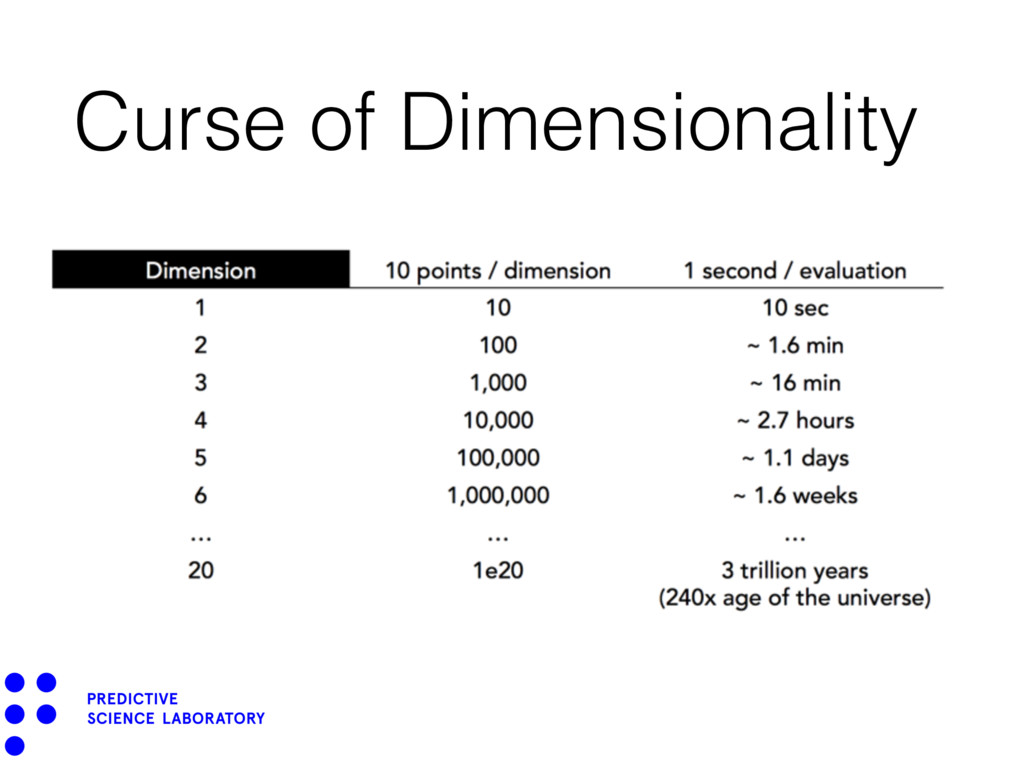
rate independent of number of dimensions. • Realistic problems require tens of thousands of simulations. • “Monte Carlo is fundamentally unsound” - O’ Hagen (1987). 6
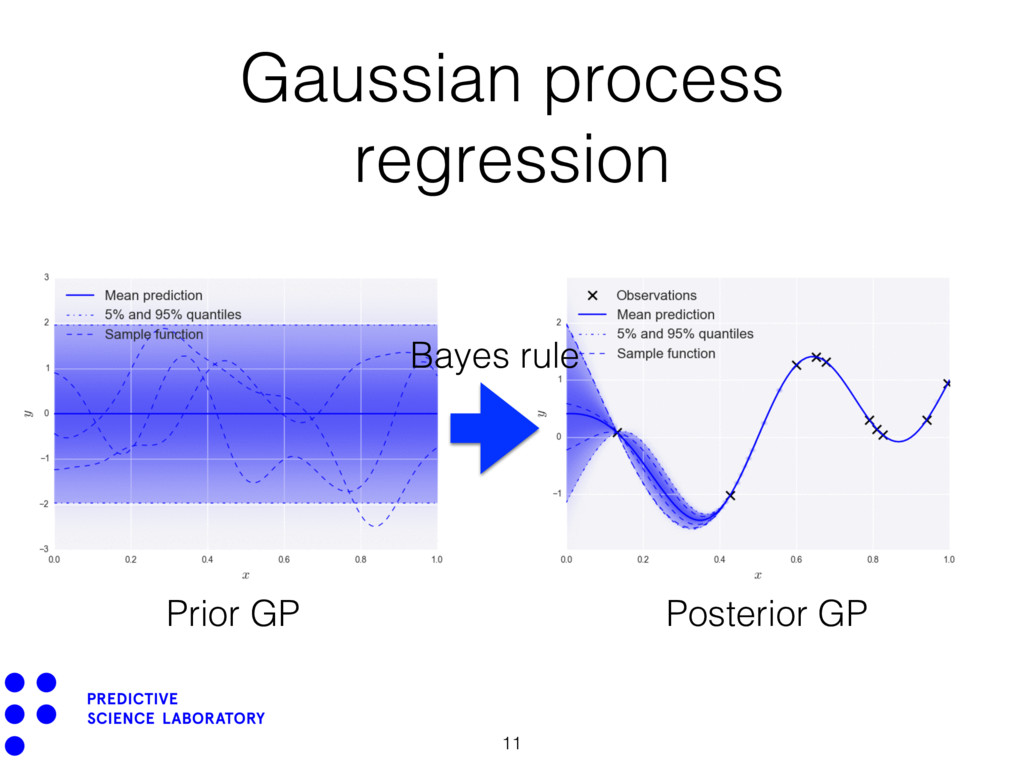
is high-dimensional (> 20). • We cannot compute derivatives of the response. • The response may be noisy. “How do you build a surrogate under these conditions?”
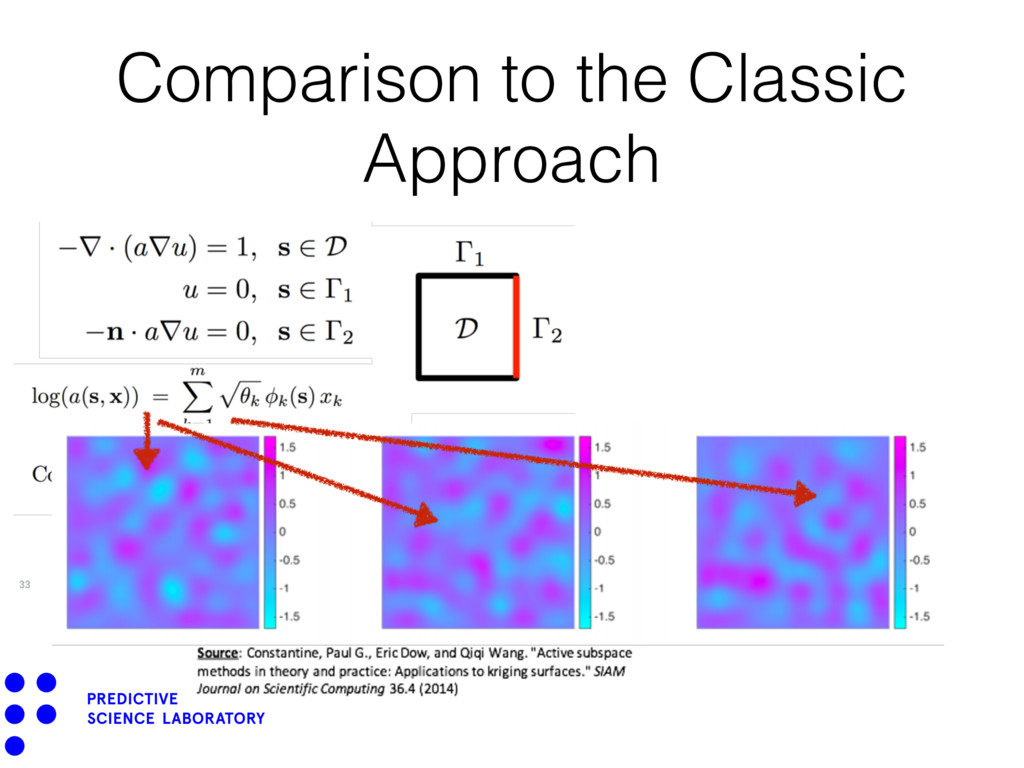
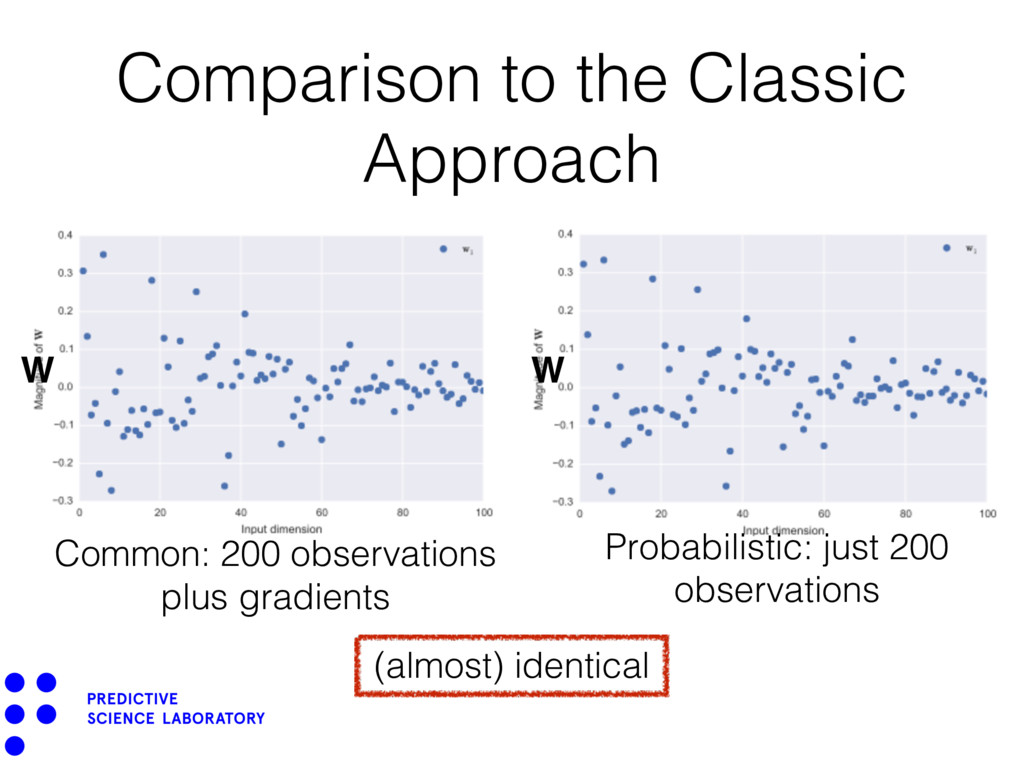
architecture - infinite mixture of AS-GP models. • Deep architecture - deep GPs with AS-GP components. • Epistemic uncertainty on W (MCMC on Stiefel manifold (Giro
{kind=link}
![The Team 2 Rohit Tripathy [email protected] PhD student Marcial Gonzalez](https://files.speakerdeck.com/presentations/e535135e56354a0b8a3218d5ae4e861f/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
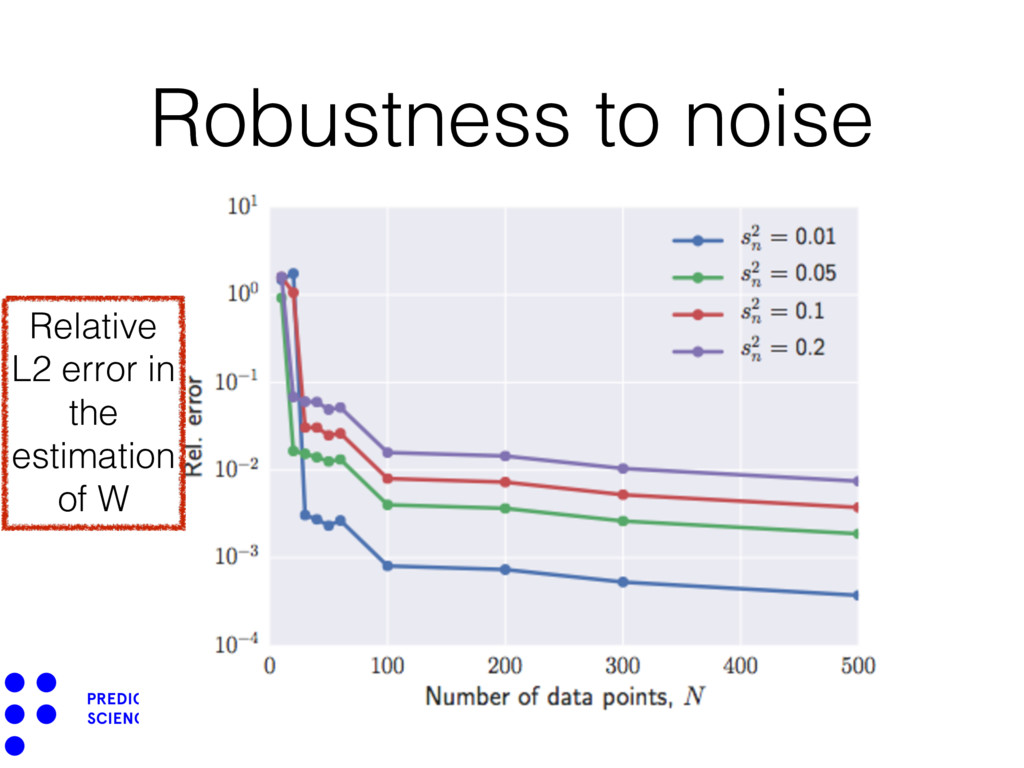{kind=link}
{kind=link}
{kind=link}
{kind=link}
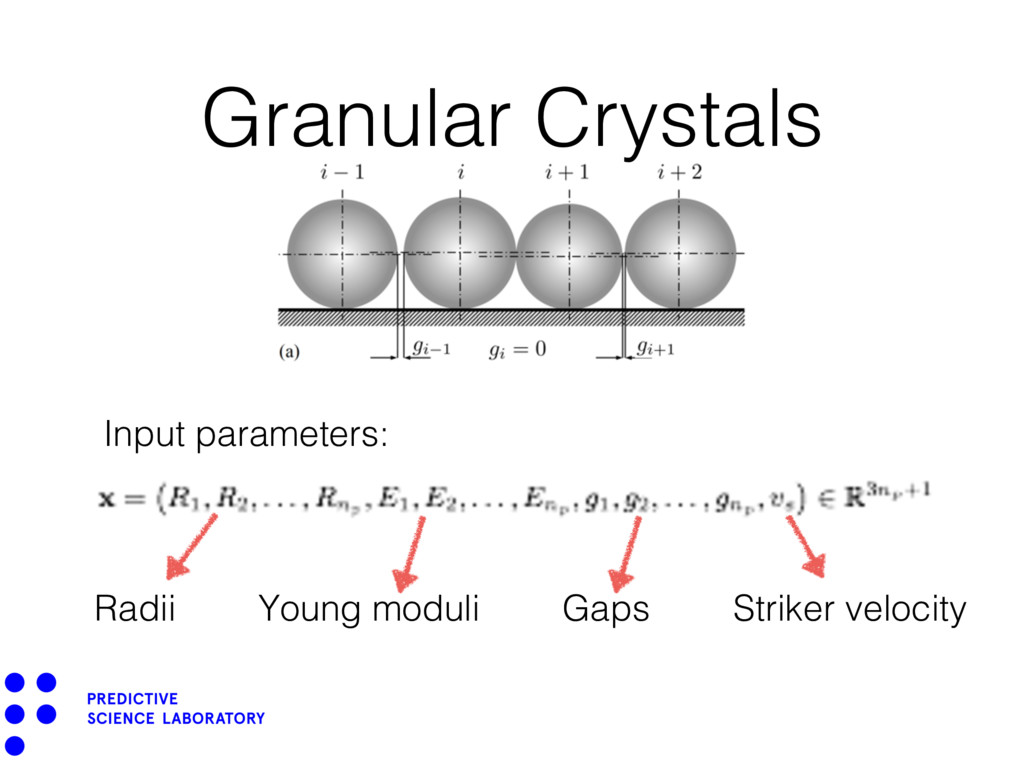{kind=link}
{kind=link}
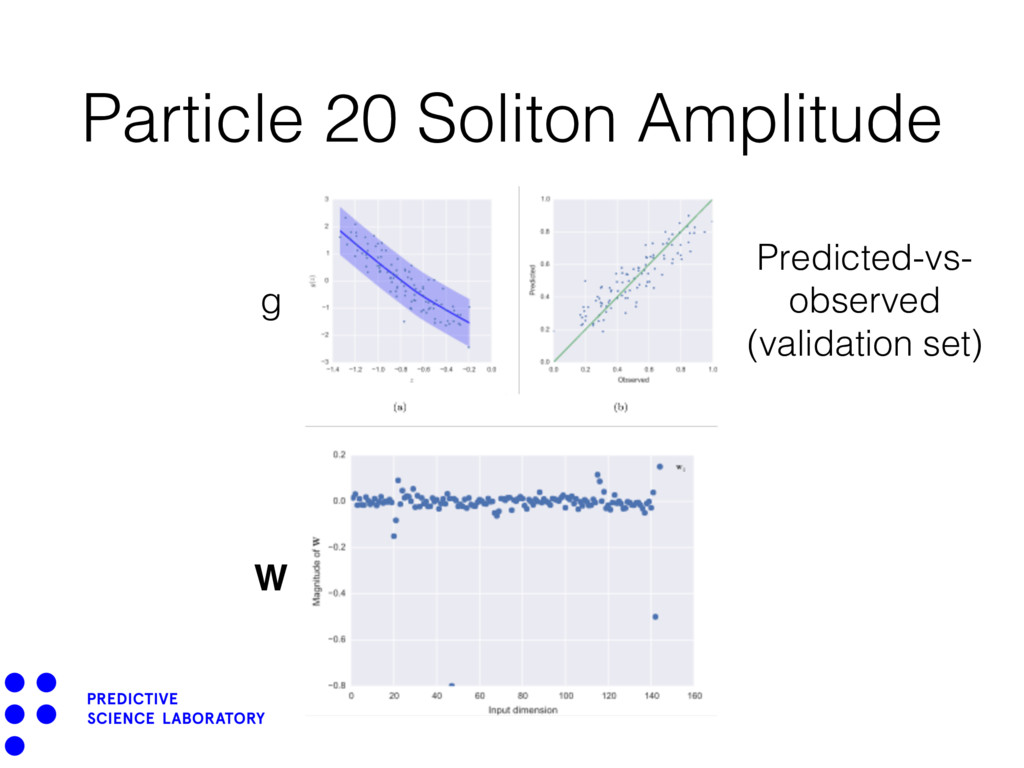{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}