に、運用上のメトリックをインストルメント化するようア プリケーションをコーディングしてください。 システムの 枠を越えてイベントを相互に関連付けることができる一般 的かつ一貫性のあるスキーマを使用しましょう。 Red Method 、USE Method 、The Four Golden Signals は、システムの正常性と状態を追跡する標準的な手法で す。
takes to service a request) ◦ Traffic(A measure of how much demand is being placed on your system) ◦ Errors(The rate of requests that fail) ◦ Saturation(How "full" your service is) • ユーザーが直接利用するシステムで、メトリクスを4つだけ計測 できるなら、この4つに集中してください。 https://landing.google.com/sre/sre-book/chapters/monitoring-distributed-systems/#xref_monitoring_ golden-signals
resource was busy) ◦ Saturation (amount of work resource has to do, often queue length) ◦ Errors (count of error events) • サーバやNWに用いられることが多い ◦ CPU、メモリの使用率 ◦ ストレージの容量、Read/Writeキューの長さ ◦ messageログに出ているエラー • 確かに有用なんだけど、もうちょっとサービス指向のが欲しい The RED Method: How to Instrument Your Services https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
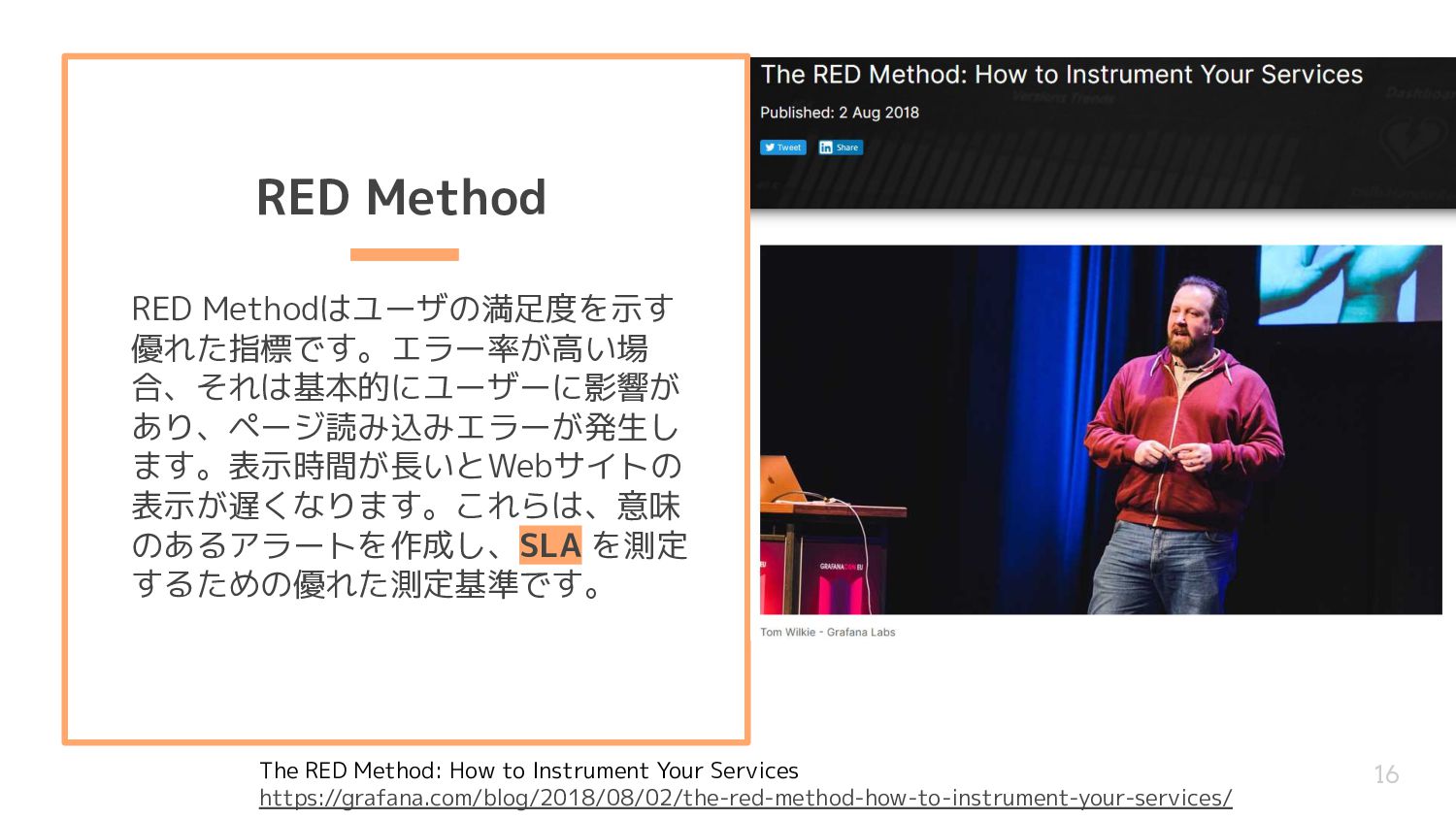
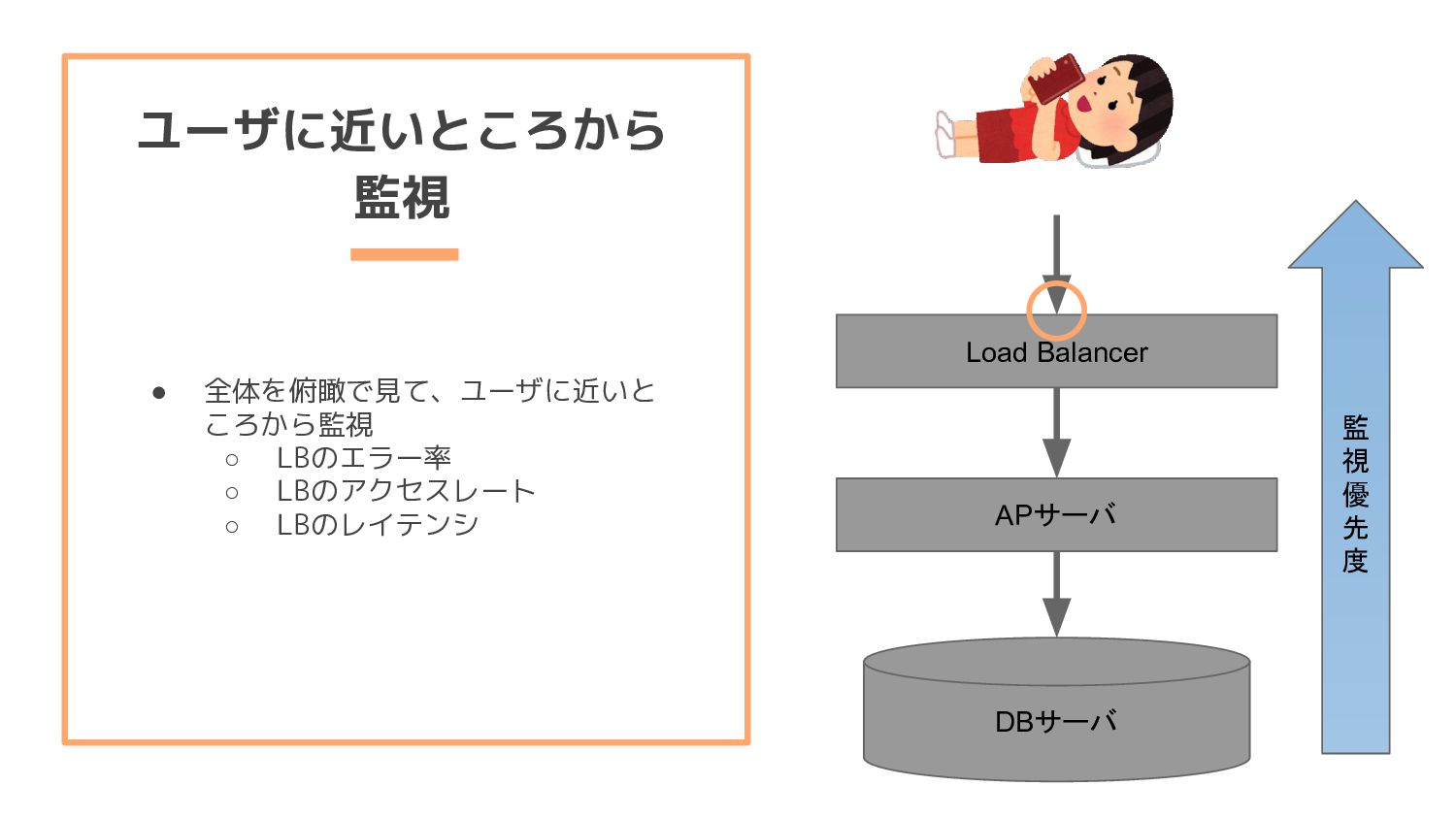
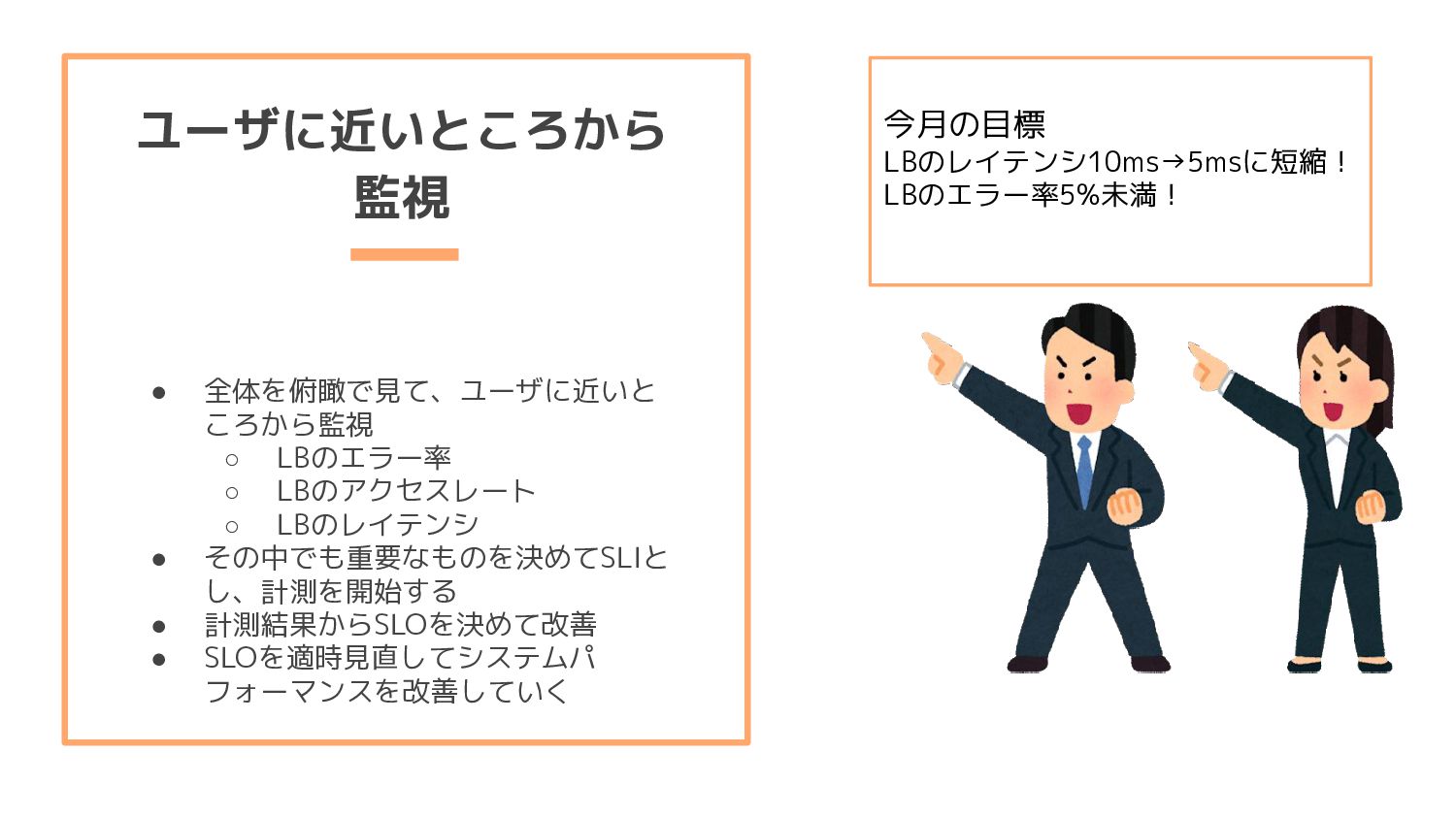
per second) ◦ Errors (the number of those requests that are failing) ◦ Duration (the amount of time those requests take) • USE Method に比べてBlackbox的 • Webサービスの外形監視と相性が良い。こういう値の方が気にな りませんか? ◦ 毎分当たりのリクエスト数 ◦ 5xxエラーの数 ◦ どのくらいの時間でリクエストを捌いてるのか The RED Method: How to Instrument Your Services https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
を測定 するための優れた測定基準です。 16 The RED Method: How to Instrument Your Services https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
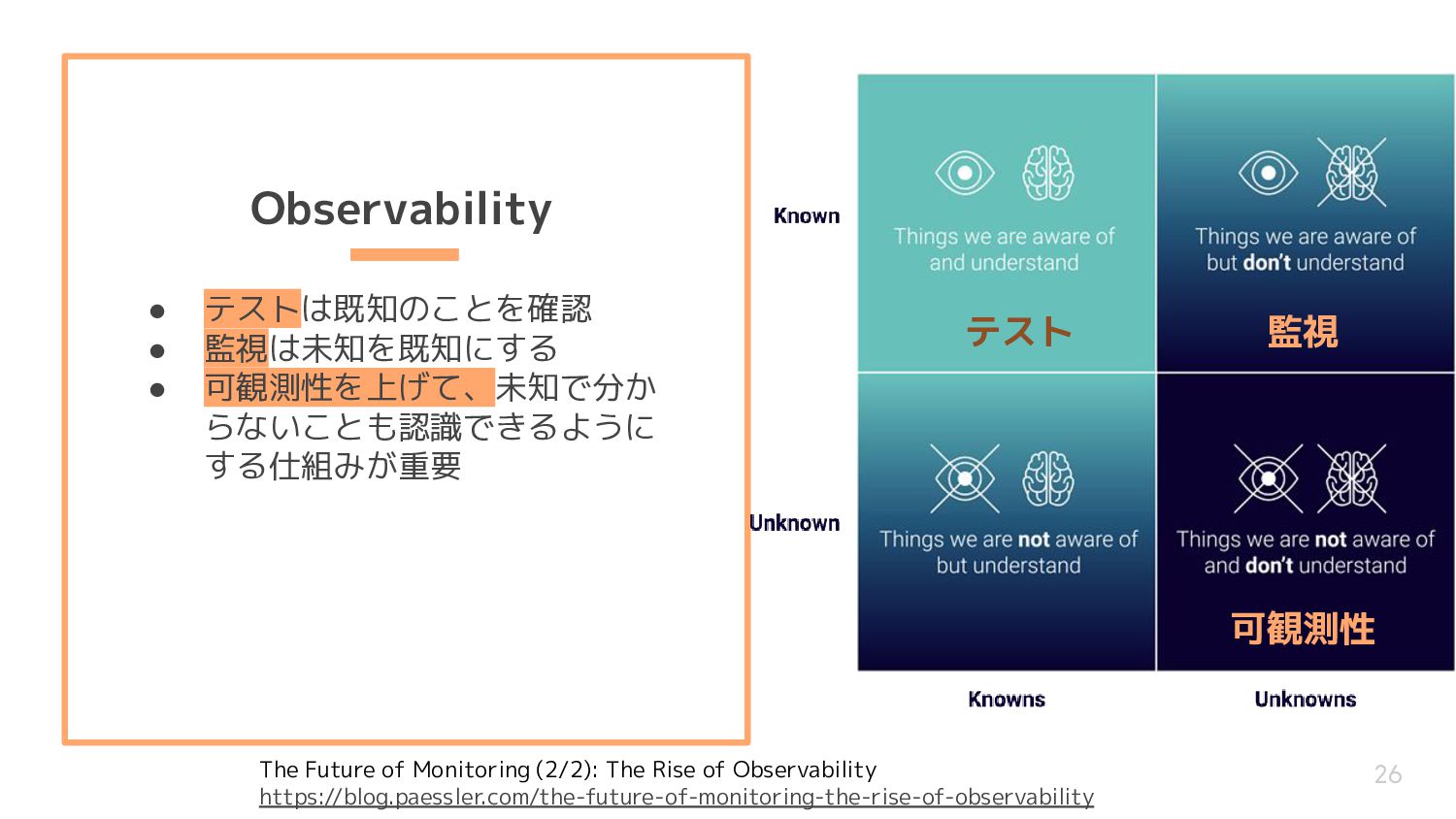
for known unknowns • observability is for unknown unknowns – Jez Humble 20 The Future of Monitoring (2/2): The Rise of Observability https://blog.paessler.com/the-future-of-monitoring-the-rise-of-observability
• observabilityはシステムを生き 物のように扱い、厳密に定義さ れたカウンタというよりかは計 測できる機構を兼ね備えている • 未知の望ましくない振る舞いや 外れ値を引き出す事が出来る 23 Observability for developers: How to get from here to there https://conferences.oreilly.com/velocity/vl-ca/public/schedule/detail/74780
なってきている • 外れ値を特定するには、まず可 視化が必要 24 Observability for developers: How to get from here to there https://conferences.oreilly.com/velocity/vl-ca/public/schedule/detail/74780
を測定 するための優れた測定基準です。 47 The RED Method: How to Instrument Your Services https://grafana.com/blog/2018/08/02/the-red-method-how-to-instrument-your-services/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}