Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Beating State-of-the-art By -10000% @ CIDR Gong...
Search
Reynold Xin
January 07, 2013
Research
160
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Beating State-of-the-art By -10000% @ CIDR Gong Show
I gave a 5-min Gong Show talk at CIDR on my experience with Spark, Shark, and GraphX.
Reynold Xin
January 07, 2013
More Decks by Reynold Xin
See All by Reynold Xin
(Berkeley CS186 guest lecture) Big Data Analytics Systems: What Goes Around Comes Around
rxin
12
2k
Interface Design for Spark Community
rxin
12
1.4k
Spark Committer Night meetup @ NYC
rxin
1
140
Apache Spark: Unified Platform for Big Data
rxin
1
250
Advanced Spark @ Spark Summit 2014
rxin
4
360
Apache Spark: Easier and Faster Big Data
rxin
2
310
GraphX at Spark User Meetup
rxin
0
170
Shark SIGMOD research deck
rxin
2
570
The Spark Ecosystem: Fast and Expressive Big Data Analytics in Scala @ Scala Days 2013
rxin
3
720
Other Decks in Research
See All in Research
typst の使い方:言語学を研究する学生のために
gitomochang
0
510
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
260
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
160
セマンティック通信勉強会 6Gに向けたデバイス間効率的な通信の技術紹介・課題・今後展望
satai
3
230
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
6
2.5k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
640
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
640
Using our influence and power for patient safety
helenbevan
0
370
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
[CV勉強会@関東 CVPR2026] PSDesigner: Automated Graphic Design with a Human-Like Creative Workflow / kantocv 67th CVPR 2026
shunk031
0
150
Featured
See All Featured
Exploring anti-patterns in Rails
aemeredith
3
440
The agentic SEO stack - context over prompts
schlessera
0
850
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
AI: The stuff that nobody shows you
jnunemaker
PRO
8
830
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
How to train your dragon (web standard)
notwaldorf
97
6.7k
Being A Developer After 40
akosma
91
590k
HDC tutorial
michielstock
2
750
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The SEO identity crisis: Don't let AI make you average
varn
0
510
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Transcript
Beating State-of-the-art By -10000% Reynold Xin, AMPLab, UC Berkeley with
help from Joseph Gonzalez, Josh Rosen, Matei Zaharia, Michael Franklin, Scott Shenker, Ion Stoica
Beating State-of-the-art By -10000% NOT A TYPO Reynold Xin, AMPLab,
UC Berkeley with help from Joseph Gonzalez, Josh Rosen, Matei Zaharia, Michael Franklin, Scott Shenker, Ion Stoica
MapReduce deterministic, idempotent tasks fault-tolerance elasticity resource sharing
“The bar for open source software is at historical low.”
“The bar for open source software is at historical low.”
i.e. “This is the right time to do grad school.”
iterative machine learning OLAP strong temporal locality
Does in-memory computation help in petabyte-scale warehouses?
Does in-memory computation help in petabyte-scale warehouses? YES
Spark How to do in-memory computation efficiently in a fault-tolerant
way?
Shark How to do SQL query processing efficiently in “MapReduce”
style SQL on top of Spark Hive compatible (UDF, Type, InputFormat, Metadata)
“You need to beat Hadoop by at least 100X to
publish a paper in 2013.”
“You need to beat Hadoop by at least 100X to
publish a paper in 2013.” i.e. “You should’ve come to grad school 2 years earlier.”
Shark in-memory columnar store dynamic query re-optimization and a lot
of engineering...
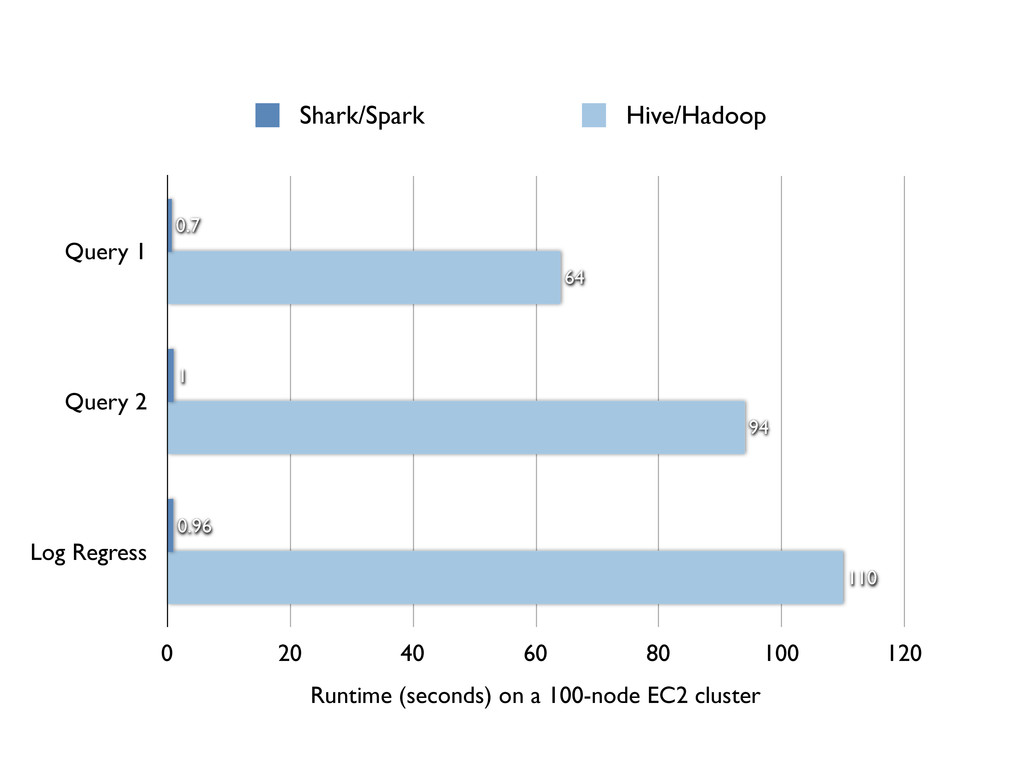
Query 1 Query 2 Log Regress 0 20 40 60
80 100 120 110 94 64 0.96 1 0.7 Runtime (seconds) on a 100-node EC2 cluster Shark/Spark Hive/Hadoop
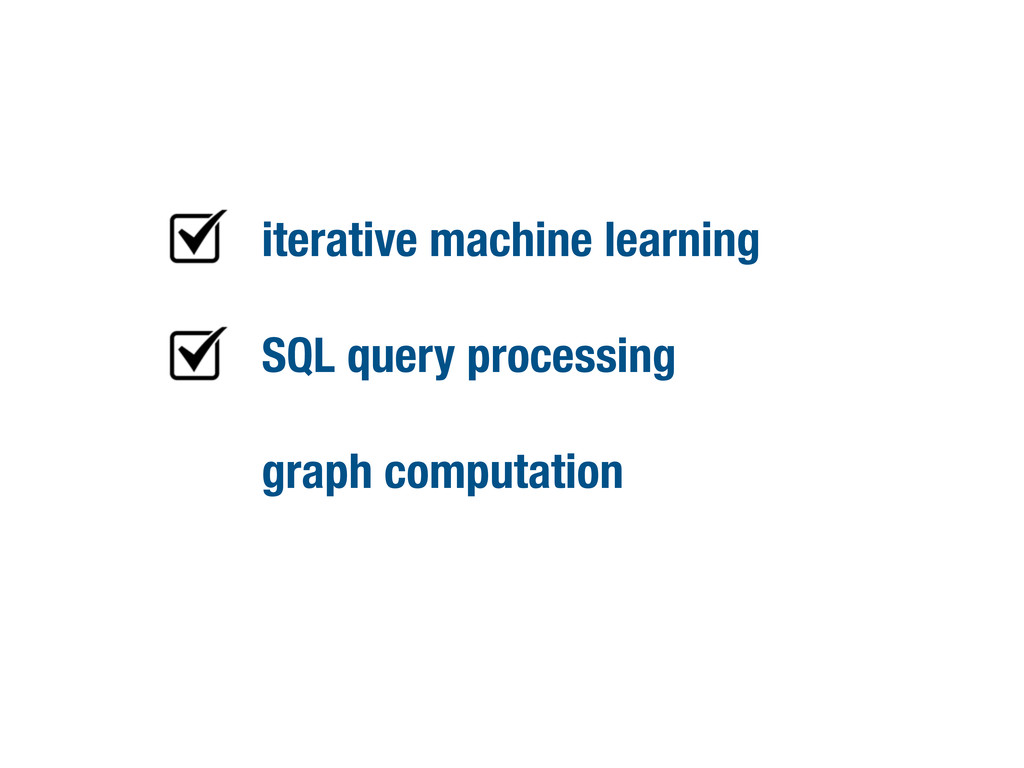
iterative machine learning SQL query processing
iterative machine learning SQL query processing graph computation
GraphLab on Spark
I spent a day pair-programming with Joey Gonzalez and improved
performance by 10X. Not bad for a day of work!
I spent a day pair-programming with Joey Gonzalez and improved
performance by 10X. but I later found out that it is still 10X slower than the latest version of GraphLab :(
A lot of open questions for fault- tolerant, distributed graph
computation. “MapReduce”? Data partitioning? Fault-tolerance? Asynchrony?
iterative machine learning www.spark-project.org SQL query processing shark.cs.berkeley.edu graph computation
www.wait-another-year.com
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}