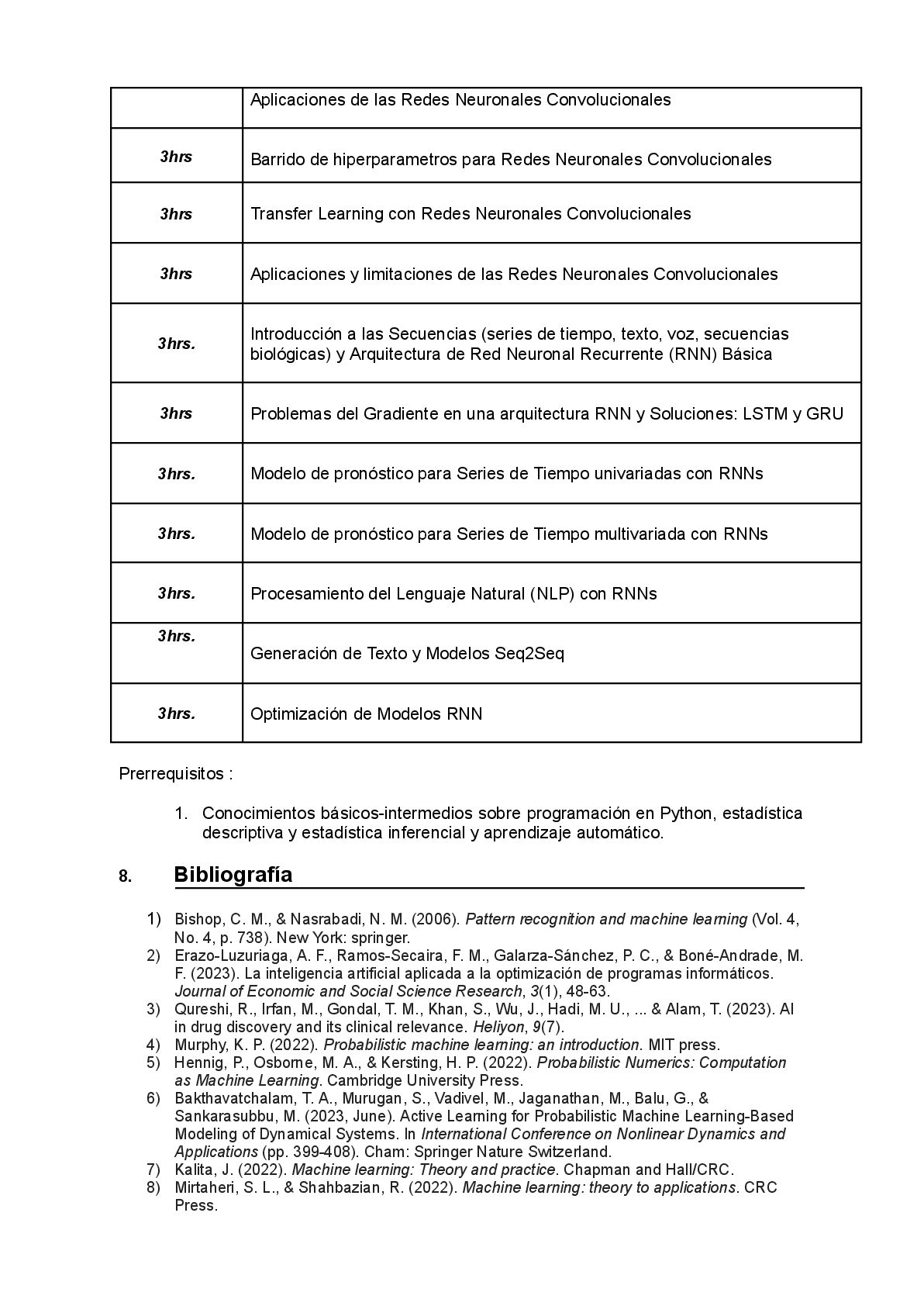
para Redes Neuronales Convolucionales 3hrs Transfer Learning con Redes Neuronales Convolucionales 3hrs Aplicaciones y limitaciones de las Redes Neuronales Convolucionales 3hrs. Introducción a las Secuencias (series de tiempo, texto, voz, secuencias biológicas) y Arquitectura de Red Neuronal Recurrente (RNN) Básica 3hrs Problemas del Gradiente en una arquitectura RNN y Soluciones: LSTM y GRU 3hrs. Modelo de pronóstico para Series de Tiempo univariadas con RNNs 3hrs. Modelo de pronóstico para Series de Tiempo multivariada con RNNs 3hrs. Procesamiento del Lenguaje Natural (NLP) con RNNs 3hrs. Generación de Texto y Modelos Seq2Seq 3hrs. Optimización de Modelos RNN Prerrequisitos : 1. Conocimientos básicos-intermedios sobre programación en Python, estadística descriptiva y estadística inferencial y aprendizaje automático. 8. Bibliografía 1) Bishop, C. M., & Nasrabadi, N. M. (2006). Pattern recognition and machine learning (Vol. 4, No. 4, p. 738). New York: springer. 2) Erazo-Luzuriaga, A. F., Ramos-Secaira, F. M., Galarza-Sánchez, P. C., & Boné-Andrade, M. F. (2023). La inteligencia artificial aplicada a la optimización de programas informáticos. Journal of Economic and Social Science Research, 3(1), 48-63. 3) Qureshi, R., Irfan, M., Gondal, T. M., Khan, S., Wu, J., Hadi, M. U., ... & Alam, T. (2023). AI in drug discovery and its clinical relevance. Heliyon, 9(7). 4) Murphy, K. P. (2022). Probabilistic machine learning: an introduction. MIT press. 5) Hennig, P., Osborne, M. A., & Kersting, H. P. (2022). Probabilistic Numerics: Computation as Machine Learning. Cambridge University Press. 6) Bakthavatchalam, T. A., Murugan, S., Vadivel, M., Jaganathan, M., Balu, G., & Sankarasubbu, M. (2023, June). Active Learning for Probabilistic Machine Learning-Based Modeling of Dynamical Systems. In International Conference on Nonlinear Dynamics and Applications (pp. 399-408). Cham: Springer Nature Switzerland. 7) Kalita, J. (2022). Machine learning: Theory and practice. Chapman and Hall/CRC. 8) Mirtaheri, S. L., & Shahbazian, R. (2022). Machine learning: theory to applications. CRC Press.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}