approach Rohit Tripathy PhD candidate, Predictive Science Lab Purdue University, West Lafayette, IN https://rohittripathy.netlify.com/ (Advised by Prof. Ilias Bilionis)
• Propagating uncertainties in the inputs. • Optimizing the output of scientific/engineering processes characterized by uncertain parameters. INTRODUCTION WHAT IS UQ?
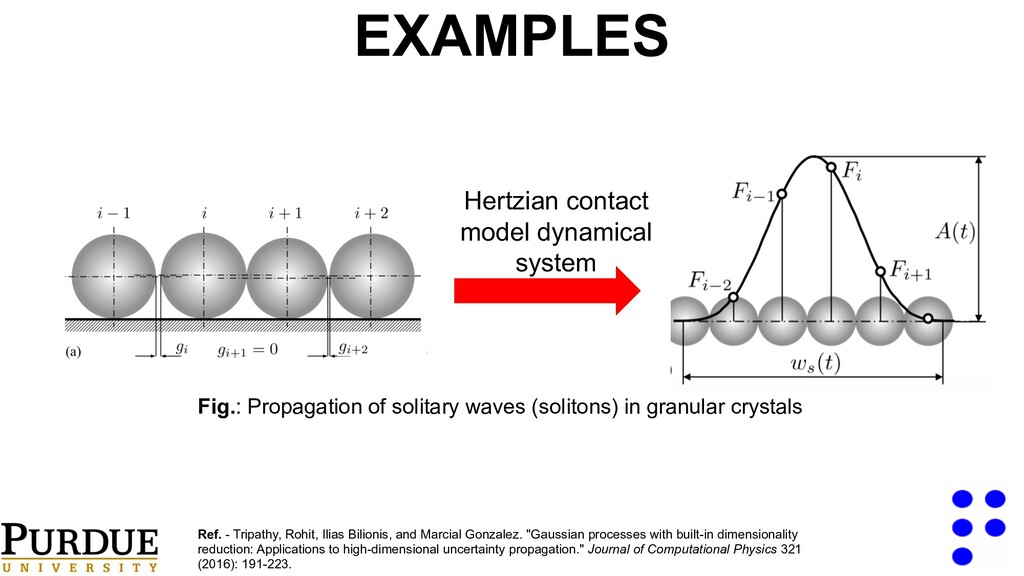
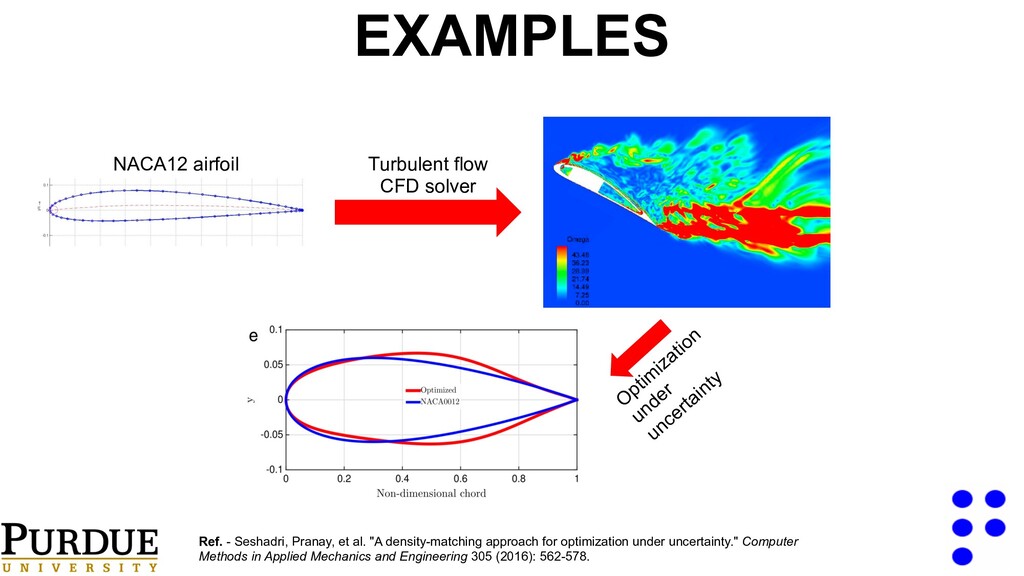
uncertainty Ref. - Seshadri, Pranay, et al. "A density-matching approach for optimization under uncertainty." Computer Methods in Applied Mechanics and Engineering 305 (2016): 562-578. EXAMPLES
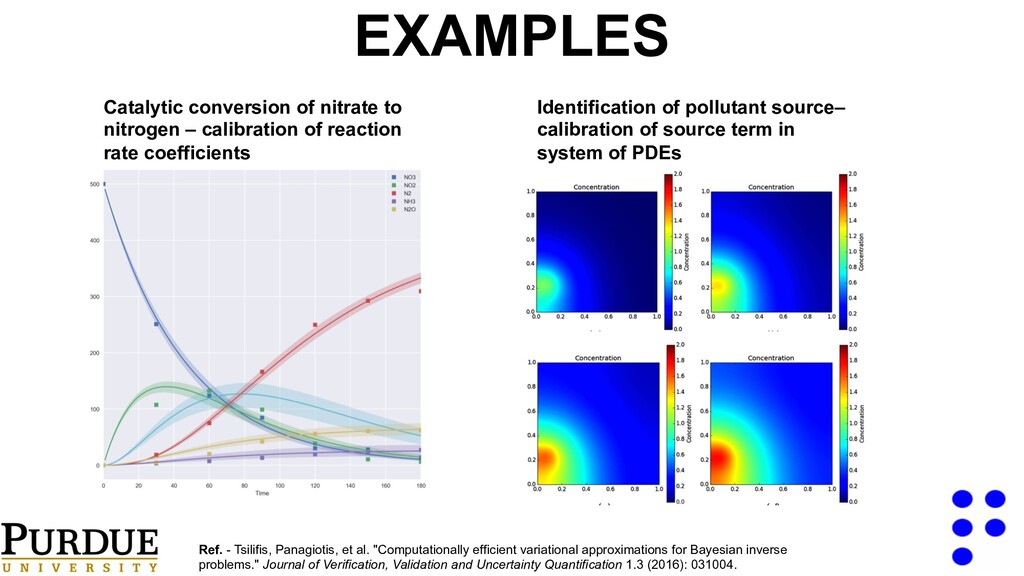
rate coefficients Identification of pollutant source– calibration of source term in system of PDEs Ref. - Tsilifis, Panagiotis, et al. "Computationally efficient variational approximations for Bayesian inverse problems." Journal of Verification, Validation and Uncertainty Quantification 1.3 (2016): 031004. EXAMPLES
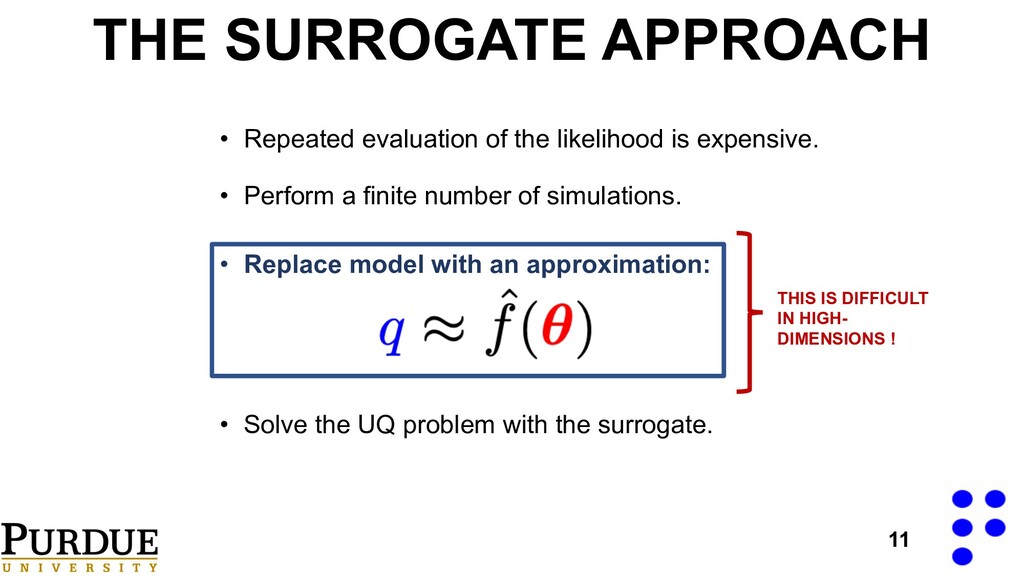
• Solve the UQ problem with the surrogate. • Replace model with an approximation: 11 • Repeated evaluation of the likelihood is expensive. THIS IS DIFFICULT IN HIGH- DIMENSIONS !
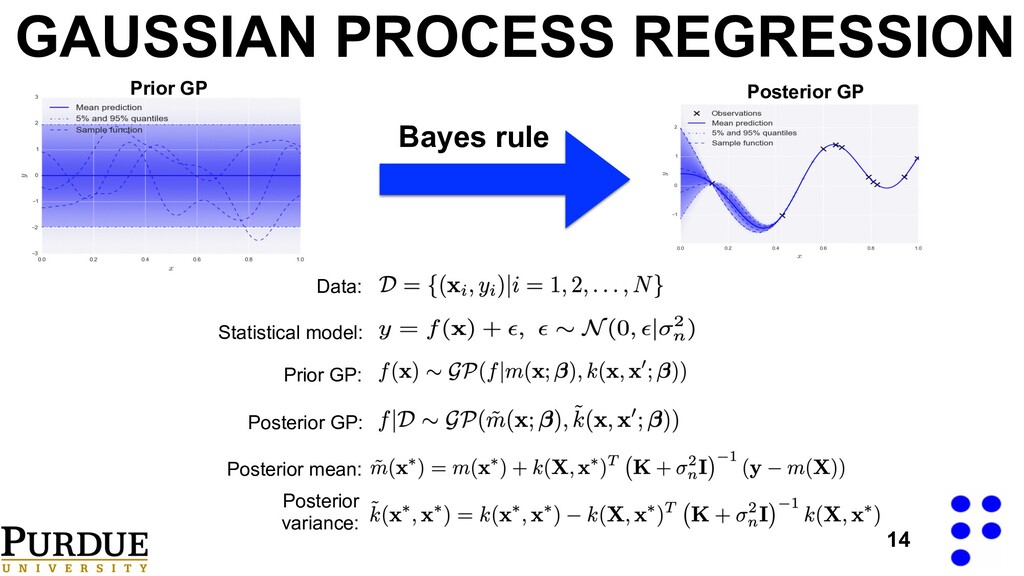
distribution of the hyperparameters. Ref. - Rasmussen, Carl Edward. "Gaussian processes in machine learning." Advanced lectures on machine learning. Springer, Berlin, Heidelberg, 2004. 63-71.. Hyperparameter prior: Hyperparameter posterior: Approximation of the posterior at the mode: Marginal likelihood:
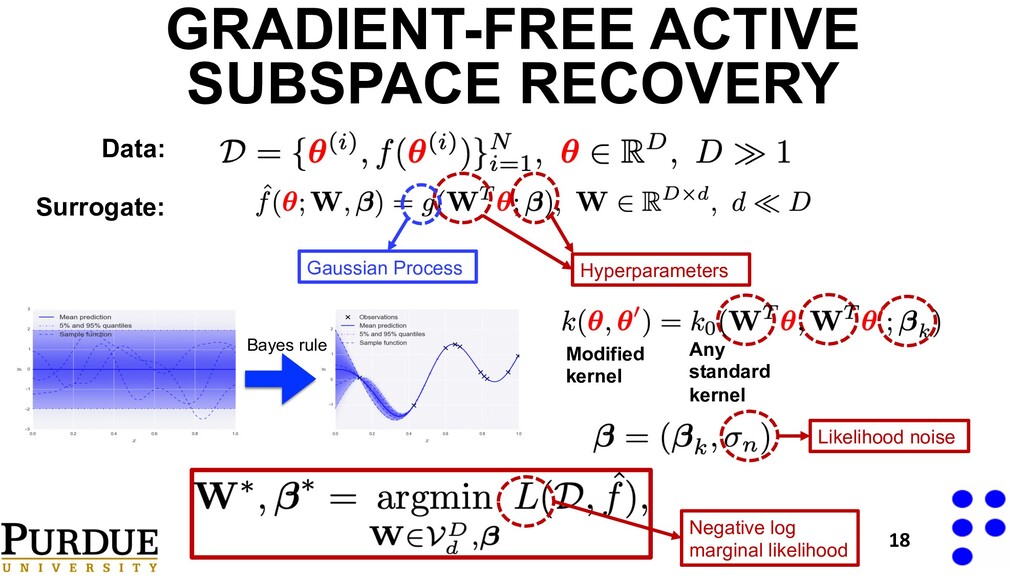
and Qiqi Wang. "Active subspace methods in theory and practice: applications to kriging surfaces." SIAM Journal on Scientific Computing 36.4 (2014): A1500-A1524. Probability Measure: Sample gradients: Centered covariance: Spectral decomposition: Final surrogate: How do we get these? 16
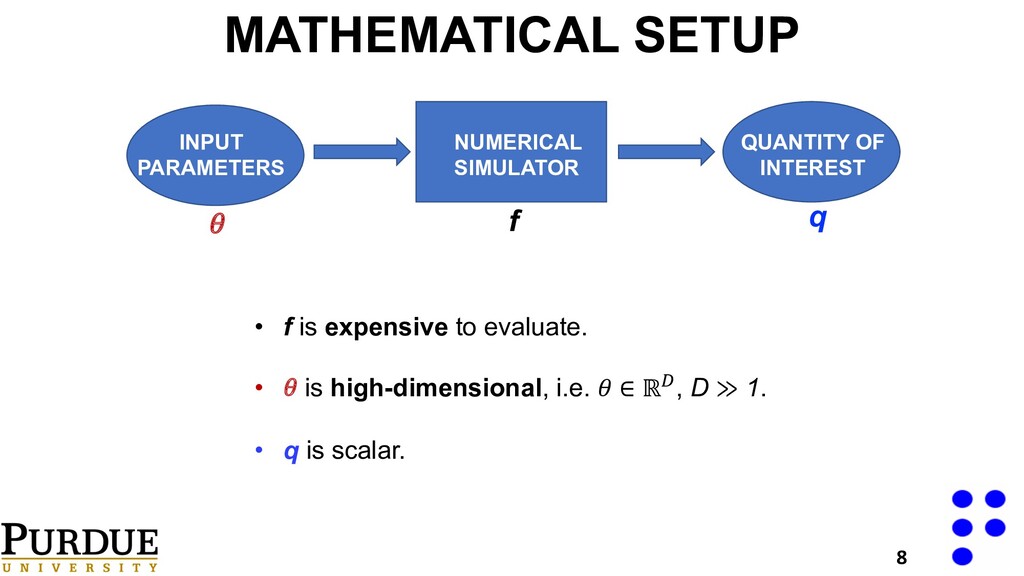
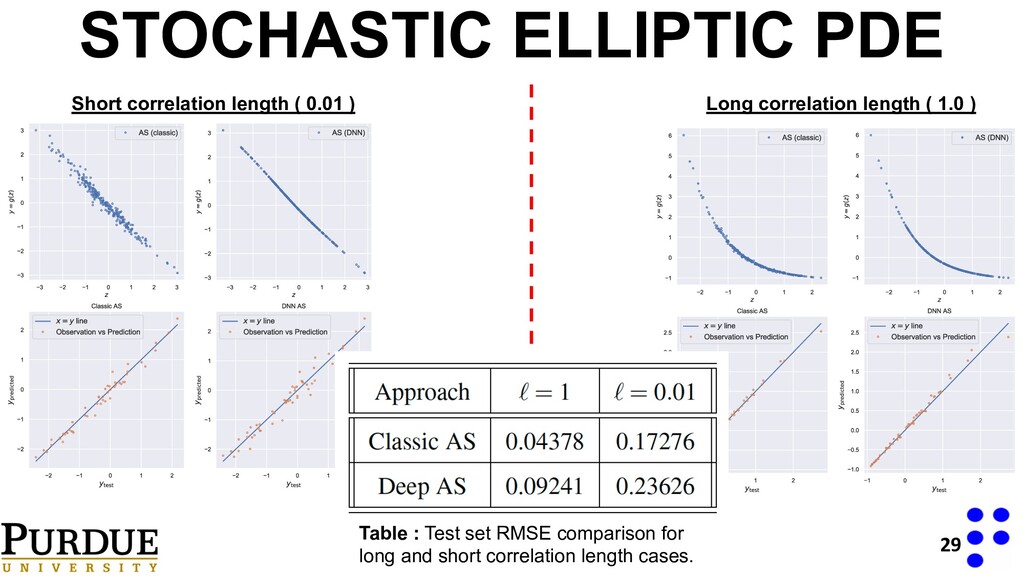
links the vector of uncertain parameters to the quantity of interest q. Find: With data**: High dimensional inputs, small sample set. **Data source: https://github.com/paulcon/as-data-sets/tree/master/Elliptic_PDE STOCHASTIC ELLIPTIC PDE 20 Tripathy, Rohit, Ilias Bilionis, and Marcial Gonzalez. "Gaussian processes with built-in dimensionality reduction: Applications to high-dimensional uncertainty propagation." Journal of Computational Physics 321 (2016): 191-223.
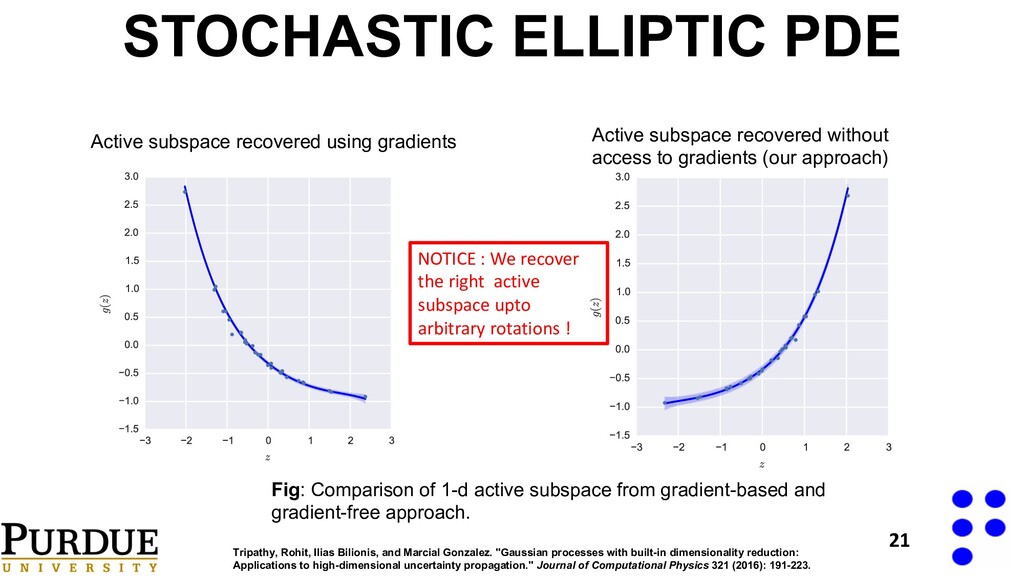
approach. Active subspace recovered using gradients Active subspace recovered without access to gradients (our approach) NOTICE : We recover the right active subspace upto arbitrary rotations ! 21 Tripathy, Rohit, Ilias Bilionis, and Marcial Gonzalez. "Gaussian processes with built-in dimensionality reduction: Applications to high-dimensional uncertainty propagation." Journal of Computational Physics 321 (2016): 191-223. STOCHASTIC ELLIPTIC PDE
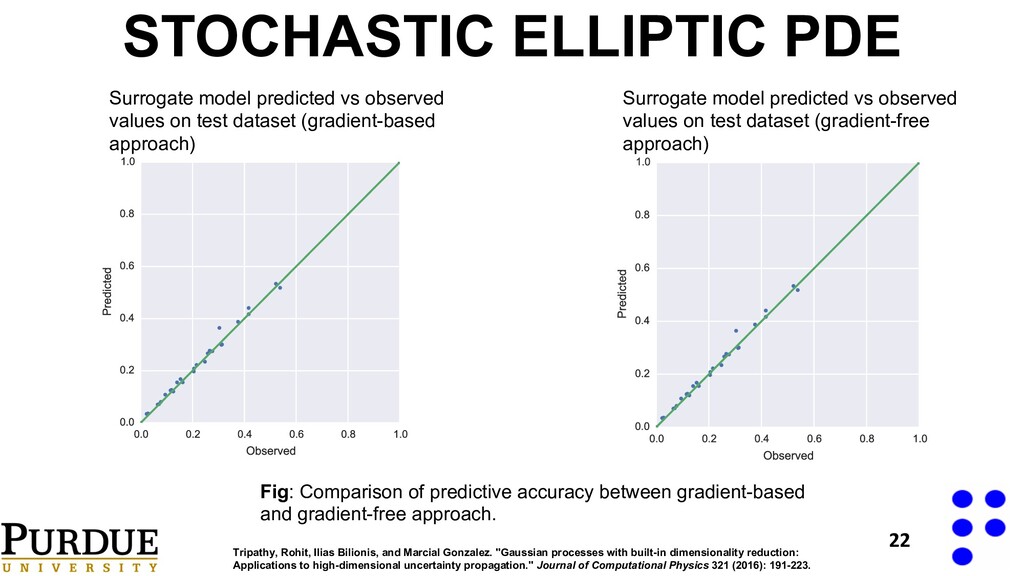
Surrogate model predicted vs observed values on test dataset (gradient-based approach) Surrogate model predicted vs observed values on test dataset (gradient-free approach) 22 Tripathy, Rohit, Ilias Bilionis, and Marcial Gonzalez. "Gaussian processes with built-in dimensionality reduction: Applications to high-dimensional uncertainty propagation." Journal of Computational Physics 321 (2016): 191-223. STOCHASTIC ELLIPTIC PDE
Dow, and Qiqi Wang. "Active subspace methods in theory and practice: applications to kriging surfaces." SIAM Journal on Scientific Computing 36.4 (2014): A1500-A1524. Probability Measure: Sample gradients: Centered covariance: Spectral decomposition: Final surrogate: 26
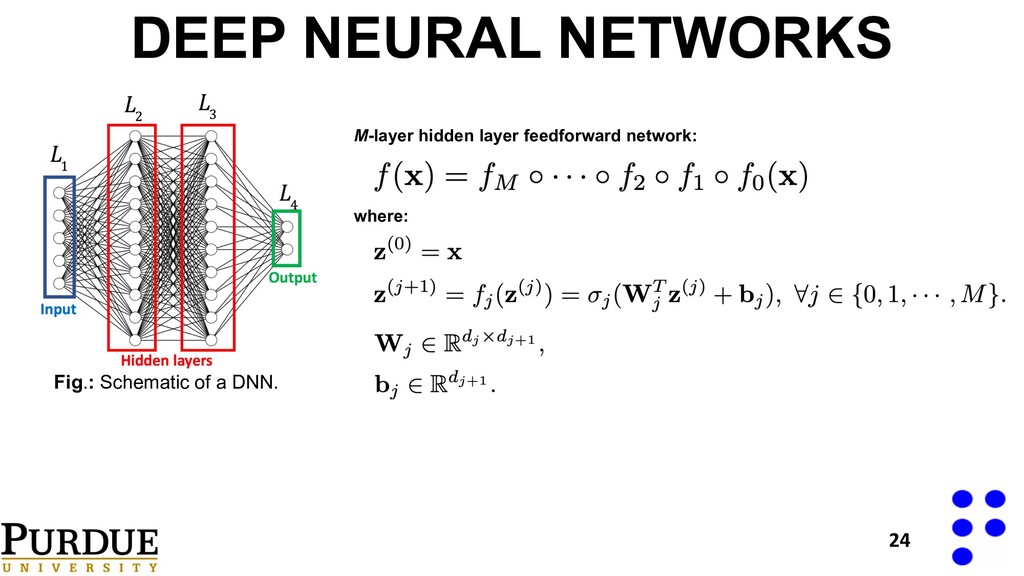
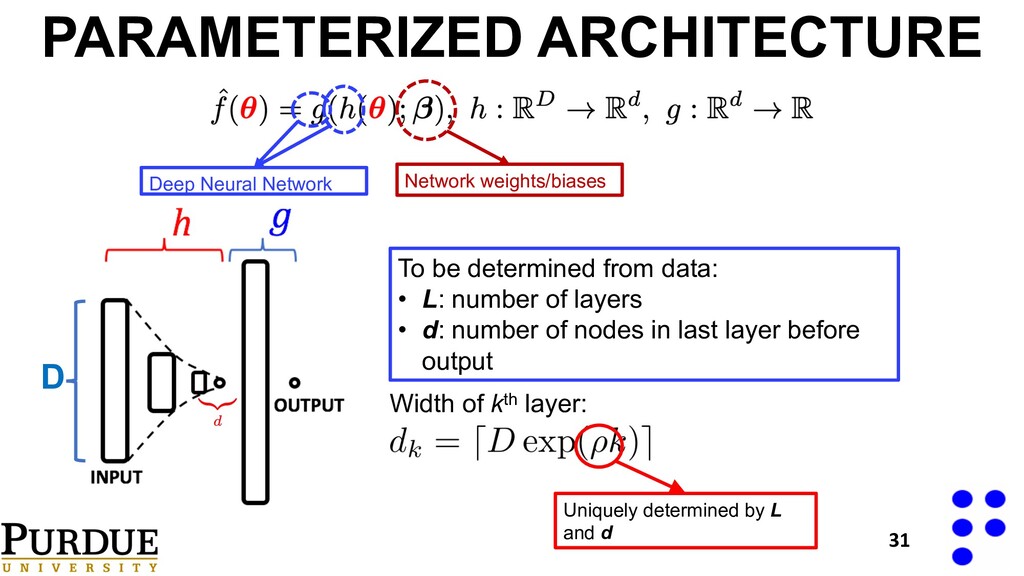
• d: number of nodes in last layer before output PARAMETERIZED ARCHITECTURE 31 Width of kth layer: Uniquely determined by L and d Deep Neural Network Network weights/biases D
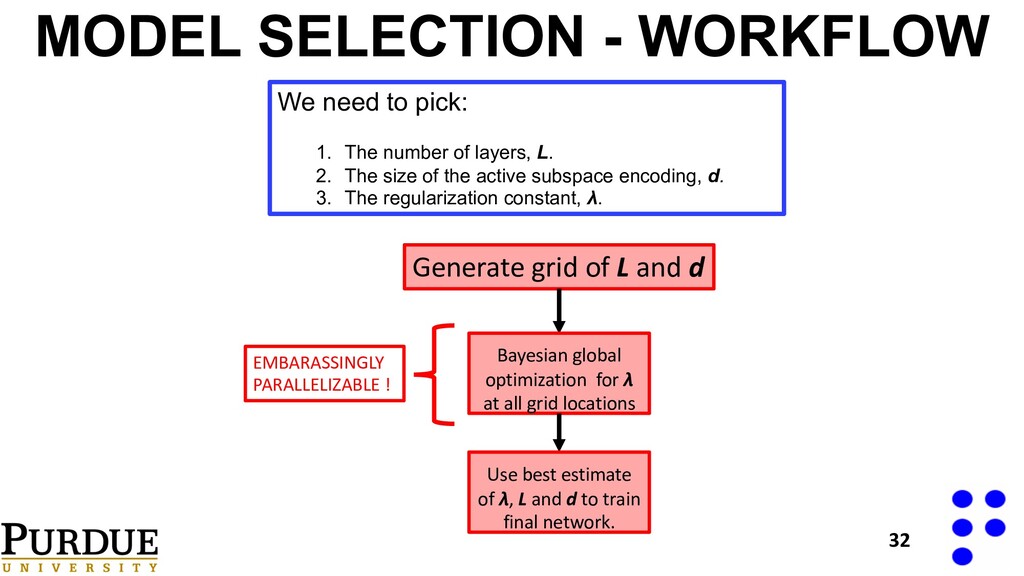
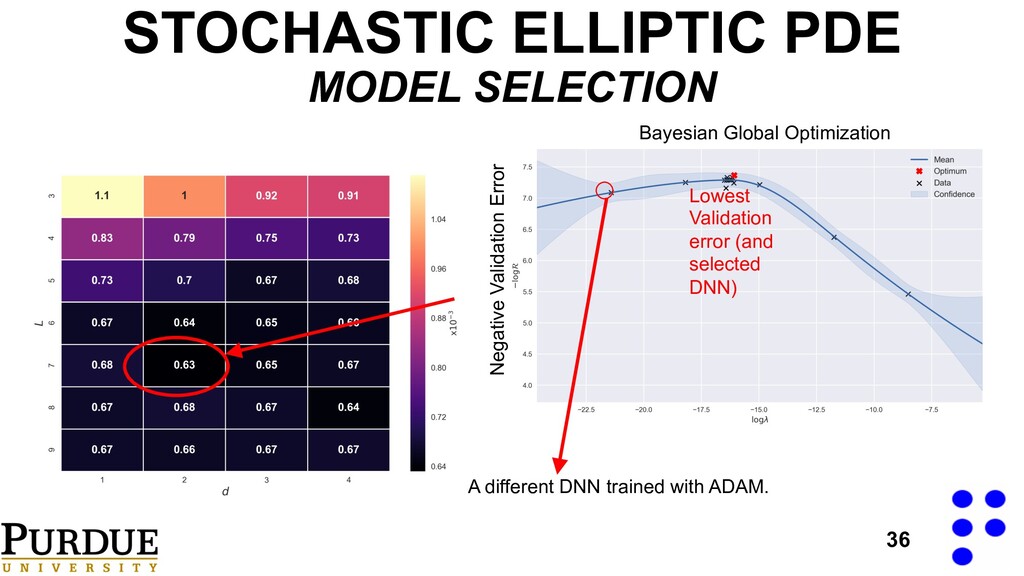
d Bayesian global optimization for λ at all grid locations Use best estimate of λ, L and d to train final network. EMBARASSINGLY PARALLELIZABLE ! We need to pick: 1. The number of layers, L. 2. The size of the active subspace encoding, d. 3. The regularization constant, λ.
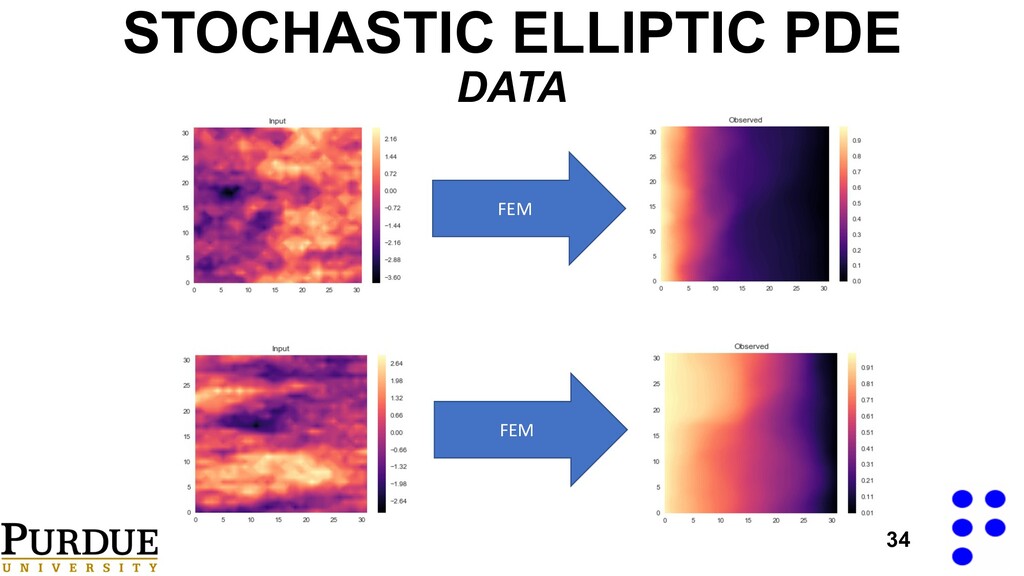
• Sampling the conductivity on a 32x32 grid. oFor each one of the sampled conductivities, we solved the PDE on a 32x32 grid. u(x, ✓) <latexit sha1_base64="ErE6xeO1oqTds87eAIYJzhu3d/o=">AAACJXicbVDLSgMxFM3UV62vqks3wSIoSJkRQRcuim5cKlgtdErJZO60oZkHyR2xDPMzbvwVNy4sIrjyV8zUgtp6IOTk3EfuPV4ihUbb/rBKc/MLi0vl5crK6tr6RnVz61bHqeLQ5LGMVctjGqSIoIkCJbQSBSz0JNx5g4sifncPSos4usFhAp2Q9SIRCM7QSN3q2Z4bMux7QfaQV9L9n8chzdxx+0yBn1PXi6Wvh6G5Mhf7gCzPD7rVml23x6CzxJmQGpngqlsduX7M0xAi5JJp3XbsBDsZUyi4hLziphoSxgesB21DIxaC7mTjMXK6ZxSfBrEyJ0I6Vn9XZCzUxYQms9hCT8cK8b9YO8XgtJOJKEkRIv79UZBKijEtLKO+UMBRDg1hXAkzK+V9phhHY2zFmOBMrzxLbo/qjl13ro9rjfOJHWWyQ3bJPnHICWmQS3JFmoSTR/JMXsnIerJerDfr/Tu1ZE1qtskfWJ9fggumgw==</latexit> <latexit sha1_base64="ErE6xeO1oqTds87eAIYJzhu3d/o=">AAACJXicbVDLSgMxFM3UV62vqks3wSIoSJkRQRcuim5cKlgtdErJZO60oZkHyR2xDPMzbvwVNy4sIrjyV8zUgtp6IOTk3EfuPV4ihUbb/rBKc/MLi0vl5crK6tr6RnVz61bHqeLQ5LGMVctjGqSIoIkCJbQSBSz0JNx5g4sifncPSos4usFhAp2Q9SIRCM7QSN3q2Z4bMux7QfaQV9L9n8chzdxx+0yBn1PXi6Wvh6G5Mhf7gCzPD7rVml23x6CzxJmQGpngqlsduX7M0xAi5JJp3XbsBDsZUyi4hLziphoSxgesB21DIxaC7mTjMXK6ZxSfBrEyJ0I6Vn9XZCzUxYQms9hCT8cK8b9YO8XgtJOJKEkRIv79UZBKijEtLKO+UMBRDg1hXAkzK+V9phhHY2zFmOBMrzxLbo/qjl13ro9rjfOJHWWyQ3bJPnHICWmQS3JFmoSTR/JMXsnIerJerDfr/Tu1ZE1qtskfWJ9fggumgw==</latexit> <latexit sha1_base64="ErE6xeO1oqTds87eAIYJzhu3d/o=">AAACJXicbVDLSgMxFM3UV62vqks3wSIoSJkRQRcuim5cKlgtdErJZO60oZkHyR2xDPMzbvwVNy4sIrjyV8zUgtp6IOTk3EfuPV4ihUbb/rBKc/MLi0vl5crK6tr6RnVz61bHqeLQ5LGMVctjGqSIoIkCJbQSBSz0JNx5g4sifncPSos4usFhAp2Q9SIRCM7QSN3q2Z4bMux7QfaQV9L9n8chzdxx+0yBn1PXi6Wvh6G5Mhf7gCzPD7rVml23x6CzxJmQGpngqlsduX7M0xAi5JJp3XbsBDsZUyi4hLziphoSxgesB21DIxaC7mTjMXK6ZxSfBrEyJ0I6Vn9XZCzUxYQms9hCT8cK8b9YO8XgtJOJKEkRIv79UZBKijEtLKO+UMBRDg1hXAkzK+V9phhHY2zFmOBMrzxLbo/qjl13ro9rjfOJHWWyQ3bJPnHICWmQS3JFmoSTR/JMXsnIerJerDfr/Tu1ZE1qtskfWJ9fggumgw==</latexit> STOCHASTIC ELLIPTIC PDE DATA [1] - Rohit K Tripathy and Ilias Bilionis. Deep UQ: Learning deep neural network surrogate models for high dimensional uncertainty quantification. Journal of Computational Physics, 375:565–588, 2018.
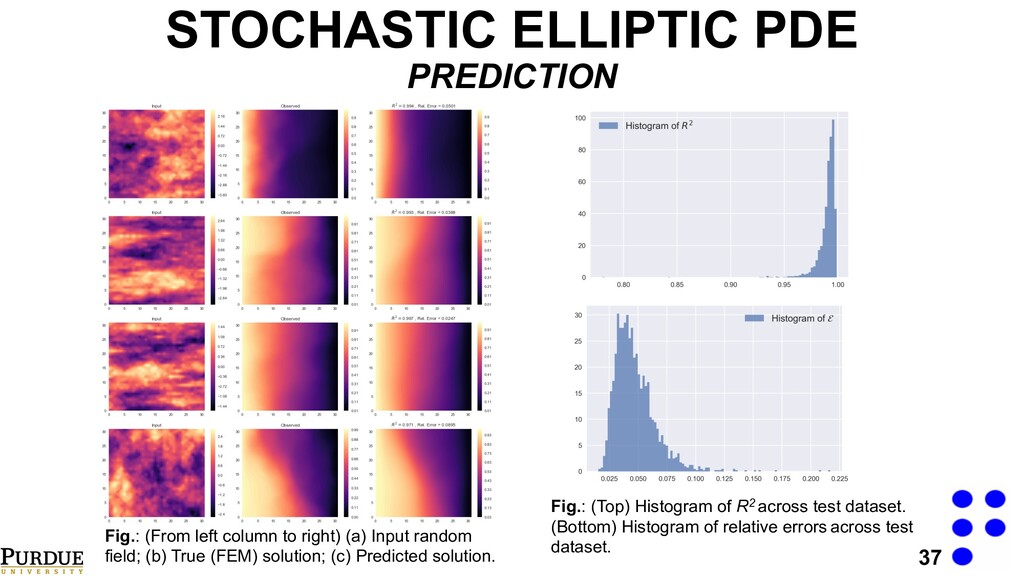
right) (a) Input random field; (b) True (FEM) solution; (c) Predicted solution. Fig.: (Top) Histogram of R2 across test dataset. (Bottom) Histogram of relative errors across test dataset.
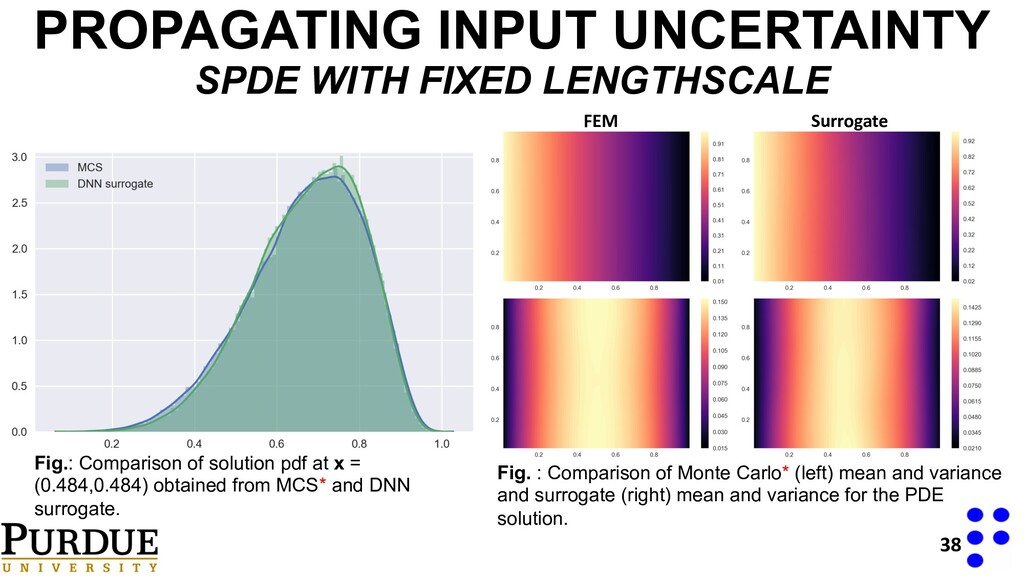
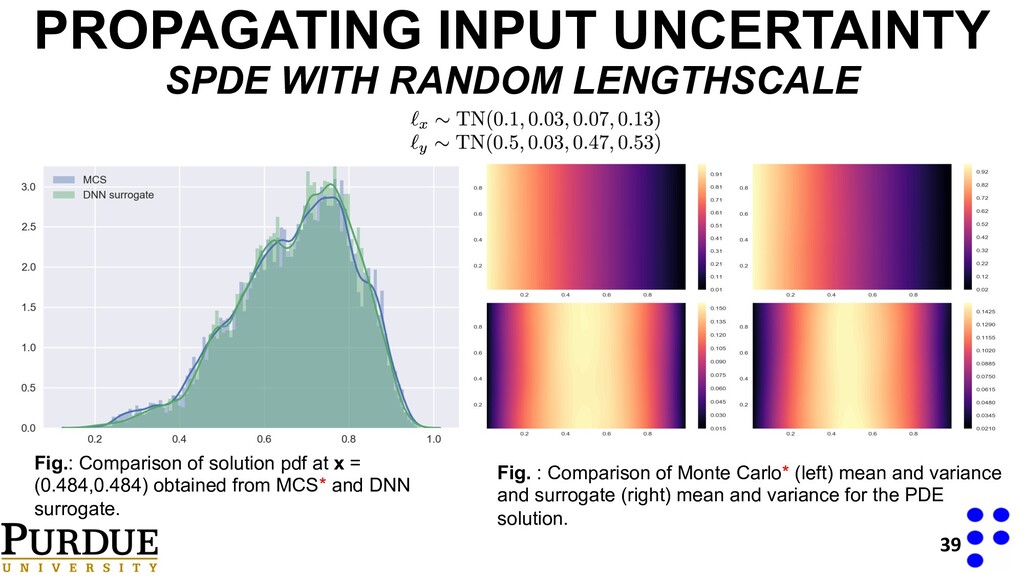
of solution pdf at x = (0.484,0.484) obtained from MCS* and DNN surrogate. Fig. : Comparison of Monte Carlo* (left) mean and variance and surrogate (right) mean and variance for the PDE solution. FEM Surrogate
of solution pdf at x = (0.484,0.484) obtained from MCS* and DNN surrogate. Fig. : Comparison of Monte Carlo* (left) mean and variance and surrogate (right) mean and variance for the PDE solution.
due to slow convergence. § Surrogate approach to UQ – constrained by high-dimensionality and cost of numerical simulator. § Strategy – find suitable low-rank approximation of the stochastic parameter space: • Optimal linear projections for capturing directions of maximal variation of QoI gradient (active subspace). • Nonlinear manifold capturing QoI variability (deep neural networks). § Limitations with proposed approaches – • Scalability concerns with GPs. • Incorporation of rigorous priors (continuity/smoothness etc.) in DNNs. • Incorporation of physical constraints. 40
into statistical models (physics-informed machine learning). • Synthesizing information from multiple sources of varying levels of fidelity (multifidelity surrogate modeling & uncertainty quantification). • Exploiting group-theoretic structure in dynamical systems. • Developing surrogates robust to non-stationarities, discontinuities etc. 41
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![35 o2000 random conductivities generated by: • Sampling length-scales [1].](https://files.speakerdeck.com/presentations/b4a2f3f8050448aaa9cfc6b1dad8abc8/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![REFERENCES 42 [1] Rohit Tripathy, Ilias Bilionis, and Marcial Gonzalez.](https://files.speakerdeck.com/presentations/b4a2f3f8050448aaa9cfc6b1dad8abc8/slide_41.jpg){kind=link}
{kind=link}