regarding concurrency and distribution • Concurrency & distribution is hard • How Ruby deals with it • Elixir & Erlang introduction • How Erlang-land stuff impacts the way we design such systems • Conclusions
answers • I absolutely won’t tell you “what to do” • I will assume “some” knowledge with the backend stuff discussed today • I will not show you a {case,example} so that we will have more time to talk about stuff
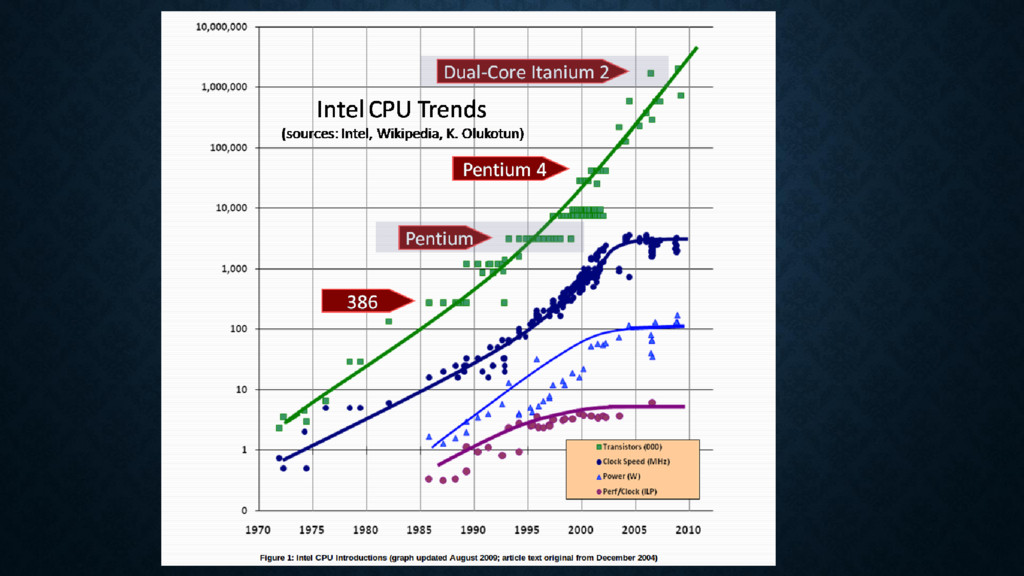
getting faster exponentially –But we are still getting sponentially more transitors (more cores!) –No substantial gains in sequential performance* –Concurrency is the next major revolution in how we write software
only in 2007. –No AWS, Twitter, Netflix. –Ruby on Rails 1.0 only in december. –Youtube was just founded. –You never heard of Justing Bieber –NO STACK OVERFLOW.
load application (10s of page views/sec) • 2 - Small, has users. Now we need to take some things to the background • 3 – Some complex and “long” async workflows. A *big* machine still solves our issues • 4 – Tons of machines, apps, developers and multiple data stores. Requires lots of coordination and distribution. Real-time & stateful stuff. A “real backend”
load application (10s of page views/sec) • 2 - Small, has users. Now we need to take some things to the background • 3 – Some complex and “long” async workflows. A *big* machine still solves our issues • 4 – Tons of machines, apps, developers and multiple data stores. Requires lots of coordination and distribution. Real-time & stateful stuff. A “real backend” THIS IS HELL HARD
its isolation levels. • Mongo basically screws up every guarantee it claims to give you. Kyle Kingsbury (@aphyr) tells you not to use it. See the posts below for more info: https://aphyr.com/posts/322-jepsen-mongodb-stale-reads https://aphyr.com/posts/284-jepsen-mongodb
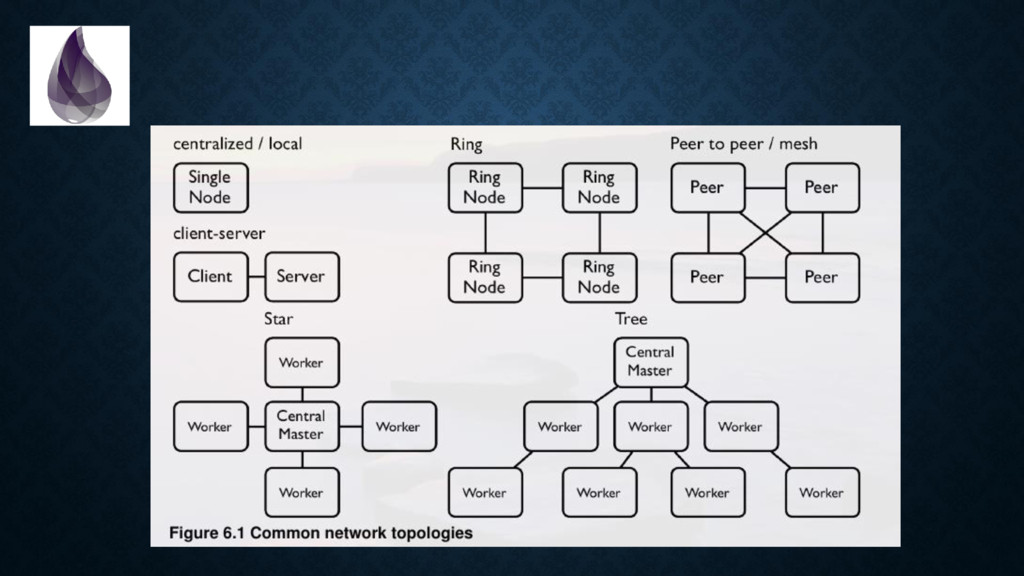
hard about distributed systems: • 2. ensure messages are “delivered once” • 1. ensure messages are “delivered in order” • 2. ensure messages are “delivered once” • That’s why Distributed Locks & Counters are hard.
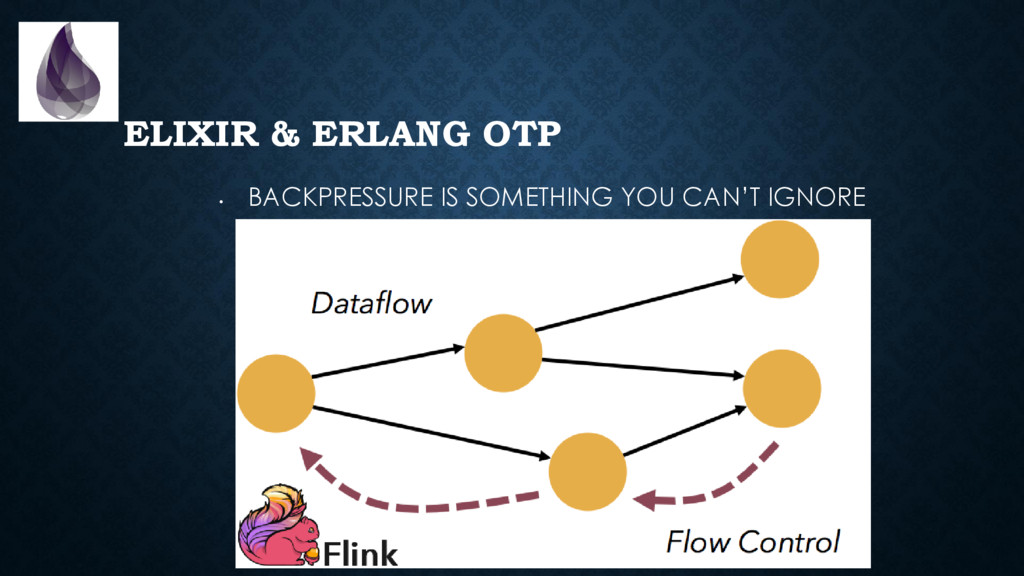
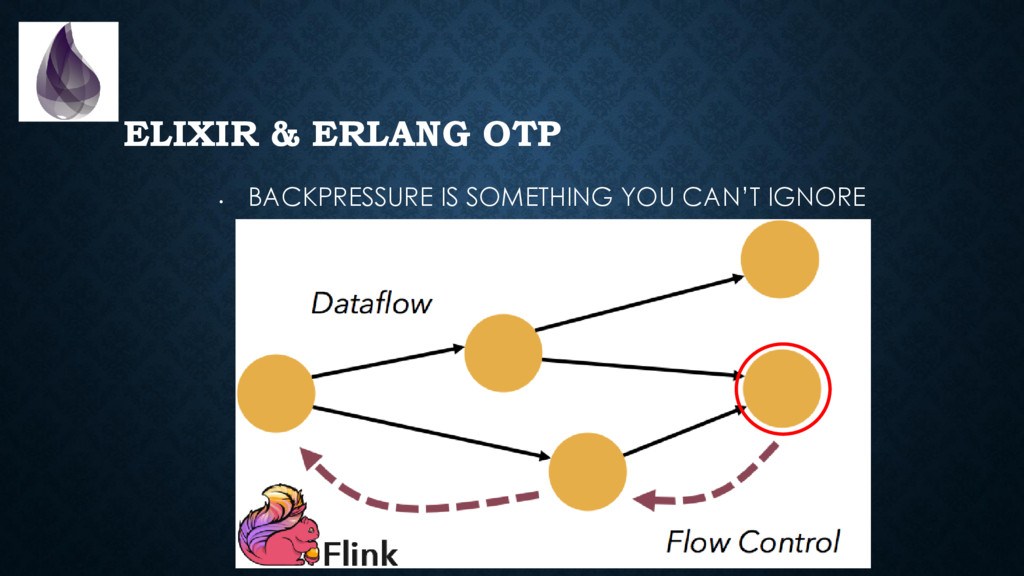
Metrics, alerts, log aggregation are a must-have. • You need to handle back-pressure & timeouts when integrating systems • Releasing a new version is *not* instantaneous. You gotta deal with different live versions at the same time. • You need to be able to easily “inspect” the whole- system when debugging. Ssh-ing individual nodes won’t cut it.
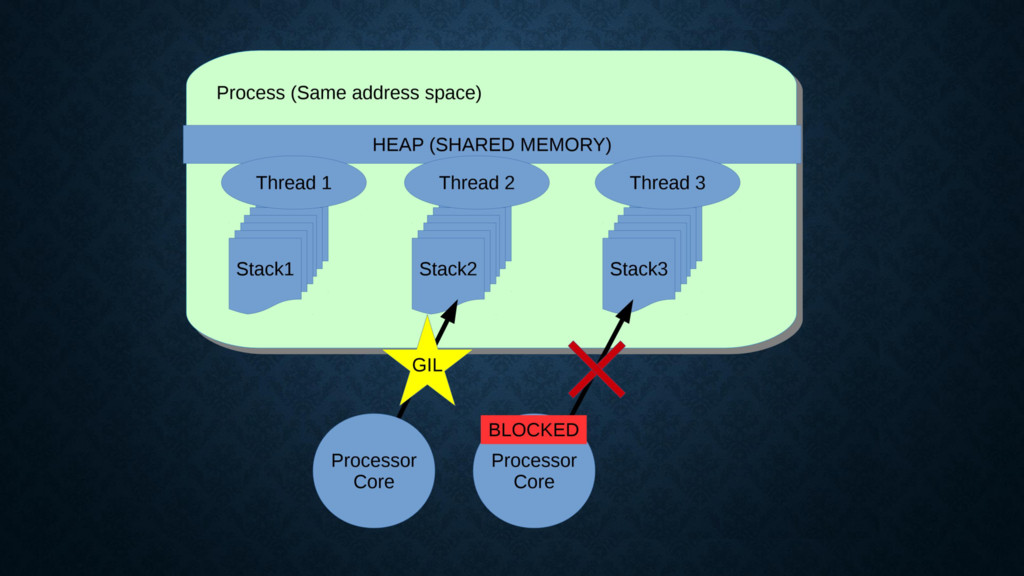
Concurrent-ruby, etc that are able to help you *a lot* when writing concurrent. No memory model and portability issues. • I argue that they only “marginally extend” the spectrum of problems in which we are able to handle with Ruby. Ruby 3.0 _might_ make the situation better, but we’re far from it. • **IT IS** definitely possible to scale Ruby to tremendous loads. See Shopify as an example. • Ruby’s design goals are very different than the ones of Elixir & Erlang.
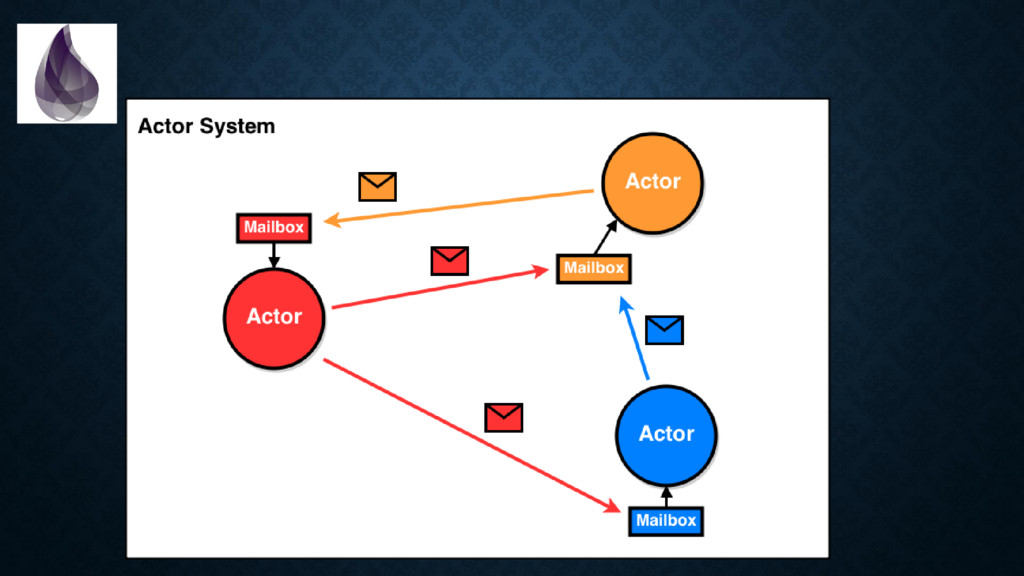
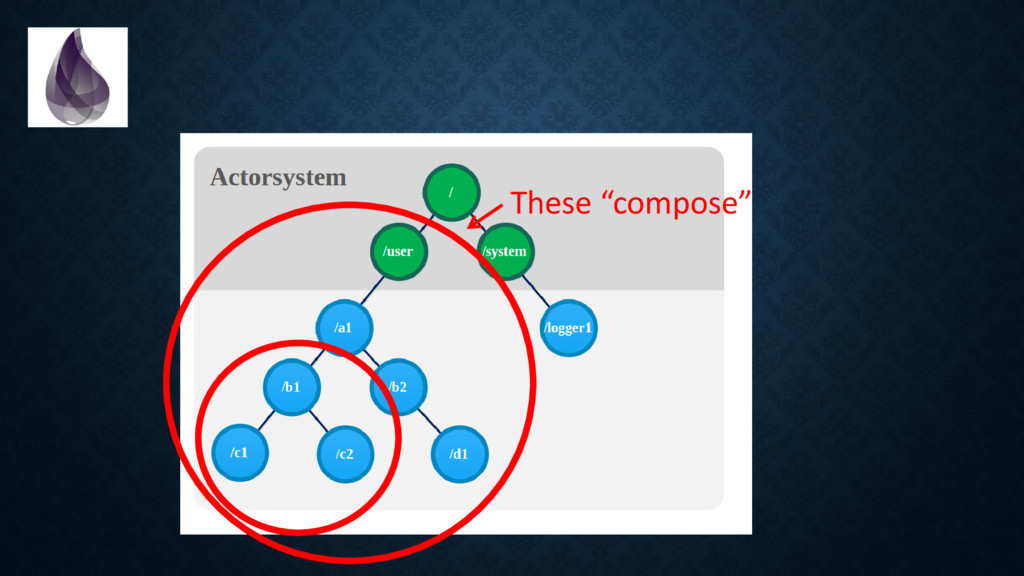
a lot of punching. • Erlang's runtime is extremely mature and battle-hardened. • Fault tolerance is a first class citizen. Hot-code reloads are possible. Many versions of the same module can coexist. • Erlang is built to yield uptimes up to 99.9999999% (really) • Communication is “shared nothing” and “default asynchronous”. • This is also called the “Actor System”.
& Macros (!*). • Elixir is pragmatic (!!!) • Performance is great. GC happens per-process. (*) • Very small latency variance (!!) • Documentation & tooling are take seriously. (*) • The runtime & OTP are AWESOME. Every process is preempted. No bad neighbors. SO CHEAP (~4k overhead)
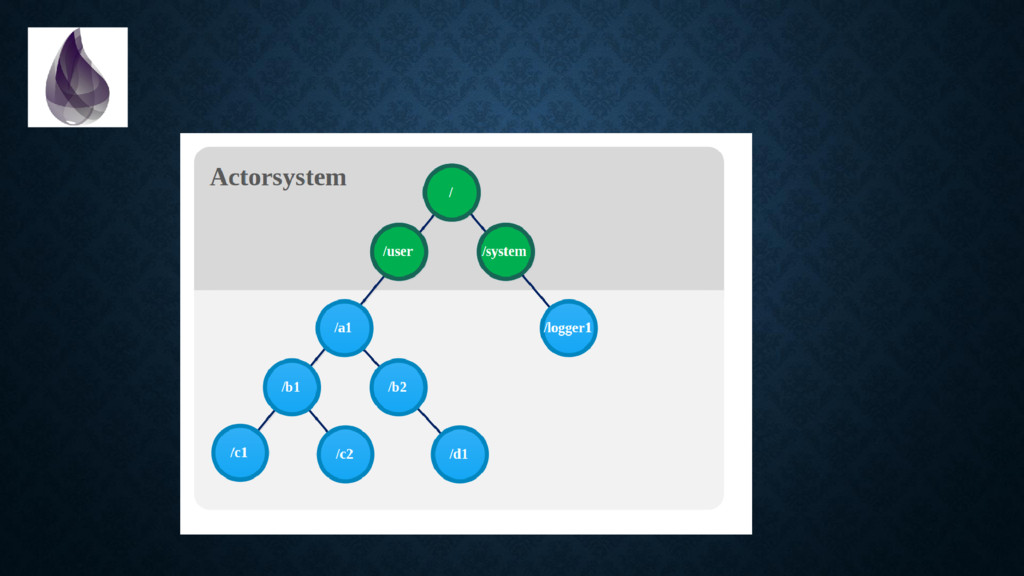
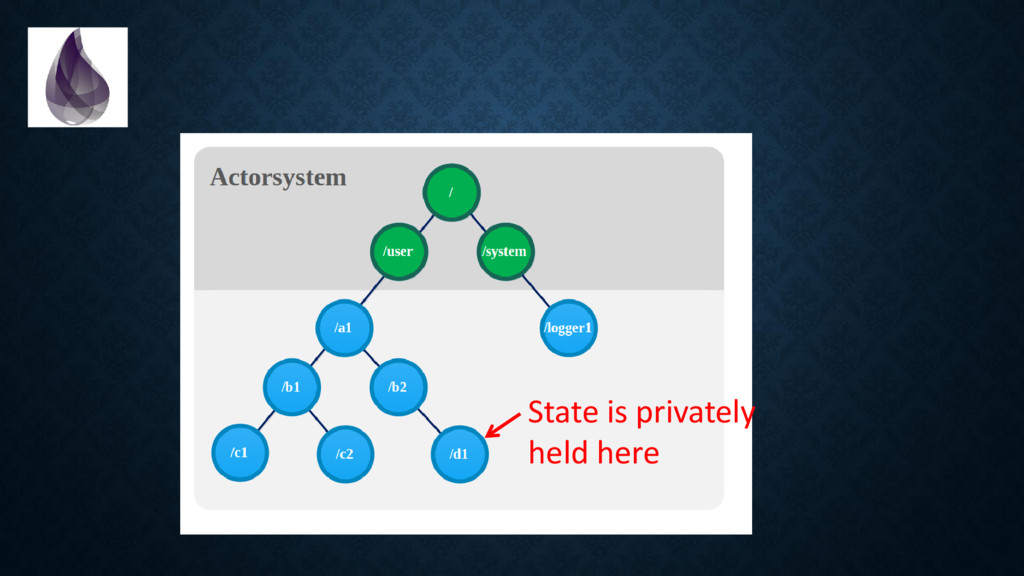
in terms of “bindings” and “values” instead of “addresses” and “memory”. • There is “one true way” to achieve coordination. And since nothing is shared you *don’t need to think about memory access patterns (!!!!)*
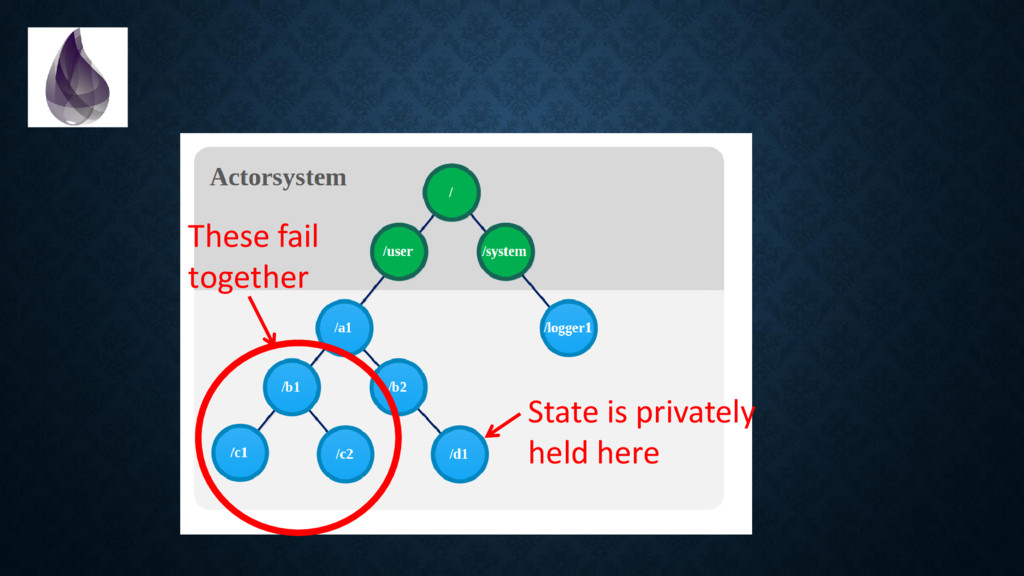
are various options with strong guarantees. You can isolate crashes, but you can also connect failures if needed. Some scenarios may require more work, but the implementation is still straightforward. Supporting these scenarios without process isolation and crash propagation would be harder and you might end up reinventing parts of Erlang. Sasa Juric
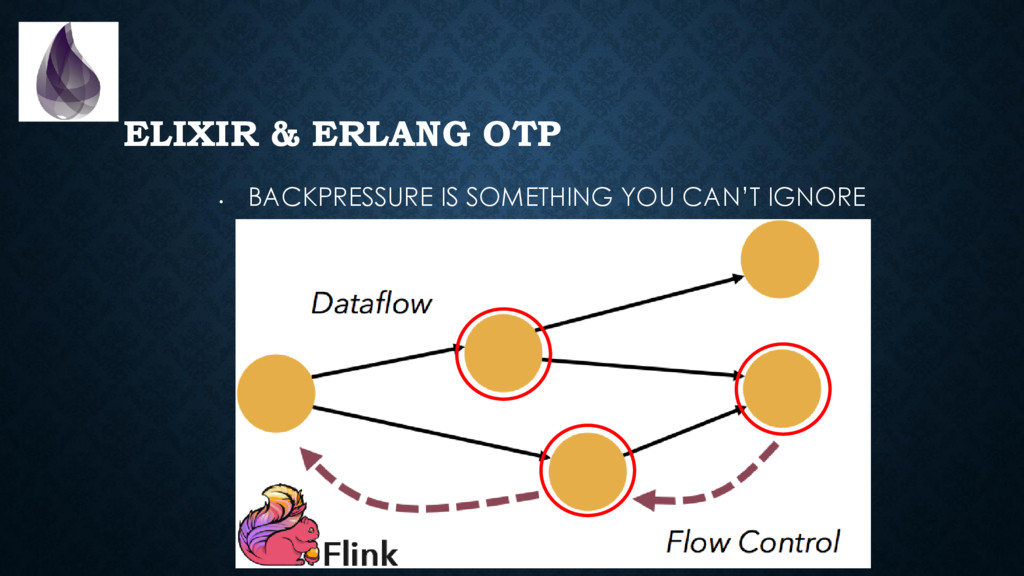
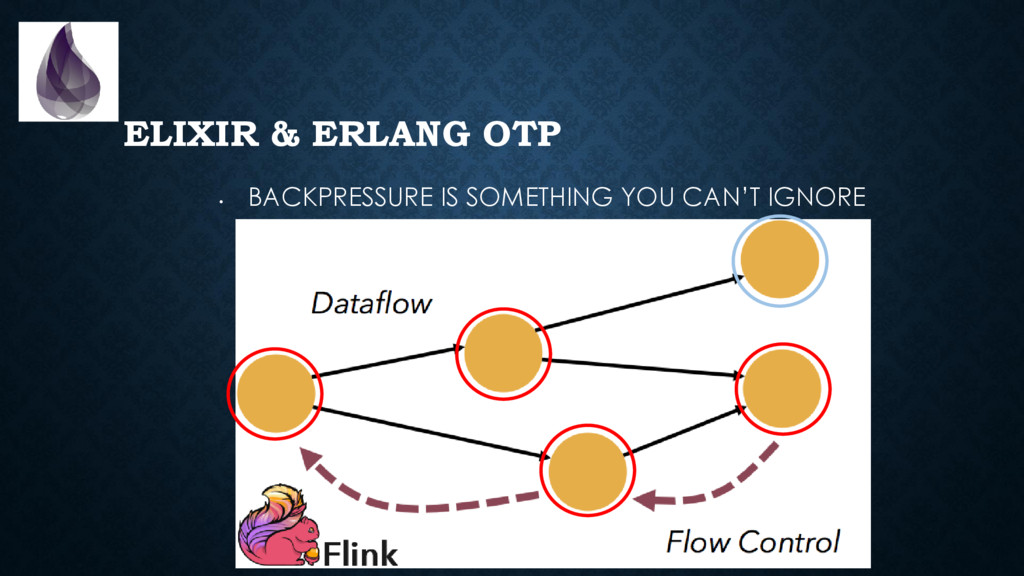
to package, start, inspect, stop, upgrade and debug applications *in production*. (with some discipline & configuration, we can solve many of the same problems microservices solve) • Backpressure is built-in in many places • The virtual machine provides you with a **ton** of metrics. It is trivial and non-intrusive to collect those. • Tracing is “cheap” and built-in. Think of “log on steroids”
to handle 2M web sockets in a single box without fancy kernel optimizations. Maxed out on the limit of open files. (100k new conns/sec) • http://www.phoenixframework.org/blog/the-road-to-2- million-websocket-connections
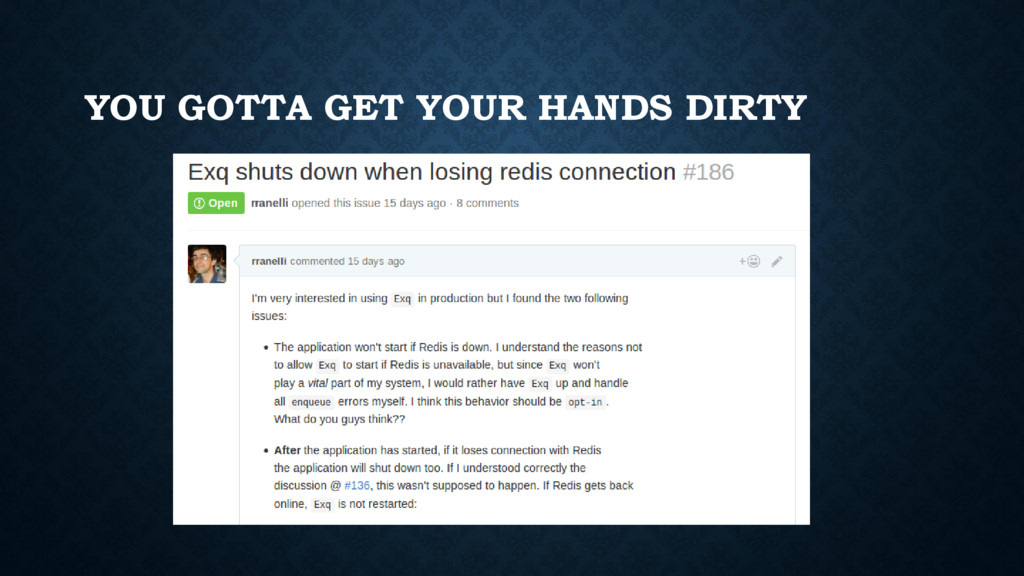
very small (and somewhat buggy). • No easy & quick-win options for monitoring apps (like new relic, appsignal, honeybadger). • Nothing as mature as Sidekiq (we have Exq and verk, but still...).
very small (and kinda buggy). • No usable client for elastic search (*) • No usable (at the time?) library for exposing jsonapi (*) • No usable (at the time) library to handle auth (*) • No usable bindings for GraphicsMagick (*) • Releases are so damn hard and un-12factor (*) (config) • Hot code reloads are much much harder than people say • Almost no problems with core libs like Ecto, Plug & Phoenix though.
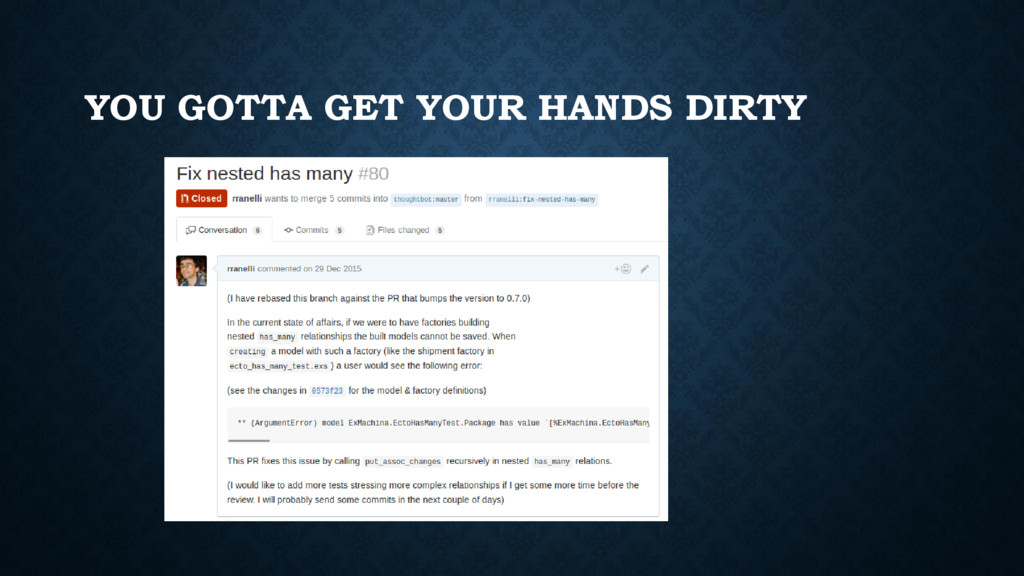
lot from other communities. It fundamentally changes the way we think and architect systems • You can see that it evolves and taps into the learning experiences of other languages & communities. It still lacks a mature ecosystem but it is gaining traction fast. • If you truly aim to invest yourself in it, you must be ready to get your hands dirty and write some infrastructure you take for granted in other ecosystems. • Do *not* underestimate the complexity of managing library code + tests + docs + versioning + bug tracking.
issues I talked about here. {Erlang,Elixir} is *not* the only kid in the block … (see how many data-infrastructure projects are java based) • However, it is common to add *a lot* of extra infrastructure and moving parts in alternatives.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}