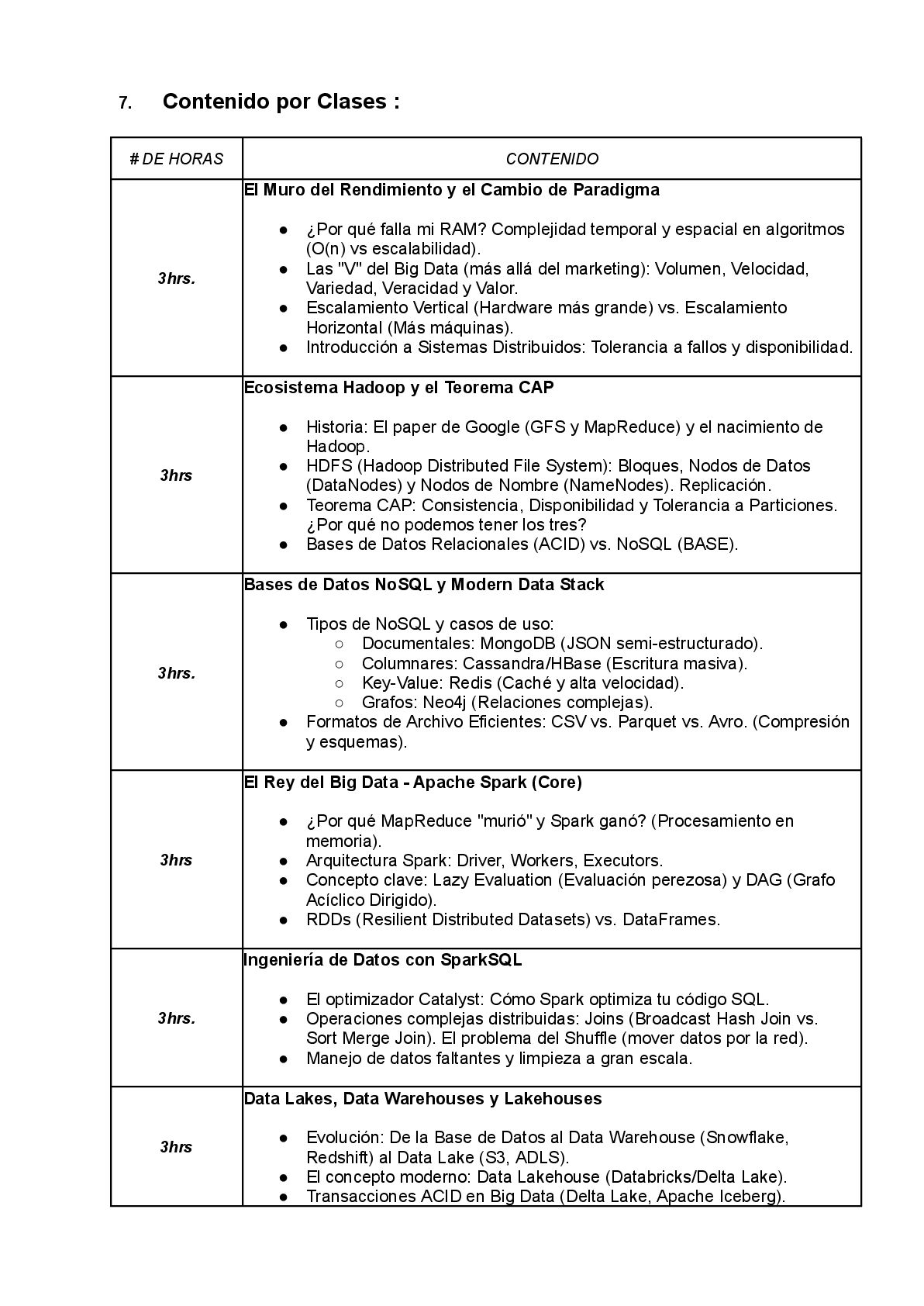
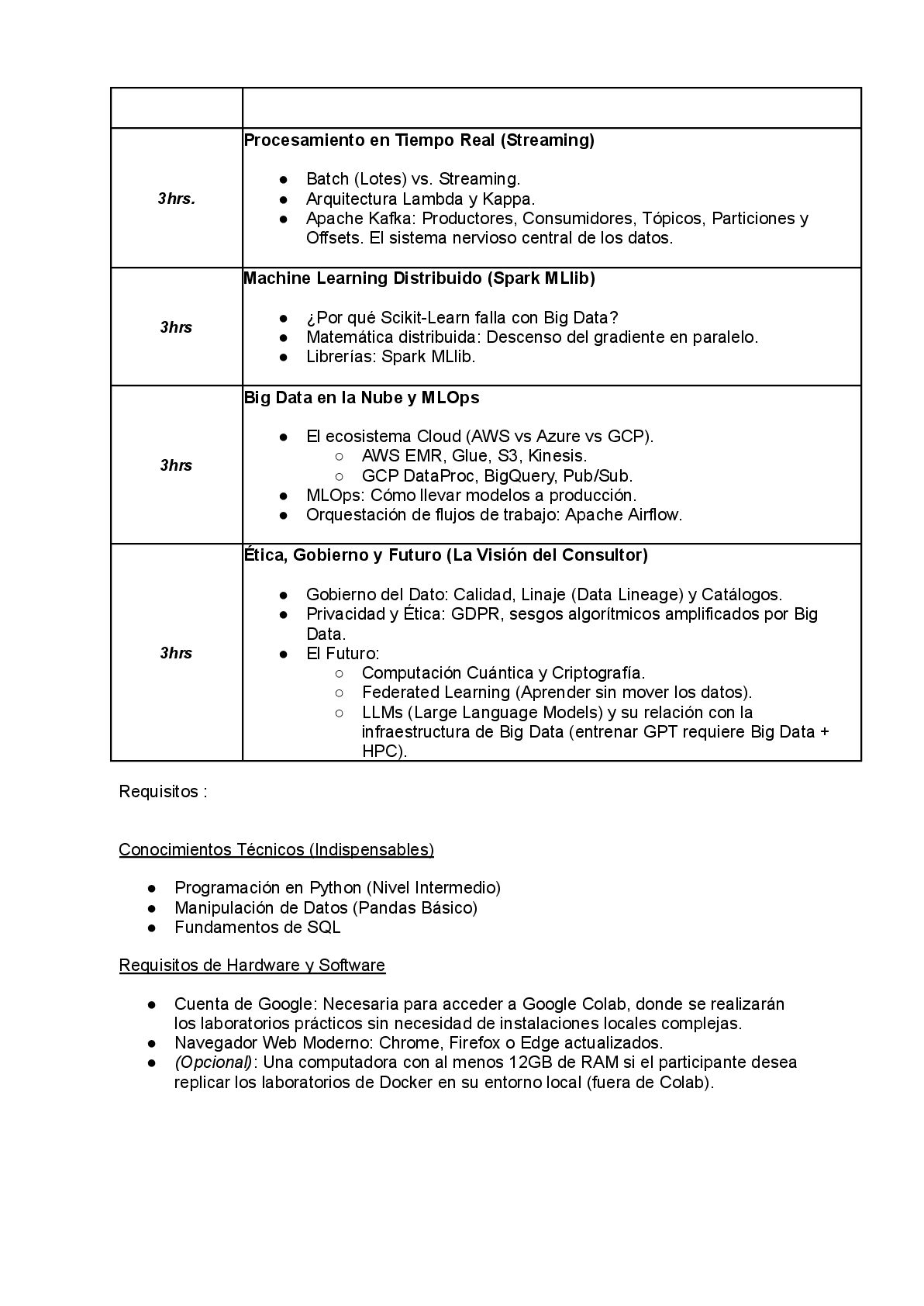
sesión, cambiaremos el paradigma de Batch (lotes) a Streaming (flujo continuo). Estudiaremos las arquitecturas Lambda y Kappa. Diseccionaremos el sistema nervioso central de las empresas modernas: Apache Kafka. Entenderemos Tópicos, Particiones y Offsets, y cómo garantizar que ningún mensaje se pierda, incluso si se apagan los servidores. Implementaremos ventanas de tiempo para calcular métricas en tiempo real. Clase 8: Inteligencia a Escala - Machine Learning Distribuido (Spark MLlib) Scikit-Learn es fantástico, pero no escala. ¿Cómo entrenamos un modelo con 1 billón de registros? Aquí veremos la matemática distribuida. Cómo funciona el descenso del gradiente cuando los datos están partidos en 100 máquinas. Usaremos Spark MLlib para crear pipelines de Feature Engineering (VectorAssembler, OneHotEncoding) y entrenar modelos de clasificación y regresión que aprenden de todo el dataset, no solo de una muestra. Clase 9: El Mundo Real - Cloud Computing y MLOps Dejaremos la teoría local para ir a la Nube. Compararemos AWS, Azure y GCP. Entenderemos la economía de la nube (Spot Instances, Serverless). Y abordaremos el problema más grande de la Ciencia de Datos: poner modelos en producción. Hablaremos de MLOps, el ciclo de vida del modelo, monitoreo de Data Drift (cuando los datos cambian y el modelo falla) y orquestación de flujos de trabajo complejos utilizando Apache Airflow. Clase 10: La Visión del Asesor - Ética, Gobierno y Futuro Cerraremos con la visión estratégica. El Big Data sin control es un riesgo legal. Hablaremos de Gobierno de Datos: Calidad, Linaje y Catálogos. Abordaremos la Ética y Privacidad: GDPR, sesgos algorítmicos y el derecho al olvido. Y finalmente, miraremos al horizonte: Computación Cuántica, Aprendizaje Federado y el impacto de los LLMs (Large Language Models) en la infraestructura de datos. VALOR PARA EL SECTOR PÚBLICO: TRANSPARENCIA Y EFICIENCIA Para los profesionales que sirven en el Sector Público, este curso no es un lujo, es una necesidad de estado. • Interoperabilidad: El estado maneja silos de información (Salud, Policía, Impuestos). Las arquitecturas de Data Lakehouse enseñadas aquí son la clave para la interoperabilidad real, permitiendo una visión única del ciudadano sin duplicar bases de datos. • Detección de Fraude y Evasión: Las técnicas de Streaming y Machine Learning distribuido son las herramientas estándar para detectar anomalías en compras públicas, facturación electrónica y movimientos financieros en tiempo real, no meses después cuando el dinero ya desapareció. • Diseño de Políticas Basadas en Evidencia: Moverse de la estadística muestral (encuestas) al análisis censal en tiempo real permite diseñar políticas públicas hiper-focalizadas y eficientes. • Soberanía del Dato: Entender las tecnologías Open Source (Spark, Kafka, Hadoop) permite al Estado construir infraestructuras soberanas sin depender de licencias costosas y cajas negras de proveedores propietarios ("Vendor Lock-in").
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}