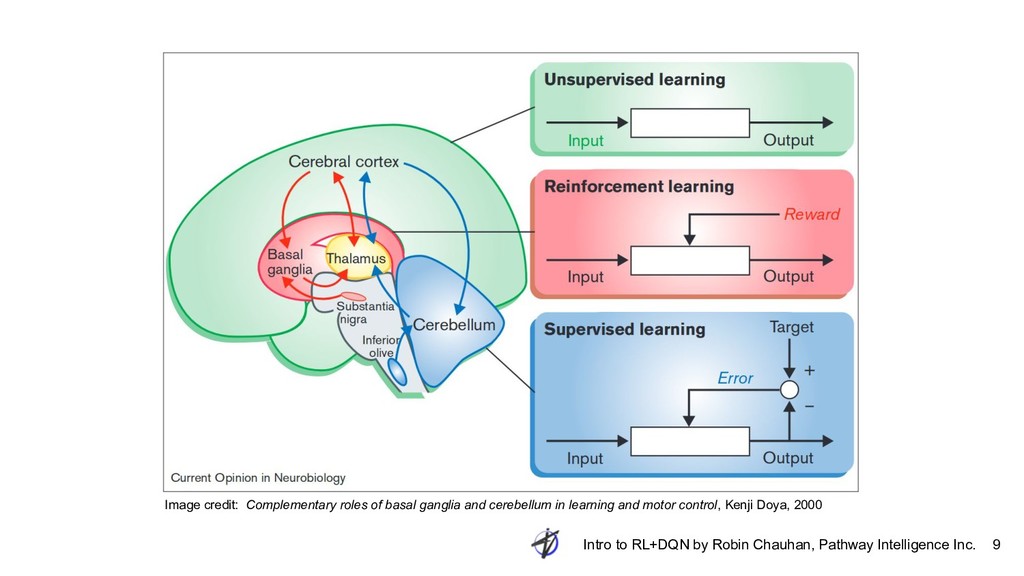
We will introduce Reinforcement Learning concepts, methods, and applications. We will look at tools and frameworks for posing and RL problems, including OpenAI gym. We introduce Q learning and set the stage for DQN.
Robin aims to share the best insights from the top researchers in a lucid and entertaining way. We assume only basic knowledge of machine learning and math.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Robin Ranjit Singh Chauhan [email protected] https://github.com/pathway https://ca.linkedin.com/in/robinc https://pathway.com/aiml](https://files.speakerdeck.com/presentations/7388920c54604bfa9a9dd6629514965f/slide_73.jpg){kind=link}