Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Microsoft Fabricで考える非構造データのAI活用
Search
Ryoma Nagata
March 31, 2026
Technology
1.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Microsoft Fabricで考える非構造データのAI活用
https://sqlserver.connpass.com/event/386300/
登壇資料
Ryoma Nagata
March 31, 2026
More Decks by Ryoma Nagata
See All by Ryoma Nagata
Fabric-cicd によるAzure DevOps デプロイ
ryomaru0825
0
320
Fabric MCPの紹介と使い分け
ryomaru0825
2
400
Microsoft Fabric のワークスペースと容量の設計原則
ryomaru0825
2
810
Microsoft Fabric AI Demo @Tech Boost Summit 2025
ryomaru0825
1
480
忙しい人むけの FabCon Vienna 2025 KeyNote
ryomaru0825
1
230
Microsoft Fabric 攻略ガイド 2.0 (ドラフト)
ryomaru0825
2
2.5k
Microsoft Fabric のネットワーク保護のアップデートについて
ryomaru0825
2
600
Microsoft Analytics Day 2025.7 最新情報ピックアップ・デモ
ryomaru0825
1
140
Microsoft Fabric ガバナンス設計の一歩目を考える
ryomaru0825
3
2.1k
Other Decks in Technology
See All in Technology
最高のシステムプロンプトを作るためにフィードバック機能を導入した話
alchemy1115
1
240
1台から試せる!Edge IoTを使った位置情報の活用設計【SORACOM Discovery 2026】
soracom
PRO
0
110
A Bag-of-Documents Model for Query Specificity
dtunkelang
0
170
【5分でわかる】セーフィー エンジニア向け会社紹介
safie_recruit
0
53k
書籍セキュアAPIについて
riiimparm
0
390
事業成長とAI活用を止めないデータ基盤アーキテクチャの設計思想
hiracky16
0
780
現場をAIで動かす「フィジカル AI」の組み込み設計の考え方【SORACOM Discovery 2026】
soracom
PRO
0
150
13年運用タイトルのサーバーサイドが辿り着いた現在地 ― モンスターストライクにおける技術・組織・AI活用から得た知見
mixi_engineers
PRO
1
330
NetBoxを利用した作業効率化の試み_NetDevNight4
tnoha
0
390
AI駆動開発は個人技からチーム戦へ:組織でAIを使いこなすための実践設計
moongift
PRO
0
320
AIがAPIを書く時代に、私たちは何を設計すべきか
nagix
0
170
PLaMo 3.0 Primeの事後学習
pfn
PRO
0
200
Featured
See All Featured
Thoughts on Productivity
jonyablonski
76
5.3k
The SEO Collaboration Effect
kristinabergwall1
1
510
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
640
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
sira's awesome portfolio website redesign presentation
elsirapls
0
310
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Why Mistakes Are the Best Teachers: Turning Failure into a Pathway for Growth
auna
0
190
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
230
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Transcript
Microsoft MVP for Data Platform 永田 亮磨 (ZEAL CORPORATION) X:
@ryomaru0825 Linkedin: ryoma-nagata-0825 Qiita: ryoma-nagata Microsoft Fabricで考える 非構造データのAI活用
AGENDA メダリオンアーキテクチャの非構造化データへの適用 AI ユースケースに対するデータストアの適切な選択 Microsoft Fabric における
AI ユースケースの構成パターン デモ:領収書分析エージェント
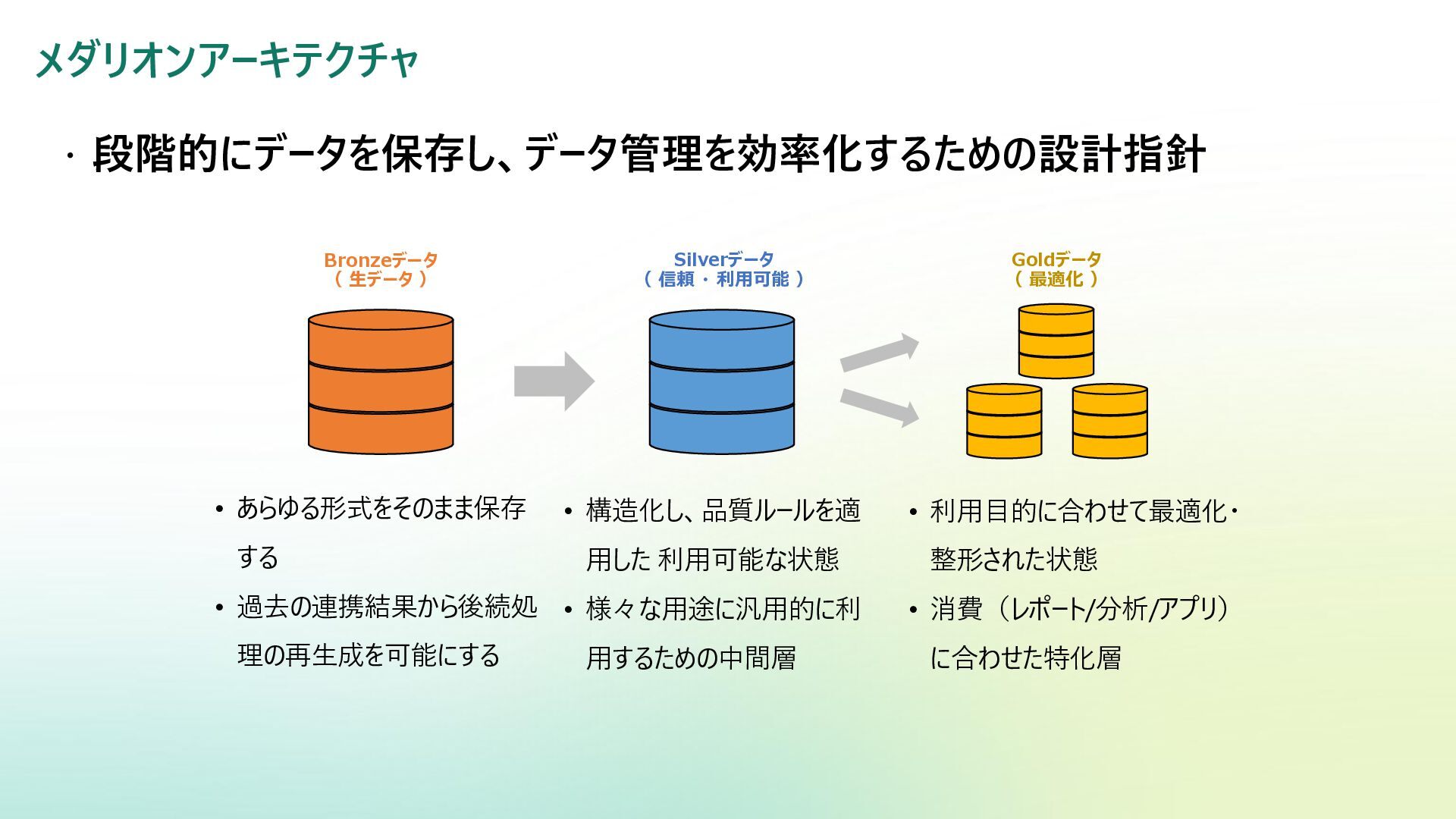
メダリオンアーキテクチャ 段階的にデータを保存し、データ管理を効率化するための設計指針 Bronzeデータ ( 生データ ) Goldデータ ( 最適化
) Silverデータ ( 信頼 ・ 利用可能 ) • あらゆる形式をそのまま保存 する • 過去の連携結果から後続処 理の再生成を可能にする • 構造化し、品質ルールを適 用した 利用可能な状態 • 様々な用途に汎用的に利 用するための中間層 • 利用目的に合わせて最適化・ 整形された状態 • 消費(レポート/分析/アプリ) に合わせた特化層
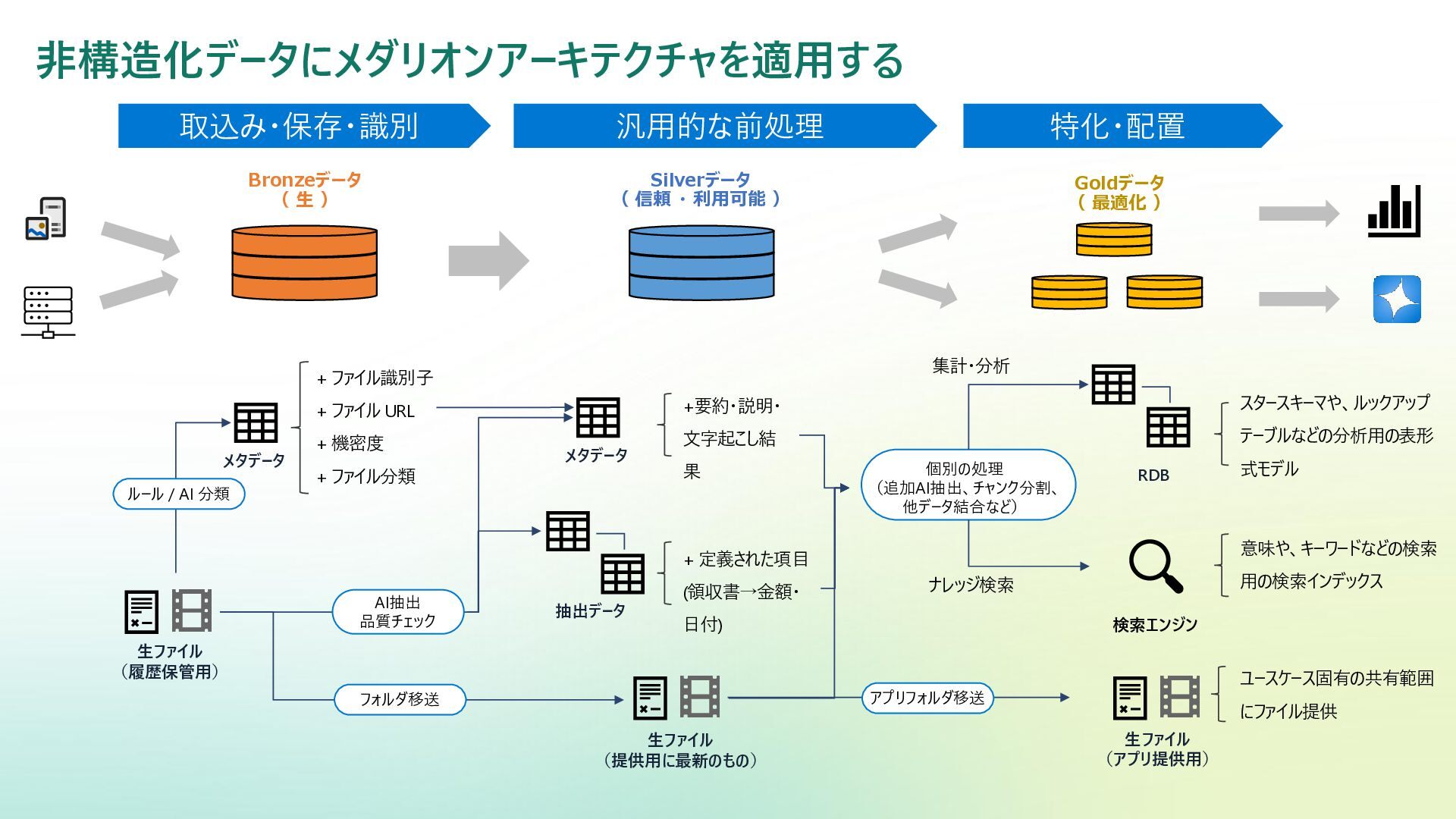
非構造化データにメダリオンアーキテクチャを適用する Bronzeデータ ( 生 ) Goldデータ ( 最適化 ) Silverデータ
( 信頼 ・ 利用可能 ) 取込み・保存・識別 汎用的な前処理 特化・配置 メタデータ 生ファイル (履歴保管用) + ファイル識別子 + ファイル URL + 機密度 + ファイル分類 生ファイル (提供用に最新のもの) RDB 集計・分析 抽出データ + 定義された項目 (領収書→金額・ 日付) 検索エンジン 意味や、キーワードなどの検索 用の検索インデックス 生ファイル (アプリ提供用) ユースケース固有の共有範囲 にファイル提供 メタデータ +要約・説明・ 文字起こし結 果 ルール / AI 分類 AI抽出 品質チェック フォルダ移送 アプリフォルダ移送 個別の処理 (追加AI抽出、チャンク分割、 他データ結合など) ナレッジ検索 スタースキーマや、ルックアップ テーブルなどの分析用の表形 式モデル
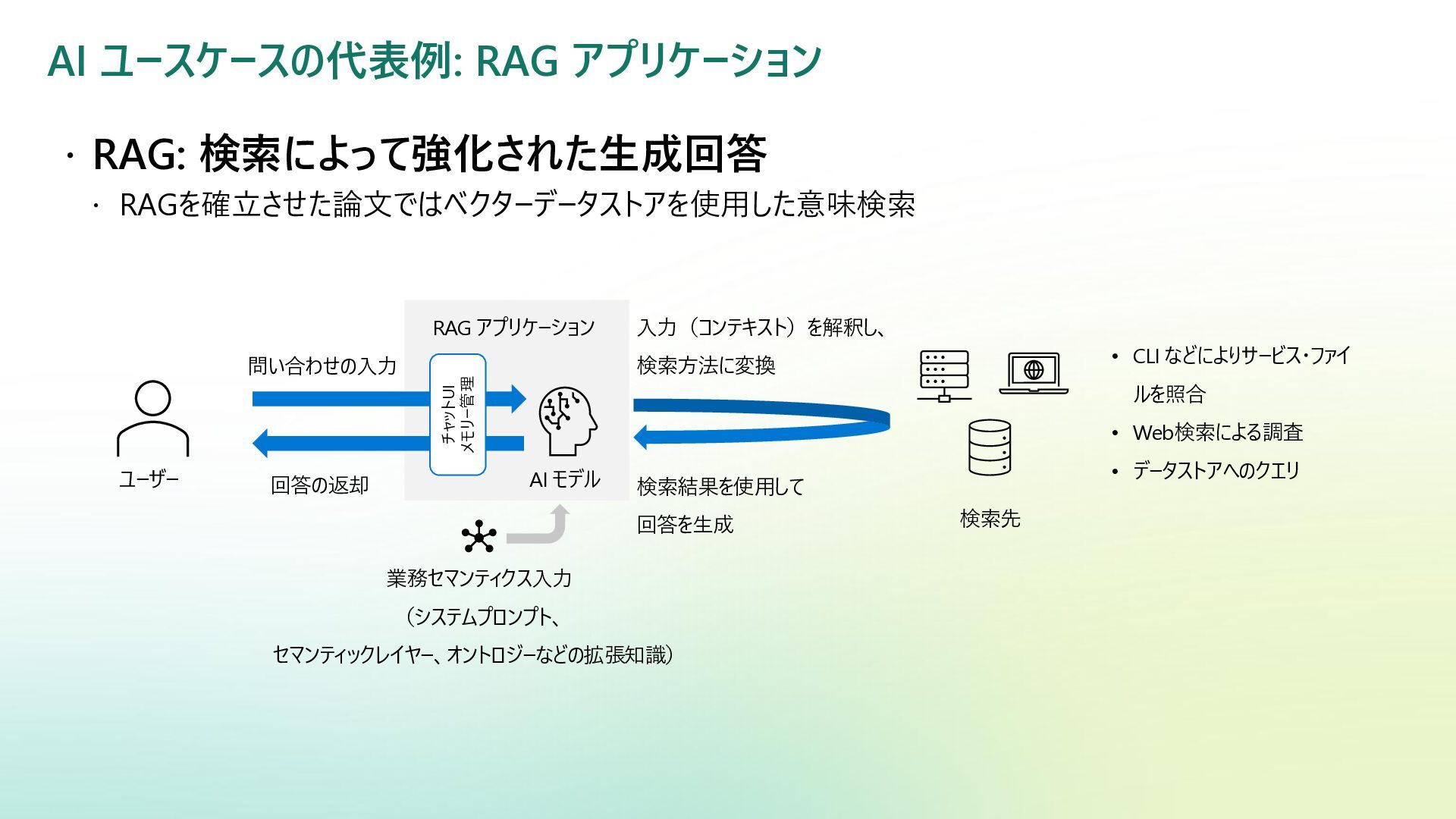
AI ユースケースの代表例: RAG アプリケーション RAG: 検索によって強化された生成回答 RAGを確立させた論文ではベクターデータストアを使用した意味検索 •
CLI などによりサービス・ファイ ルを照合 • Web検索による調査 • データストアへのクエリ z 問い合わせの入力 回答の返却 入力(コンテキスト)を解釈し、 検索方法に変換 検索結果を使用して 回答を生成 業務セマンティクス入力 (システムプロンプト、 セマンティックレイヤー、オントロジーなどの拡張知識) AI モデル ユーザー 検索先 RAG アプリケーション チャットUI メモリー管理
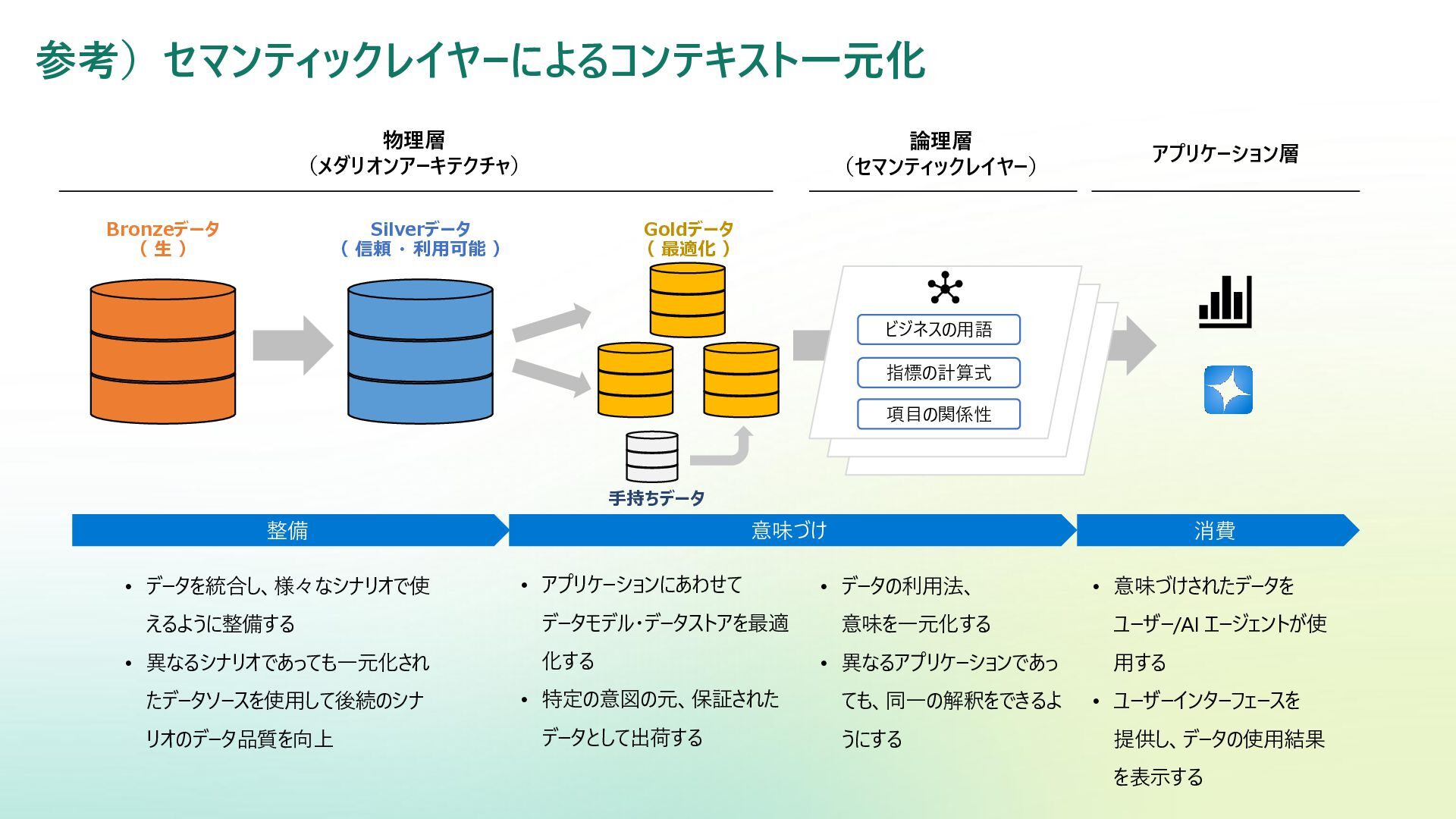
参考)セマンティックレイヤーによるコンテキスト一元化 Bronzeデータ ( 生 ) Goldデータ ( 最適化 ) Silverデータ
( 信頼 ・ 利用可能 ) 論理層 (セマンティックレイヤー) 物理層 (メダリオンアーキテクチャ) ビジネスの用語 指標の計算式 項目の関係性 アプリケーション層 手持ちデータ • データの利用法、 意味を一元化する • 異なるアプリケーションであっ ても、同一の解釈をできるよ うにする • アプリケーションにあわせて データモデル・データストアを最適 化する • 特定の意図の元、保証された データとして出荷する • データを統合し、様々なシナリオで使 えるように整備する • 異なるシナリオであっても一元化され たデータソースを使用して後続のシナ リオのデータ品質を向上 整備 意味づけ 消費 • 意味づけされたデータを ユーザー/AI エージェントが使 用する • ユーザーインターフェースを 提供し、データの使用結果 を表示する
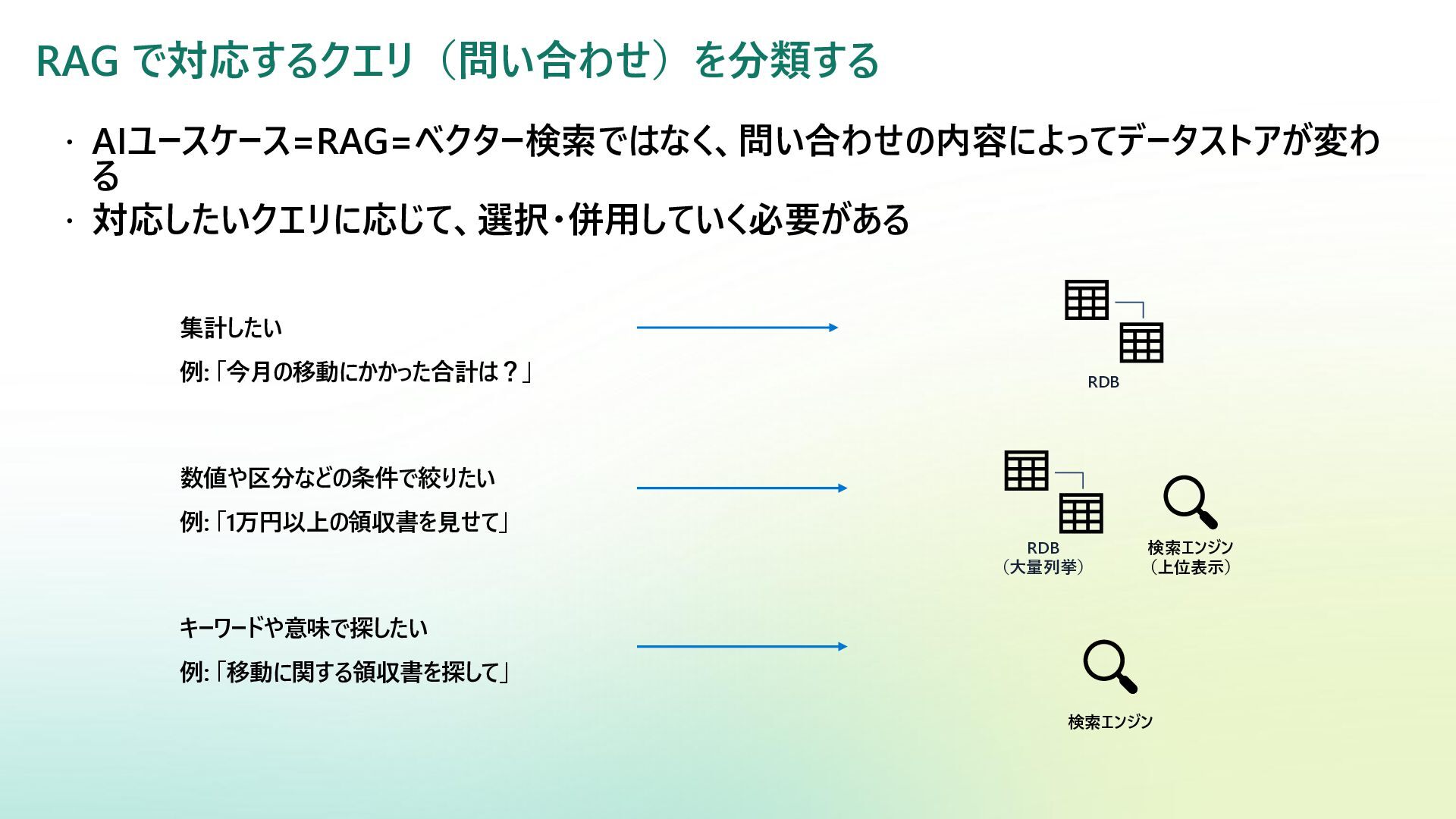
RAG で対応するクエリ(問い合わせ)を分類する AIユースケース=RAG=ベクター検索ではなく、問い合わせの内容によってデータストアが変わ る 対応したいクエリに応じて、選択・併用していく必要がある 集計したい 例: 「今月の移動にかかった合計は?」
数値や区分などの条件で絞りたい 例: 「1万円以上の領収書を見せて」 キーワードや意味で探したい 例: 「移動に関する領収書を探して」 RDB (大量列挙) 検索エンジン RDB 検索エンジン (上位表示)
RAG の内容によるデータストア選択の重要性 – RDB vs 検索エンジン 分析中心→RDB ダッシュボードや集計は原則
RDB で対応する必要がある。 検索中心→検索エンジン 百~数千程度の小規模で精度の出しやすいナレッジ検索であれば、 RDB上で要約や単語レベルの埋め込みを作成して対応可 能だが、高精度を目指す際には検索エンジンの利用が重要となる 特にナレッジ検索シナリオでは全文検索とベクター検索のハイブリッド+リランキング(質問との合致度)への対応が精度向上で 重要となる データストア エージェント例 得意なクエリ 苦手なクエリ データモデル分類 意味検索の実装 ※製品依存 RDB 集計分析 列集計、 一致フィルタによる検索や 分析 曖昧な一致条件 リレーショナル (表形式) ベクター列に対する近似メ トリックスコアのソート 検索エンジン ナレッジ検索 キーワード検索、 意味検索 厳密な列集計 非リレーショナル (検索インデックス) ベクターフィールドに対する 近似メトリックスコアのソー ト +検索文とのリランキング によるソート • データ モデルについて - Azure Architecture Center | Microsoft Learn • Microsoft Fabric 攻略ガイド 2.0 (ドラフト) - Speaker Deck
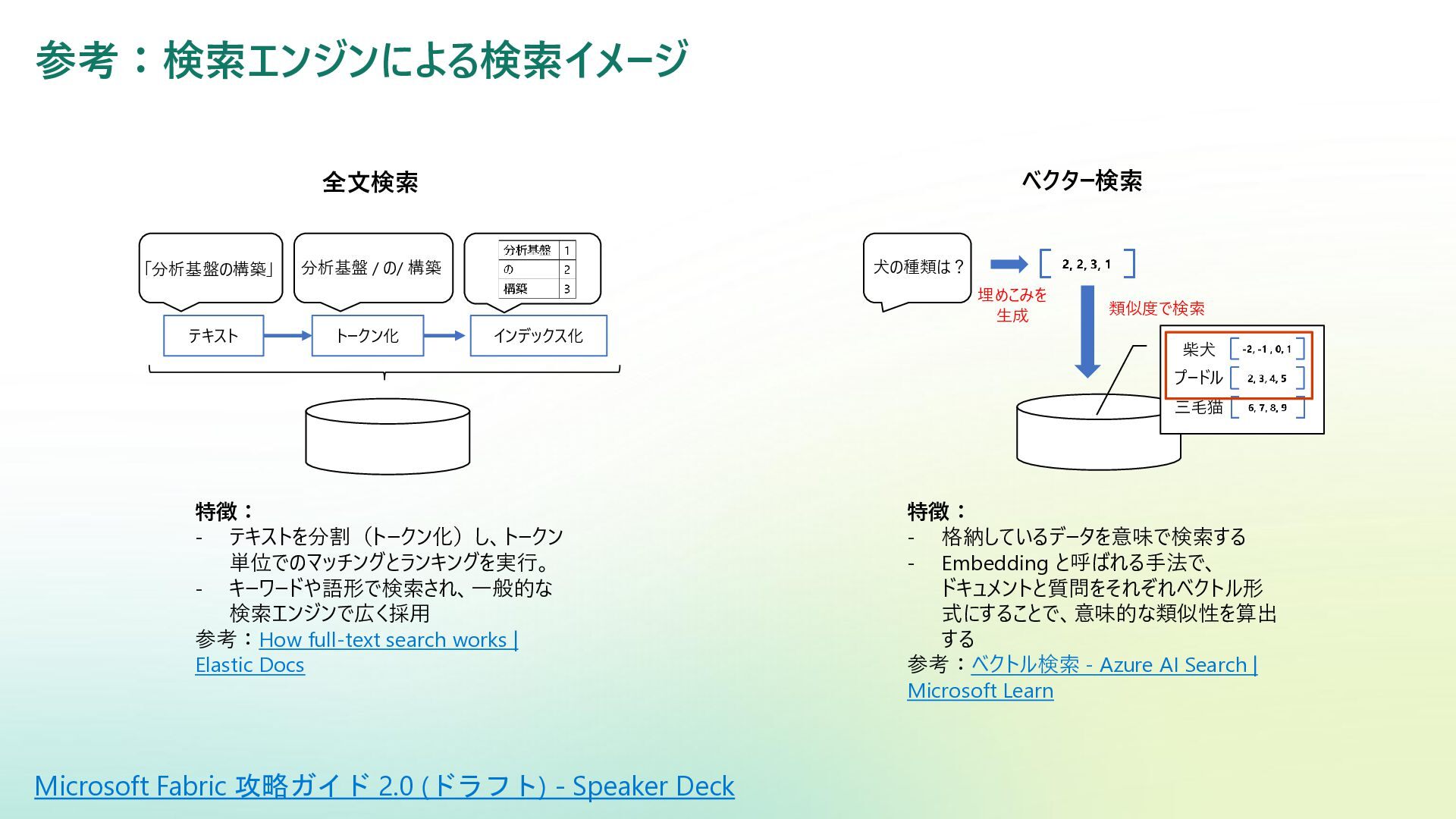
参考:検索エンジンによる検索イメージ 全文検索 ベクター検索 特徴: - テキストを分割(トークン化)し、トークン 単位でのマッチングとランキングを実行。 - キーワードや語形で検索され、一般的な 検索エンジンで広く採用
参考:How full-text search works | Elastic Docs 特徴: - 格納しているデータを意味で検索する - Embedding と呼ばれる手法で、 ドキュメントと質問をそれぞれベクトル形 式にすることで、意味的な類似性を算出 する 参考:ベクトル検索 - Azure AI Search | Microsoft Learn テキスト 分析基盤 / の/ 構築 トークン化 インデックス化 「分析基盤の構築」 柴犬 プードル 三毛猫 犬の種類は? 類似度で検索 埋めこみを 生成 Microsoft Fabric 攻略ガイド 2.0 (ドラフト) - Speaker Deck
その他のデータストア その他にも様々なクエリ用途によりデータストアの使い分けが必要 データストア エージェント例 得意なクエリ 苦手なクエリ データモデル分類 意味検索の実装 ※製品依存
時系列DB ログ分析エージェント 時間を条件にした レコードの分析 多数テーブルの結合 非リレーショナル (追記型の時刻付きイベ ント) ベクター列に対する近似メ トリックスコアのソート ドキュメント 製品リコメンド オブジェクト単位の 引き当て ドキュメント横断の集計や、 多数の結合 非リレーショナル ( json などの不定の階 層構造) ベクタープロパティに対する 近似メトリックスコアのソー ト グラフ ネットワーク分析 深いリレーションシップをたど る検索 表形式の集計や、 全文検索 非リレーショナル (ノードとエッジによる関係 構造) ベクタープロパティに対する 近似メトリックスコアのソー ト • データ モデルについて - Azure Architecture Center | Microsoft Learn • Microsoft Fabric 攻略ガイド 2.0 (ドラフト) - Speaker Deck
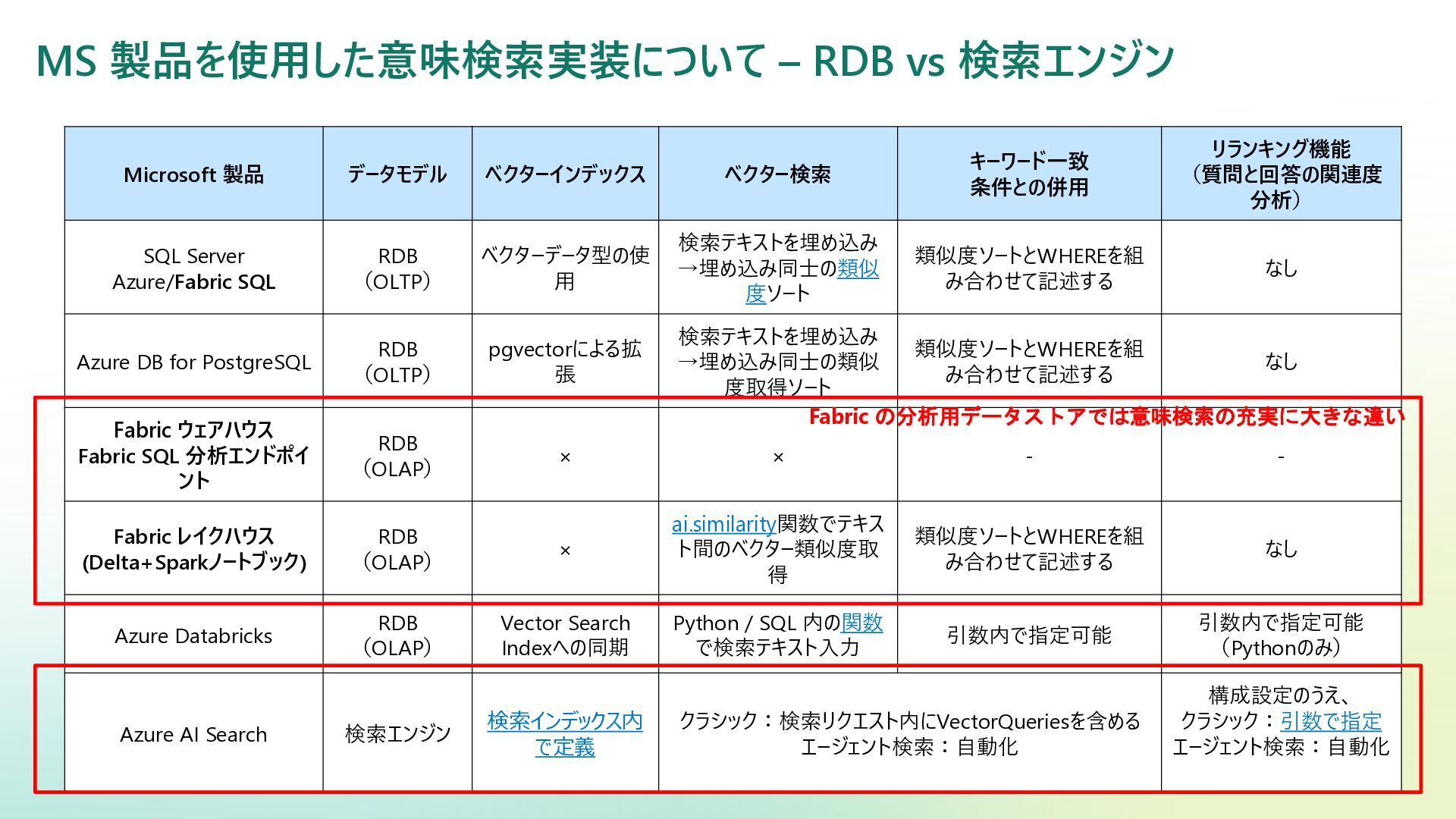
MS 製品を使用した意味検索実装について – RDB vs 検索エンジン Microsoft 製品 データモデル ベクターインデックス
ベクター検索 キーワード一致 条件との併用 リランキング機能 (質問と回答の関連度 分析) SQL Server Azure/Fabric SQL RDB (OLTP) ベクターデータ型の使 用 検索テキストを埋め込み →埋め込み同士の類似 度ソート 類似度ソートとWHEREを組 み合わせて記述する なし Azure DB for PostgreSQL RDB (OLTP) pgvectorによる拡 張 検索テキストを埋め込み →埋め込み同士の類似 度取得ソート 類似度ソートとWHEREを組 み合わせて記述する なし Fabric ウェアハウス Fabric SQL 分析エンドポイ ント RDB (OLAP) × × - - Fabric レイクハウス (Delta+Sparkノートブック) RDB (OLAP) × ai.similarity関数でテキス ト間のベクター類似度取 得 類似度ソートとWHEREを組 み合わせて記述する なし Azure Databricks RDB (OLAP) Vector Search Indexへの同期 Python / SQL 内の関数 で検索テキスト入力 引数内で指定可能 引数内で指定可能 (Pythonのみ) Azure AI Search 検索エンジン 検索インデックス内 で定義 クラシック:検索リクエスト内にVectorQueriesを含める エージェント検索:自動化 構成設定のうえ、 クラシック:引数で指定 エージェント検索:自動化 Fabric の分析用データストアでは意味検索の充実に大きな違い
Agentic retrieval in Azure AI Search エージェントの検索ワークフローを一本化する機能(Foundry IQの中核)
ナレッジベースのワークフロー クエリ計画:スペルミスの修正、クエリ対象ソースの選定、サブクエリの分割 並列クエリ実行:ナレッジソースに応じた検索を実行する ナレッジソース:Azure AI Search内のインデックス(ハイブリッド検索)、Web・SharePointなどのリモート検索(Copilot 検索API) 回答生成:生の検索結果またはLLMによる生成回答を返却する 構成したナレッジベースはMCPツールとしてエージェントから利用可能 エージェント取得の概要 - Azure AI Search | Microsoft Learn
MS 製品を使用した意味検索実装について -その他のデータストア Microsoft 製品 データモデル ベクターインデックス ベクター検索 ハイブリッド検索 リランキング機能
(質問と回答の関連 度分析) Azure Data Explorer Fabric イベントハウス 時系列 Dynamicデータタイプの利 用 検索テキストを埋め込 み →埋め込み同士の類 似度ソート 類似度ソートとWHERE を組み合わせて記述す る なし Azure/Fabric CosmosDB ドキュメント ベクタープロパティの使用 検索テキストを埋め込 み →埋め込み同士の類 似度ソート ハイブリッド検索用イン デックスを作成する プライベートプレビュー中 Fabric Graph グラフ × × - -
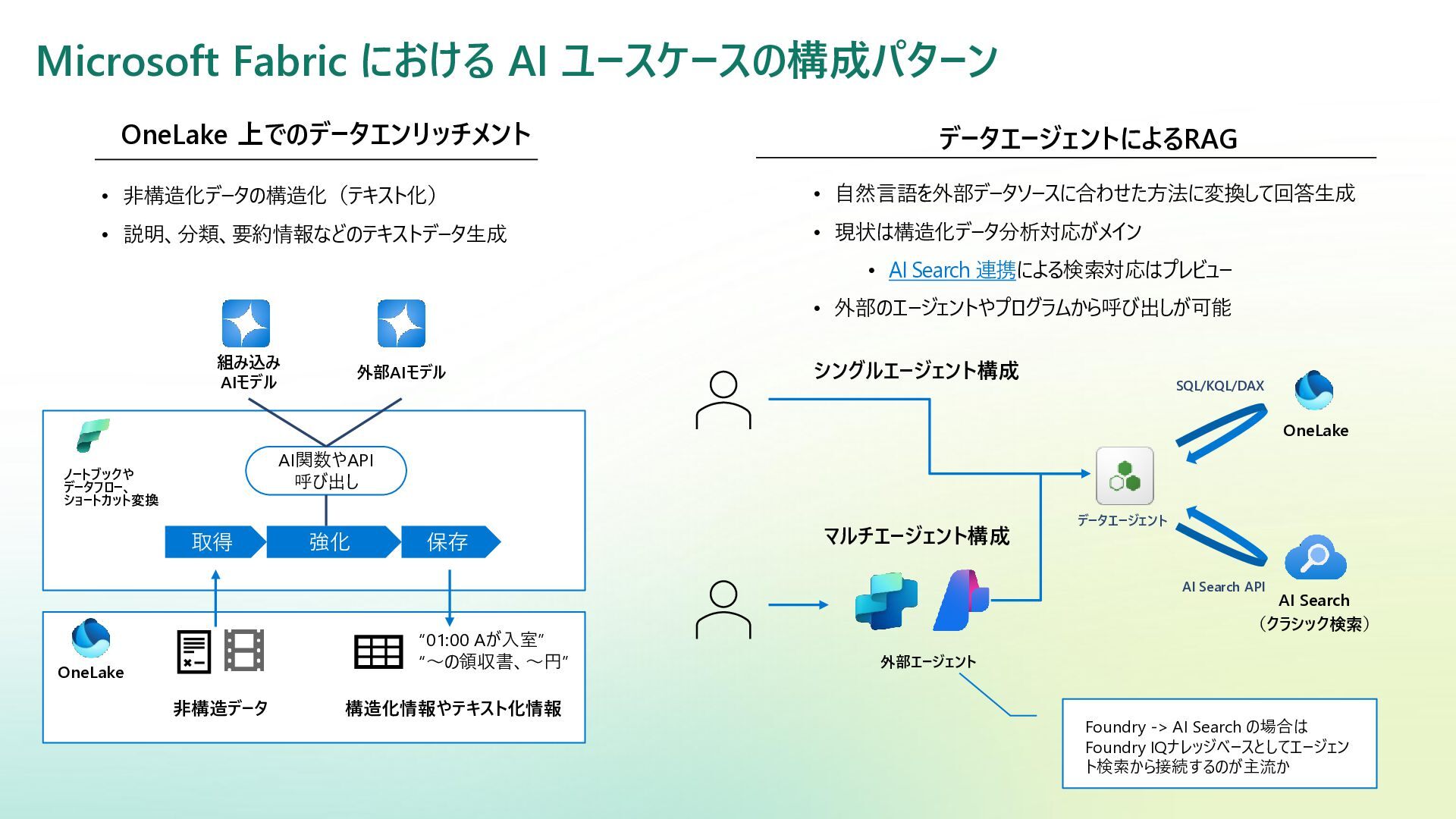
マルチエージェント構成 Microsoft Fabric における AI ユースケースの構成パターン ノートブックや データフロー、 ショートカット変換 組み込み
AIモデル 外部AIモデル 取得 保存 強化 AI関数やAPI 呼び出し “01:00 Aが入室” “~の領収書、~円” 構造化情報やテキスト化情報 非構造データ OneLake 上でのデータエンリッチメント OneLake データエージェントによるRAG データエージェント 外部エージェント OneLake AI Search (クラシック検索) SQL/KQL/DAX AI Search API シングルエージェント構成 • 非構造化データの構造化(テキスト化) • 説明、分類、要約情報などのテキストデータ生成 • 自然言語を外部データソースに合わせた方法に変換して回答生成 • 現状は構造化データ分析対応がメイン • AI Search 連携による検索対応はプレビュー • 外部のエージェントやプログラムから呼び出しが可能 Foundry -> AI Search の場合は Foundry IQナレッジベースとしてエージェン ト検索から接続するのが主流か
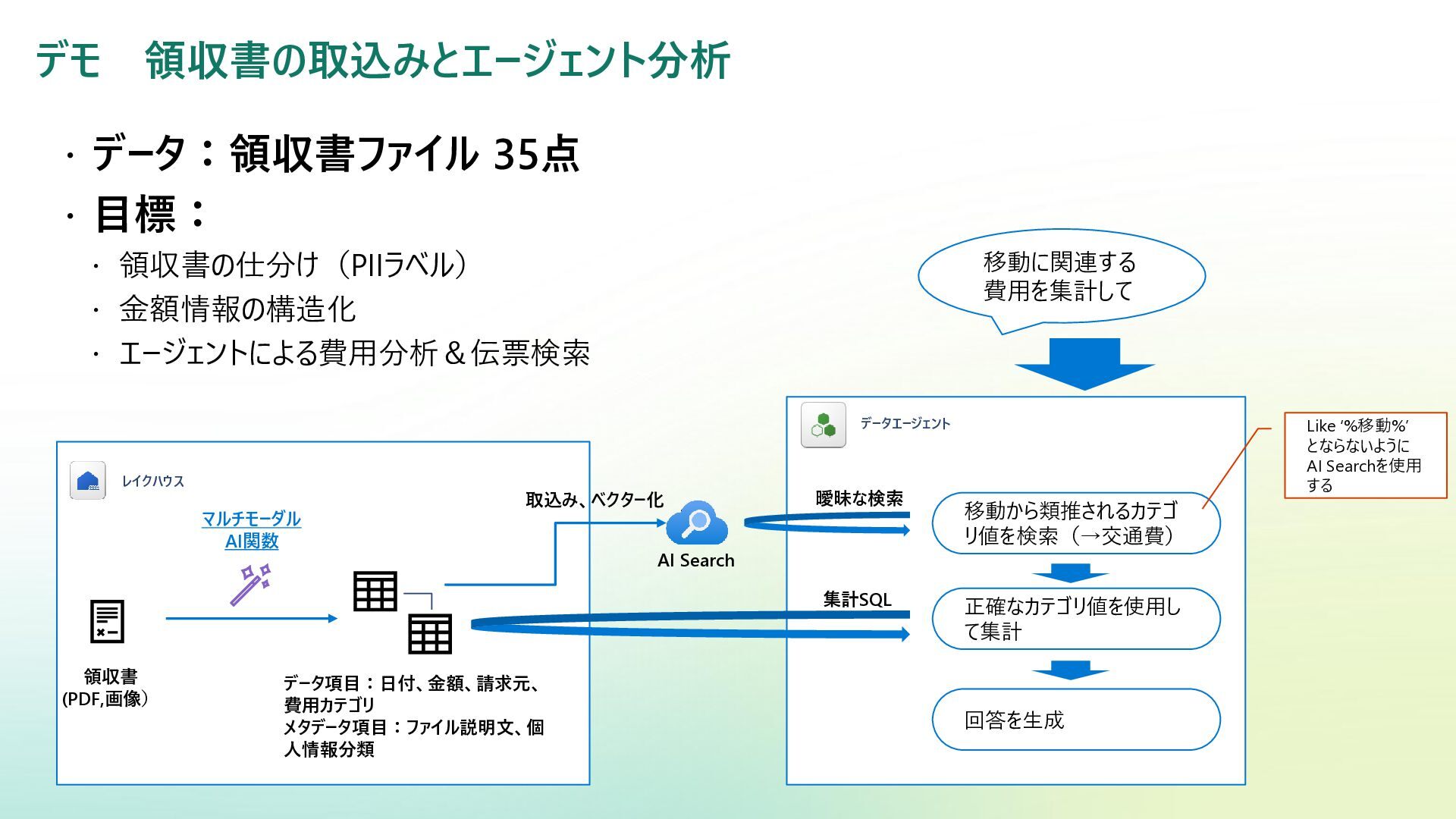
デモ 領収書の取込みとエージェント分析 データ:領収書ファイル 35点 目標: 領収書の仕分け(PIIラベル)
金額情報の構造化 エージェントによる費用分析&伝票検索 領収書 (PDF,画像) データ項目:日付、金額、請求元、 費用カテゴリ メタデータ項目:ファイル説明文、個 人情報分類 マルチモーダル AI関数 取込み、ベクター化 データエージェント レイクハウス AI Search 移動に関連する 費用を集計して 移動から類推されるカテゴ リ値を検索(→交通費) 正確なカテゴリ値を使用し て集計 曖昧な検索 集計SQL 回答を生成 Like ‘%移動%’ とならないように AI Searchを使用 する
狙った課題 問い合わせ側の語彙と、集計対象のテーブルで設定されているカテゴリ値の ギャップ 例:ユーザーは 「移動」 という言葉で問い合わせ -> テーブル上では
L1: 交通費 / L2: タクシー のように管理 「移動」→「交通費」 のように正規のカテゴリ値へ変換したうえで集計する必要がある。 初期案:AISearch で該当レシートIDを取得→DataAgentの ID in (~)で使ってもらう スケールしない。レシート数が多いと、SQLへのID入力がうまくいく気がしない 今回の案:集計のカテゴリマスタをAISearch に取込して正規カテゴリ変換をAI Search にまかせる AI Search 使うほどではない構成になる気もするけど、リランキング含めた該当伝票の検索にも使える構成だからOKとする
FAQ アクセスするエージェントの使い分けは? 集計を必要とするならデータエージェント Foundry などの外部エージェントはデータエージェントを専門家として聞きに行く立場として利用 ナレッジ検索中心なら
Foundry 側のエージェントのみでOK なぜデータエージェントが必要? 実行可能なSQLを検証するなど、分析を実行するための機能がビルトインされている 意味定義を再利用することができる 複数外部エージェントがデータの利用方法をそれぞれ定義した場合→解釈のゆれ データエージェントによるデータソース説明の単一化→どの外部エージェントから依頼をうけても一致した解釈で分析 +セマンティックモデルやオントロジー、グラフによりデータソース側で説明を定義すると複数のデータエージェントが増える場合も対応可能 OneLake の情報をAI Searchに格納した場合にどちらのエージェントがアクセスするべ き? SQL分析に必要な情報であればデータエージェントに直接与えられるほうがよい オーケストレーションエージェント側で把握しておくべき内容であればデータエージェントだけがアクセスできるのは不適
今後扱わなかった課題など チャンク分割 同一画像に複数領収書が含まれる場合、複数ドキュメントとして分割する必要がある 画像を切り取るまではいかなくとも、書き起こし時点で配列化して複数レコードに分割させるなどの粒度調整が必要になる また、その場合のID発番方法など検討事項は多い
領収書はチャンク単位がわかりやすいが、QAや不具合対応のようなシナリオでは、長いドキュメントを扱う可能 性もあるため、よりエージェントとしての責務分離が重要になりそう Azure AI Search インデックスへの取込 SQL コネクタは使用できなかったため、サポートされているCSV連携とした。 大規模データだとどうなるか、また、連携ファイルを重複して持つことになるため二重持ち問題も。
その他参考 RAG ソリューションの設計と開発 - Azure Architecture Center | Microsoft
Learn Building a RAG application with Microsoft Fabric Unstructured Data Management at Scale | by Piethein Strengholt | Medium AI-Readyを目指した非構造化データのメダリオンアーキテクチャ - Speaker Deck
Thank you !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}