A brief look at the new generation of models that are dominating Natural Language Processing (NLP). Focusing on GPT but also including ULMFiT, ElMO, BERT, and GPT2. Packed full of details and insight from the original papers, secondary sources, plus some original content.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Genealogy • Dai & Le 2015 [Google] ◦ use unlabeled](https://files.speakerdeck.com/presentations/77a67d7c258c46eb88f57e8d1667c381/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
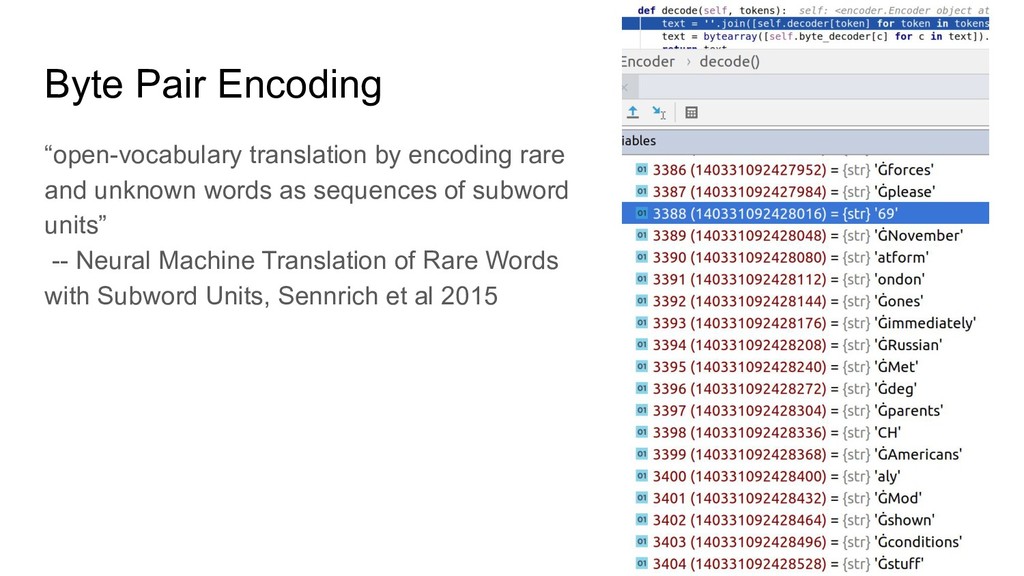{kind=link}
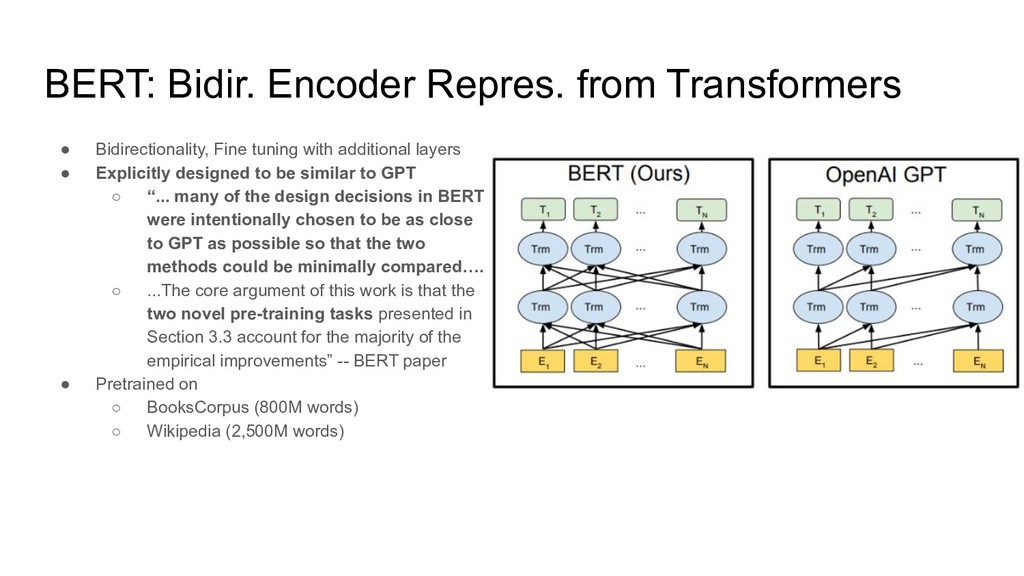{kind=link}
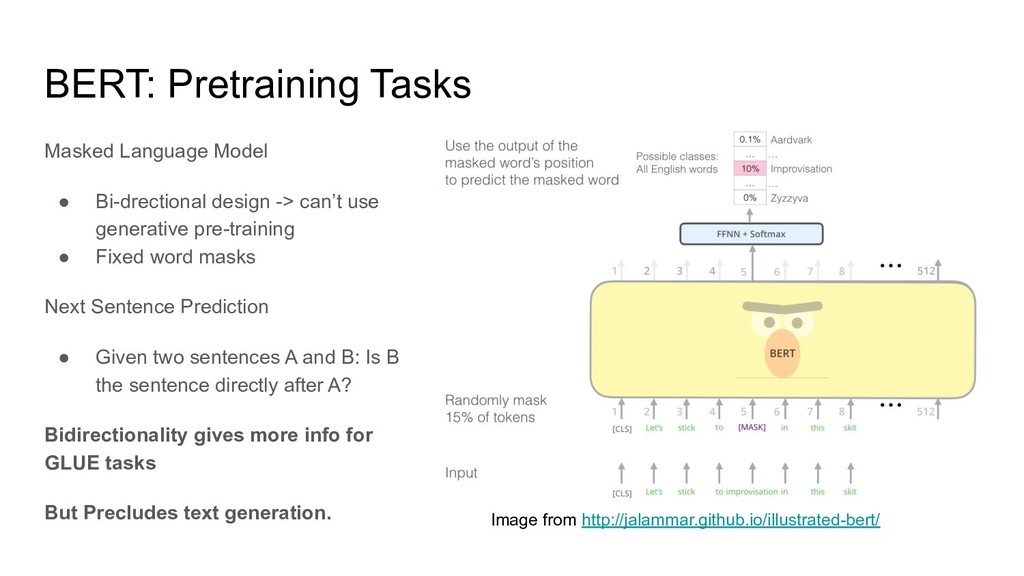{kind=link}
{kind=link}
{kind=link}
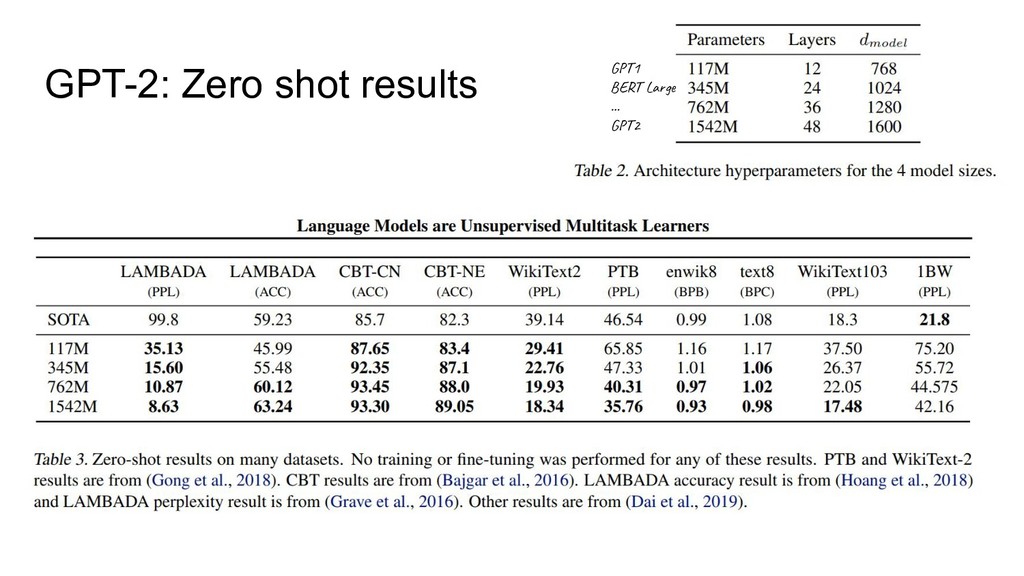{kind=link}
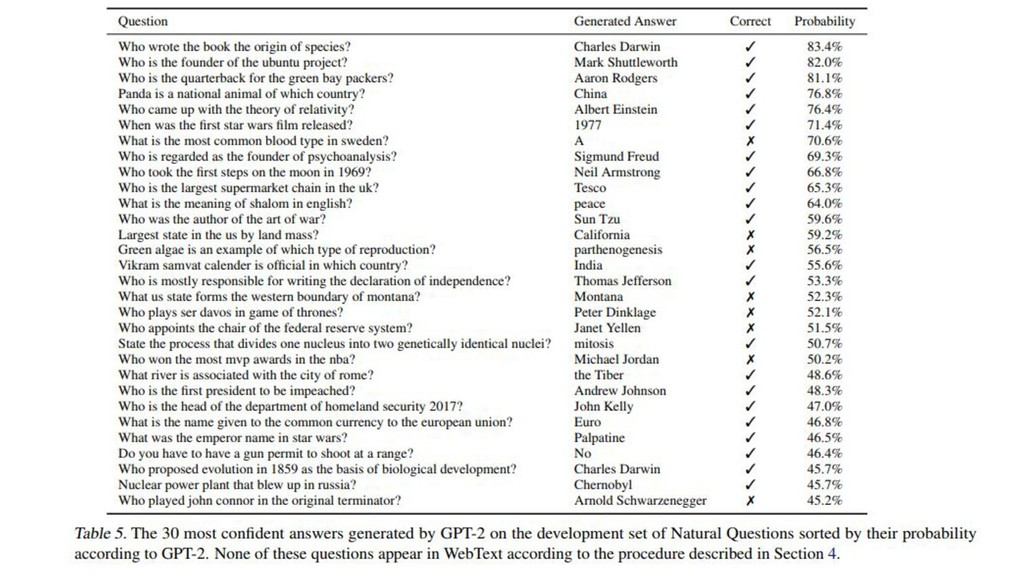{kind=link}
{kind=link}
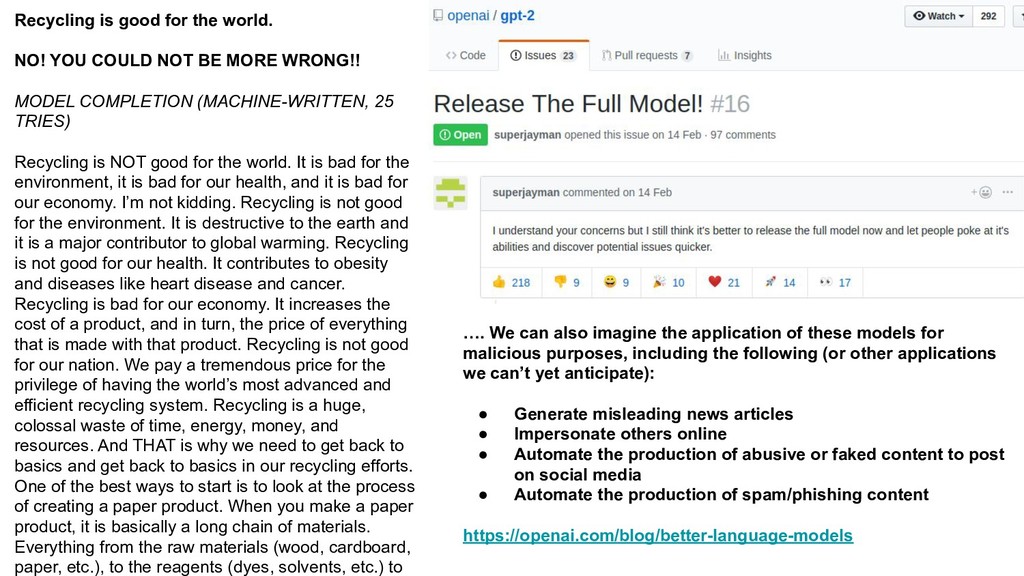{kind=link}
{kind=link}