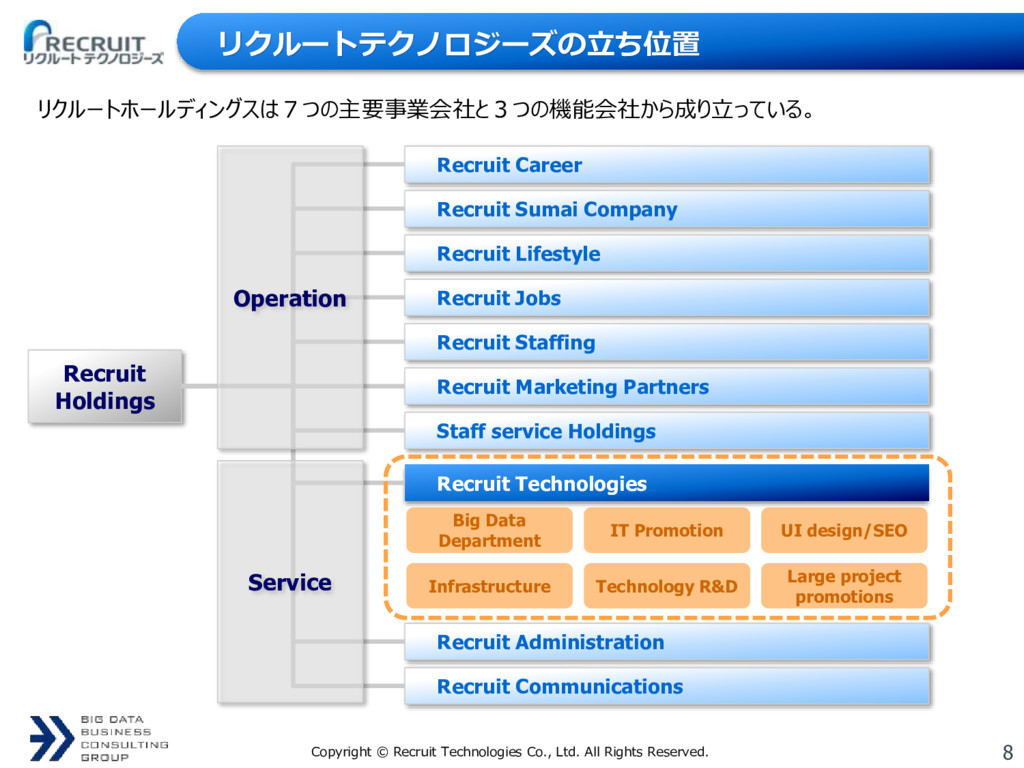
リクルートテクノロジーズの立ち位置 リクルートホールディングスは7つの主要事業会社と3つの機能会社から成り立っている。 Infrastructure Large project promotions UI design/SEO Big Data Department Technology R&D IT Promotion Recruit Holdings Recruit Career Recruit Sumai Company Recruit Lifestyle Recruit Jobs Recruit Staffing Recruit Marketing Partners Staff service Holdings Recruit Technologies Recruit Administration Recruit Communications Operation Service
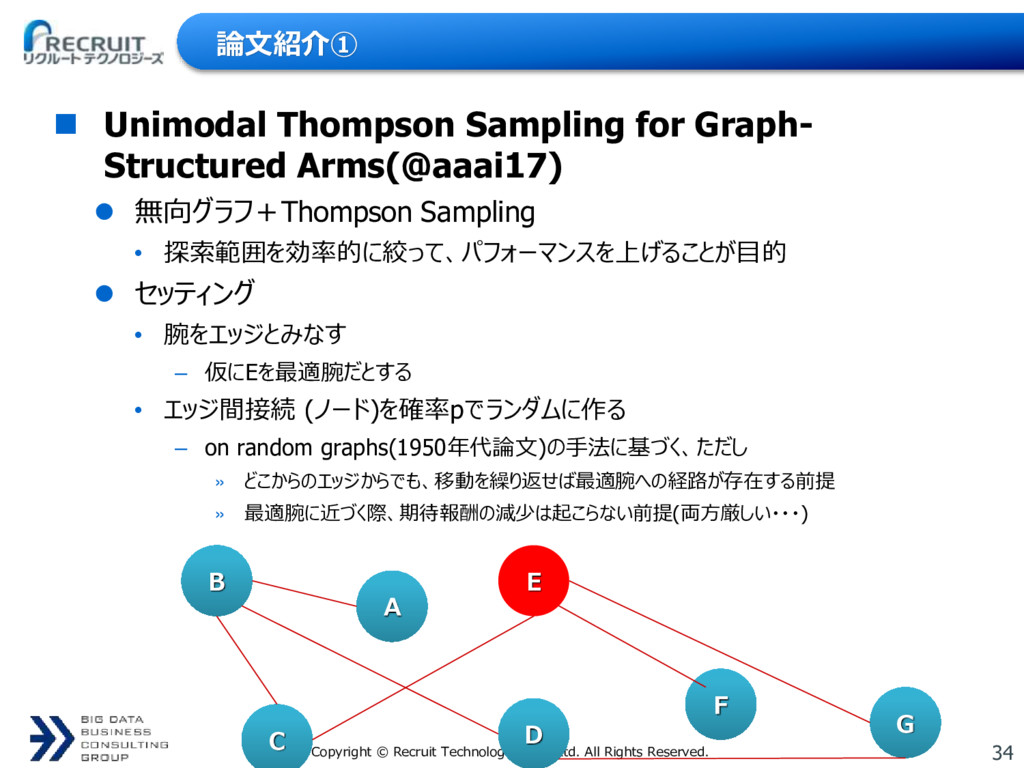
論文紹介① Unimodal Thompson Sampling for Graph- Structured Arms(@aaai17) 無向グラフ+Thompson Sampling • 探索範囲を効率的に絞って、パフォーマンスを上げることが目的 セッティング • 腕をエッジとみなす – 仮にEを最適腕だとする • エッジ間接続 (ノード)を確率pでランダムに作る – on random graphs(1950年代論文)の手法に基づく、ただし » どこからのエッジからでも、移動を繰り返せば最適腕への経路が存在する前提 » 最適腕に近づく際、期待報酬の減少は起こらない前提(両方厳しい・・・) B A E G F D C
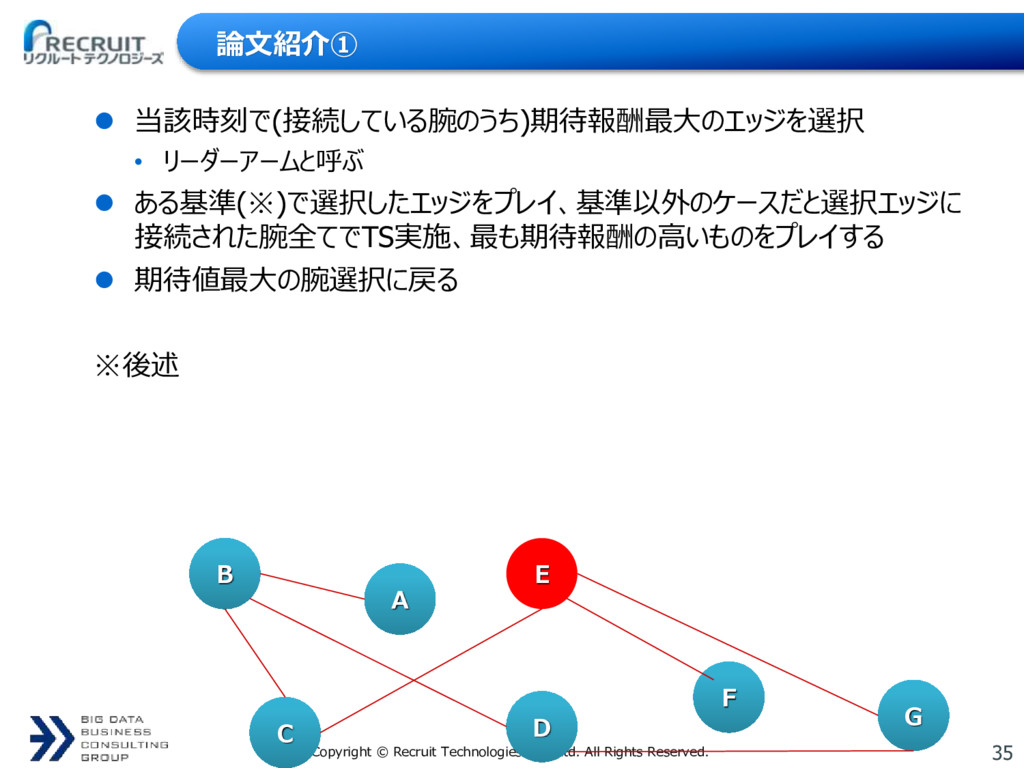
論文紹介① 当該時刻で(接続している腕のうち)期待報酬最大のエッジを選択 • リーダーアームと呼ぶ ある基準(※)で選択したエッジをプレイ、基準以外のケースだと選択エッジに 接続された腕全てでTS実施、最も期待報酬の高いものをプレイする 期待値最大の腕選択に戻る ※後述 B A E G F D C
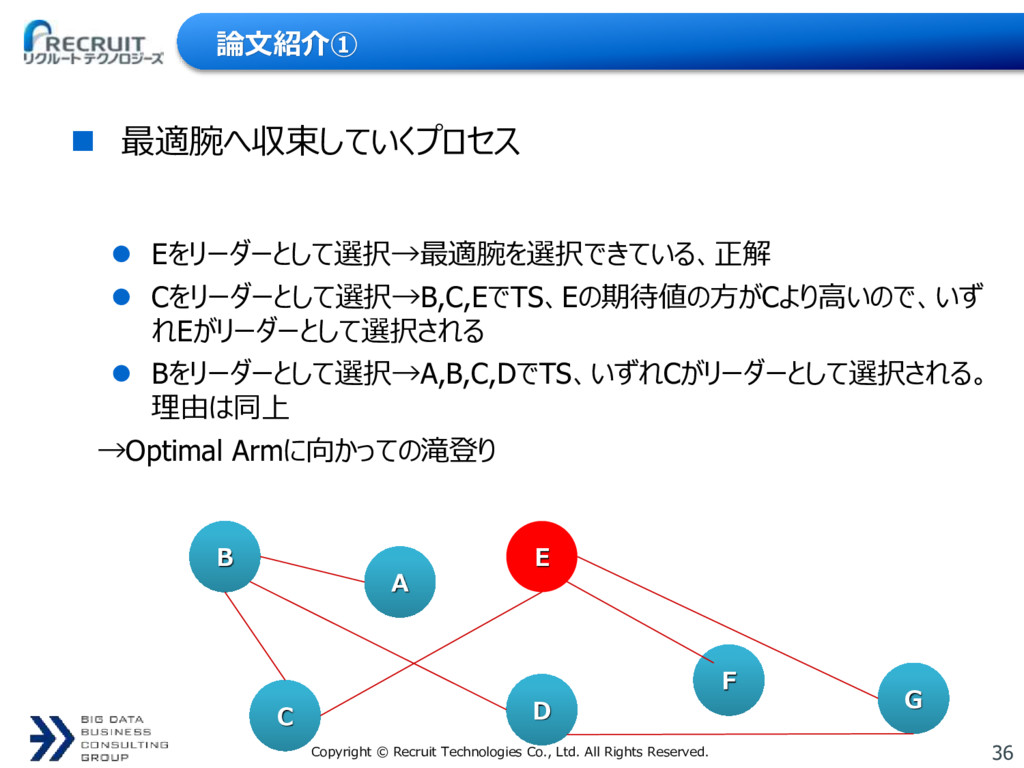
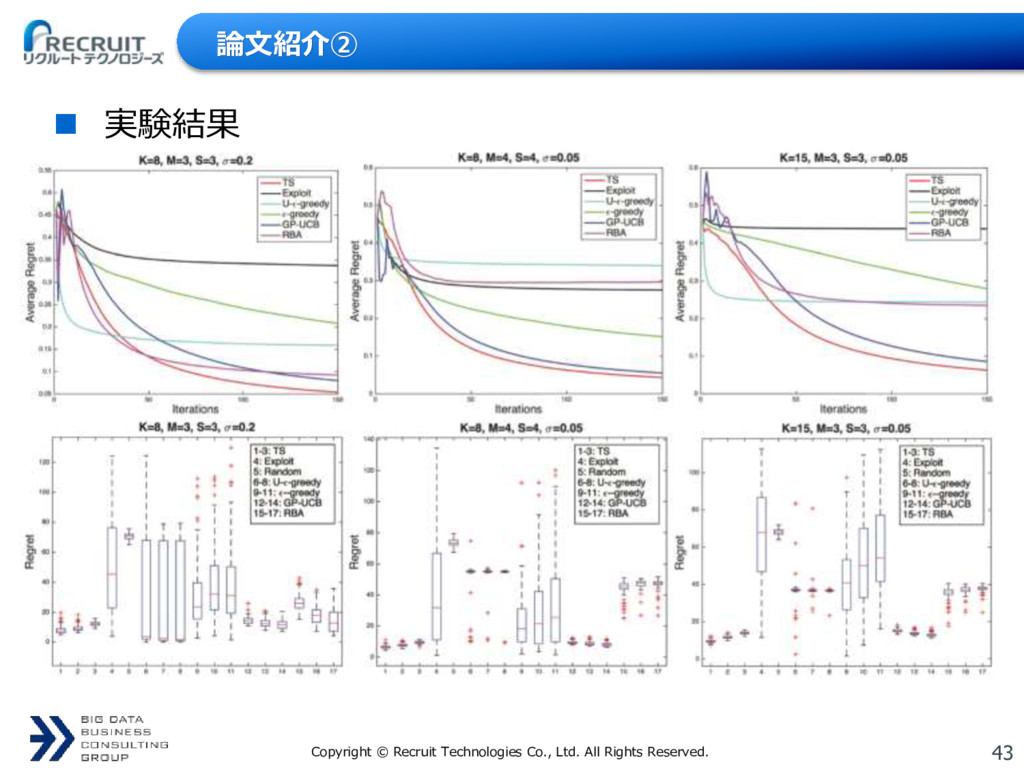
論文紹介① B A E G F D C 最適腕へ収束していくプロセス Eをリーダーとして選択→最適腕を選択できている、正解 Cをリーダーとして選択→B,C,EでTS、Eの期待値の方がCより高いので、いず れEがリーダーとして選択される Bをリーダーとして選択→A,B,C,DでTS、いずれCがリーダーとして選択される。 理由は同上 →Optimal Armに向かっての滝登り
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
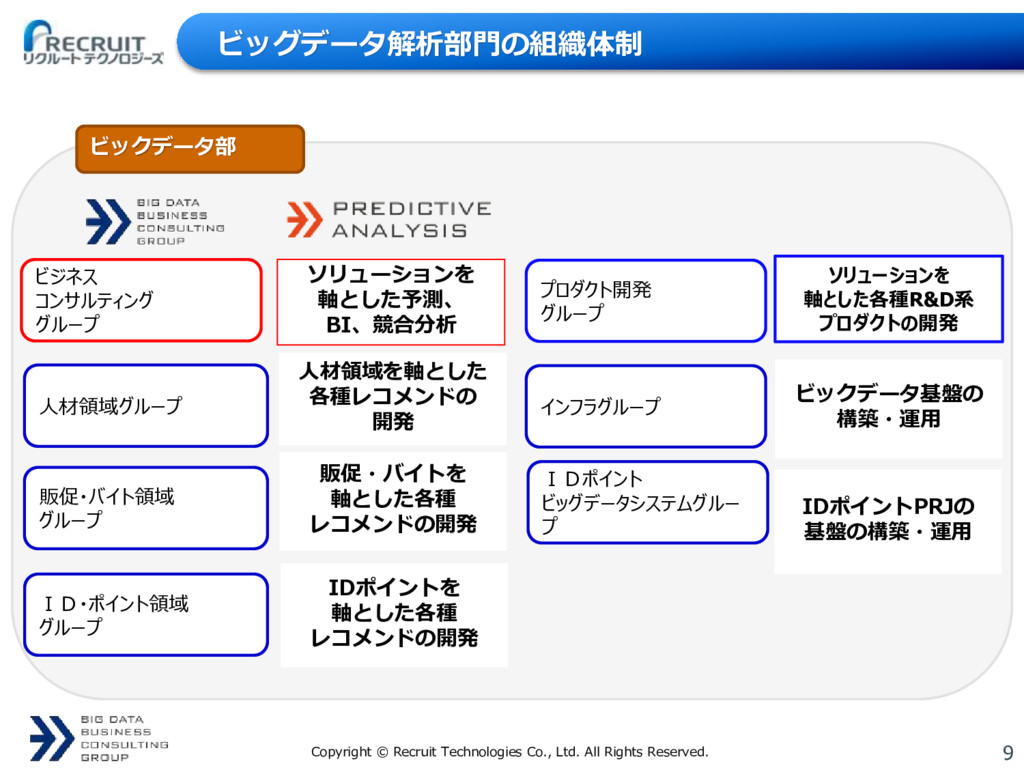{kind=link}
{kind=link}
{kind=link}
{kind=link}
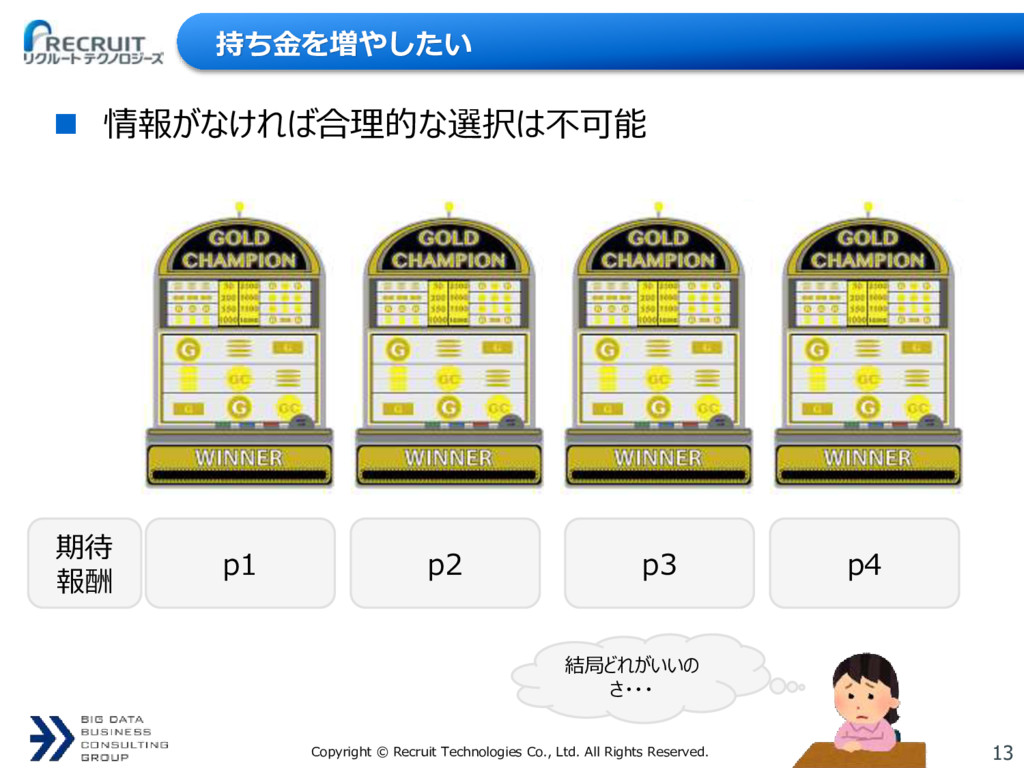{kind=link}
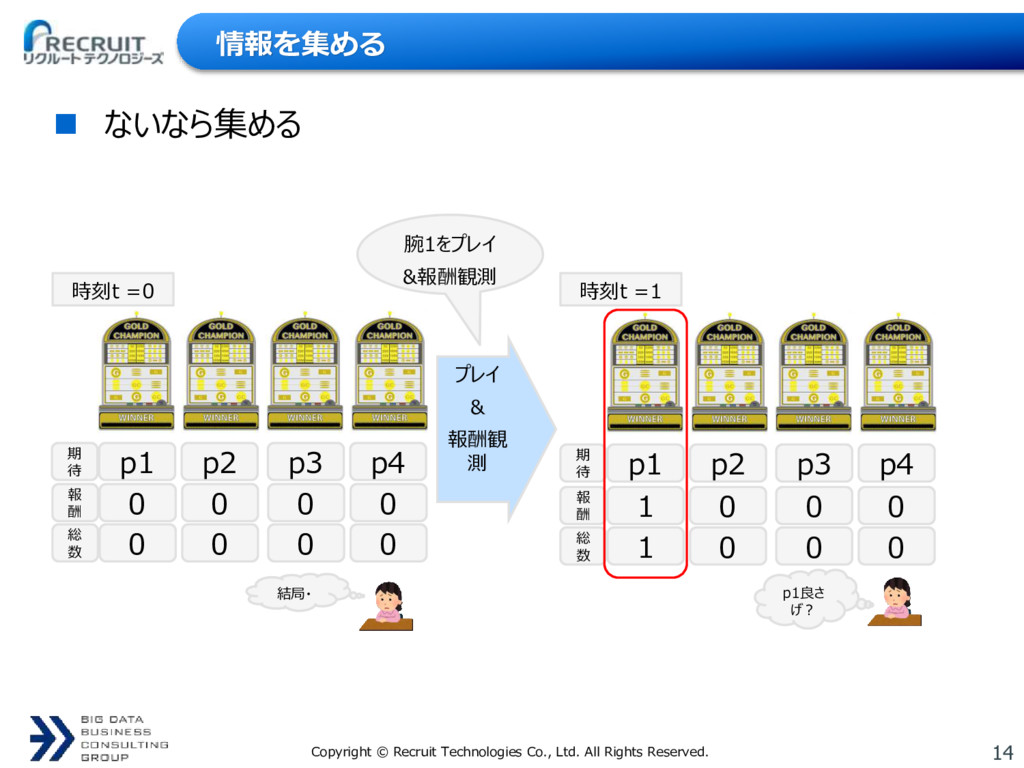{kind=link}
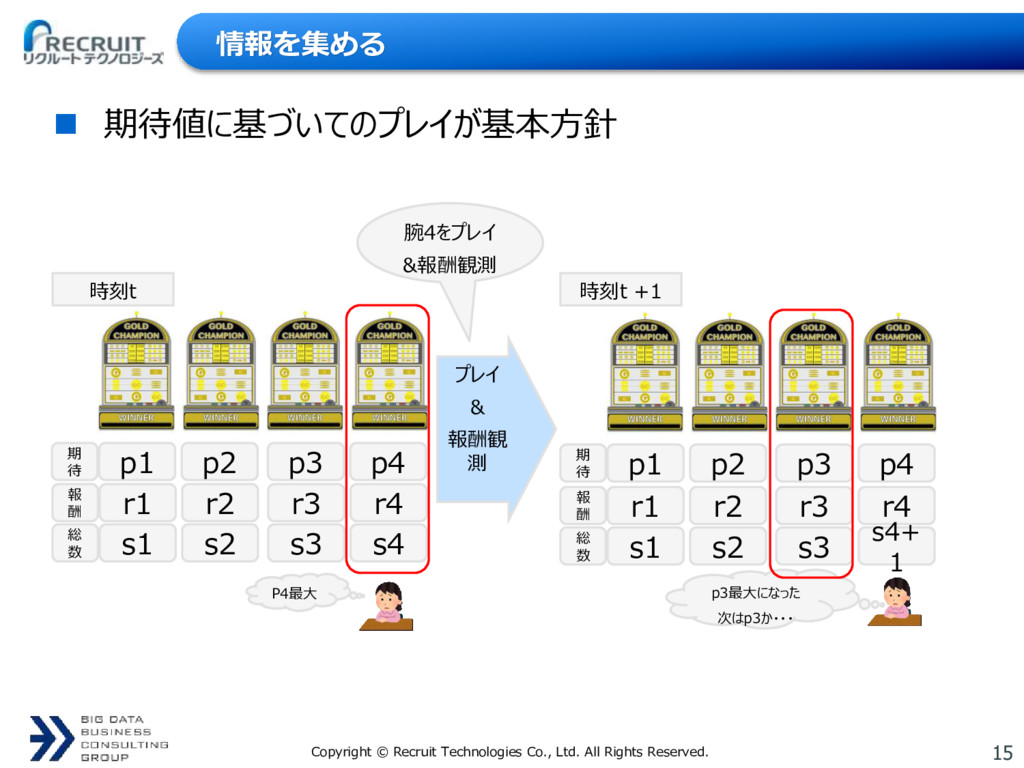{kind=link}
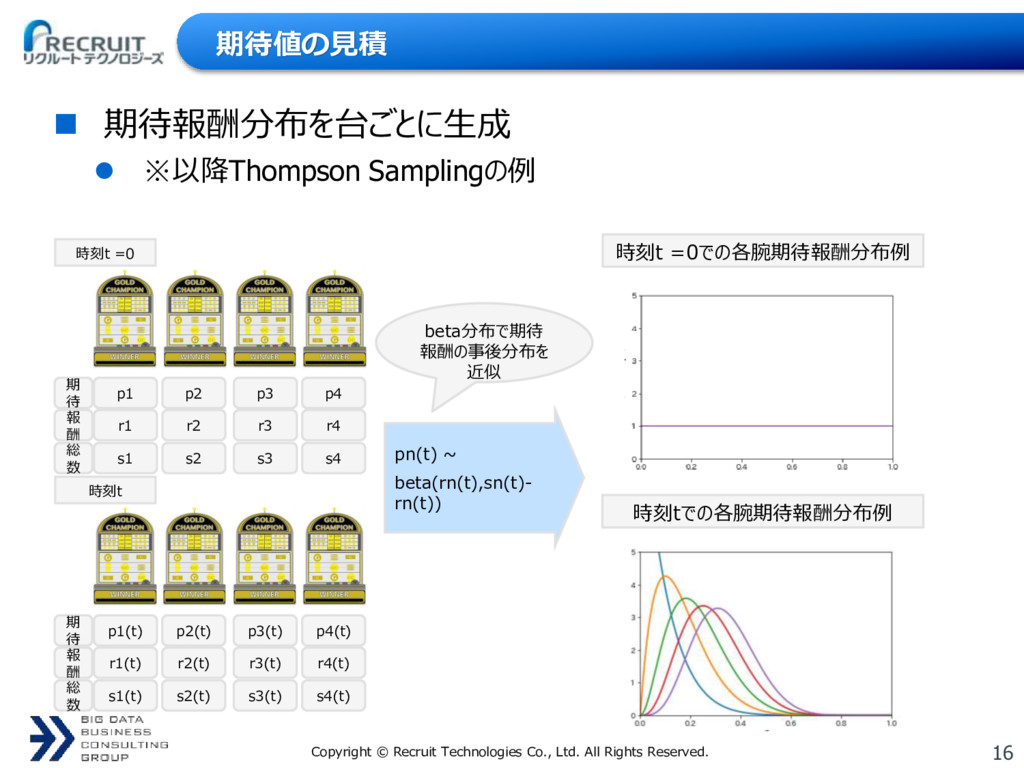{kind=link}
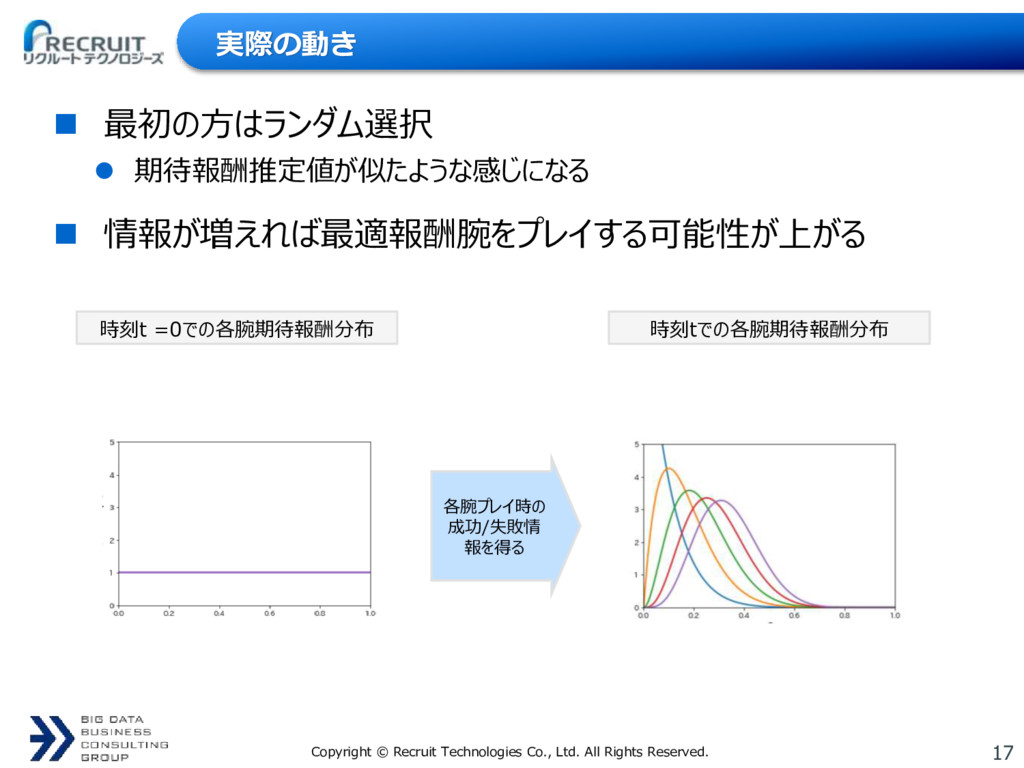{kind=link}
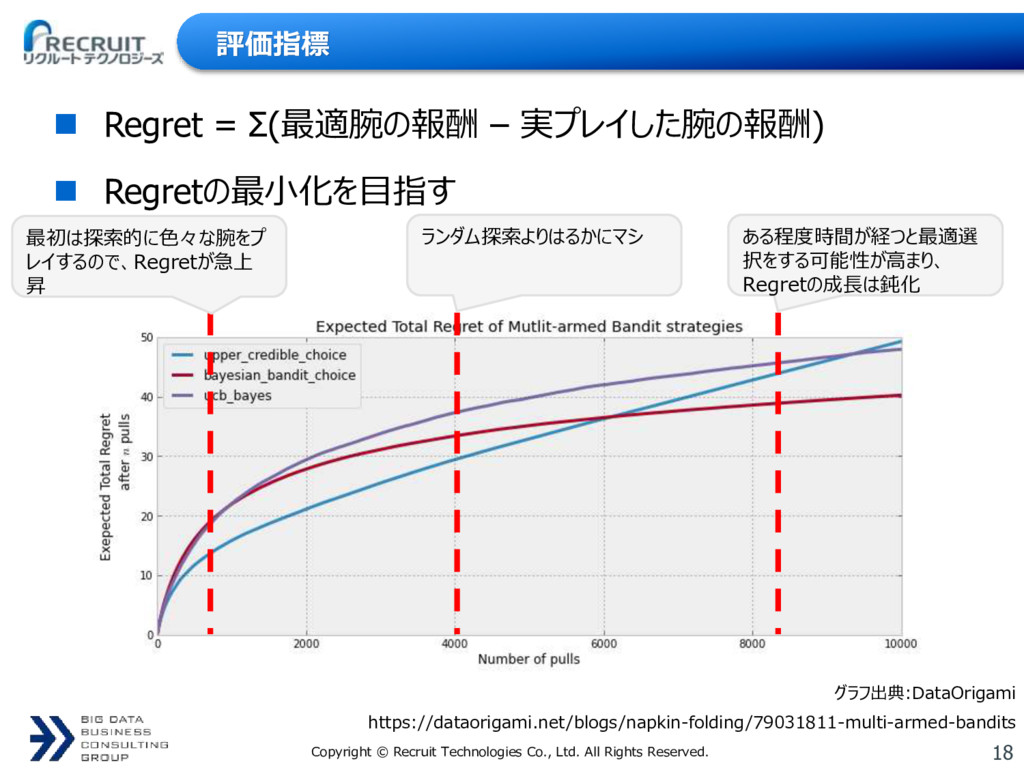{kind=link}
{kind=link}
{kind=link}
{kind=link}
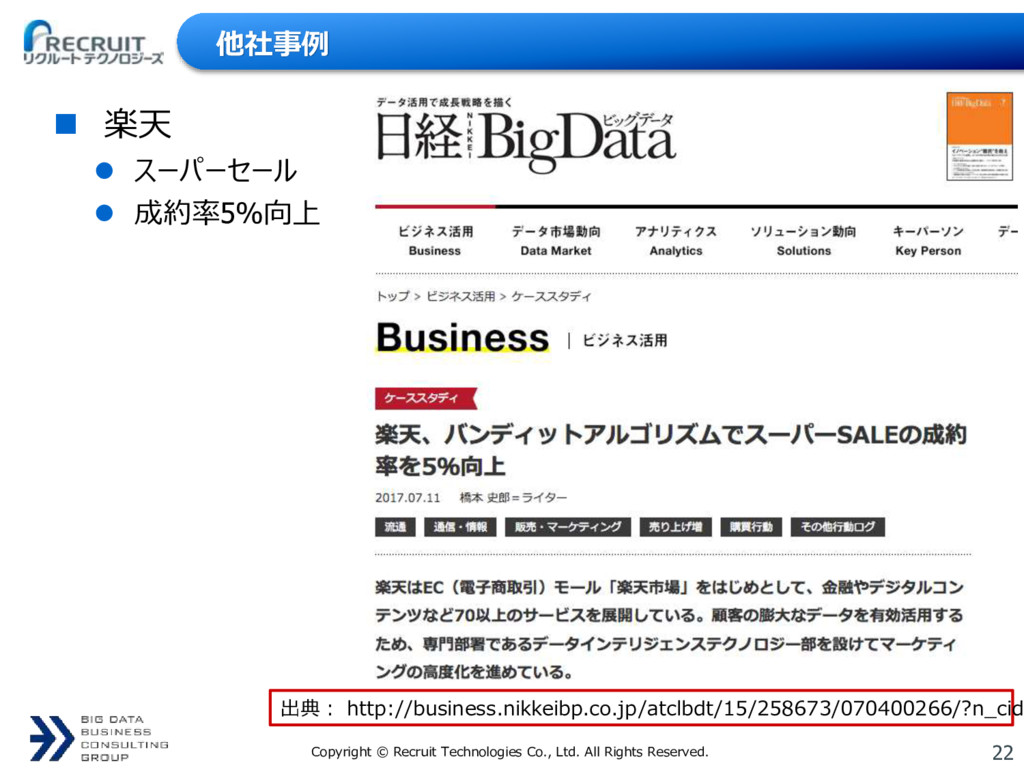{kind=link}
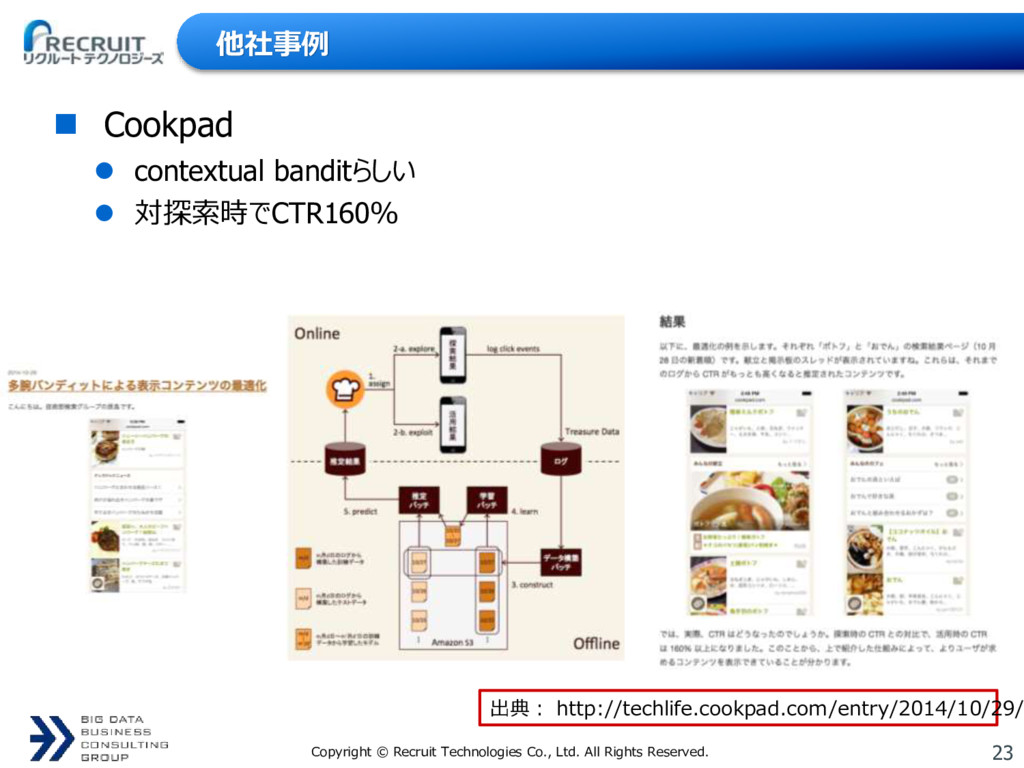{kind=link}
{kind=link}
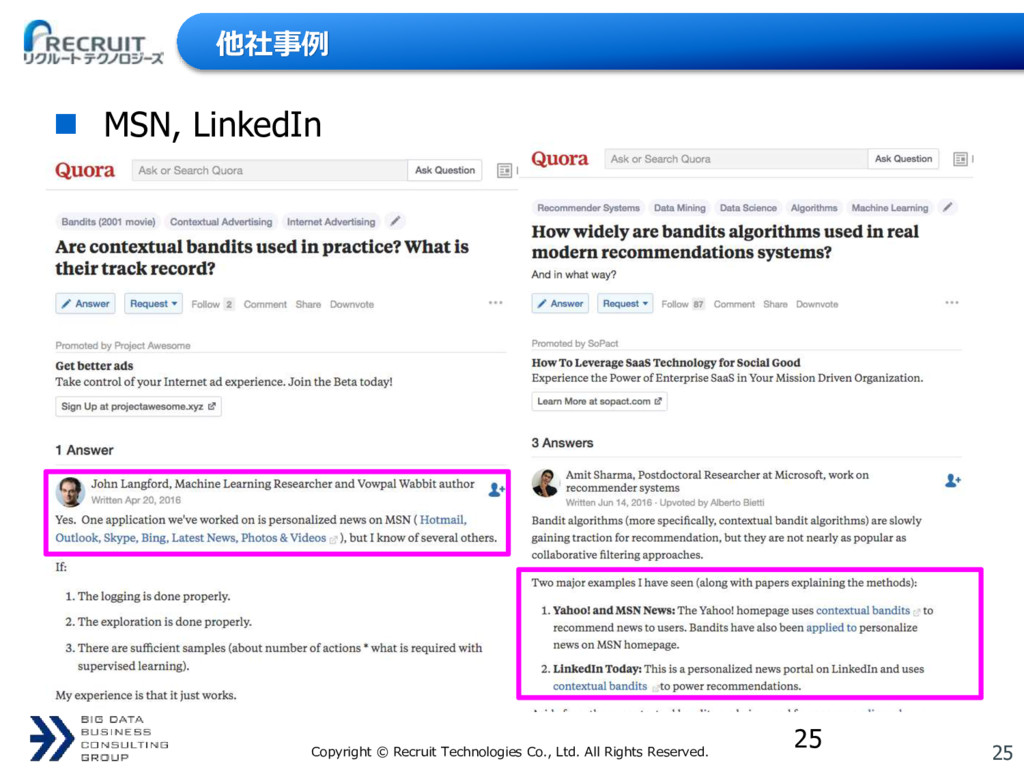{kind=link}
{kind=link}
{kind=link}
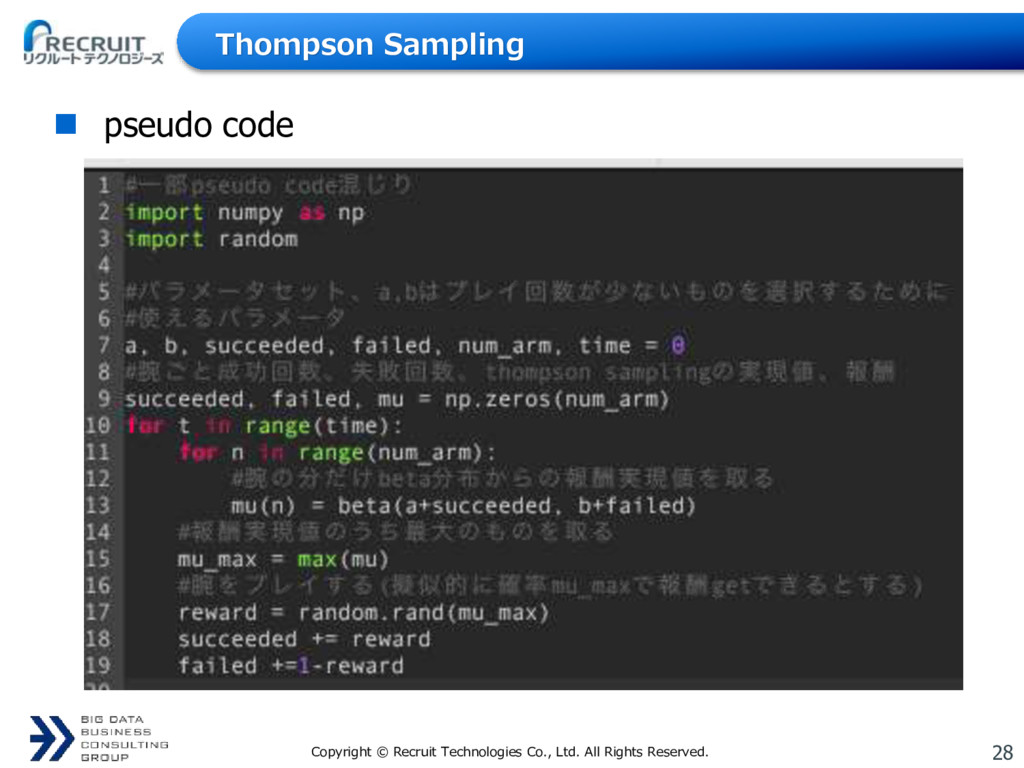{kind=link}
{kind=link}
{kind=link}
{kind=link}
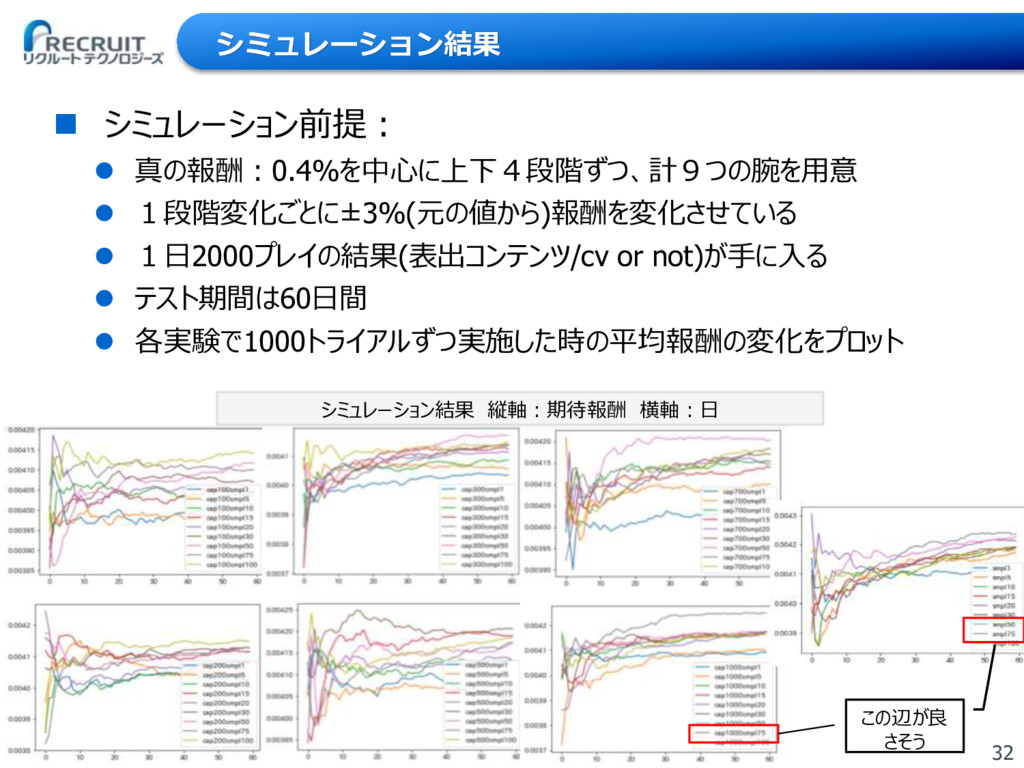{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
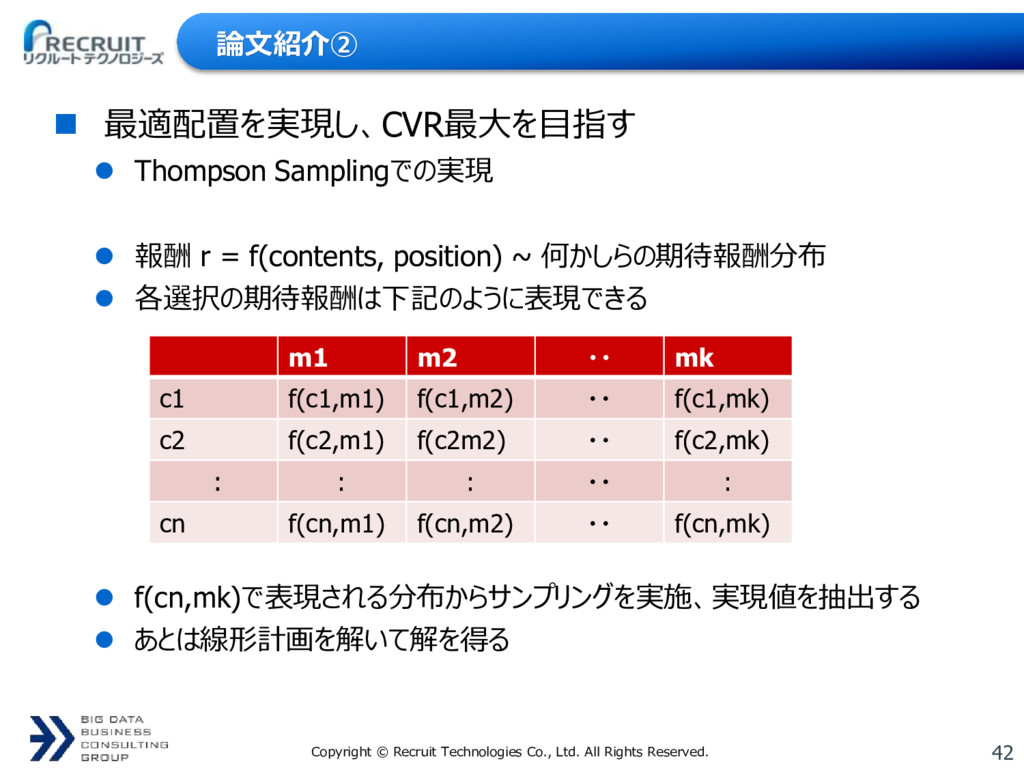
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}