Intelligence Inc • Dota 1: 2003 ◦ Multiplayer online battle arena (MOBA) mod for the video game Warcraft III: Reign of Chaos (real-time strategy from Blizzard) ◦ Valve of Kirkland WA (96) bought IP in 2009 • Dota 2: 2013 ◦ Played by over 10M people monthly ◦ Highest betting of any esport in tens of M$ USD • Goal ◦ collectively destroy a large structure defended by the opposing team known as the "Ancient", whilst defending their own Defense of the Ancients 2
Intelligence Inc Valve’s Dota Bot API Simplifying restrictions • Lua/C++ scripting of server ◦ Directly access game engine info ◦ Not pixel/memory level like ▪ ALE Atari ▪ Deepmind Lab ▪ Karpathy’s Pong from pixels, etc • Besides detailed “action level API” ◦ also has higher level “teams” and “modes” APIs ◦ See https://developer.valvesoftware.com/wiki/D ota_Bot_Scripting • Mirror match of specific heroes (18 of 100+) • No … ◦ warding (vision+spying) ◦ Roshan (most powerful neutral creep) ◦ invisibility of units/heroes (consumables and relevant items) ◦ summons (units via spells) /illusions (copies of heroes) ◦ Divine Rapier, Bottle, Quelling Blade, Boots of Travel, Tome of Knowledge, Infused Raindrop (powerful items) ◦ No Scan (minimap enemy hero detection) ◦ 5 invulnerable couriers, no exploiting them by scouting or tanking • Some restrictions lifted last week, expect more to be lifted over time...
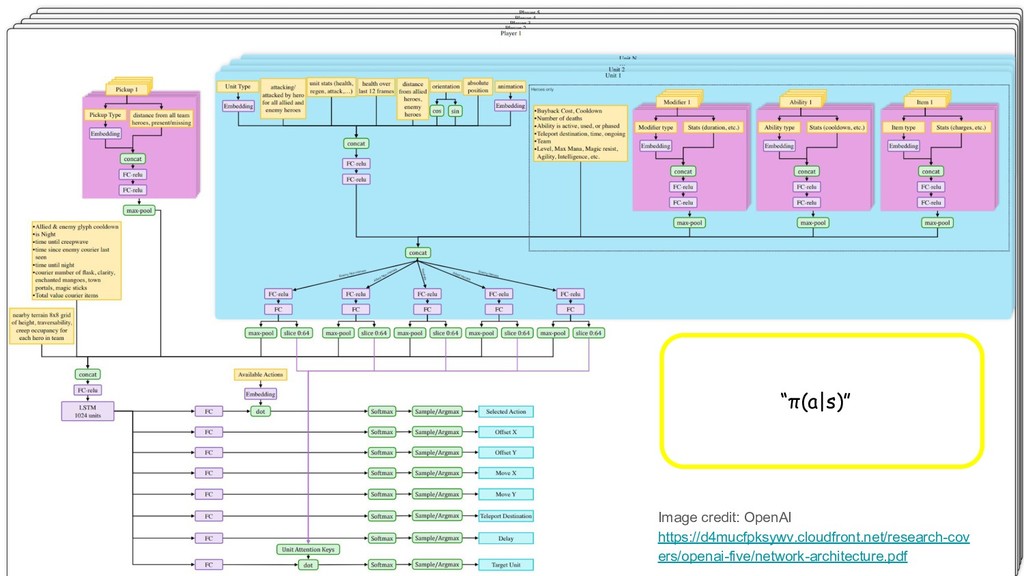
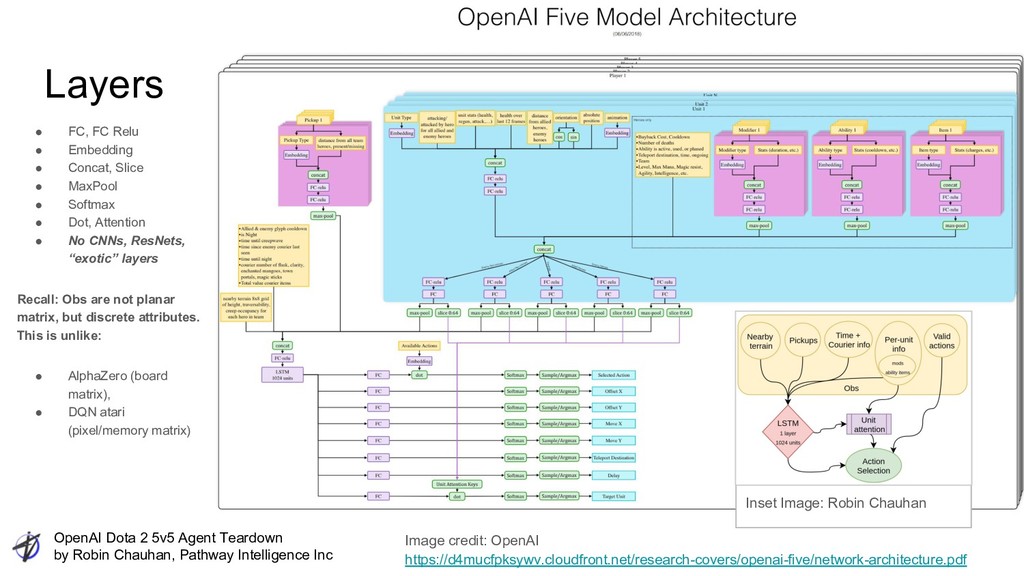
Intelligence Inc Agent Net Image credit: Robin Chauhan Based on OpenAI Five Architecture https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf π(a|s) Image credit: OpenAI https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf
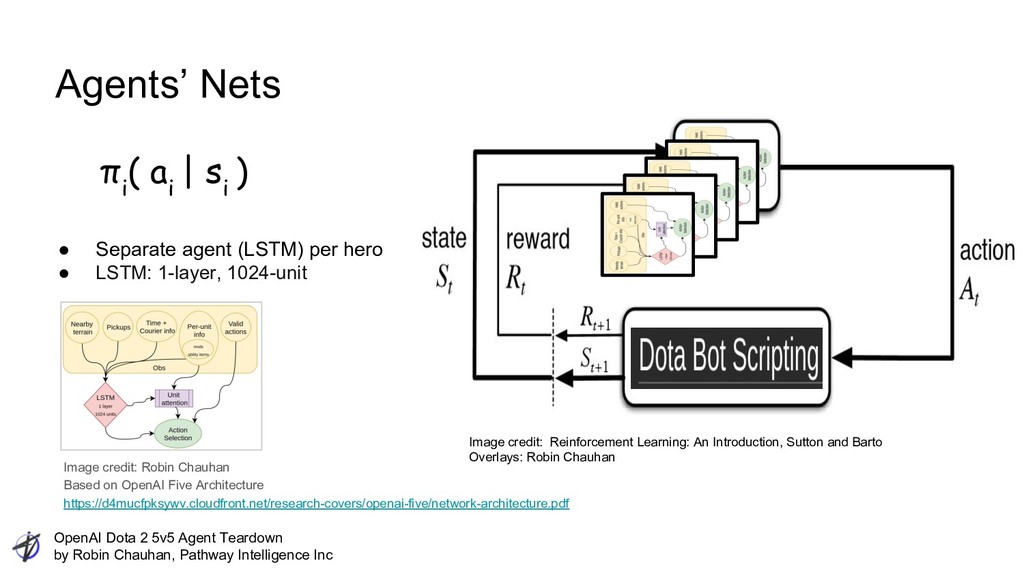
Intelligence Inc Agents’ Nets Image credit: Robin Chauhan Based on OpenAI Five Architecture https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf • Separate agent (LSTM) per hero • LSTM: 1-layer, 1024-unit Image credit: Reinforcement Learning: An Introduction, Sutton and Barto Overlays: Robin Chauhan π i ( a i | s i )
Intelligence Inc Reward Shaping • Hero score ◦ +: Experience, gold, mana, hero health, last hit, deny ◦ -: kill enemy hero (?), dying • Zero Sum ◦ team's mean reward is subtracted from the rewards of the enemy team ▪ hero_rewards[i] -= mean(enemy_rewards) • Building: all heros on team ◦ Weighted by type and health • Time scaling of rewards ◦ scale up all rewards early in the game and scale down rewards late in the game Source: OpenAI See https://gist.github.com/dfarhi/66ec9d760ae0c49a5c492c9fae93984a Image credit: Wikipedia Such reward
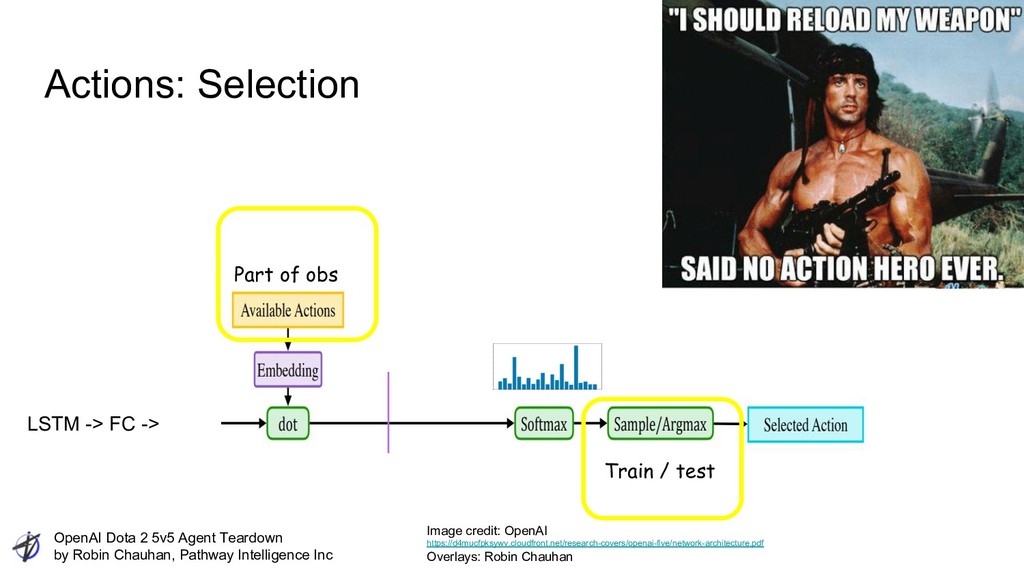
Intelligence Inc Actions: Selection LSTM -> FC -> Train / test Part of obs Image credit: OpenAI https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf Overlays: Robin Chauhan
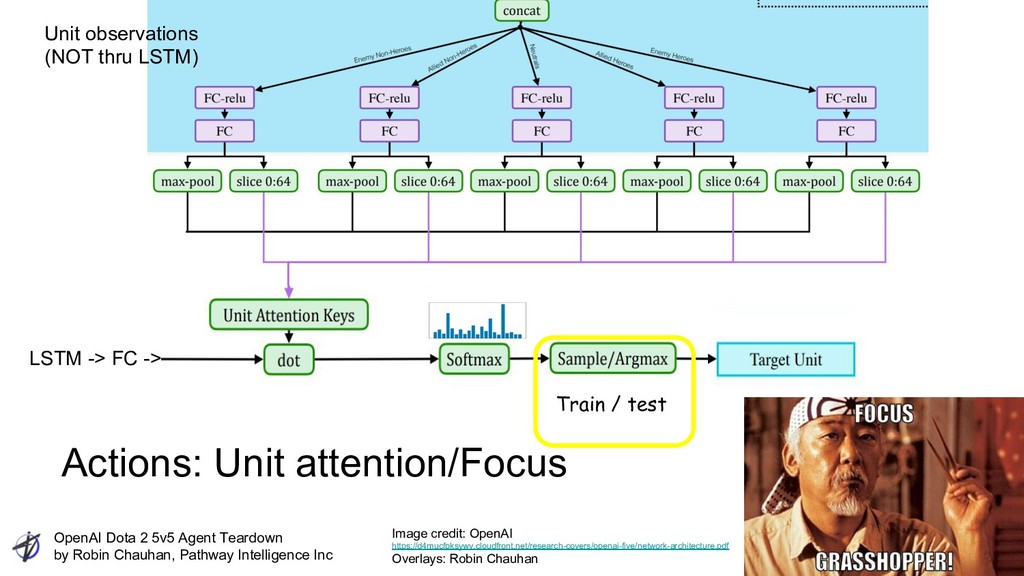
Intelligence Inc LSTM -> FC -> Unit observations (NOT thru LSTM) Actions: Unit attention/Focus Train / test Image credit: OpenAI https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf Overlays: Robin Chauhan
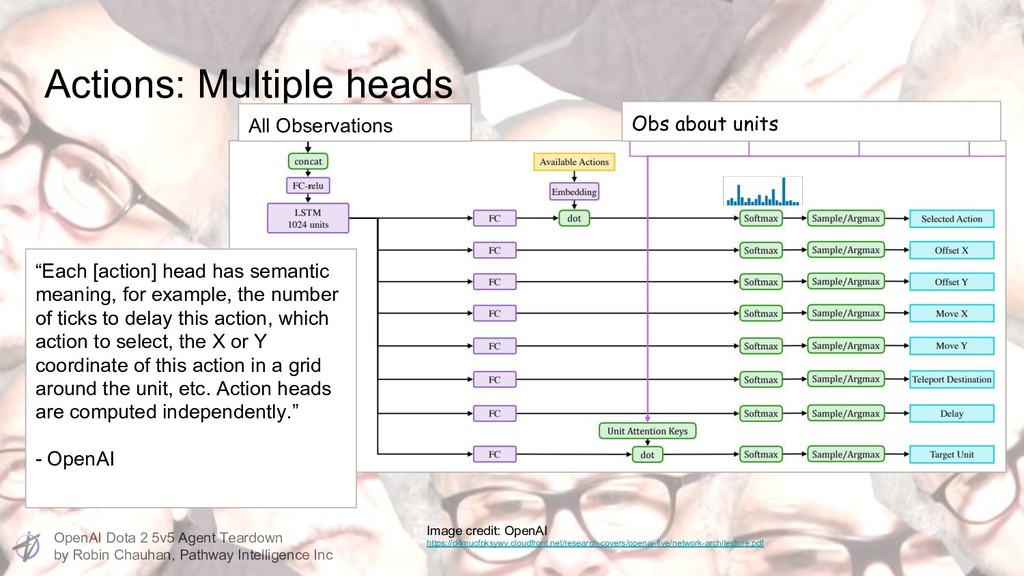
Intelligence Inc Actions: Multiple heads All Observations Obs about units “Each [action] head has semantic meaning, for example, the number of ticks to delay this action, which action to select, the X or Y coordinate of this action in a grid around the unit, etc. Action heads are computed independently.” - OpenAI Image credit: OpenAI https://d4mucfpksywv.cloudfront.net/research-covers/openai-five/network-architecture.pdf
Intelligence Inc MARL: τ ≡ tau ≡ Team Spirit • “how much each of OpenAI Five’s heroes should care about its individual reward … versus the average of the team’s reward” ◦ Start focussed on self reward ◦ end focussed on team reward • τ ◦ hero_rewards[i] = τ * mean(hero_rewards) + (1 - τ) * hero_rewards[i] ◦ anneal τ from 0.2 to 0.97 • No comms, no central controller, no cutting edge MARL training ◦ Independent LSTM, but any other shared weights? ◦ Simple τ scheme -> team coordination
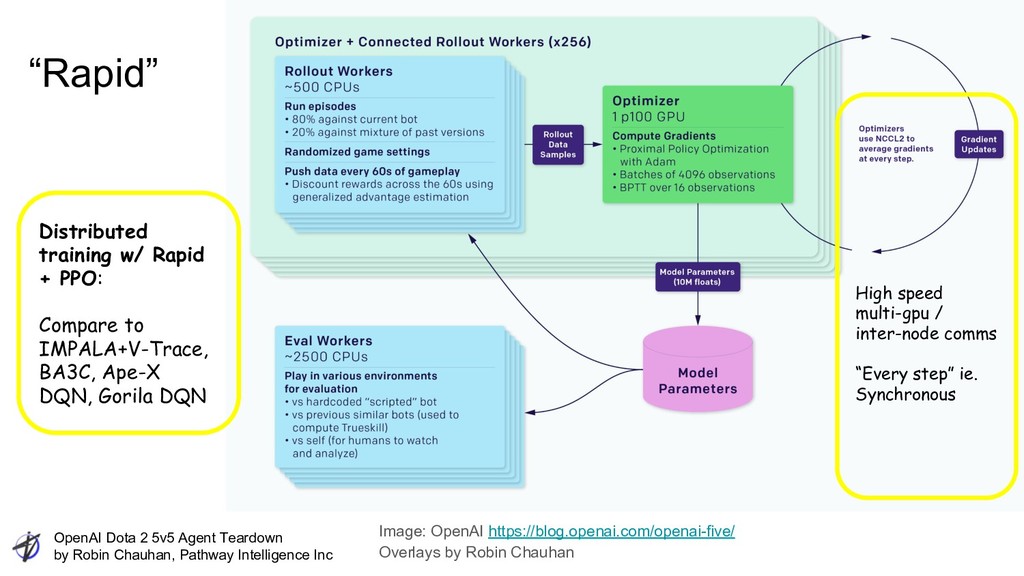
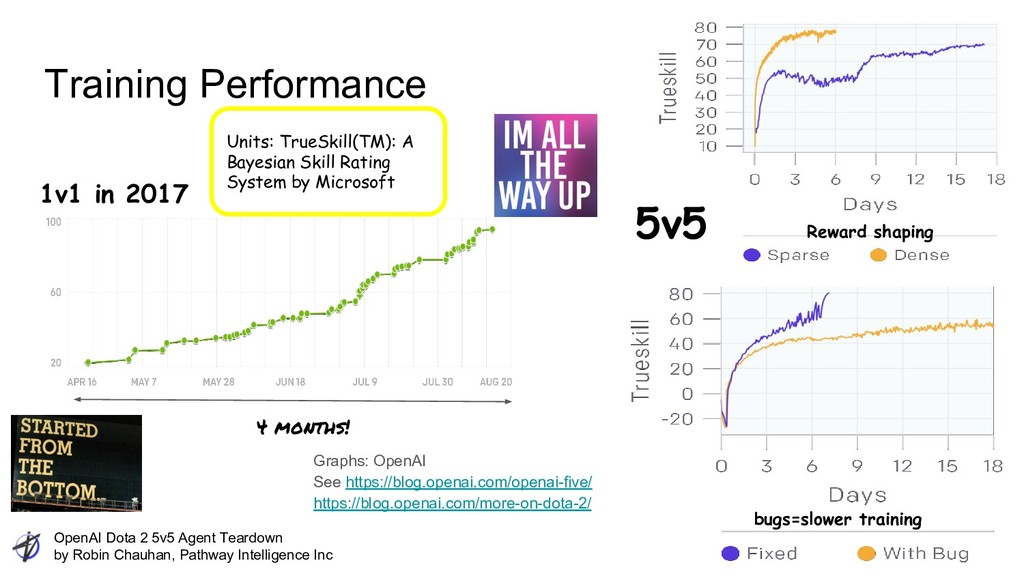
Intelligence Inc Training Performance Graphs: OpenAI See https://blog.openai.com/openai-five/ https://blog.openai.com/more-on-dota-2/ 1v1 in 2017 5v5 Reward shaping bugs=slower training Units: TrueSkill(TM): A Bayesian Skill Rating System by Microsoft 4 months!
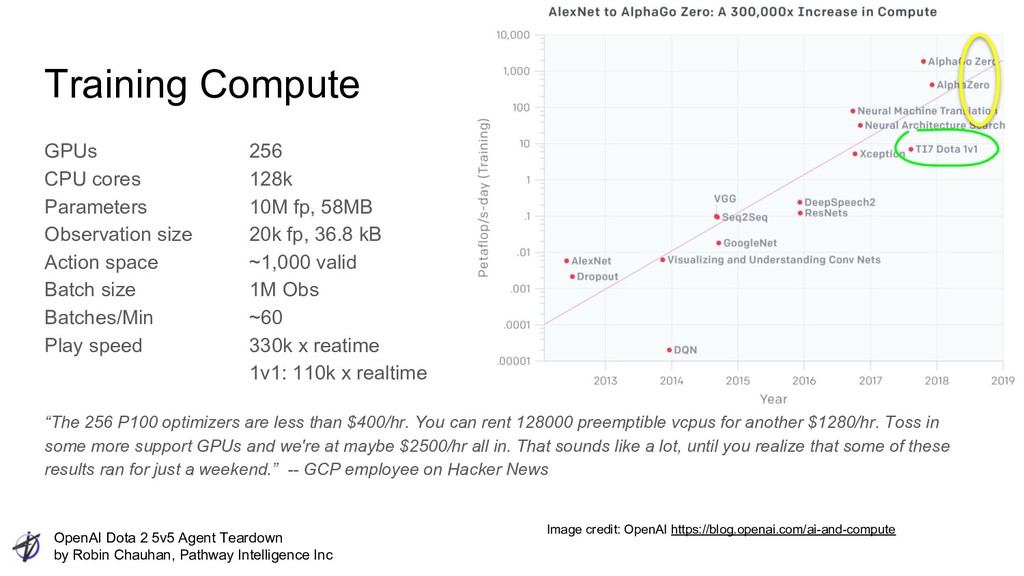
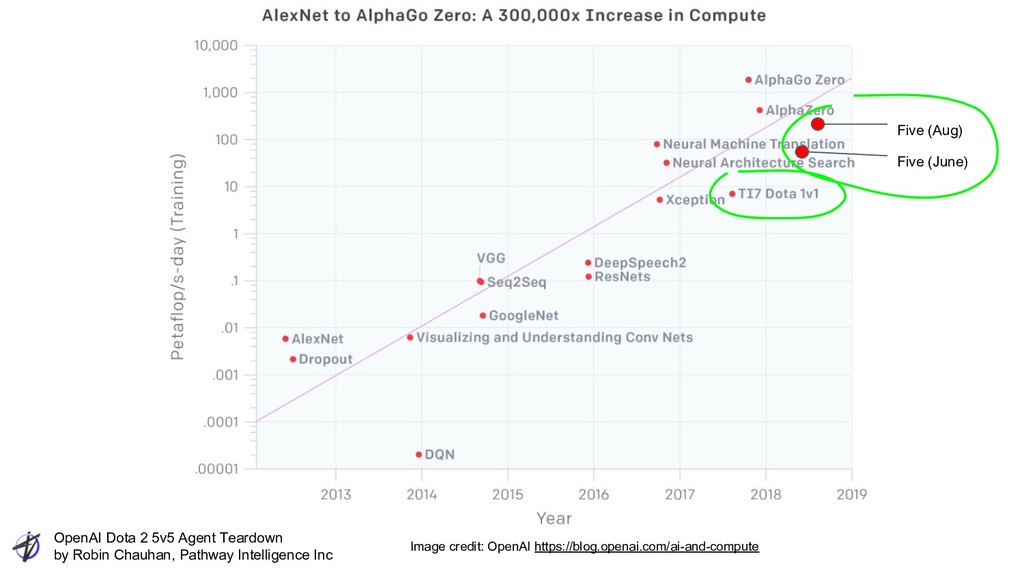
Intelligence Inc Training Compute GPUs 256 CPU cores 128k Parameters 10M fp, 58MB Observation size 20k fp, 36.8 kB Action space ~1,000 valid Batch size 1M Obs Batches/Min ~60 Play speed 330k x reatime 1v1: 110k x realtime “The 256 P100 optimizers are less than $400/hr. You can rent 128000 preemptible vcpus for another $1280/hr. Toss in some more support GPUs and we're at maybe $2500/hr all in. That sounds like a lot, until you realize that some of these results ran for just a weekend.” -- GCP employee on Hacker News Image credit: OpenAI https://blog.openai.com/ai-and-compute
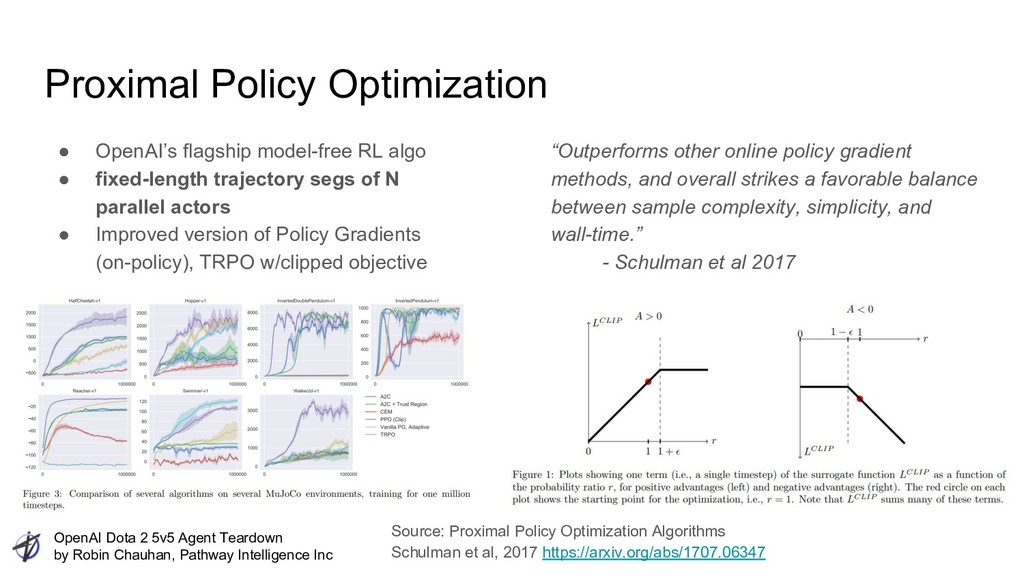
Intelligence Inc • Reinforcement Learning ◦ PPO => general purpose, previously existing, Model-free, on-policy, policy gradient Deep Reinforcement Learning ▪ RL innovation in scaling with Rapid ▪ Teamwork with Tau • Deep learning ◦ Specific network design tuned for inductive bias on this environment ▪ Net design itself embodies “human knowledge” ** AlphaZero same same ◦ “Single-layer LSTM” agent core = pure elegance ▪ “Basic” RNN performance surprise? My take: Innovation, Intelligence
Intelligence Inc • OpenAI Five Formula ◦ Hand-designed Deep Learning inductive bias ** Agent net ◦ + Teamwork annealing ** cool ◦ + Basic RNN ** LSTM ◦ + General RL ** PPO ◦ + (Well engineered) Brute Force ** Rapid => Results ▪ Similar formula as Deepmind AlphaZero ** ResNet + innovative but very simple model-based RL • RL Implications ◦ Discouraging for Proponents of HRL, MARL-tailored algos, richer RL ▪ Sample efficiency? My take: their AI Formula
Intelligence Inc My take: Impact • Brag rights to OpenAI for major achievement ◦ Compare Deepmind’s AlphaGo Zero/AlphaZero ▪ Dota has vastly larger action and obs spaces • Largest scale Multi-agent mixed collaborative/competitive result so far ◦ Compare to AlphaGo Zero/AlphaZero purely competitive self-play ◦ Provides a potential approach for design ◦ Influence StarCraft Agent design for DeepMind’s SC2LE? • Create vs Destroy ◦ Dota as betting platform? Game AI jobs? • AGI ◦ Not intended to directly address AGI ◦ Useful datapoint on potential of general DRL for simulatable domain-specific intelligence
Intelligence Inc Thank you! Robin Ranjit Singh Chauhan: The rest [email protected] https://github.com/pathway https://ca.linkedin.com/in/robinc https://pathway.com/aiml Kiran Chauhan: Memes and Dota info [email protected] Aug 5: Benchmark match • Playing vs 99.95th-percentile Dota players 12:30pm Pacific Time on August 5th in SF • Streaming at https://www.twitch.tv/openai Aug 20–25: Dota 2 International • Rogers Arena in Vancouver, Canada
![Robin Ranjit Singh Chauhan Pathway Intelligence Inc [email protected] https://pathwayi.com OpenAI](https://files.speakerdeck.com/presentations/8d3493e8eb8f47a5839a751c0b9751fb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}