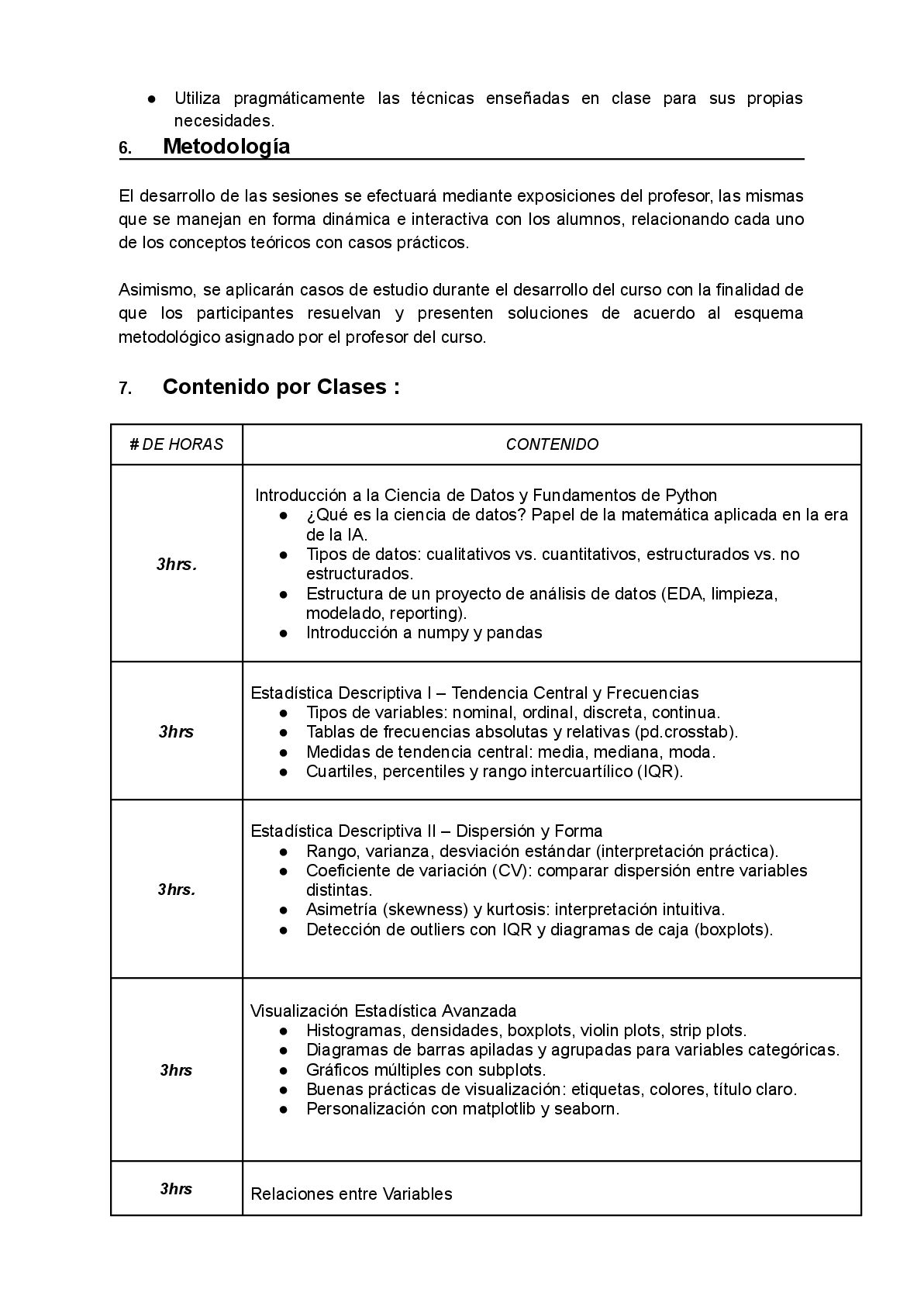
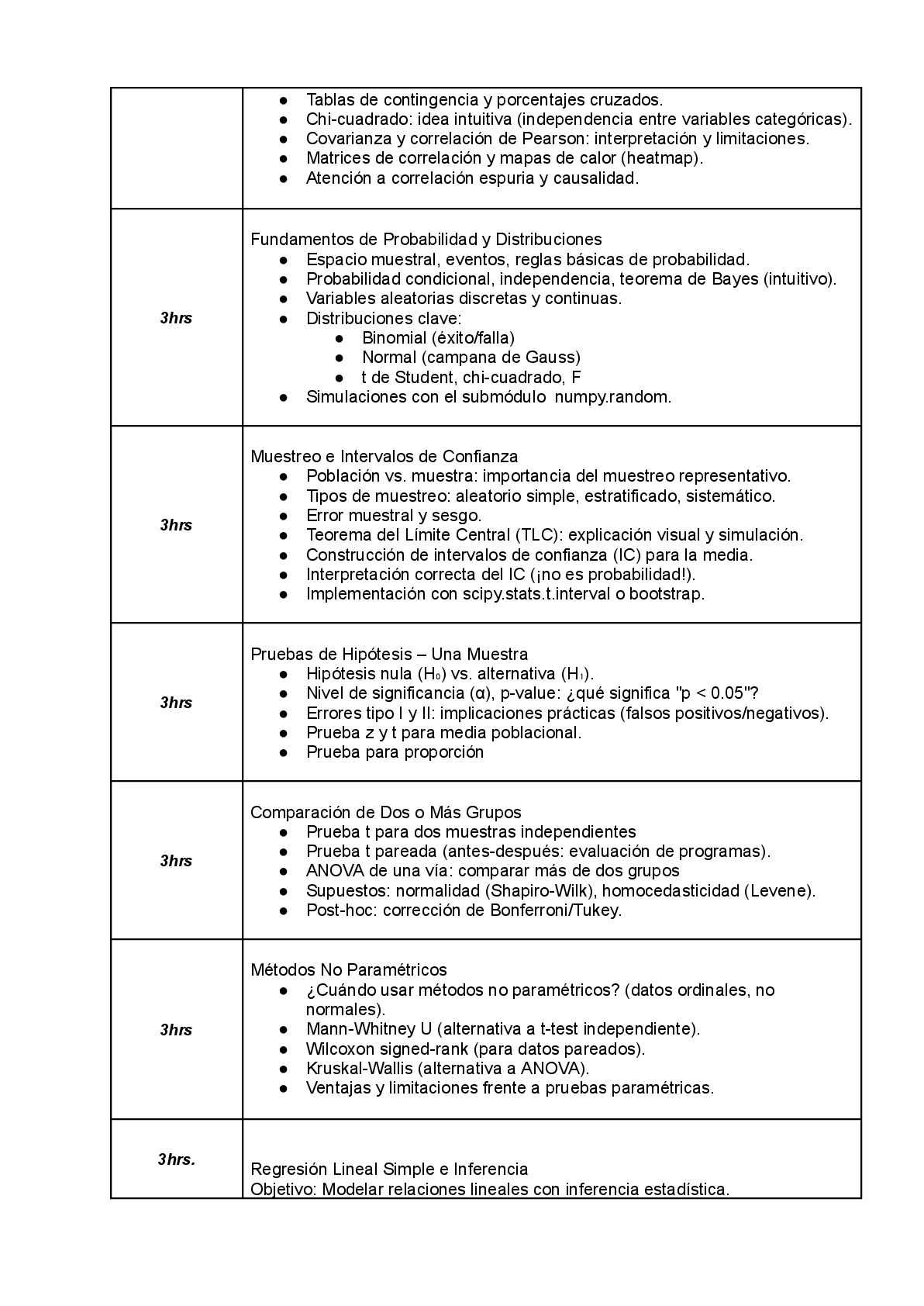
aplicarla. Y aquí entra Python. Python no es solo uno de los lenguajes de programación mas usados en nuestra sociedad. Es una plataforma de liberación intelectual. Por primera vez en la historia, cualquier persona con acceso a una computadora puede: • Cargar millones de registros • Calcular medidas descriptivas en micro segundos • Visualizar patrones complejos • Probar hipótesis con precisión • Construir modelos predictivos Sin necesidad de licencias costosas, sin depender de interfaces opacas, sin estar atados a software privativo. Python, junto con su ecosistema (pandas, numpy, matplotlib, scipy, statsmodels y scikit-learn), ha democratizado el análisis de datos. Y este curso lo pone al alcance de todos. Una Propuesta Interdisciplinaria para Todos los Perfiles Universitarios y Profesionales. Uno de los grandes errores en la educación actual es creer que la matemática y la programación son solo para “matemáticos” o “ingenieros”. Nada más alejado de la realidad. La matemática (y de manera más puntual : la estadística) es tan esencial para un sociólogo que estudia la desigualdad como para un biólogo que secuencia genomas, tan relevante para un lingüista que analiza corpus textuales como para un historiador que compara series temporales de conflictos sociales. Este curso está diseñado específicamente para estudiantes de ciencias sociales, ciencias exactas, ingenierías y letras, con al menos tres años de formación universitaria. ¿Por qué este perfil? Porque son ustedes quienes están en la línea de fuego entre el conocimiento técnico y el impacto social. Ustedes no solo consumen datos: los interpretan, los comunican, los usan para argumentar, para transformar realidades. Un estudiante de psicología necesita saber si una terapia cognitivo-conductual es significativamente más efectiva que otra. Un economista debe evaluar si una política fiscal tuvo un impacto real en el empleo. Un politólogo desea saber si hay asociación entre nivel educativo y participación electoral. Un ingeniero civil requiere estimar intervalos de confianza para la resistencia de un material. Un filólogo puede usar correlaciones para estudiar evolución léxica en distintas regiones. Todos ellos, sin excepción, necesitan de la matemática aplicada (estadística inferencial). No como una asignatura olvidada en algún semestre de su formación profesional, sino como una herramienta viva, práctica, aplicable. Y Python no es un obstáculo. Es un aliado. Por eso, el curso comienza desde cero: con una introducción accesible a pandas y numpy, usando entornos como Google Colab, eliminando barreras tecnológicas. Se exige experiencia básica en programación, es decir, haber aprobado un curso introductorio de python. Estructura del Curso: 12 Clases de Transformación Intelectual. El curso dura 36 horas, distribuidas en 12 clases de 3 horas cada una. Cada sesión es una inmersión completa: teoría, práctica, discusión y aplicación inmediata. Nada de esperar semanas para ver resultados. Desde la primera clase, ustedes trabajarán con datos reales, harán gráficos, calcularán estadísticos, probarán hipótesis. La proporción del contenido está cuidadosamente equilibrada: • 40% estadística descriptiva
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}