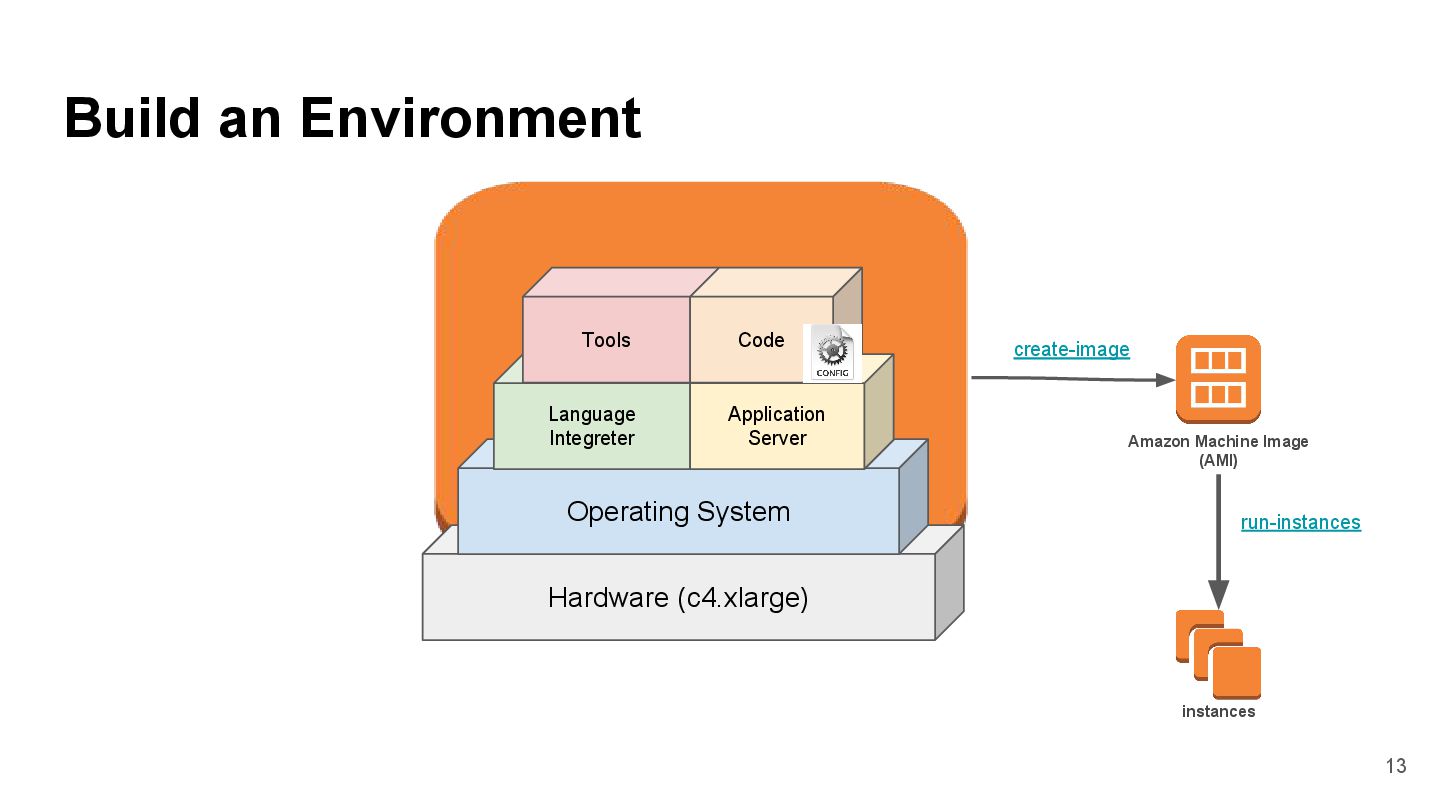{kind=link}
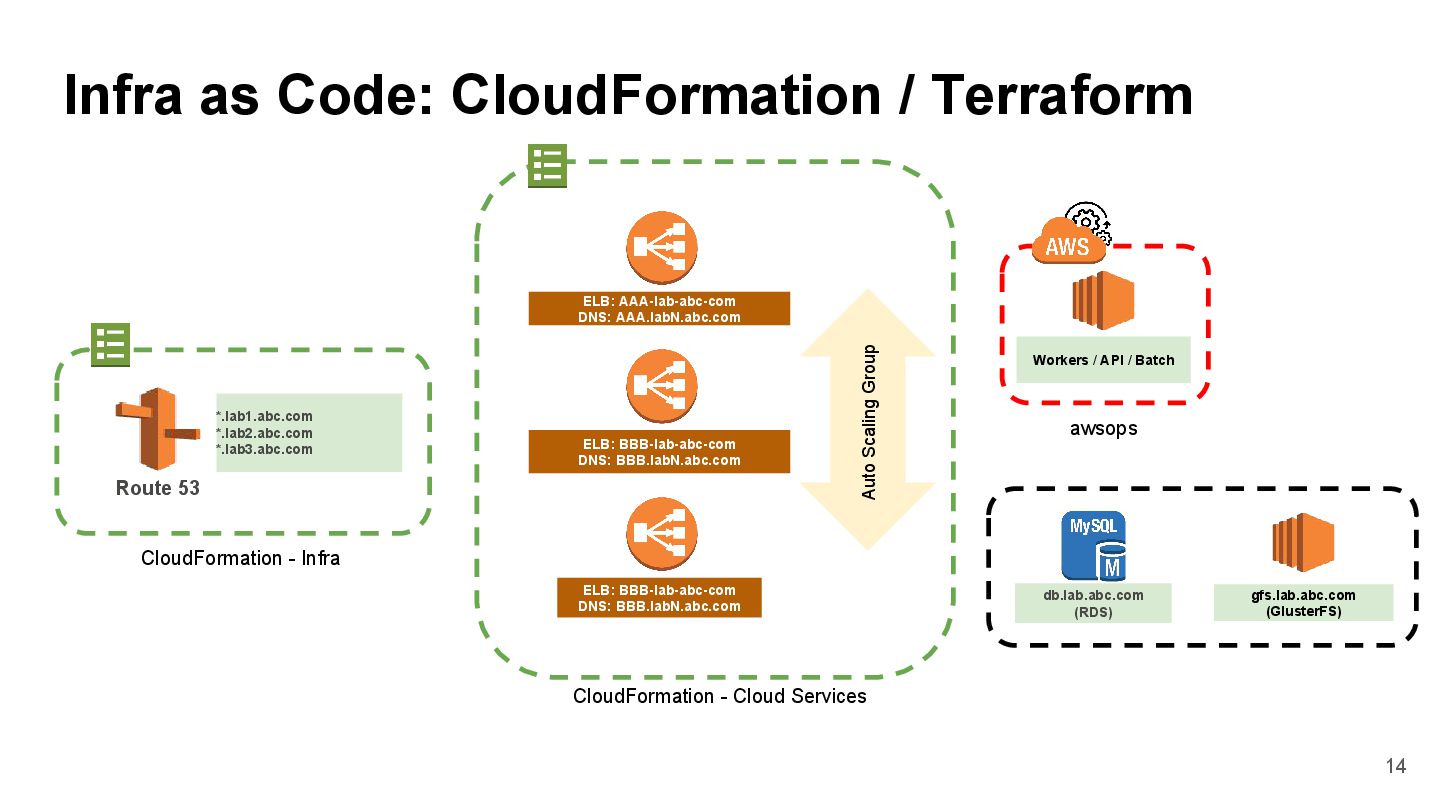{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
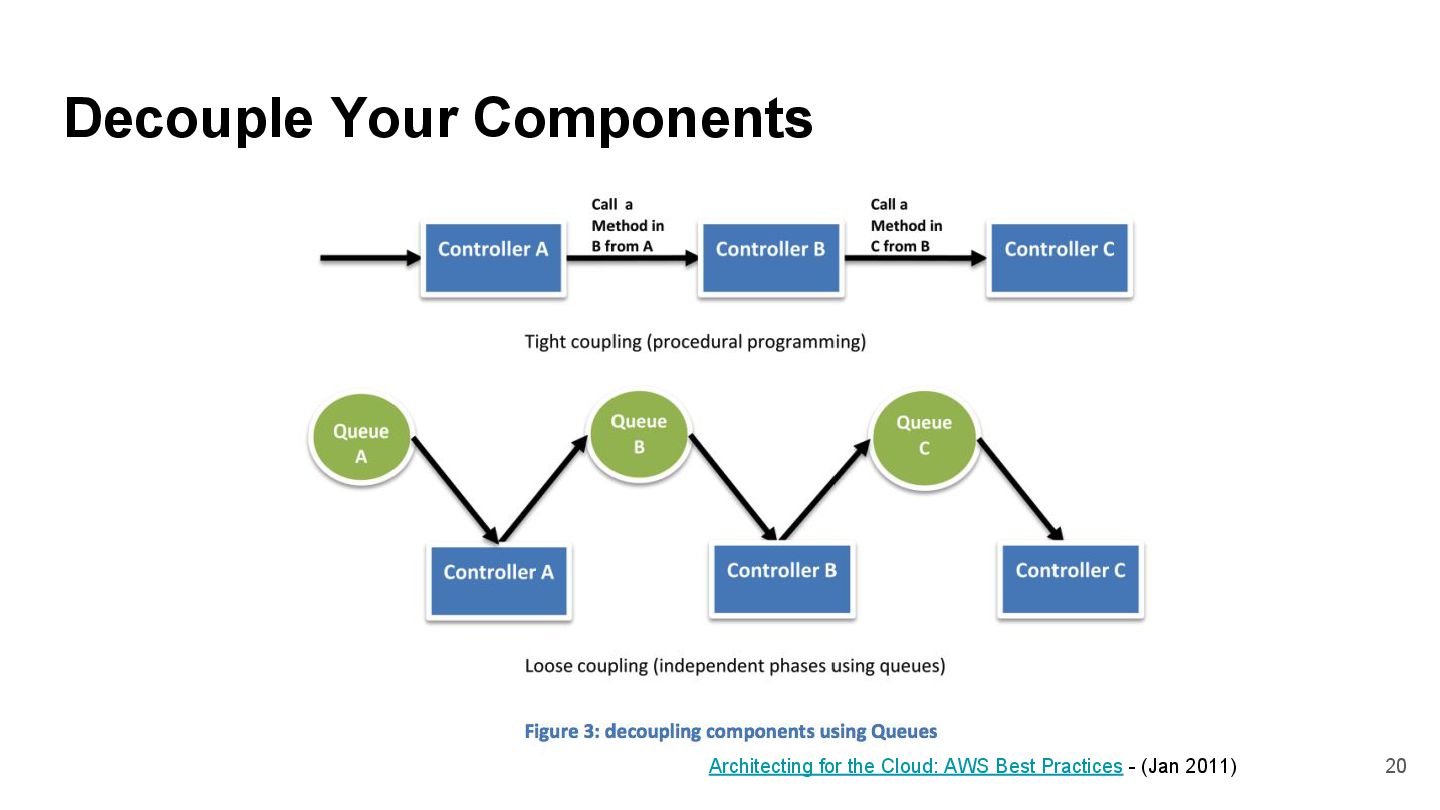{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}