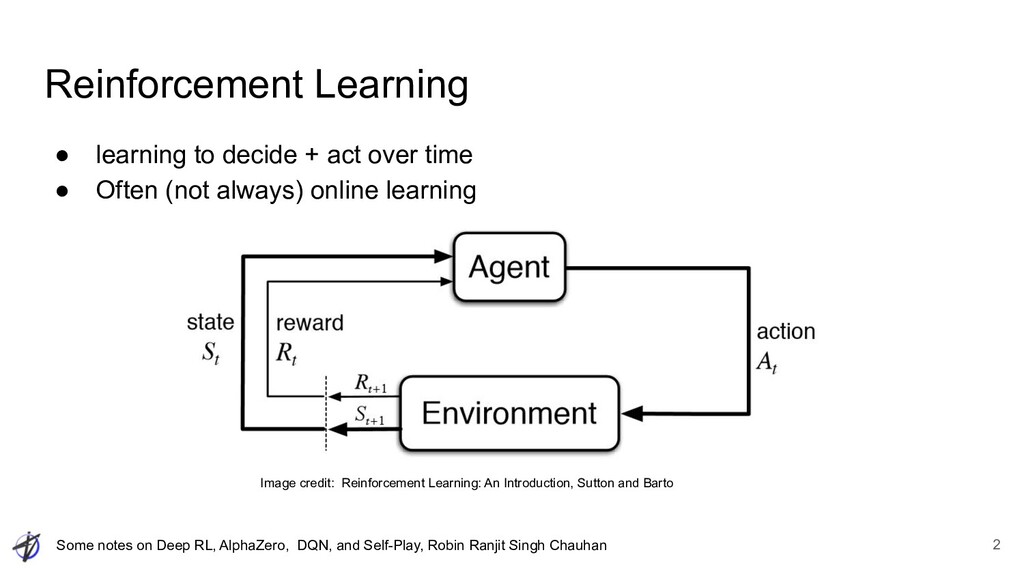
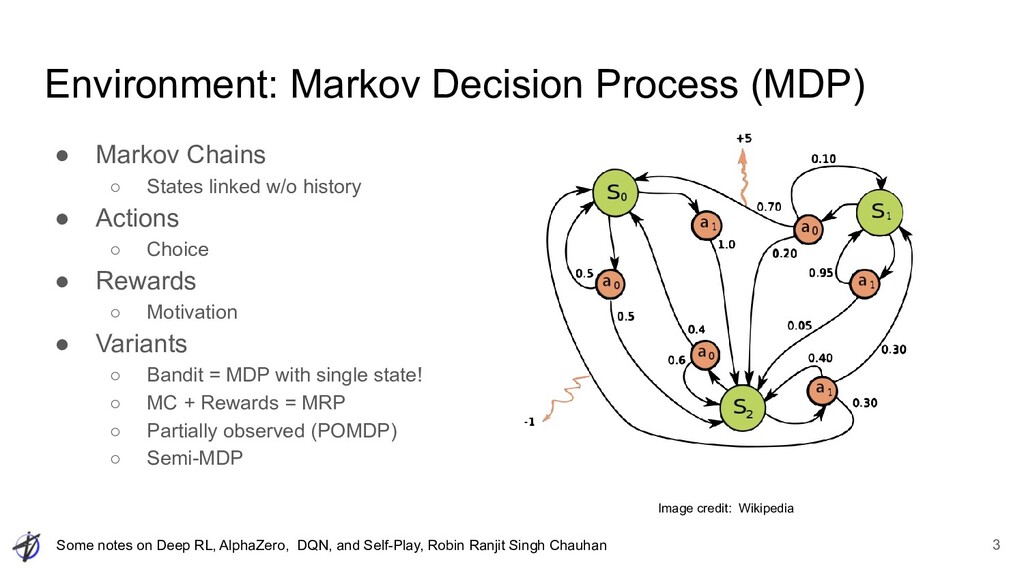
Ranjit Singh Chauhan Reinforcement Learning • learning to decide + act over time • Often (not always) online learning 2 Image credit: Reinforcement Learning: An Introduction, Sutton and Barto
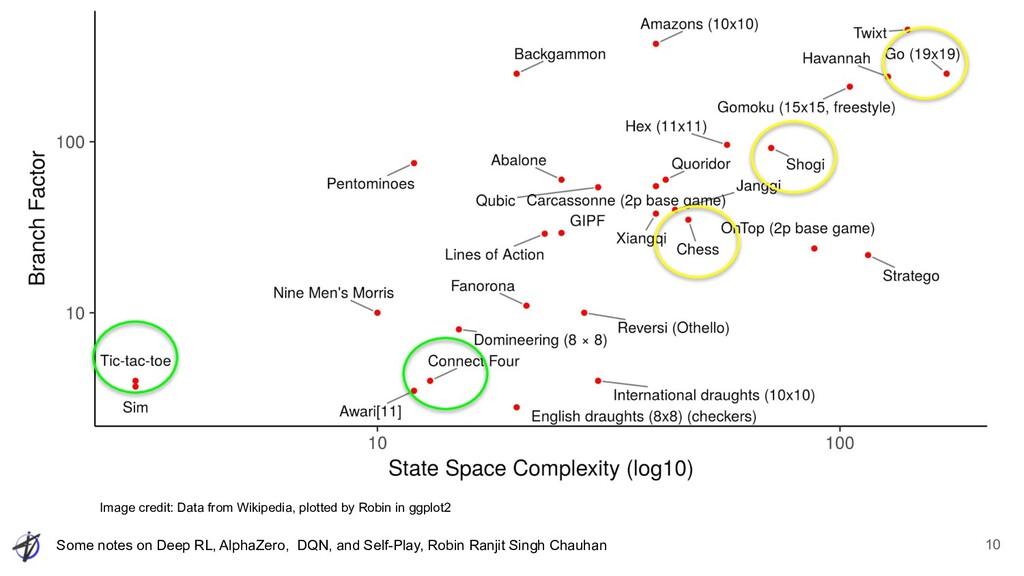
Ranjit Singh Chauhan Self-Play: Domains • Board games, DOTA, StarCraft, ... What do these self-play domains mostly have in common? • Easy to simulate ◦ Notice none are messy real world domains • Many strong opponents ◦ Software ◦ Sometimes human • Exploration is tractable Not always applicable, but cool when it is 5
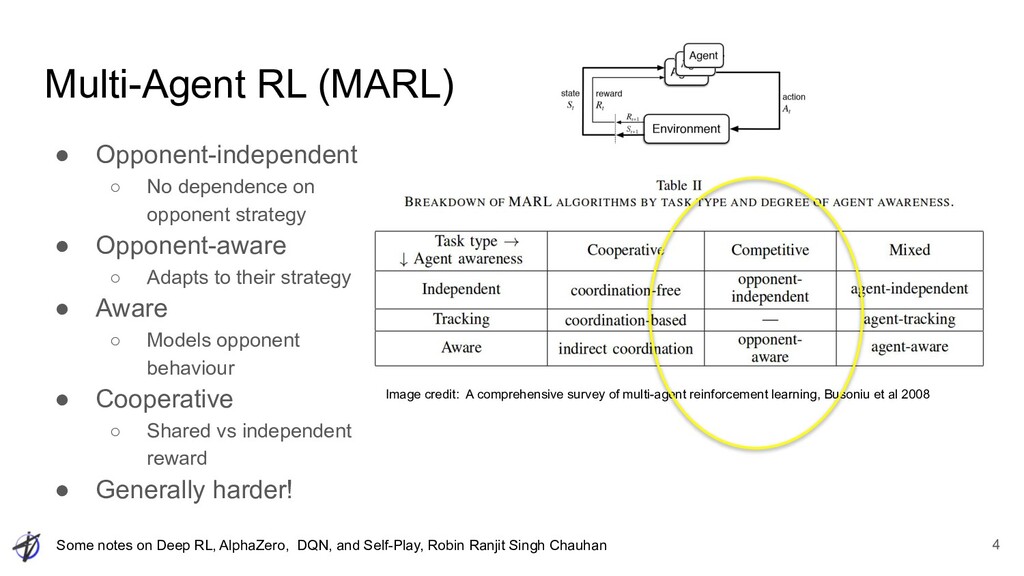
• Single agent + environment = “playing by itself”, right? ◦ No: Self Play specifically means playing (competitively against?) ▪ Another agent (Dota) ▪ Recent replica (AlphaGo) ▪ Self in the mirror (AlphaZero) • Self Play has specific and interesting properties, benefits, challenges Self-Play RL 6
Ranjit Singh Chauhan Game of Go • Ancient Chinese game ◦ 围棋 wéiqí (pronounced way-chee), which means the "surrounding game" • Invented over 3-4k years ago ◦ Myth: legendary Emperor Yao invented Go to enlighten his son, Dan Zhu ◦ by 500 BC it had already become one of the "Four Accomplishments" that must be mastered by Chinese gentlemen ◦ Professional system established 1978 Paraphrased from: British Go Association, GoBase.org, Wikipedia
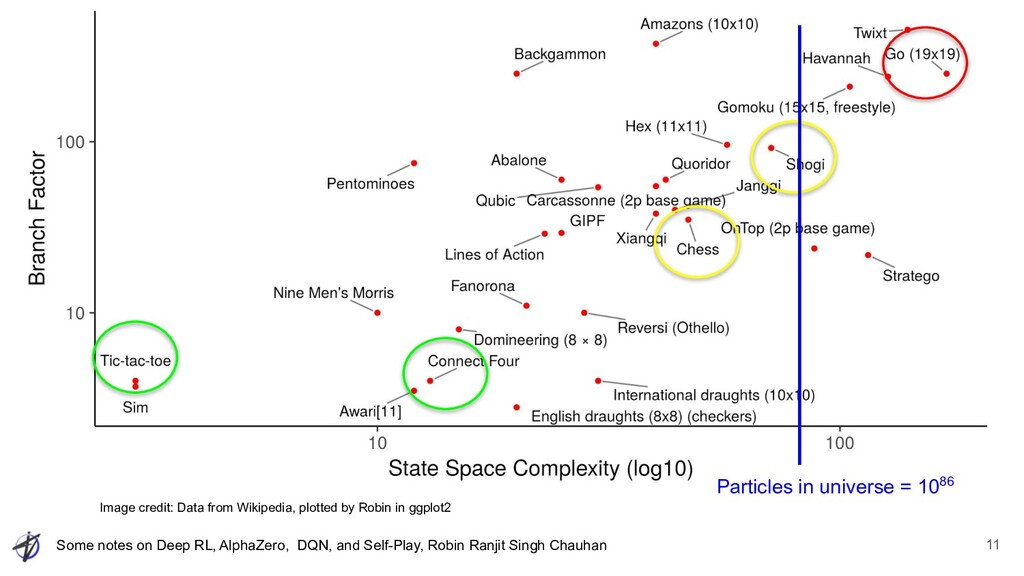
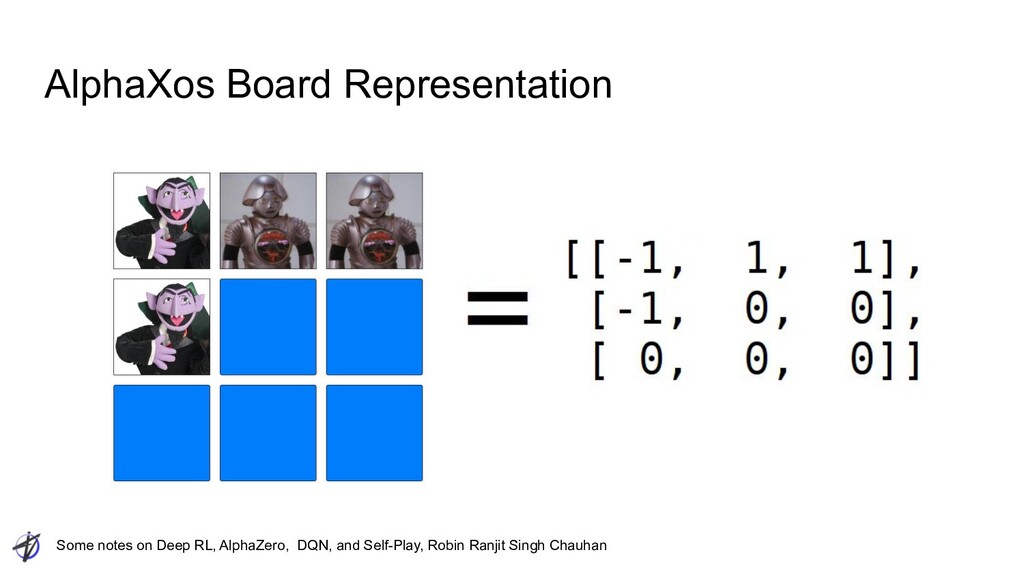
Ranjit Singh Chauhan Game of Go • Associated with divination ◦ Divination associated with agriculture ◦ Yellow River Diagram and the Luo Record were “magic squares” ▪ depicted in the same way as go diagrams ▪ numbers are not shown with numerals but with clusters of black and white "go" stones • Properties of Go ◦ Perfect Information ◦ Zero-sum ◦ Deterministic ◦ Very large action, state spaces Image credit: Wikipedia
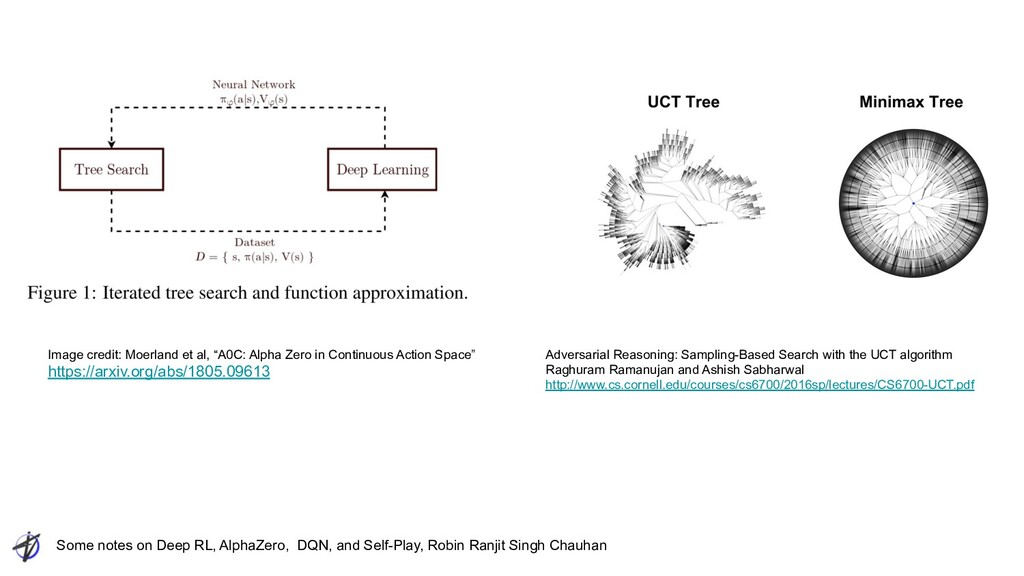
Ranjit Singh Chauhan Image credit: Moerland et al, “A0C: Alpha Zero in Continuous Action Space” https://arxiv.org/abs/1805.09613 Adversarial Reasoning: Sampling-Based Search with the UCT algorithm Raghuram Ramanujan and Ashish Sabharwal http://www.cs.cornell.edu/courses/cs6700/2016sp/lectures/CS6700-UCT.pdf
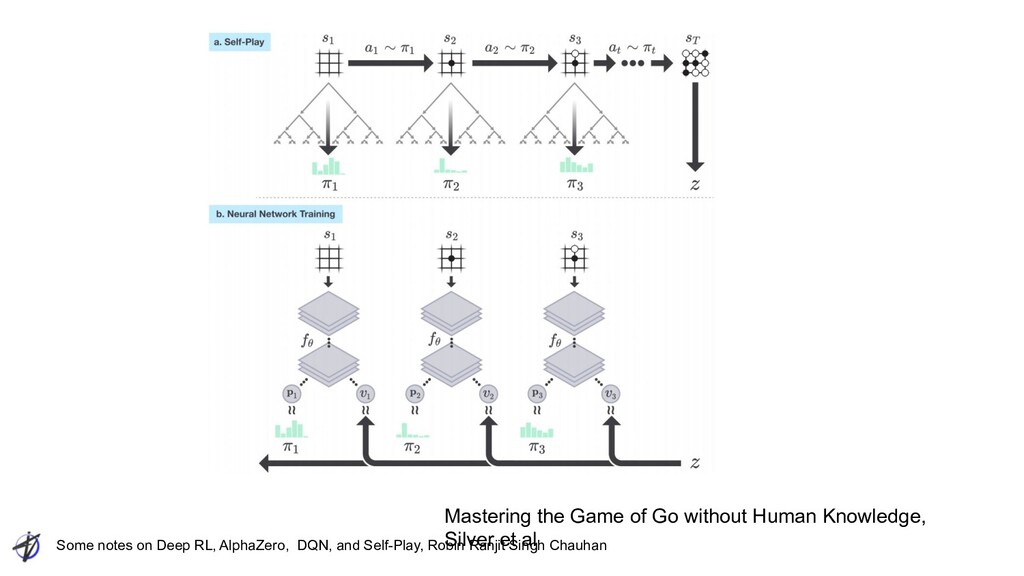
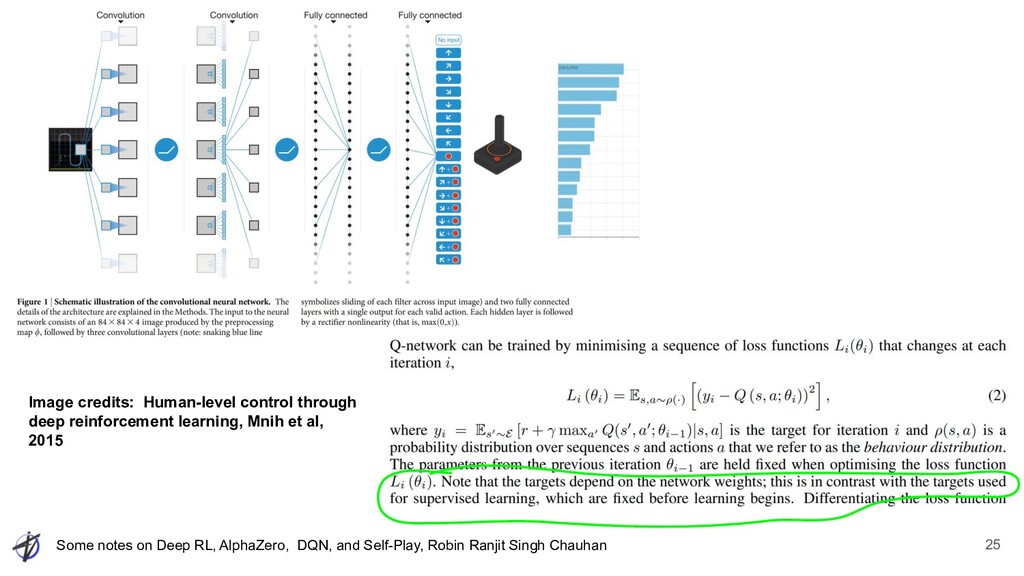
Ranjit Singh Chauhan AlphaZero Loss ◦ z: actual winner ◦ p: observed move prob using MCTS ◦ v: network value head output: Scalar ◦ π: network policy head output: Vector over actions ◦ c: L2 regularization constant Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm, Silver et al Mean Squared Error Cross Entropy Regularize
Ranjit Singh Chauhan From Surag Nair https://web.stanford.edu/~surag/posts/alphazero.html Learning to Play Othello Without Human Knowledge, Thakoor et al
Ranjit Singh Chauhan From Surag Nair https://web.stanford.edu/~surag/posts/alphazero.html Learning to Play Othello Without Human Knowledge, Thakoor et al
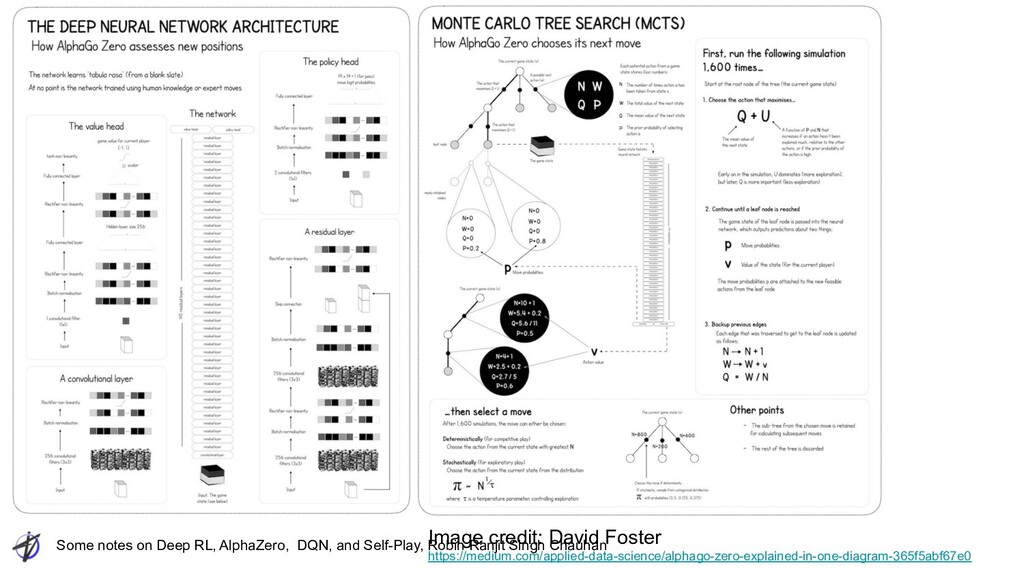
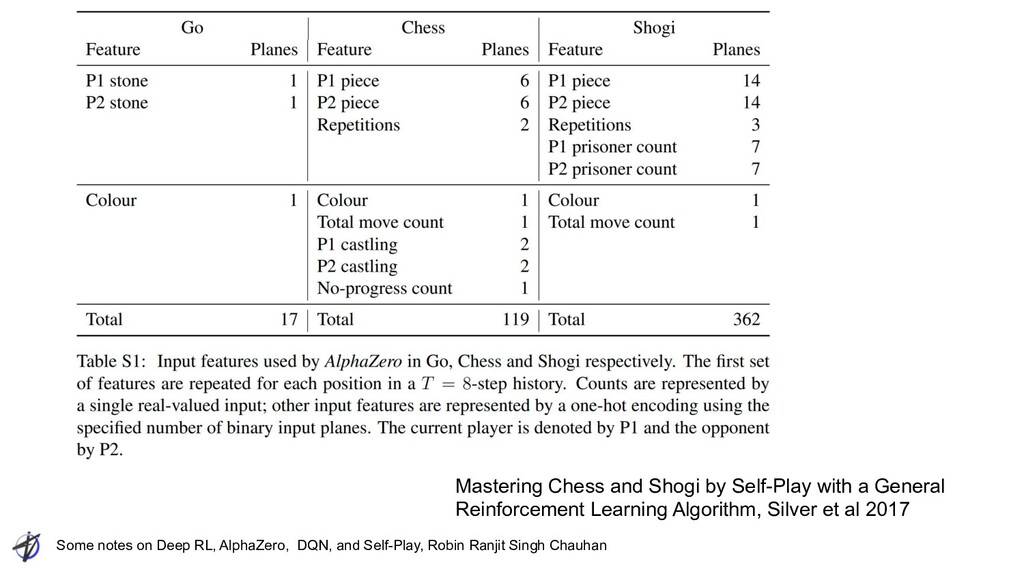
Ranjit Singh Chauhan AlphaZero: Chess Output • Chess Move: 1) Select piece, 2) Select destination • 73 x 8x8 planes ◦ probability distribution over 4,672 possible moves ◦ First 56: “Queen” type moves for any piece ◦ “a number of squares [1..7] in which the piece will be moved, along one of eight relative compass directions {N, NE, E, SE, S, SW, W, NW}” ◦ next 8 planes encode possible knight moves for that piece ◦ Final 9: underpromotions for pawn moves or captures in two possible diagonals, to knight, bishop or rook
Extra Exploration: Dirichlet(α) • Adds to 1; Softmax-ish • Symmetric Dirichlet distribution ◦ Alpha has same value for all elements ◦ Symmetric useful when “there is no prior knowledge favoring one component over another” • α = {0.3, 0.15, 0.03} for chess, shogi and Go respectively ◦ α=1: Uniform ◦ α>1: “Similar” values ◦ 0 < α <1 ▪ sparse distributions; most near zero, most of mass near a few values • Root node only
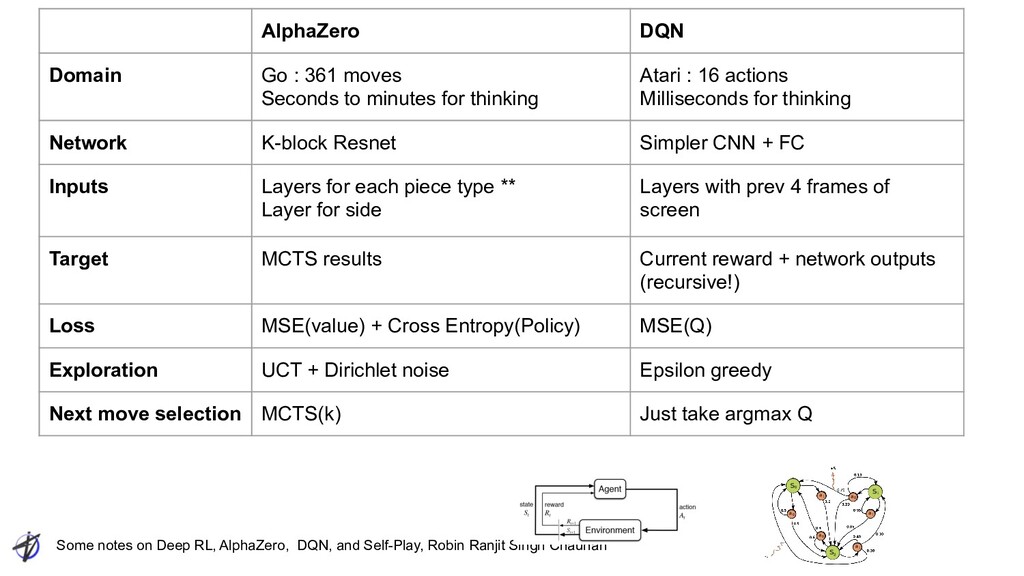
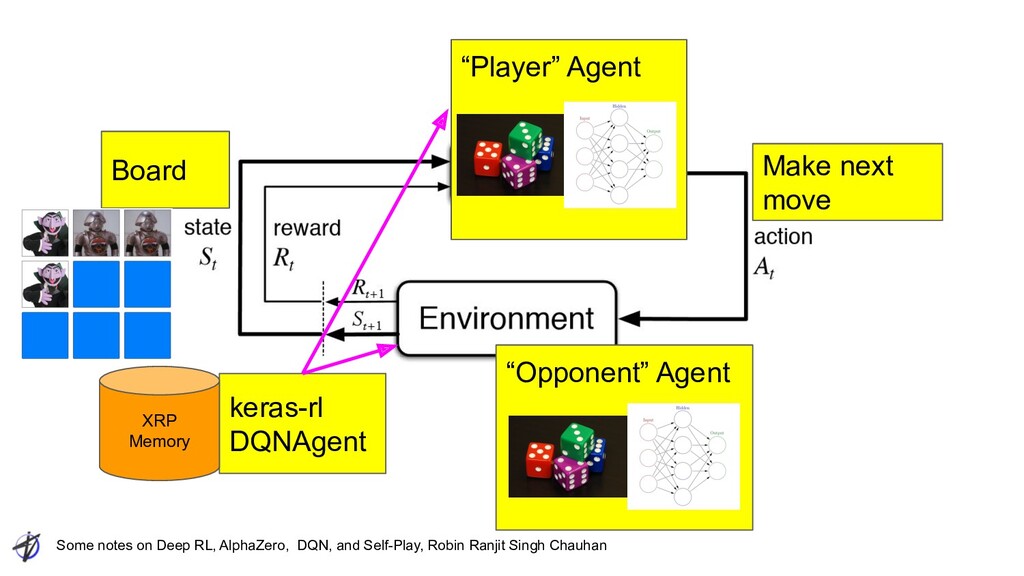
Ranjit Singh Chauhan AlphaZero DQN Domain Go : 361 moves Seconds to minutes for thinking Atari : 16 actions Milliseconds for thinking Network K-block Resnet Simpler CNN + FC Inputs Layers for each piece type ** Layer for side Layers with prev 4 frames of screen Target MCTS results Current reward + network outputs (recursive!) Loss MSE(value) + Cross Entropy(Policy) MSE(Q) Exploration UCT + Dirichlet noise Epsilon greedy Next move selection MCTS(k) Just take argmax Q
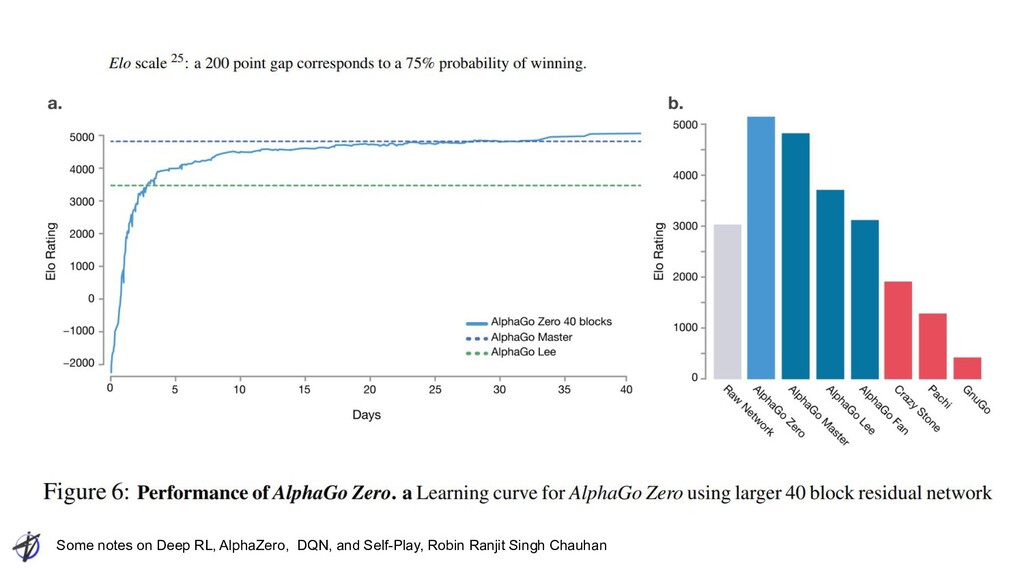
Ranjit Singh Chauhan • “most directly applicable to zero-sum games of perfect information" • Requires model ◦ Perfect : allows accurate sim over many steps ◦ Performant : allowing many (~10k) simulated decisions each step • Value function “bumpy” ◦ Value estimate can change unpredictably within a small # of steps/plies ◦ Otherwise, MCTS not as important ▪ Network could completely capture subtree value ▪ Alternatively, policy network could completely capture best move • For Go MDP, Value function alone could not capture enough detail Applicability of AlphaZero algo
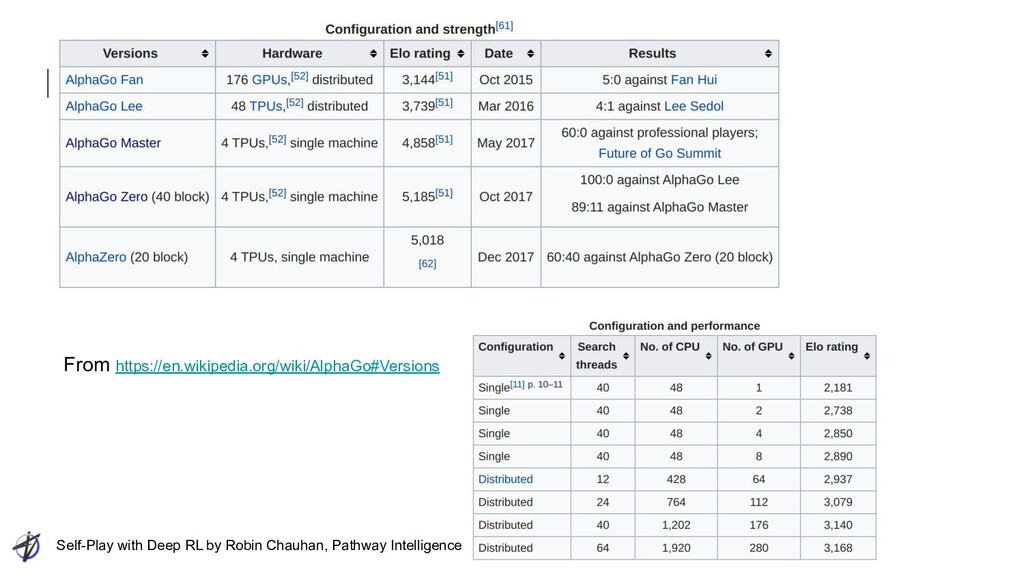
Ranjit Singh Chauhan AlphaZero References • AlphaGo: Mastering the game of Go with deep neural networks and tree search, Silver et al ◦ https://storage.googleapis.com/deepmind-media/alphago/AlphaGoNaturePaper.pdf • AlphaGo Zero: Mastering the Game of Go without Human Knowledge, Silver et al ◦ https://discovery.ucl.ac.uk/id/eprint/10045895/1/agz_unformatted_nature.pdf • AlphaZero: A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play, Silver et al ◦ Science paper https://science.sciencemag.org/content/sci/362/6419/1140.full.pdf ◦ Preprint https://arxiv.org/pdf/1712.01815.pdf • Implementations ◦ https://github.com/suragnair/alpha-zero-general ◦ https://github.com/junxiaosong/AlphaZero_Gomoku ◦ https://github.com/NeymarL/ChineseChess-AlphaZero ◦ https://github.com/pytorch/ELF ◦ https://github.com/topics/alphazero
Ranjit Singh Chauhan Self-Play: Measuring performance • Measuring performance in self-play can be stranger ◦ There is often no absolute score ◦ Can’t generally have humans in the loop ◦ Performance is often only relative to other agents • Special cases of competitors ◦ AlphaGo/Zero : other Go programs ◦ ConnectX : perfect play agent 33
Ranjit Singh Chauhan Games + Agents • Various agent designs ◦ with various deep learning network architectures • Training regime ◦ Distribution of opponents • Evaluation ◦ Round-robin Tournaments 37
Ranjit Singh Chauhan Sutskever on Self-Play / Multi-agent Play • Simple environments -> extremely complex strategy • Convert Compute into Data • Perfect curriculum • Main open question ◦ Design the self play environment so that the result will be useful to some external task • Social life incentivizes evolution of intelligence • Society of agents which will have... ◦ language, theory of mind, negotiation, social skills, trade, economy, politics, justice system … ◦ all these things should happen inside a multi-agent environment Comments from Ilya Sustkever presentation in MIT 6.S099 AGI class, April 2018 44
![Robin Ranjit Singh Chauhan [email protected] Notes on Deep RL, Self-Play,](https://files.speakerdeck.com/presentations/24d48c9e4fc6447c8c76b4d30188c90f/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}