Signate Student Cup 2020 (https://signate.jp/competitions/281/) の17位解法をチズチズさん(@chizu_potato)主催のLT会にて発表した資料になります.
ソースコードは後日GitHubで公開する予定です(公開したらURL追加します).
関係各位の皆さん, ありがとうございました!
僕のtwitter -> @rinchi_math
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![コンペの取り組み 基本⽅針: • KaggleのNLP系過去コンペの上位解法を調べる. • BERT系⾊々試す. • ⽂章全体と局所的な単語の特徴量が効きそうだったので単純に[CLS] tokenを⽤いる以 外の⽅法も考える.](https://files.speakerdeck.com/presentations/2e66da1eb8fa4f70af7354194881572f/slide_4.jpg){kind=link}
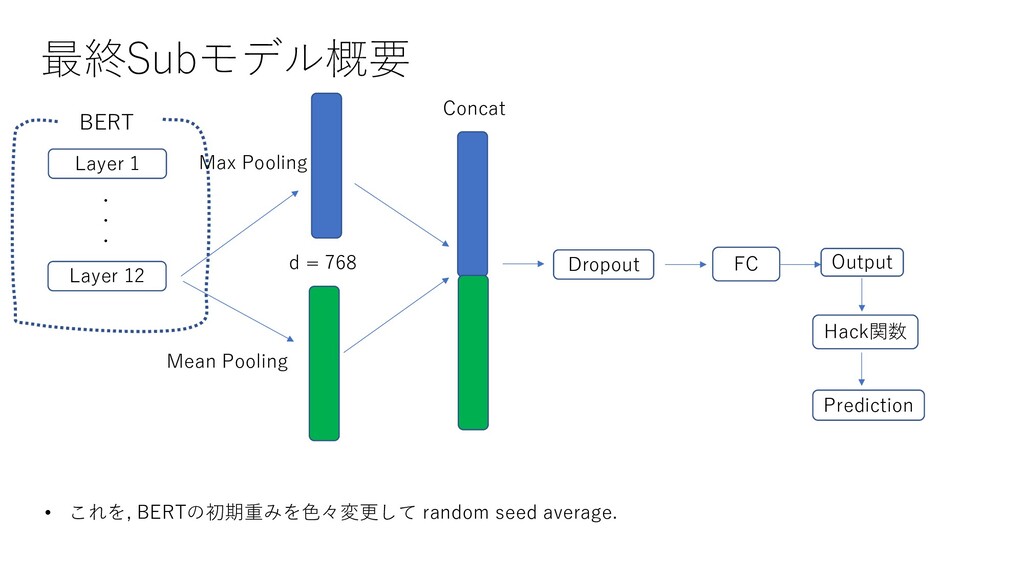{kind=link}
{kind=link}
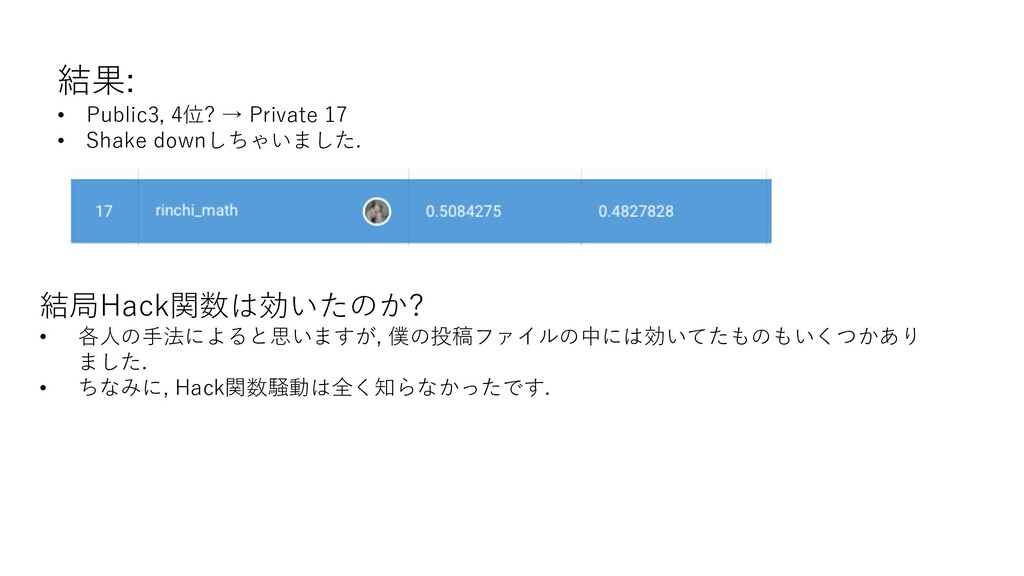{kind=link}
{kind=link}
{kind=link}