su evolución histórica. • Reconocer su papel central en el desarrollo de software y luego en el ecosistema de la ciencia de datos. • Mostrar cómo SQL es la herramienta principal para el data wrangling en entornos reales. • Conectar SQL con flujos modernos de ML/AI y arquitecturas de datos.
es un lenguaje declarativo estándar para gestionar y manipular sistemas de gestión de bases de datos relacionales (RDBMS). • Características clave: • Declarativo (no imperativo): describes qué quieres, no cómo hacerlo. • Estándar ANSI/ISO (aunque con dialectos). • Soporta operaciones CRUD + definición y control de datos (DDL, DML, DCL, TCL).
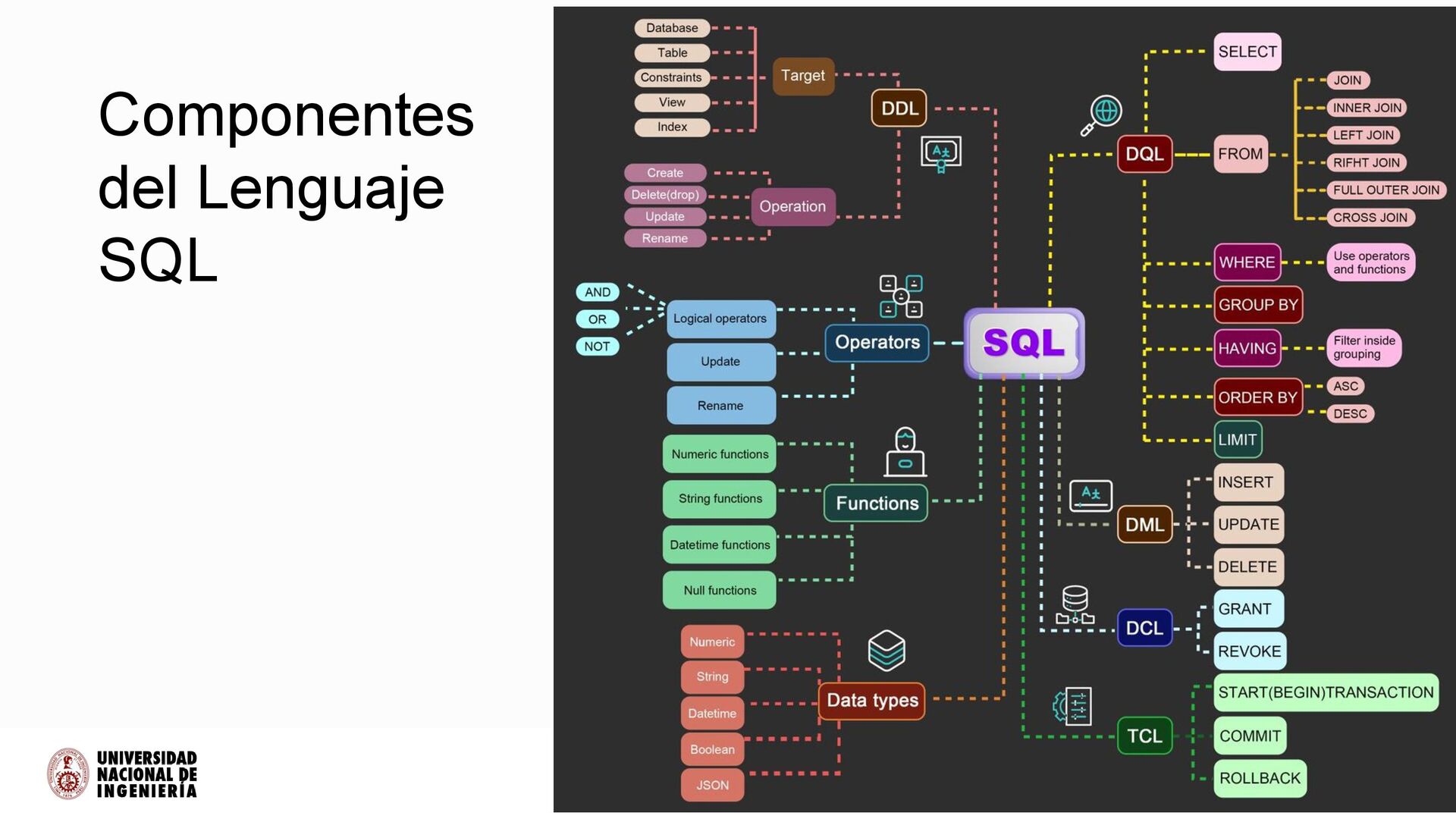
definición de datos (DDL) consiste en sentencias SQL que definen la estructura o el esquema de la base de datos. Se trata simplemente de descripciones del esquema de la base de datos y se utiliza para crear y modificar la estructura de los objetos de la base de datos.El DDL proporciona un conjunto de definiciones para especificar la estructura de almacenamiento y los métodos de acceso utilizados por el sistema de base de datos. Un DDL realiza las siguientes funciones: • Debe identificar el tipo de división de datos, como elemento de datos, segmento, registro y archivo de base de datos. • Da un nombre único a cada tipo de elemento de datos, tipo de registro, tipo de archivo y base de datos. • Debe especificar el tipo de datos adecuado. • Debe definir el tamaño del elemento de datos. • Puede definir el rango de valores que un elemento de datos puede utilizar. • Puede especificar bloqueos de privacidad para evitar el ingreso no autorizado de datos.
manipulación de datos (DML) es un lenguaje de programación utilizado Para agregar (insertar), eliminar (borrar) y modificar (actualizar) datos en una base de datos. En SQL, el lenguaje de manipulación de datos comprende las sentencias SQL, que modifican los datos almacenados, pero no el esquema de la tabla de la base de datos. Una vez especificado el esquema de la base de datos y creada la base de datos, los datos se pueden manipular utilizando un conjunto de procedimientos expresados por DML. Por manipulación de datos nos referimos a: • Inserción de nueva información en la base de datos • Recuperación de información almacenada en una base de datos. • Eliminación de información de la base de datos. • Modificación de datos almacenados en la base de datos. El DML es básicamente de dos tipos: • DML procedimental: requiere que el usuario especifique qué datos necesita y cómo obtenerlos. • DML no procedimental : requiere que el usuario especifique qué datos se necesitan sin especificando cómo obtenerlo.
(DCL) es el subconjunto de SQL encargado de gestionar permisos, roles y control de acceso sobre bases de datos y sus objetos. Qué hace : Controla quién puede conectarse, qué acciones puede realizar cada identidad y qué objetos puede ver o modificar. No altera datos. Administra autorización y reparto de privilegios. Roles y pertenencias • Se usan roles/grupos para agrupar privilegios. • Se asigna rol a usuarios. • Roles pueden tener herencia. • Es la base de RBAC (Role-Based Access Control).
Language) gestiona los límites de las transacciones: inicio, confirmación, reversión y puntos de control. TCL es el subconjunto de SQL que delimita unidades atómicas de trabajo. Permite agrupar varias operaciones DML en una sola operación lógica que se confirma o revierte en bloque. Asegura ACID a nivel de sesión/transacción. ACID (qué garantiza TCL) • Atomicidad: la transacción se aplica completa o no se aplica. • Consistencia: pasa de un estado válido a otro. • Aislamiento: resultados intermedios no visibles según el nivel de aislamiento. • Durabilidad: tras COMMIT los cambios persisten aún si falla el servidor. Buenas prácticas • Mantener transacciones cortas. • Evitar interacción humana dentro de la transacción. • Manejar deadlocks con backoff y reintento. • Versionar y probar scripts transaccionales. • Usar savepoints sólo cuando sea necesario. • Documentar expectativas de aislamiento y locks. • Probar bajo carga realista.
Language) es el subconjunto de SQL utilizado exclusivamente para consultar y recuperar datos almacenados en bases de datos. No modifica estructuras ni datos; su propósito es obtener información según criterios específicos. DQL permite: • Seleccionar columnas y filas. • Filtrar registros. • Ordenar y agrupar resultados. • Ejecutar agregaciones y cálculos. • Consultar relaciones entre tablas. El comando central de DQL es SELECT. Características clave • No modifica datos ni estructuras. • Produce un conjunto de resultados (result set). • Puede combinarse con DML para operaciones posteriores. • Es la base de reportes, dashboards, análisis de datos y aplicaciones de BI. • Permite optimizaciones con índices, particionamiento y estadísticas del SGBD. Buenas prácticas 1. Especificar columnas explícitamente en vez de SELECT *. 2. Usar filtros en WHERE para reducir I/O. 3. Evitar subconsultas redundantes; preferir joins o CTE (WITH). 4. Usar índices para columnas filtradas o usadas en joins. 5. Documentar consultas complejas para mantenimiento y auditoría.
F. Codd publica “A Relational Model of Data for Large Shared Data Banks” → fundamento teórico de las bases de datos relacionales (https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf) • 1974: Donald Chamberlin y Raymond Boyce (IBM) desarrollan SEQUEL (Structured English Query Language) como interfaz para el sistema System R. (https://s3.us.cloud-object-storage.appdomain.cloud/res-files/2705-sequel-1974.pdf) • 1979: Oracle lanza la primera implementación comercial de SQL. Puntos clave de Oracle en 1979: ❖ La primera base de datos relacional comercial: Oracle v2 fue la primera base de datos relacional disponible para la compra y uso comercial. ❖ Introducción de SQL: Esta versión introdujo el concepto de SQL (Structured Query Language), un lenguaje estandarizado para consultar y manipular bases de datos. ❖ Cambio de nombre: El mismo año, SDL (nombre original de la empresa) cambió su nombre a Relational Software, Inc. (RSI). ❖ Fundación de la empresa: Oracle fue fundada en 1977 por Larry Ellison, Bob Miner y Ed Oates, bajo el nombre de SDL. El nombre "Oracle" provino de un proyecto de la CIA para el que trabajaron sus fundadores.
primer estándar ANSI SQL-86 (también llamado SQL-1986) es la primera especificación formal de SQL emitida por el American National Standards Institute (ANSI) en 1986. Su objetivo era unificar y normalizar el lenguaje SQL, que ya se usaba de manera propietaria en diferentes sistemas de bases de datos, principalmente derivados de IBM System R y Ingres. Características principales de SQL-86 1. Alcance limitado 2. Tipos de datos 3. Restricciones y claves 4. Subconsultas y joins 5. Funciones agregadas 6. Transacciones y control 7. Independencia de implementación Impacto histórico • Estableció la base del lenguaje SQL moderno. • Permitió que sistemas como Oracle, DB2 y SQL Server empezaran a converger en sintaxis y funcionalidades. • Sirvió como punto de partida para las posteriores revisiones: SQL-89 (SQL1) y SQL-92 (SQL2), que añadieron integridad referencial, subconsultas complejas, joins completos y DDL/DCL más avanzadas. • Puso los cimientos para la adopción global de SQL como lenguaje estándar para bases de datos relacionales.
→ mayor rigor y portabilidad. SQL-89 (SQL1) Nombre: Primera revisión del estándar ANSI SQL-86 1. Correcciones y clarificaciones 2. Integridad referencial (básica) 3. Compatibilidad ampliada 4. Limitaciones SQL-92 (SQL2) Nombre: Segunda revisión significativa del estándar ANSI SQL 1. Soporte completo de integridad referencial 2. Tipos de datos ampliados 3. Joins y subconsultas completas 4. Funciones agregadas y GROUP BY / HAVING 5. Transacciones y control de concurrencia 6. Extensiones de DDL, DCL y TCL 7. Compatibilidad con aplicaciones y portabilidad
de datos complejos, expresiones regulares, y funciones recursivas (WITH RECURSIVE). Características principales de SQL-99 : 1. Programación en SQL: Procedimientos y Triggers 2. Tipos de datos avanzados 3. Soporte para objetos 4. Common Table Expressions (CTE) 5. Mejoras en integridad y constraints 6. Agregados y OLAP 7. Soporte para XML 8. Subconjuntos del estándar Impacto histórico • SQL-99 convirtió SQL en un lenguaje más completo y orientado a aplicaciones empresariales. • Introdujo conceptos que hoy son estándar en casi todos los SGBD modernos: CTE, funciones de ventana, UDT, triggers, procedimientos almacenados y consultas recursivas. • Fue la base para SQL:2003, que agregó soporte completo para XML y mejoras OLAP.
XML (SQL/XML) ◦ Definición y manipulación de datos XML. ◦ Funciones para generar y consultar XML (XMLQUERY, XMLTABLE). 2. Funciones de ventana (window functions) ◦ Soporte completo para OVER(PARTITION BY … ORDER BY …). ◦ Ranking, agregados acumulativos, promedios móviles, percentiles. 3. Generación automática de secuencias (sequences) 4. MERGE (UPSERT) ◦ Combina INSERT y UPDATE en una sola sentencia según existencia de registro. 5. Mejoras en integridad y constraints ◦ Posibilidad de definir constraints más complejas ◦ Mejor integración con triggers y transacciones.
de XML más profunda ◦ Consulta y transformación de datos XML dentro de SQL. ◦ Estándares para interoperabilidad de XML con bases de datos relacionales.
TABLE estandarizado ◦ Eliminación rápida de datos sin afectar la estructura. 2. Particionamiento y manejo de grandes ◦ Mejor soporte para bases de datos masivas 3. Manejo de tipos de datos temporales (date/time ◦ Intervalos, timestamps, zonas horarias, diferencias entre fechas y horas. 4. MERGE estandarizado ◦ UPSERT formal en todos los SGBD compatibles con el estándar.
para temporal tables (System-Versioned Tables) ◦ Tablas que mantienen el historial de cambios automáticamente. ◦ Facilita auditoría y consultas sobre datos históricos. 2. Mejoras en OLAP y funciones de ventana ◦ Nuevos ranking, agregados acumulativos y cálculos sobre particiones. 3. Estándares más estrictos de integridad y compliance ◦ Facilita interoperabilidad y seguridad.
support ◦ Consultas y manipulación de datos JSON (JSON_VALUE, JSON_TABLE ◦ Integración con estructuras semi-estructuradas. 2. Política de Row-level security y privilegios más finos ◦ Mejor control de acceso a nivel de fila. 3. Funciones analíticas y agregadas extendidas ◦ Nuevas funciones para análisis de series de tiempo, estadísticas y ranking. 4. Mejor integración con Big Data y entornos distribuidos ◦ Bases de datos modernas pueden combinar SQL relacional con JSON y datos masivos.
facto para el acceso a datos estructurados. 🗓 2017: SQL Server 2017 • Compatibilidad multiplataforma: Introducción de soporte para Linux y contenedores Docker. • Mejoras en rendimiento: Optimización de consultas y mejoras en el motor de base de datos. • Soporte para Python: Integración del lenguaje Python para análisis de datos. 🗓 2019: SQL Server 2019 • Big Data Clusters: Integración de datos no estructurados con Apache Spark y HDFS. • Mejoras en inteligencia artificial: Soporte ampliado para modelos de machine learning. • Optimización de consultas: Mejoras en el procesamiento de consultas y en la ejecución de planes. 🗓 2022: SQL Server 2022 • Integración con Azure: Conexión nativa con Azure Synapse Analytics y Azure SQL Managed Instance. • Ledger para auditoría: Soporte para registros inmutables y auditoría de datos. • Mejoras en seguridad: Integración con Microsoft Purview para políticas de acceso. 🗓 2025: SQL Server 2025 (en vista previa) • Integración de inteligencia artificial: Soporte para búsquedas vectoriales y gestión de modelos de IA dentro de la base de datos. • Mejoras en productividad del desarrollador: Soporte para API REST, GraphQL, expresiones regulares y JSON. • Mejoras en rendimiento y seguridad: Optimización de consultas y mejoras en la seguridad de datos.
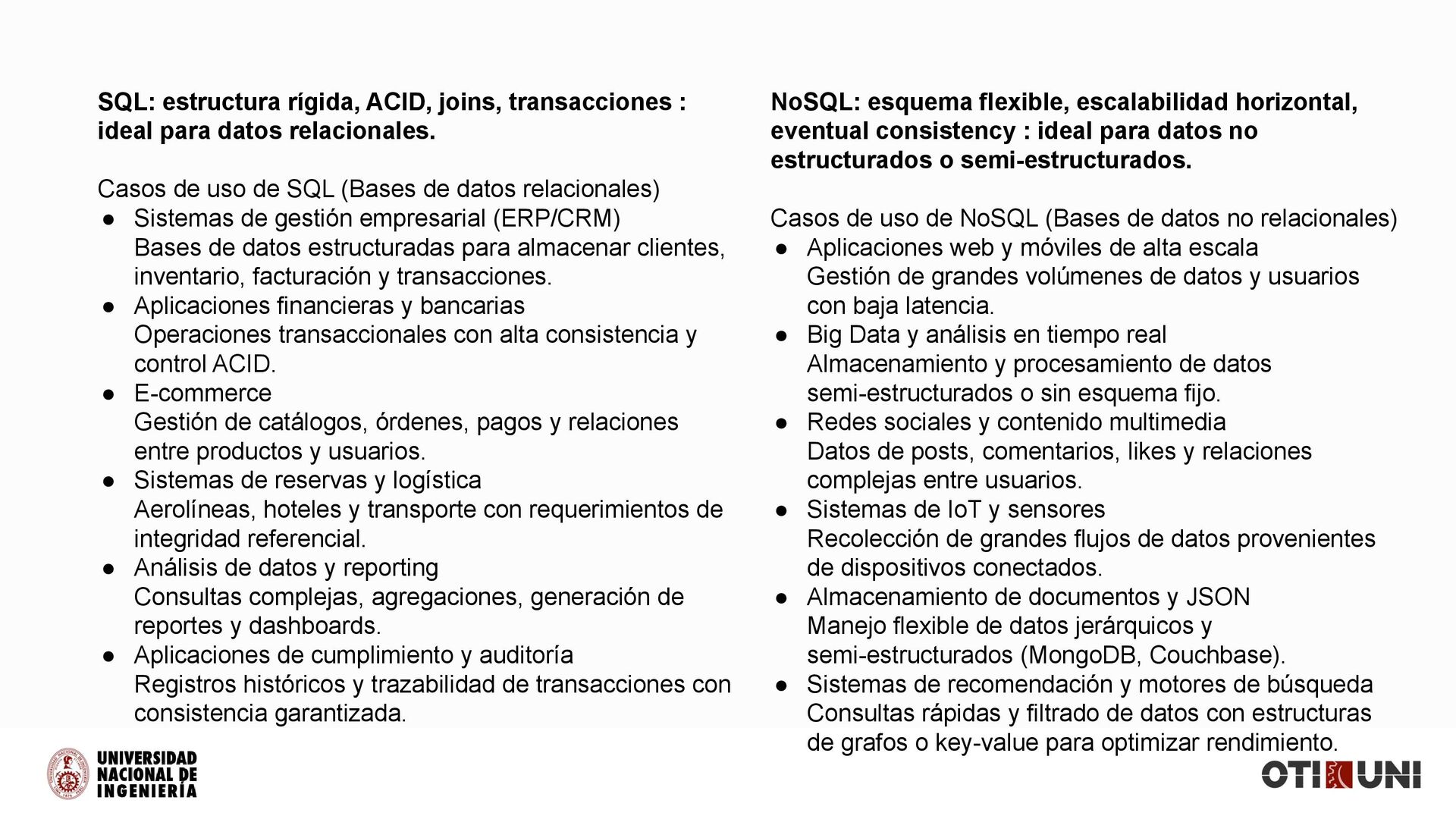
relacionales. Casos de uso de SQL (Bases de datos relacionales) • Sistemas de gestión empresarial (ERP/CRM) Bases de datos estructuradas para almacenar clientes, inventario, facturación y transacciones. • Aplicaciones financieras y bancarias Operaciones transaccionales con alta consistencia y control ACID. • E-commerce Gestión de catálogos, órdenes, pagos y relaciones entre productos y usuarios. • Sistemas de reservas y logística Aerolíneas, hoteles y transporte con requerimientos de integridad referencial. • Análisis de datos y reporting Consultas complejas, agregaciones, generación de reportes y dashboards. • Aplicaciones de cumplimiento y auditoría Registros históricos y trazabilidad de transacciones con consistencia garantizada. NoSQL: esquema flexible, escalabilidad horizontal, eventual consistency : ideal para datos no estructurados o semi-estructurados. Casos de uso de NoSQL (Bases de datos no relacionales) • Aplicaciones web y móviles de alta escala Gestión de grandes volúmenes de datos y usuarios con baja latencia. • Big Data y análisis en tiempo real Almacenamiento y procesamiento de datos semi-estructurados o sin esquema fijo. • Redes sociales y contenido multimedia Datos de posts, comentarios, likes y relaciones complejas entre usuarios. • Sistemas de IoT y sensores Recolección de grandes flujos de datos provenientes de dispositivos conectados. • Almacenamiento de documentos y JSON Manejo flexible de datos jerárquicos y semi-estructurados (MongoDB, Couchbase). • Sistemas de recomendación y motores de búsqueda Consultas rápidas y filtrado de datos con estructuras de grafos o key-value para optimizar rendimiento.
de bases de datos (SGBD) que implementan el estándar SQL y operan sobre datos estructurados en tablas con relaciones definidas mediante claves primarias y foráneas. Se enfocan en consistencia, integridad y transacciones ACID. Características principales: • Estructura fija (schema): Las tablas tienen columnas con tipos de datos definidos. • Integridad referencial: Relaciones entre tablas controladas mediante claves. • Transacciones ACID: Atomicidad, Consistencia, Aislamiento, Durabilidad. • Consultas complejas: Joins, subconsultas, funciones agregadas, CTE, funciones de ventana. • Optimización: Índices, planes de ejecución y caché de consultas. Ejemplos de motores SQL: • MySQL / MariaDB: Popular en web y aplicaciones comerciales, soporte para transacciones (InnoDB). • PostgreSQL: Avanzado, soporte completo de ACID, funciones de ventana, JSON y extensiones. • Oracle Database: Corporativo, optimización de transacciones y alta disponibilidad. • SQL Server: Integración con ecosistema Microsoft, BI y análisis avanzado. • SQLite: Motor embebido, ligero, ideal para aplicaciones locales o móviles.
datos que no requieren esquema fijo y están optimizadas para alto rendimiento, escalabilidad horizontal y grandes volúmenes de datos semi-estructurados o sin estructura. Se enfocan en flexibilidad y velocidad, a veces sacrificando consistencia estricta (ACID) en favor de disponibilidad y particionamiento (BASE). Características principales: • Modelo flexible: key-value, documento, columna ancha o grafo. • Escalabilidad horizontal: Ideal para clústeres y grandes volúmenes. • Alta disponibilidad: Replicación y tolerancia a fallos. • Optimizado para lectura/escritura rápida. • Consistencia eventual: La coherencia se garantiza con retraso en lugar de inmediatamente (opcional). Ejemplos de motores NoSQL: • MongoDB: Documento (JSON/BSON), flexible y escalable, consultas ricas. • Cassandra: Columna ancha, alta disponibilidad, tolerancia a fallos y escalabilidad horizontal. • Redis: Key-value, ultra rápido, caching y colas en memoria. • Neo4j: Base de datos de grafos, relaciones complejas y búsquedas de caminos. • Couchbase: Documento + key-value, con replicación y sincronización offline.
Cassandra, BigQuery) han incorporado dialectos SQL-like (e.g., SQL++, CQL, BigQuery SQL). SQL++ es una extensión del lenguaje SQL estándar que está diseñada para consultar y gestionar datos en formato JSON y semiestructurado, permitiendo a los usuarios aprovechar sus conocimientos de SQL en entornos de bases de datos NoSQL. SQL++ es compatible con versiones anteriores de SQL y añade sintaxis para manejar la naturaleza anidada y opcionalmente esquematizada de los datos JSON, con funcionalidades para trabajar con atributos faltantes y tipos heterogéneos. Propósito y características principales • Manejo de datos JSON • Compatibilidad retroactiva • Flexibilidad • Extensión del estándar SQL • Configurabilidad CQL, o Cassandra Query Language, es el lenguaje de consulta para bases de datos NoSQL, específicamente para el modelo de familia de columnas, como Apache Cassandra. Aunque es similar a SQL, CQL está diseñado para las estructuras de datos no relacionales de Cassandra, permitiendo la creación y manipulación de datos en un modelo de familias de columnas en lugar de tablas relacionales. ¿Por qué CQL es importante en NoSQL? • Lenguaje de acceso: CQL es el lenguaje utilizado para interactuar con bases de datos NoSQL de familia de columnas, como Apache Cassandra. • Sintaxis familiar • Adaptado al modelo: Fue desarrollado específicamente para el modelo de datos de familia de columnas de Cassandra, lo que permite una gestión eficiente de datos no estructurados y semiestructurados.
streams) 2. Ingesta y almacenamiento (SQL/NoSQL, Data Lakes, Data Warehouses) 3. Preparación de datos (data wrangling) 4. Modelado y análisis (ML, estadística, visualización) 5. Despliegue y monitoreo (MLOps, dashboards) SQL actúa en capas 1, 2 y 3. ¿Qué es Data Wrangling? • Definición: proceso de limpieza, transformación, integración y enriquecimiento de datos crudos para su análisis. • Según estudios, ~80% del tiempo de un científico de datos se dedica a wrangling. • Herramientas comunes: Pandas, Spark, OpenRefine… pero la fuente principal sigue siendo SQL.
para wrangling: • Eficiencia: operaciones en la base de datos (no en memoria local). • Escalabilidad: motores optimizados (índices, query planners). • Reproducibilidad: scripts versionables. • Integración nativa con BI, ETL y pipelines de ML. SQL en Entornos Modernos de Ciencia de Datos • Data Warehouses en la nube: Snowflake, BigQuery, Redshift → SQL nativo + escalabilidad masiva. • Notebooks + SQL: Jupyter con ipython-sql, Google Colab con BigQuery. • Orquestación: Airflow, Prefect → tareas SQL como pasos en pipelines. • Feature Stores: muchas usan SQL para definir features (e.g., Feast, Tecton). Integración con Python – El Stack Científico • pandas.read_sql() → carga directa desde DB a DataFrame. • SQLAlchemy → ORM para abstracción de motores. • dbt (data build tool) → transformaciones modulares en SQL. • Patrón recomendado: usa SQL para wrangling pesado, Python para modelado y visualización.
en base de datos: evita mover TBs de datos. • Inferencia en base de datos: PostgreSQL con pgml, Oracle con ML integrado. • Modelos entrenados con datos SQL: la mayoría de datasets de entrenamiento provienen de queries. Buenas Prácticas para Científicos de Datos • Escribe queries legibles y comentadas. • Usa CTEs (WITH) en lugar de subqueries anidadas. • Evita SELECT * en producción. • Parametriza queries para reutilización. • Versiona tus scripts SQL (Git). Desafíos Actuales • Complejidad creciente: SQL moderno incluye JSON, arrays, UDFs. • Performance: malas queries pueden colapsar sistemas. • Gobernanza: control de acceso, auditoría, calidad de datos. • Brecha de habilidades: muchos científicos de datos subestiman SQL.
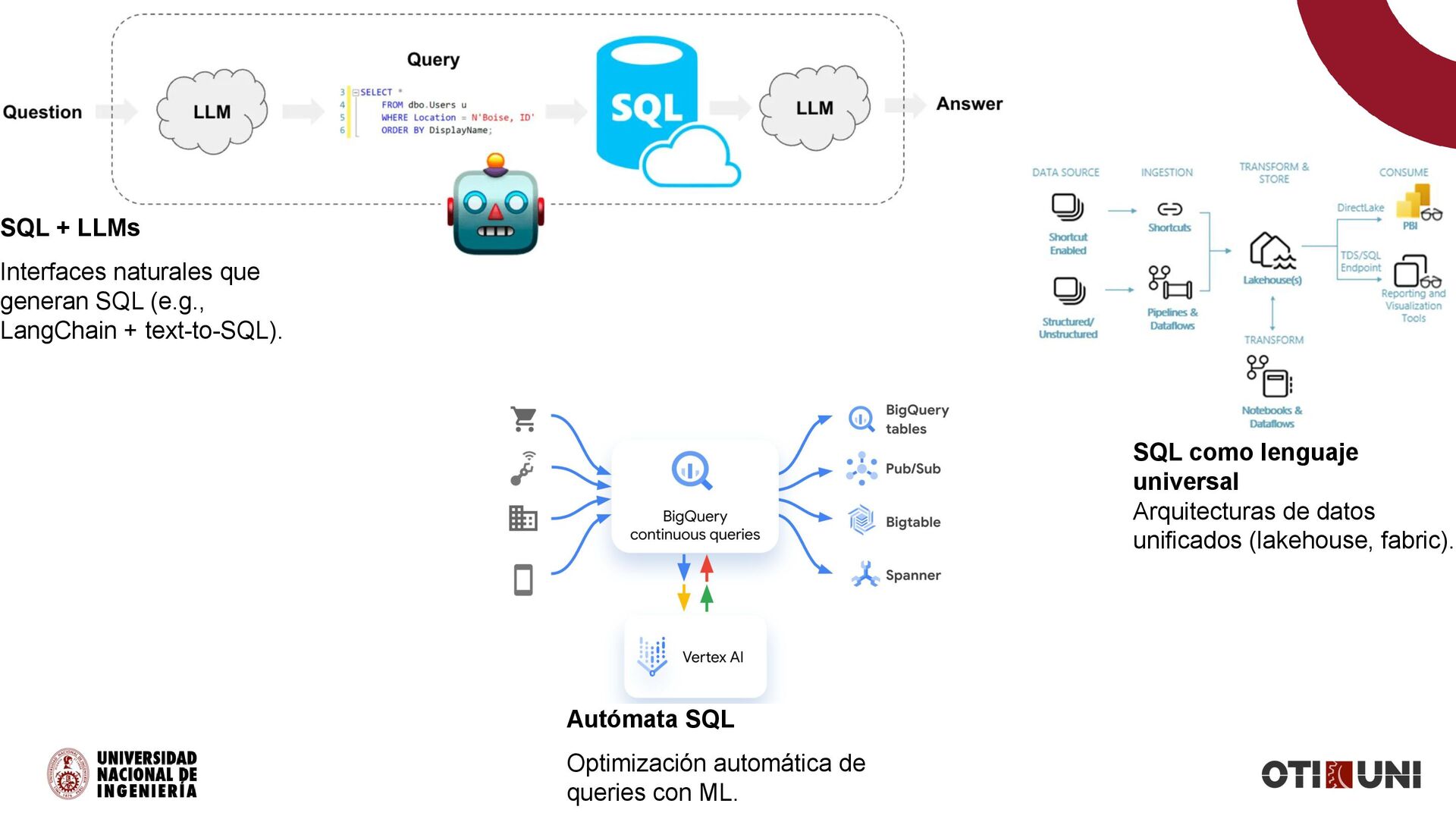
+ text-to-SQL). Autómata SQL Optimización automática de queries con ML. SQL como lenguaje universal Arquitecturas de datos unificados (lakehouse, fabric).
omnipresente. • En ciencia de datos, dominar SQL es tan crucial como dominar Python o estadística. • El verdadero poder está en combinar SQL con el ecosistema moderno de IA.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}