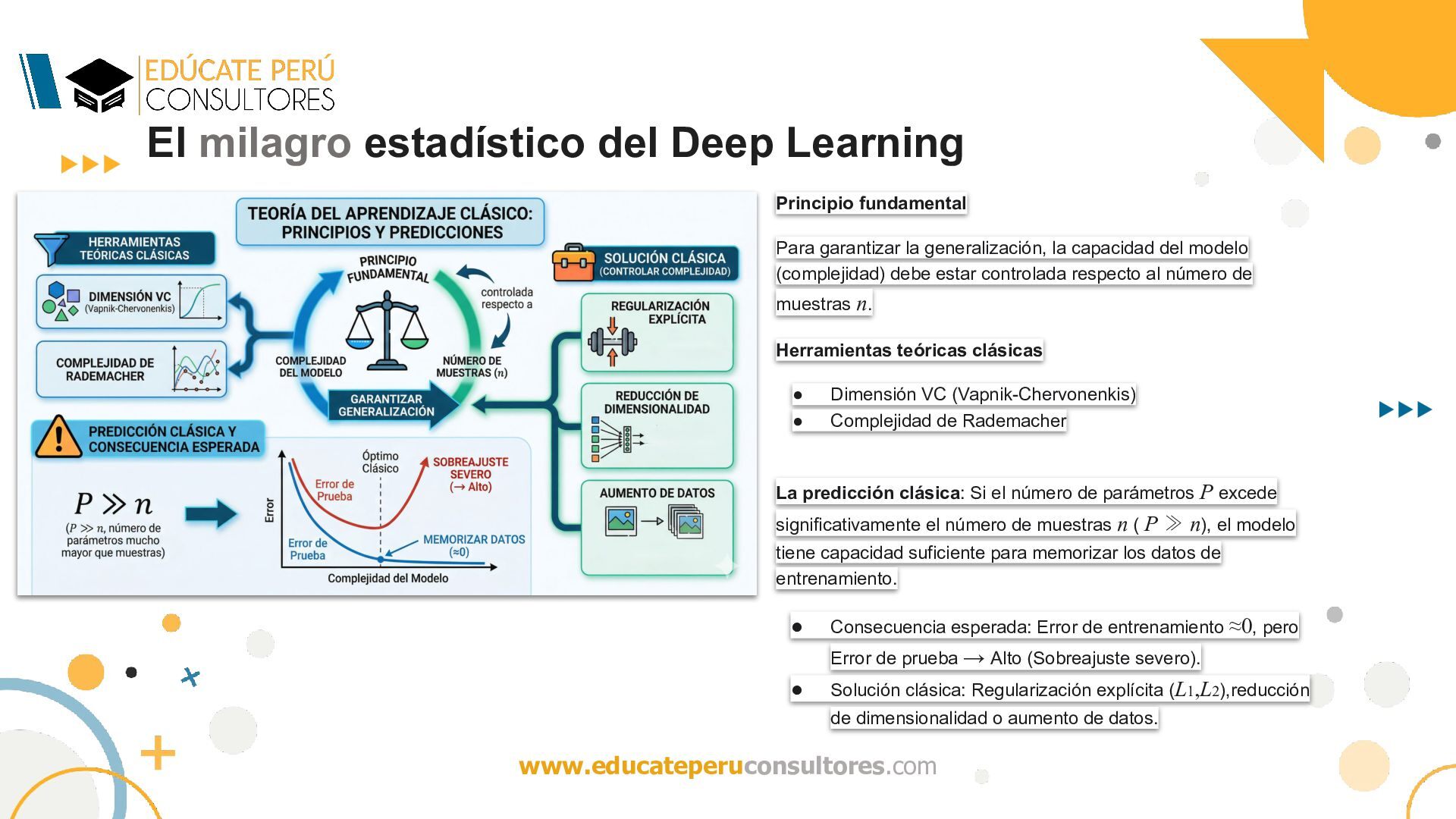
garantizar la generalización, la capacidad del modelo (complejidad) debe estar controlada respecto al número de muestras n. Herramientas teóricas clásicas • Dimensión VC (Vapnik-Chervonenkis) • Complejidad de Rademacher La predicción clásica: Si el número de parámetros P excede significativamente el número de muestras n ( P ≫ n), el modelo tiene capacidad suficiente para memorizar los datos de entrenamiento. • Consecuencia esperada: Error de entrenamiento ≈0, pero Error de prueba → Alto (Sobreajuste severo). • Solución clásica: Regularización explícita (L1,L2),reducción de dimensionalidad o aumento de datos.
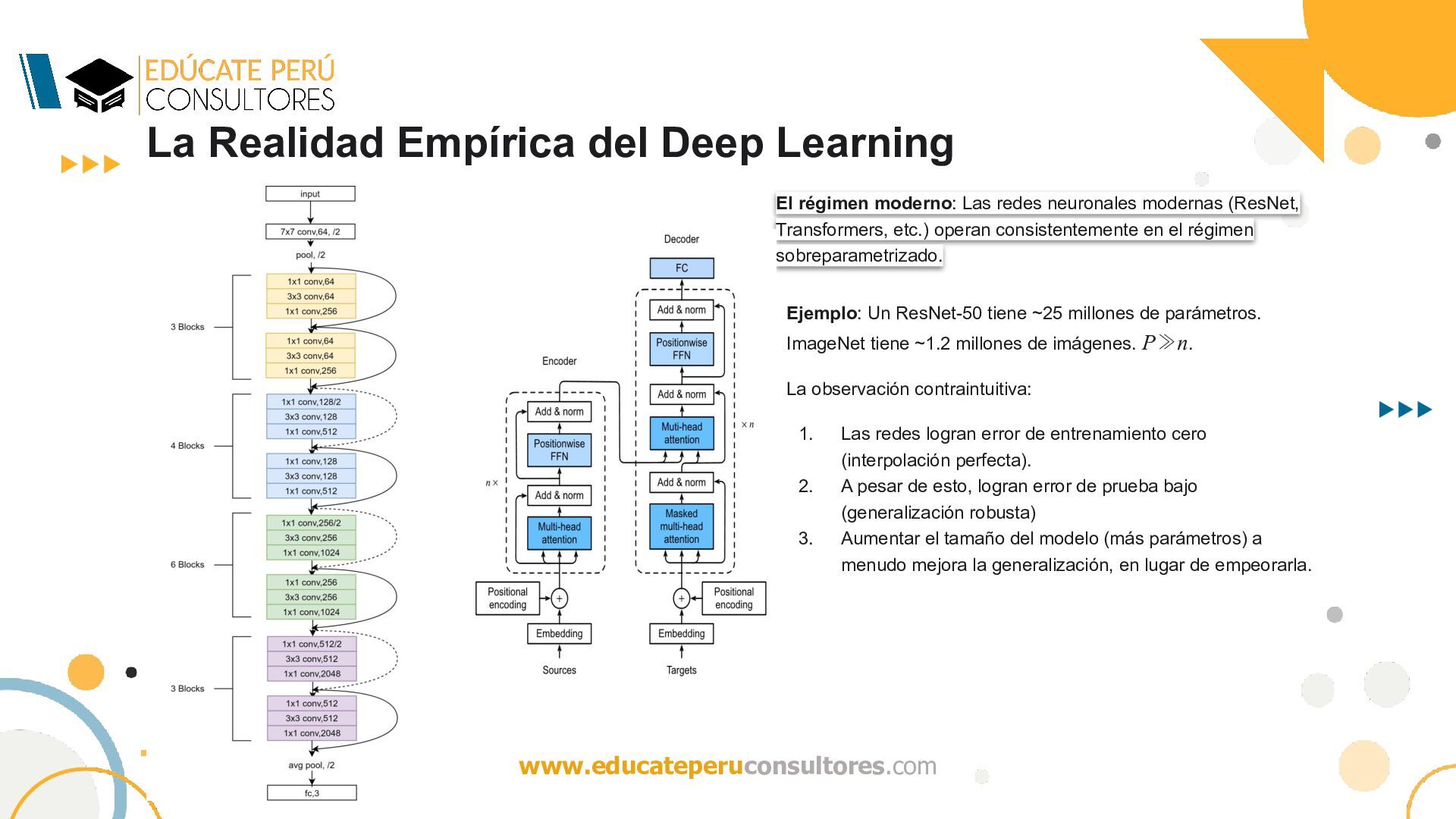
Las redes neuronales modernas (ResNet, Transformers, etc.) operan consistentemente en el régimen sobreparametrizado. Ejemplo: Un ResNet-50 tiene ~25 millones de parámetros. ImageNet tiene ~1.2 millones de imágenes. P≫n. La observación contraintuitiva: 1. Las redes logran error de entrenamiento cero (interpolación perfecta). 2. A pesar de esto, logran error de prueba bajo (generalización robusta) 3. Aumentar el tamaño del modelo (más parámetros) a menudo mejora la generalización, en lugar de empeorarla.
del experimento: 1. Entrenar una red potente (Inception, AlexNet) en CIFAR-10 (datos reales). 2. Entrenar la misma red en CIFAR-10 con etiquetas aleatorizadas (shuffled labels). 3. Entrenar la misma red en imágenes de ruido (gaussiano) con etiquetas reales. Resultados: • Datos Reales: Train Error → 0%, Test Error ≈ 10% (Excelente). • Etiquetas Aleatorias Train Error → 0% (La red memoriza el ruido), Test Error ≈ 90% (Error chance). • Imágenes de Ruido: Train Error → 0%, Test Error ≈ ≈ 90%. Conclusión devastadora para la teoría clásica: • La red tiene la capacidad expresiva para memorizar ruido completo. • Por lo tanto, las cotas clásicas basadas solo en la capacidad del modelo (VC dimension) son demasiado laxas (vacuously true bounds). • La generalización no depende solo de la arquitectura, sino de la interacción entre algoritmo de optimización (SGD) y estructura de los datos.
Formales del Problema de Aprendizaje a. El Espacio de Probabilidad Subyacente i. Definición 1 (Espacio de Generación de Datos): b. La Clase de Hipótesis (Espacio de Funciones) i. Definición 2 (Clase de Hipótesis Paramétrica): ii. Estructura típica de una red neuronal: 2. La Función de Pérdida Empírica a. Definición 3 (Riesgo Empírico): b. El Problema de Optimización Empírica (ERM) c. Propiedades Estadísticas del Riesgo Empírico 3. El Riesgo Verdadero a. Definición 4 (Riesgo Verdadero / Riesgo Esperado) b. Descomposición del Riesgo Verdadero i. Teorema 1 (Descomposición Sesgo-Varianza-Ruido): c. Estimación del Riesgo Verdadero en la Práctica 4. La Brecha de Generalización: El Objeto de Estudio Central a. Definición Formal i. Definición 5 (Brecha de Generalización): b. Cotas Teóricas Clásicas i. Teorema 2 (Cota basada en Dimensión VC - Vapnik-Chervonenkis) ii. Teorema 3 (Cota basada en Complejidad de Rademacher) c. La Brecha en el Régimen Sobreparametrizado Vapnik, Vladimir. The nature of statistical learning theory. Springer science & business media, 2013. Bartlett, Peter L., and Shahar Mendelson. "Rademacher and gaussian complexities: Risk bounds and structural results." Journal of machine learning research 3.Nov (2002): 463-482. Zhang, C., et al. "Understanding deep learning requires rethinking generalization. arXiv." arXiv preprint arXiv:1611.03530 26 (2017). Belkin, Mikhail, et al. "Reconciling modern machine-learning practice and the classical bias–variance trade-off." Proceedings of the National Academy of Sciences 116.32 (2019): 15849-15854.
arquitectos. La física clásica les dice que el edificio que diseñaron debería colapsar: tiene demasiadas ventanas, muy pocos pilares de soporte, y materiales que exceden los límites teóricos de estabilidad. Sin embargo, cuando lo construyen, no solo se mantiene en pie, sino que resiste terremotos mejor que edificios convencionales. ¿Qué harían? O bien: 1. Descartan los cálculos como irrelevantes, o 2. Sospechan que hay principios físicos no descubiertos operando en su diseño En Deep Learning, vivimos la segunda opción.
del algoritmo de optimización (por ejemplo, descenso de gradiente estocástico) inducen un sesgo implícito (implicit bias) que selecciona, entre el conjunto de minimizadores globales, aquellas soluciones con buena capacidad de generalización? ¿Qué mecanismo induce una regularización implícita que restringe efectivamente el espacio de hipótesis, favoreciendo soluciones de baja complejidad (en algún sentido funcional o geométrico), a pesar de la ausencia de regularización explícita? Dado que múltiples hipótesis interpolan perfectamente los datos, ¿por qué el algoritmo de optimización (e.g., SGD) selecciona soluciones cuya complejidad efectiva —medida en términos de normas funcionales, márgenes o subconjuntos efectivos induce cotas no vacuas de generalización (por ejemplo, a través de una baja complejidad de Rademacher efectiva)?
qué funciona el DL les permite: • Diseñar arquitecturas con principios, no por prueba y error • Identificar cuándo el DL fallará (límites teóricos) • Contribuir a la teoría que aún está en construcción Si son Practicantes Entender por qué funciona el DL les permite: • Diagnosticar problemas de generalización rigurosamente • Justificar decisiones de diseño ante stakeholders • Evitar seguir recetas ciegamente cuando el contexto cambia Si son Educadores Entender por qué funciona el DL les permite: • Enseñar fundamentos, no solo herramientas • Preparar estudiantes para un campo en evolución rápida • Fomentar pensamiento crítico sobre afirmaciones de "state-of-the-art"
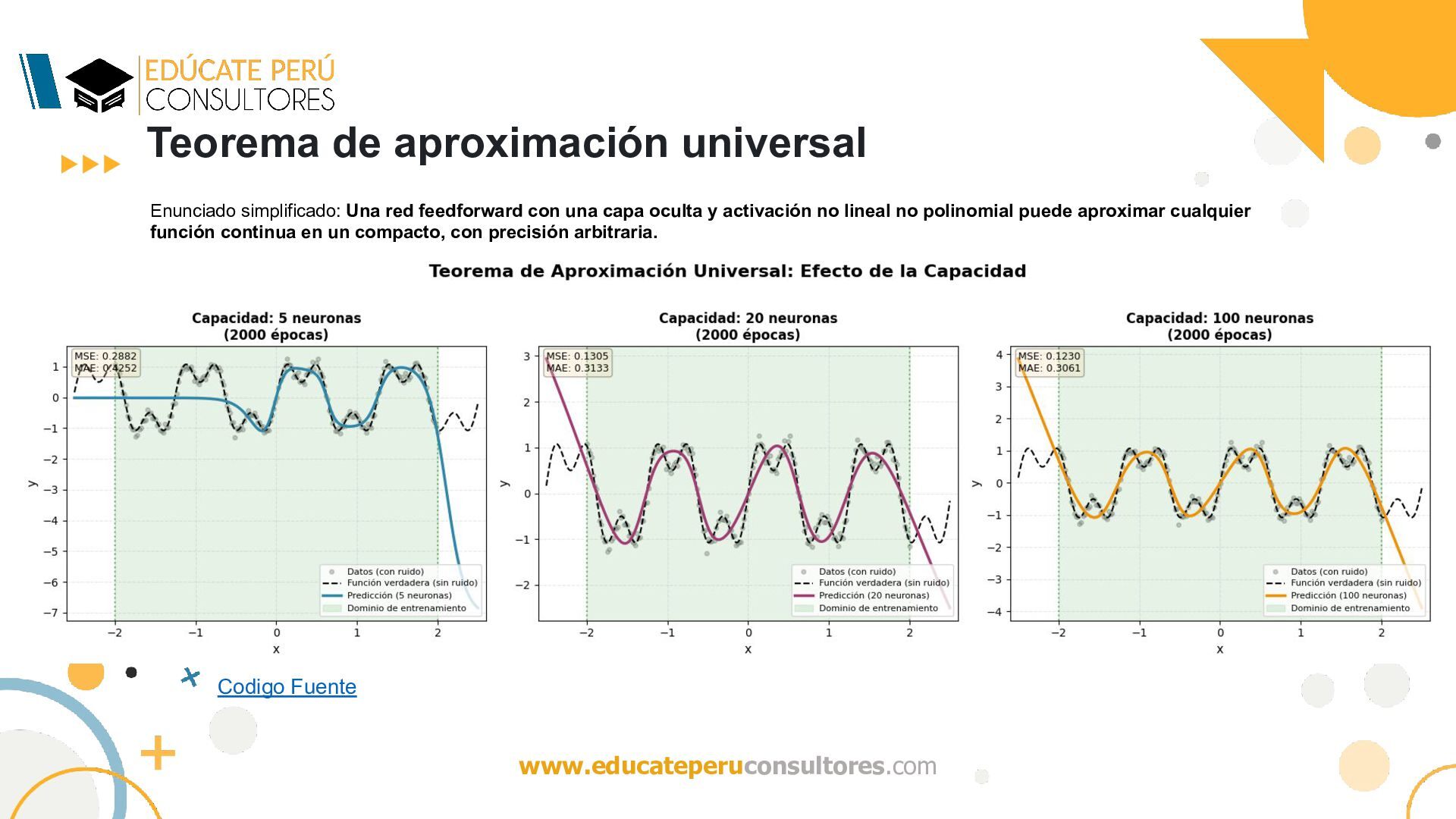
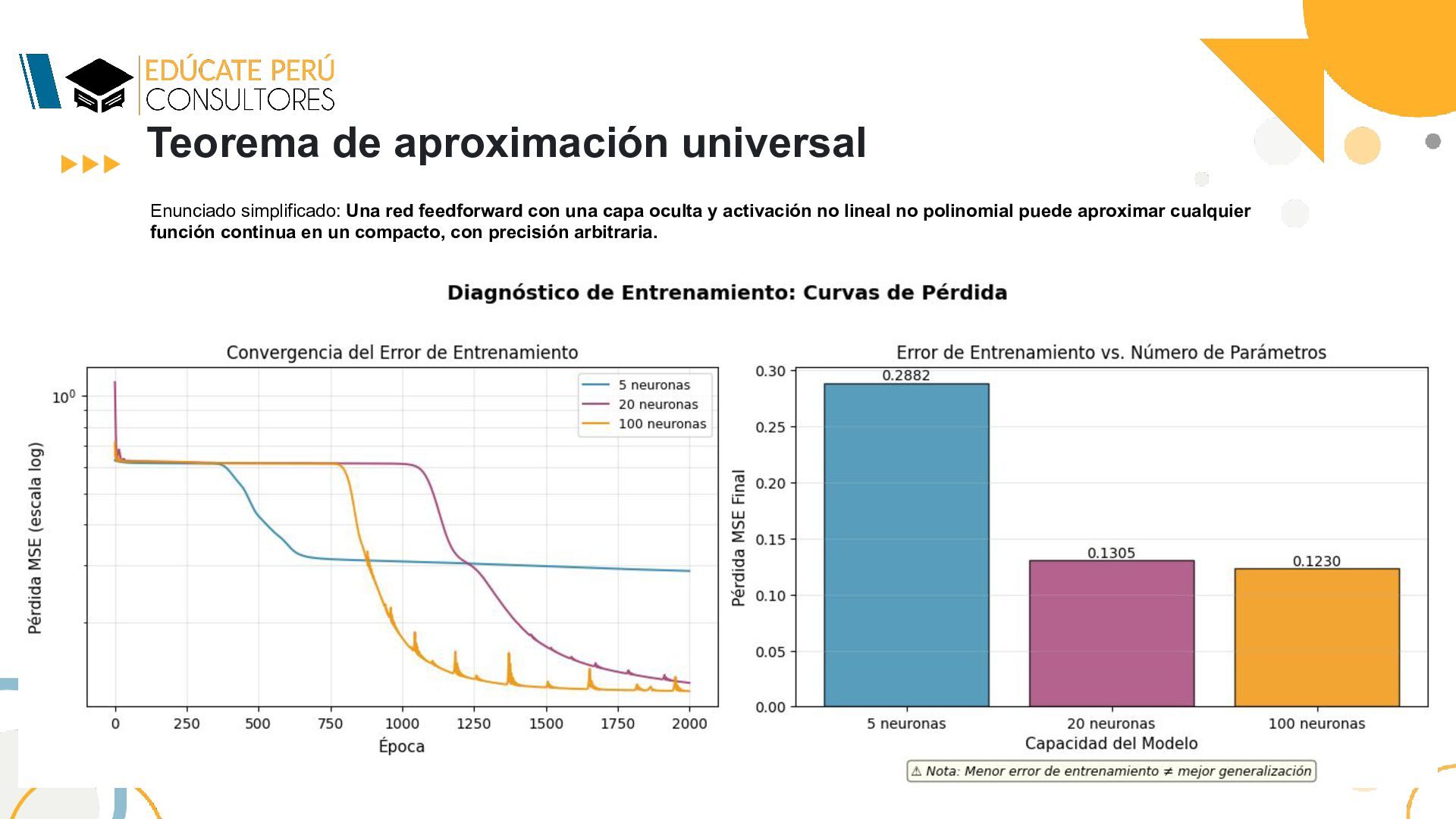
de Cybenko (1989) constituye uno de los resultados fundacionales de la teoría de redes neuronales artificiales. Este teorema establece rigurosamente que una red neuronal feedforward con una sola capa oculta, un número finito de neuronas y una función de activación sigmoidea no polinomial puede aproximar cualquier función continua definida sobre un subconjunto compacto de Rn , con precisión arbitraria en la norma del supremo. El teorema no garantiza que la aproximación sea eficiente en términos de número de neuronas, ni que los parámetros puedan ser encontrados mediante algoritmos de optimización prácticos. Sin embargo, proporciona el fundamento teórico que justifica el uso de redes neuronales como aproximadores universales de funciones, estableciendo las bases matemáticas para el desarrollo posterior del aprendizaje profundo. Enunciado simplificado: Una red feedforward con una capa oculta y activación no lineal no polinomial puede aproximar cualquier función continua en un compacto, con precisión arbitraria. Codigo Fuente
con una capa oculta y activación no lineal no polinomial puede aproximar cualquier función continua en un compacto, con precisión arbitraria. Codigo Fuente
práctica Existencia ≠ constructividad El teorema no dice cómo encontrar los pesos óptimos Número de neuronas puede crecer exponencialmente En alta dimensión, la aproximación requiere recursos prohibitivos No considera ruido ni muestreo finito La generalización depende de propiedades estadísticas de los datos Ignora la optimización SGD puede converger a mínimos locales o planos
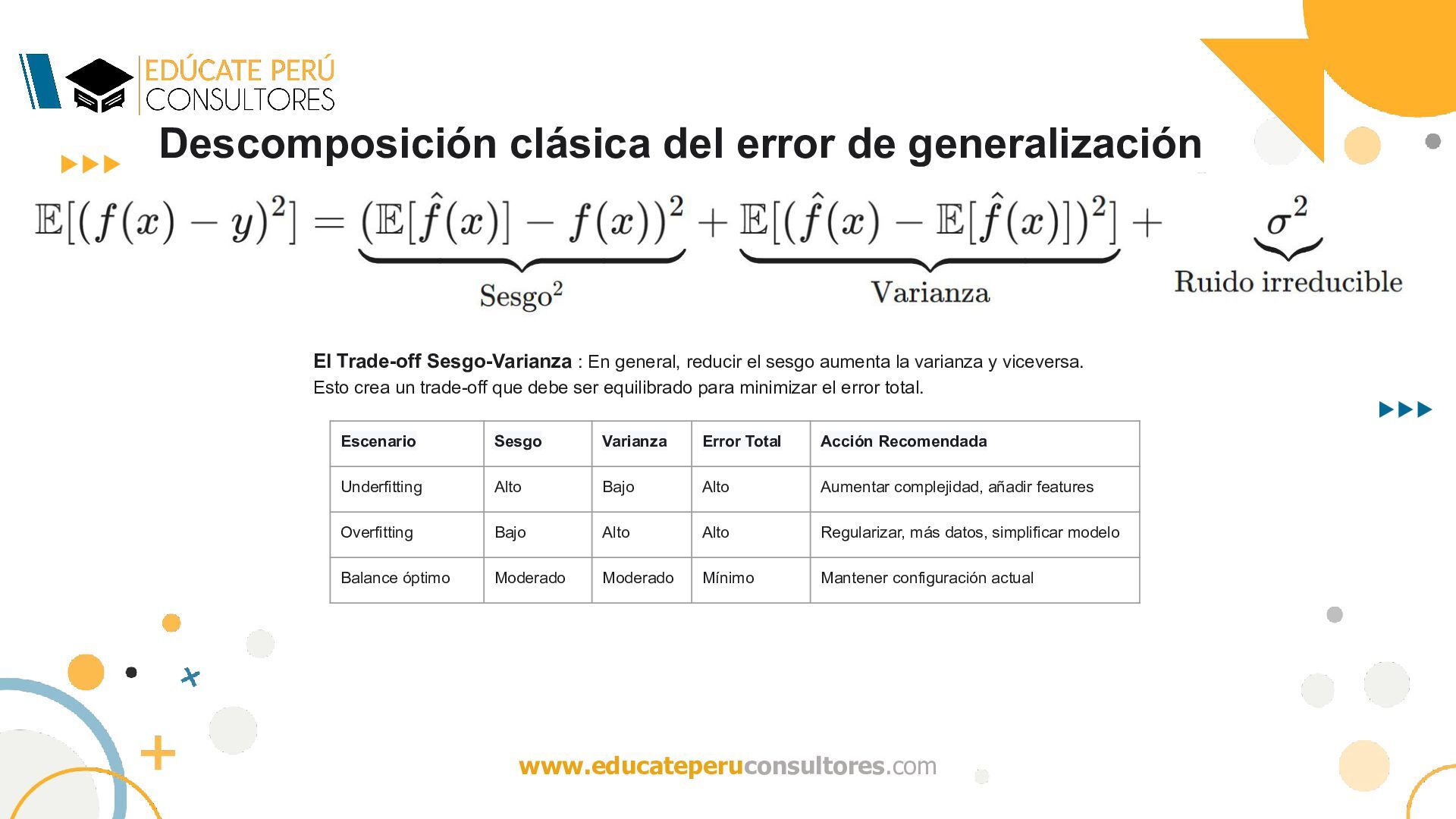
del error de generalización constituye uno de los resultados fundamentales de la teoría de aprendizaje estadístico. Este teorema establece que el error cuadrático esperado de un predictor puede descomponerse aditivamente en tres componentes conceptualmente distintos:
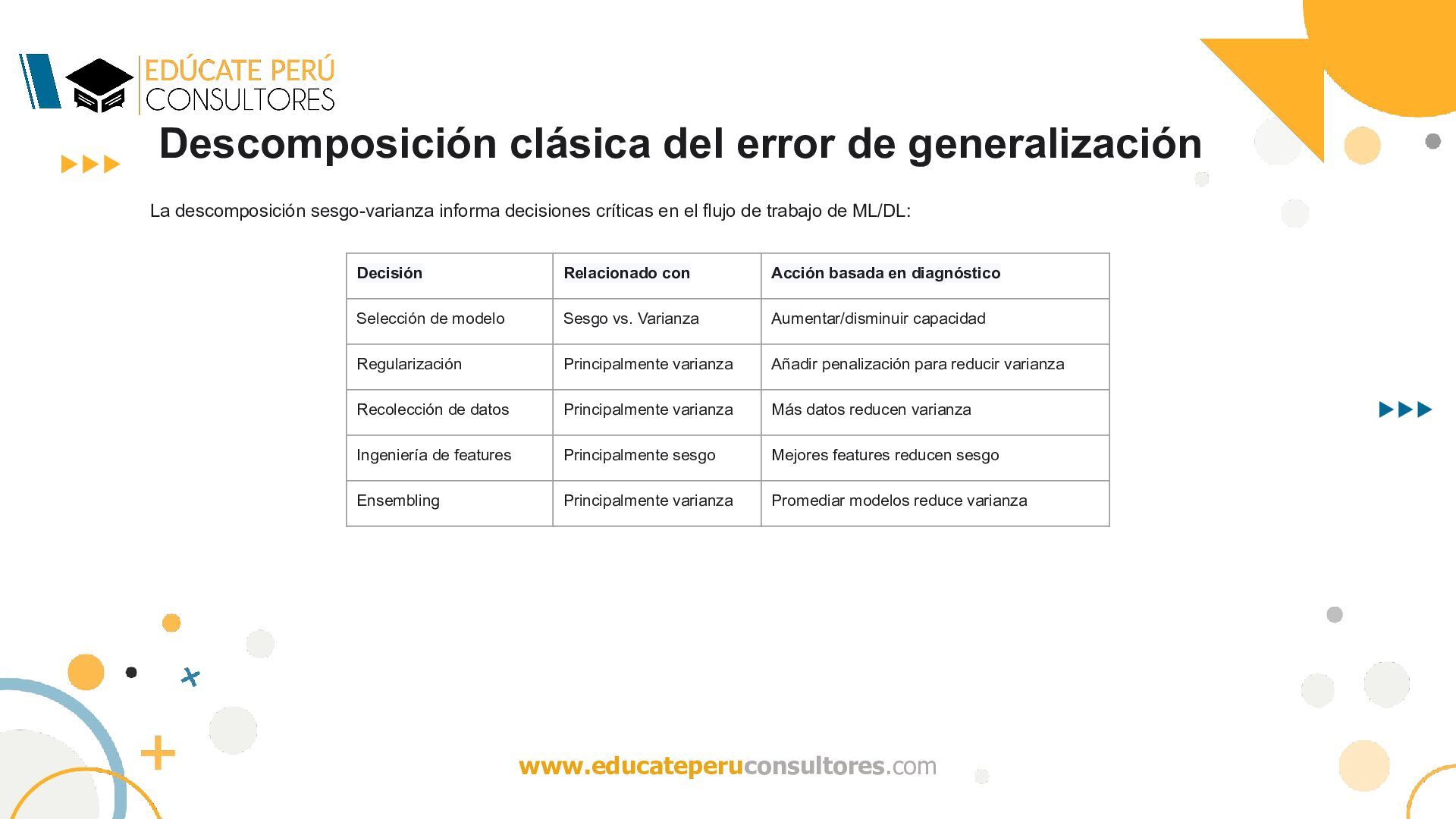
informa decisiones críticas en el flujo de trabajo de ML/DL: Decisión Relacionado con Acción basada en diagnóstico Selección de modelo Sesgo vs. Varianza Aumentar/disminuir capacidad Regularización Principalmente varianza Añadir penalización para reducir varianza Recolección de datos Principalmente varianza Más datos reducen varianza Ingeniería de features Principalmente sesgo Mejores features reducen sesgo Ensembling Principalmente varianza Promediar modelos reduce varianza
la Descomposición Estrategia de Demostración La demostración sigue estos pasos: 1. Expandir el error cuadrático 2. Añadir y restar términos estratégicos 3. Aplicar propiedades de expectativa 4. Agrupar términos para identificar sesgo, varianza y ruido
Cada Componente Sesgo (Bias) Interpretación: • Mide cuánto se desvía sistemáticamente el predictor promedio (sobre todos los posibles conjuntos de entrenamiento) de la función verdadera • Sesgo alto indica que el modelo es demasiado simple para capturar la estructura de los datos • Es un error determinístico que no se reduce con más datos
Cada Componente Varianza Interpretación: • Mide cuánto varía el predictor cuando se entrena con diferentes conjuntos de datos • Varianza alta indica que el modelo es demasiado sensible a fluctuaciones aleatorias en los datos de entrenamiento • Se reduce con más datos de entrenamiento
Cada Componente Ruido Irreducible Interpretación: • Representa la variabilidad en y que no puede ser explicada por x • Es un límite inferior fundamental: ningún modelo puede tener error menor que σ2 • No se reduce con mejores modelos ni más datos
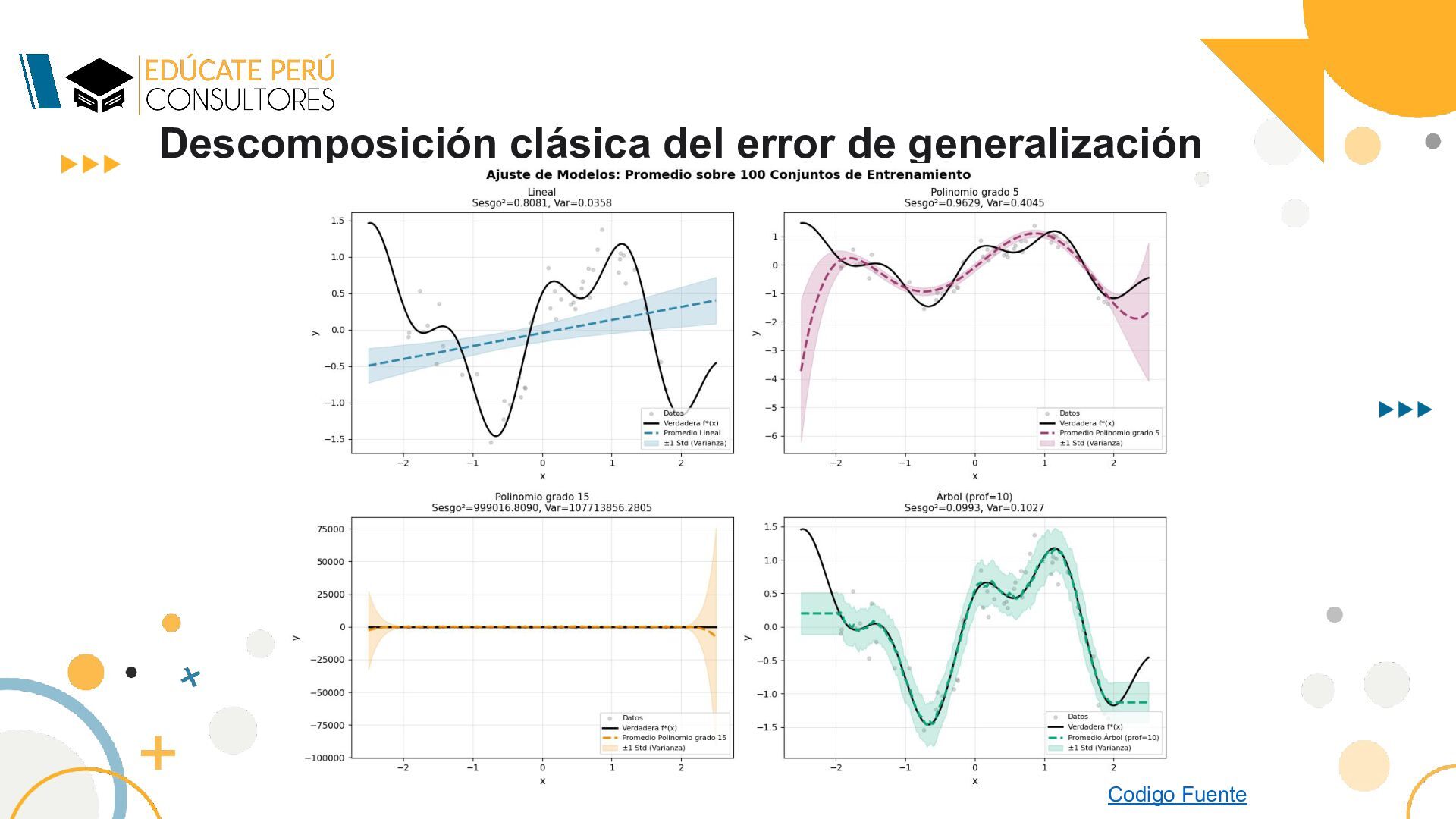
: En general, reducir el sesgo aumenta la varianza y viceversa. Esto crea un trade-off que debe ser equilibrado para minimizar el error total. Escenario Sesgo Varianza Error Total Acción Recomendada Underfitting Alto Bajo Alto Aumentar complejidad, añadir features Overfitting Bajo Alto Alto Regularizar, más datos, simplificar modelo Balance óptimo Moderado Moderado Mínimo Mantener configuración actual
et al. (2012) como una técnica heurística de regularización para redes neuronales, fue rigorosamente fundamentado teóricamente por Gal & Ghahramani (2016) como una aproximación variacional a la inferencia Bayesiana en redes neuronales profundas. Este informe técnico establece que: 1. Dropout durante el entrenamiento es equivalente a entrenar un ensemble de 2N sub-redes (donde N es el número de unidades con dropout), cada una con una configuración diferente de neuronas activas. 2. Dropout durante la inferencia (con escalado apropiado) aproxima la media predictiva posterior de un proceso Gaussiano profundo, proporcionando no solo predicciones puntuales sino también estimaciones de incertidumbre. 3. Desde la perspectiva de descomposición de error, dropout incrementa ligeramente el sesgo pero reduce significativamente la varianza, resultando en una mejora neta del error de generalización.
Szegedy (2015), representa uno de los avances más significativos en el entrenamiento de redes neuronales profundas. Originalmente propuesto para mitigar el Internal Covariate Shift (cambio en la distribución de activaciones entre capas durante el entrenamiento), análisis posteriores han revelado que sus beneficios principales provienen de: 1. Estabilización del paisaje de optimización: BN suaviza la función de pérdida, permitiendo tasas de aprendizaje más altas y reduciendo la sensibilidad a la inicialización de parámetros. 2. Regularización implícita mediante ruido de mini-batch: La estimación de estadísticas (media y varianza) sobre mini-batches introduce ruido estocástico que actúa como regularizador, similar a Dropout. 3. Normalización de momentos de primer y segundo orden: Por cada mini-batch, BN estandariza las activaciones a media cero y varianza unitaria, mejorando el flujo de gradientes durante backpropagation.
temprana) representa una de las técnicas de regularización implícita más efectivas y computacionalmente eficientes en el entrenamiento de redes neuronales profundas. Originalmente propuesto como una heurística práctica para prevenir sobreajuste, análisis teóricos posteriores han establecido que: 1. Early stopping es equivalente a validación cruzada secuencial: Cada época de entrenamiento representa un modelo de complejidad creciente, y la parada en el punto óptimo selecciona el modelo con mejor compromiso sesgo-varianza. 2. Regularización implícita mediante control de complejidad efectiva: Detener el entrenamiento antes de la convergencia completa limita la capacidad efectiva del modelo, similar a regularización L2 pero sin modificar la función de pérdida. 3. Eficiencia computacional superior: A diferencia de k-fold cross-validation que requiere entrenar k modelos, early stopping obtiene beneficios similares con un solo entrenamiento monitoreado.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}