image.. - f is some scalar quantity of interest. - Obtained numerically through the solution of a set of PDEs. - Inputs x – uncertain and high dimensional. - Interested in quantifying the uncertainty in f. 3
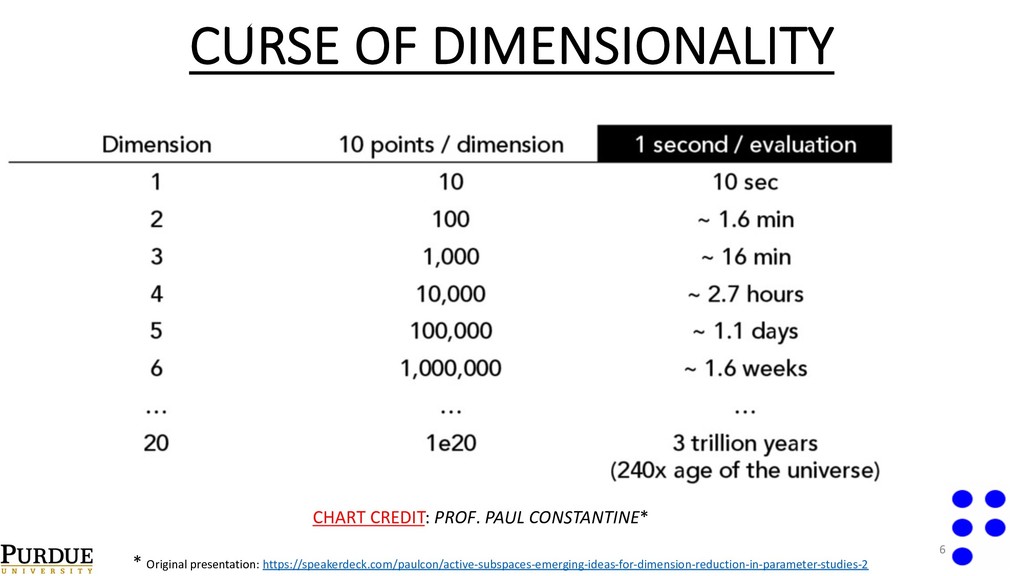
Carlo, although independent in the dimensionality, converges very slowly in the number of samples of f. • Idea -> Replace the simulator of f with a surrogate model. • Problem -> Curse of dimensionality. 5
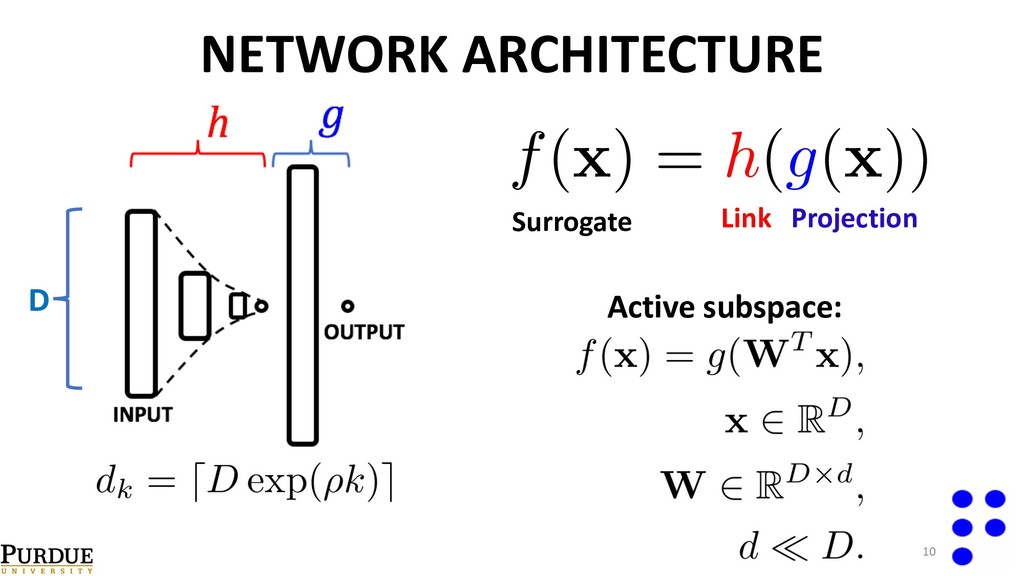
as Linear Principal Component analysis)[1]. • Kernel PCA[4]. (Non-linear model reduction). • Active Subspaces (with gradient information[2] or without gradient information[3]). References: [1]- Ghanem and Spanos. Stochastic finite elements: a spectral approach (2003). [2]- Constantine et. al. Active subspace methods in theory and practice: applications to kriging surfaces. (2014). [3]-Tripathy et. al. Gaussian processes with built-in dimensionality reduction: Applications to high-dimensional uncertainty propagation. (2016). [4]-Ma and Zabaras. Kernel principal component analysis for stochastic input model generation. (2011). 7
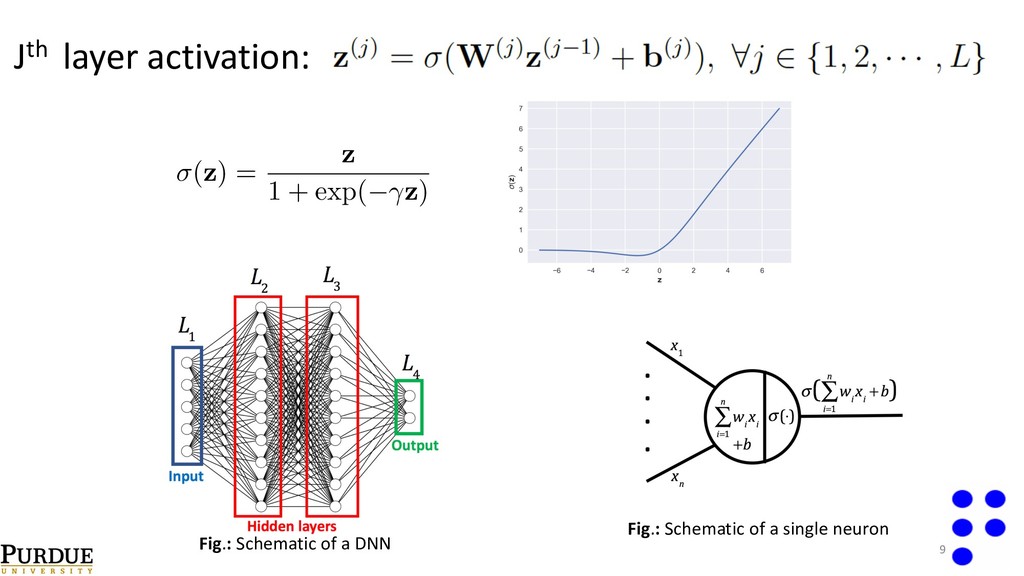
of information[2]. o Linear regression can be thought of as a special case of DNNs (no hidden layers). o Tremendous success in recent times in applications such as image classification[2], autonomous driving[3]. o Availability of libraries such as tensorflow, keras, theano, PyTorch, caffe etc. References: [1]-Hornik . Approximation capabilities of multilayer feedforward networks. (1991). [2]-Krishevsky et al. Imagenet classification with deep convolutional neural networks. (2012). [3]-Chen et. al. Deepdriving: Learning affordance for direct perception in autonomous driving. (2015). 8
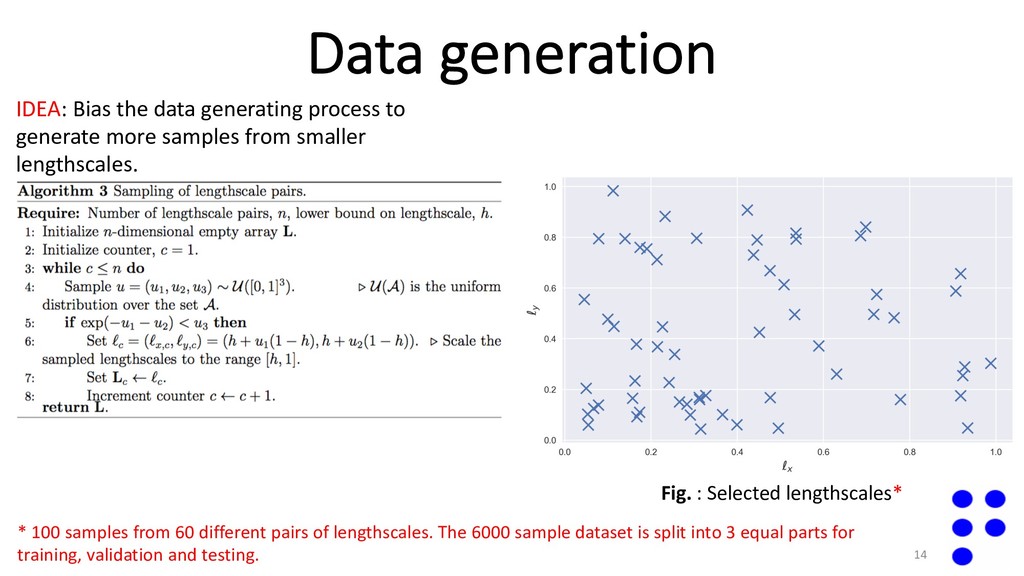
more samples from smaller lengthscales. 14 Fig. : Selected lengthscales* * 100 samples from 60 different pairs of lengthscales. The 6000 sample dataset is split into 3 equal parts for training, validation and testing.
predicted solution for Arbitrarily chosen lengthscales. Fig. : R2 score of predicted solution for Arbitrarily chosen lengthscales. • Blue dot – Lengthscales not represented in the training set. • Black x – Lengthscales represented in the training set. OBSERVATION: Higher relative error and lower R2 score for inputs with smaller lengthscales.
{kind=link}
![INTRODUCTION Image sources: [1] - Left image. [2] - Right](https://files.speakerdeck.com/presentations/99f3293e796f40df89f3a73c5261c63d/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DEEP NEURAL NETWORKS o Universal function approximators[1]. o Layered representation](https://files.speakerdeck.com/presentations/99f3293e796f40df89f3a73c5261c63d/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
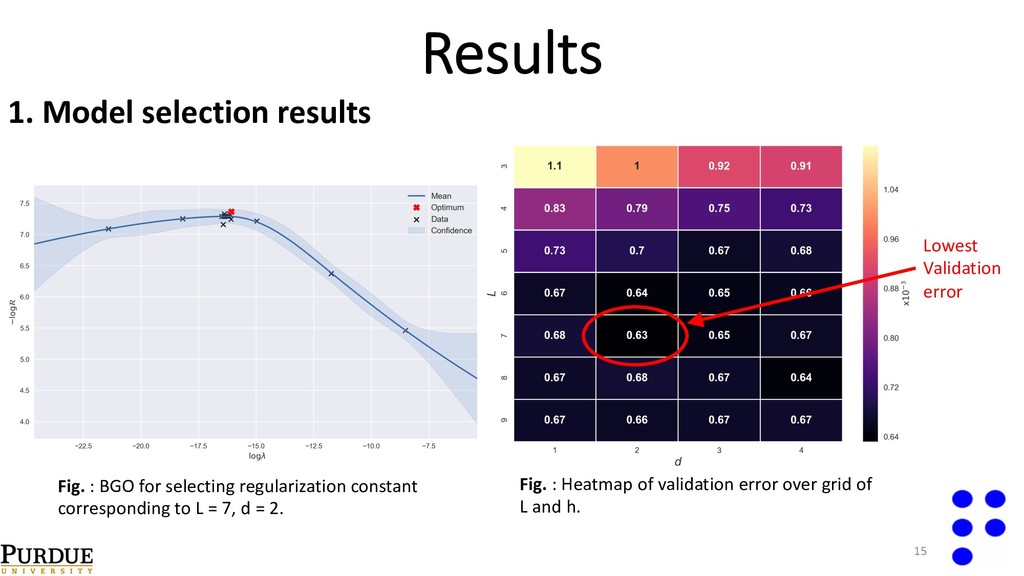{kind=link}
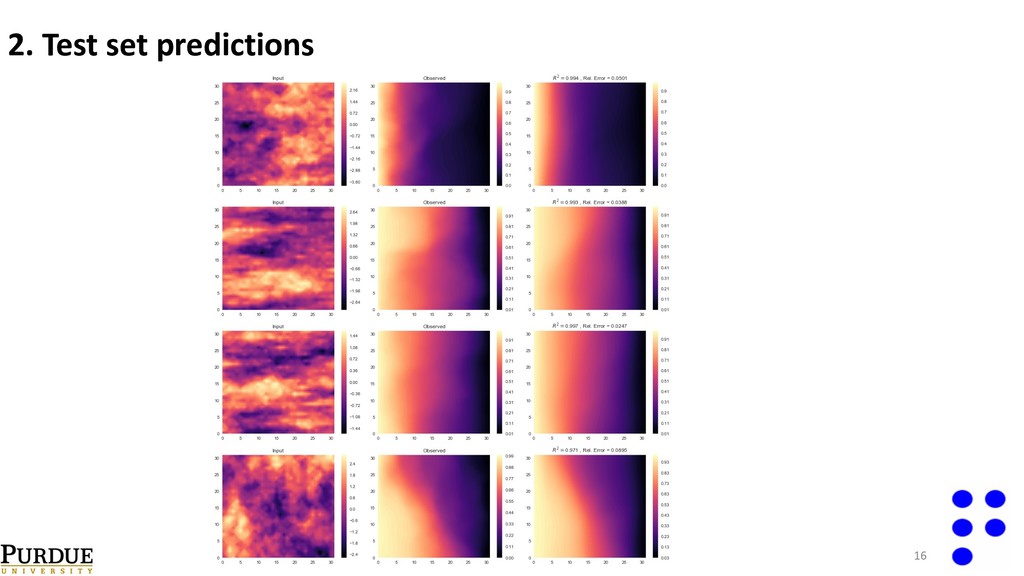{kind=link}
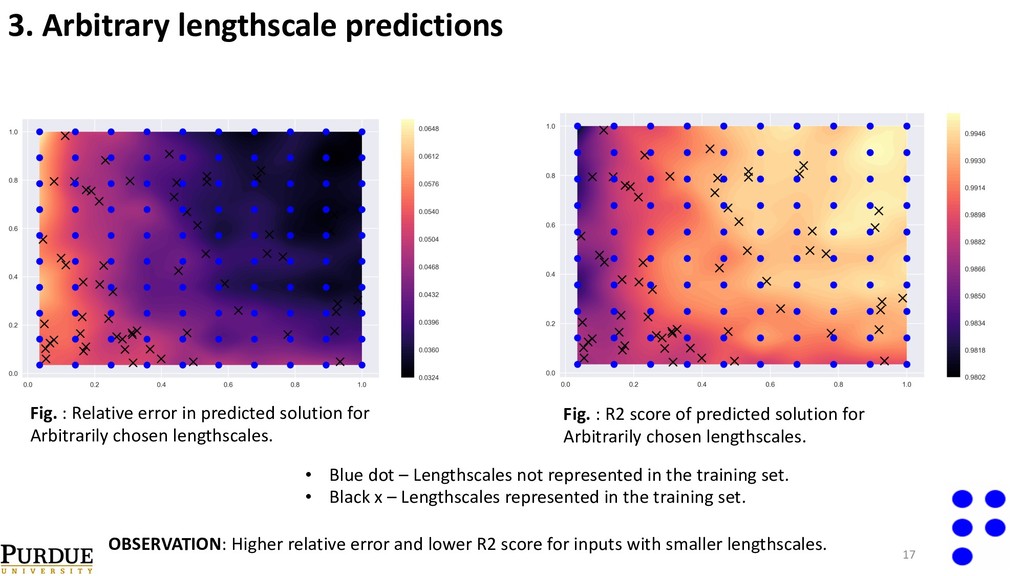{kind=link}
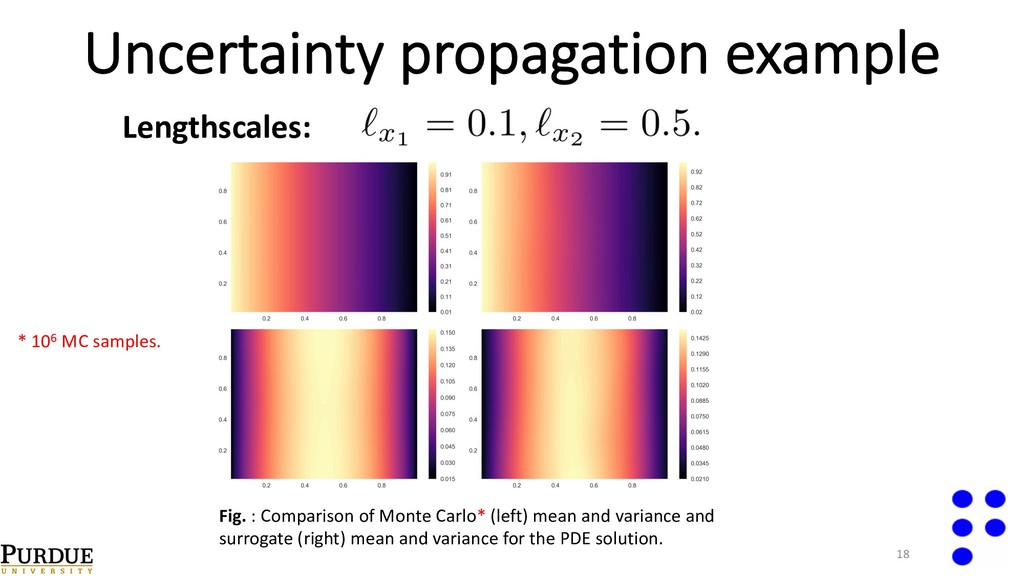{kind=link}
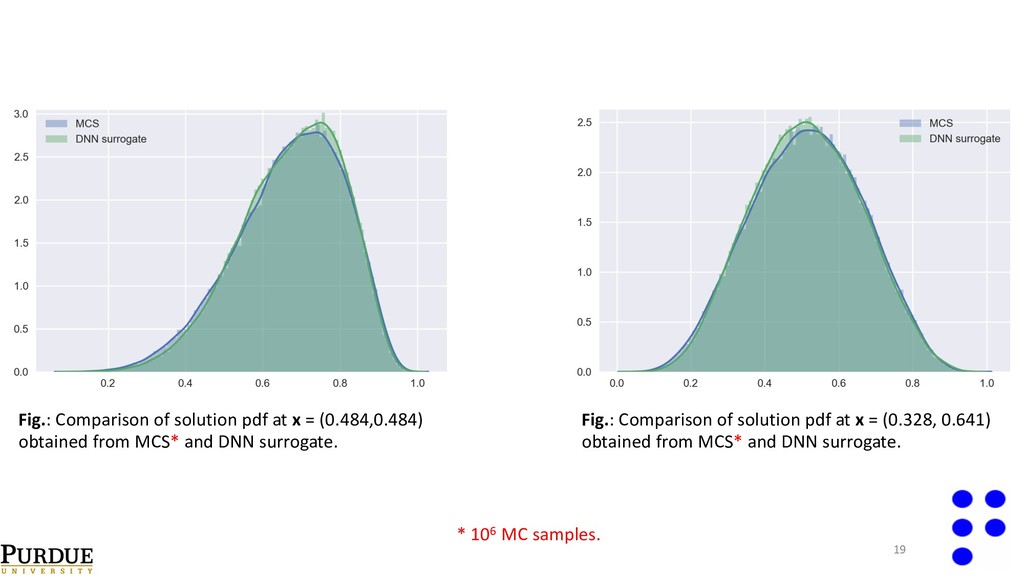{kind=link}
{kind=link}
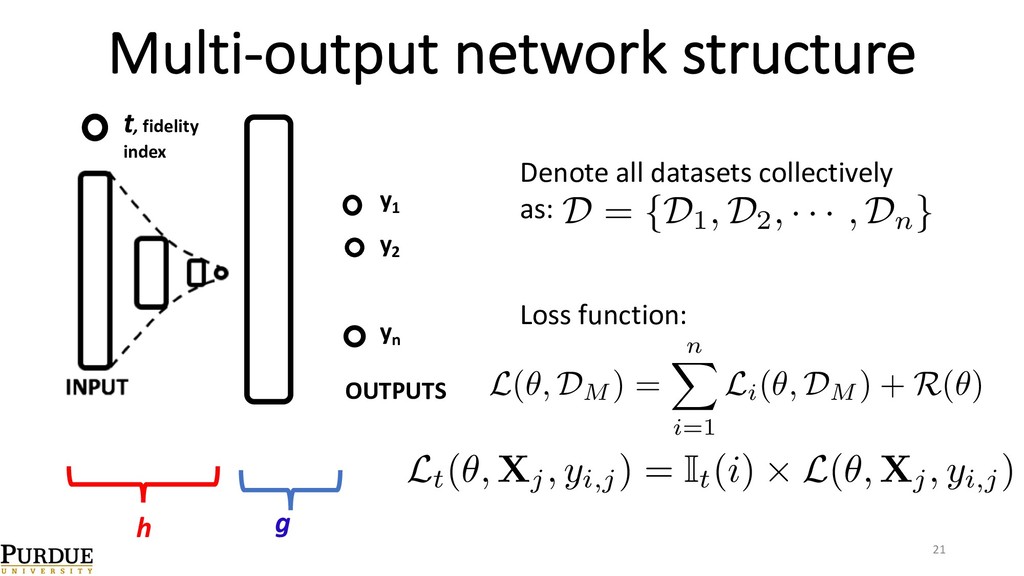{kind=link}
{kind=link}
{kind=link}
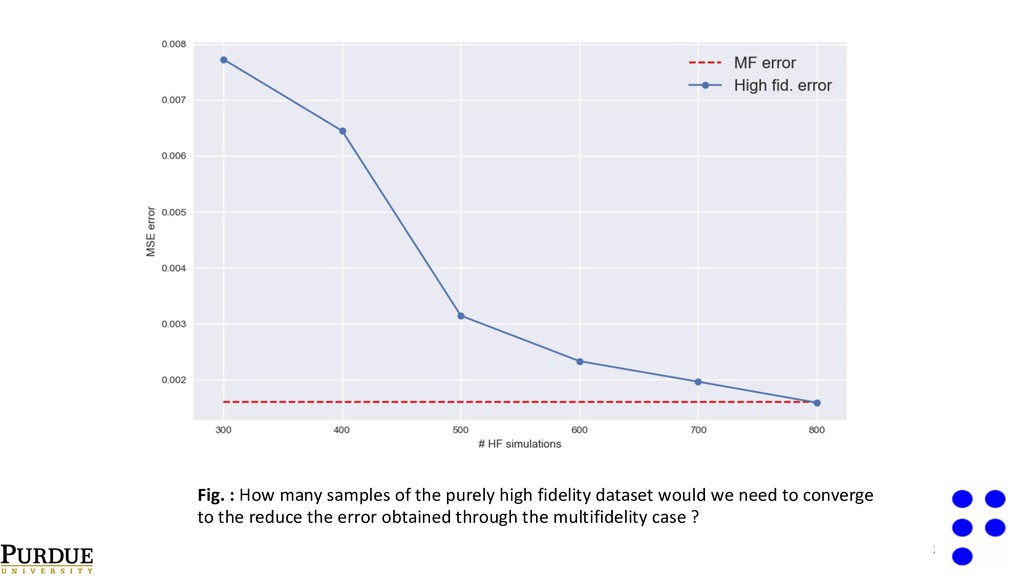{kind=link}
{kind=link}