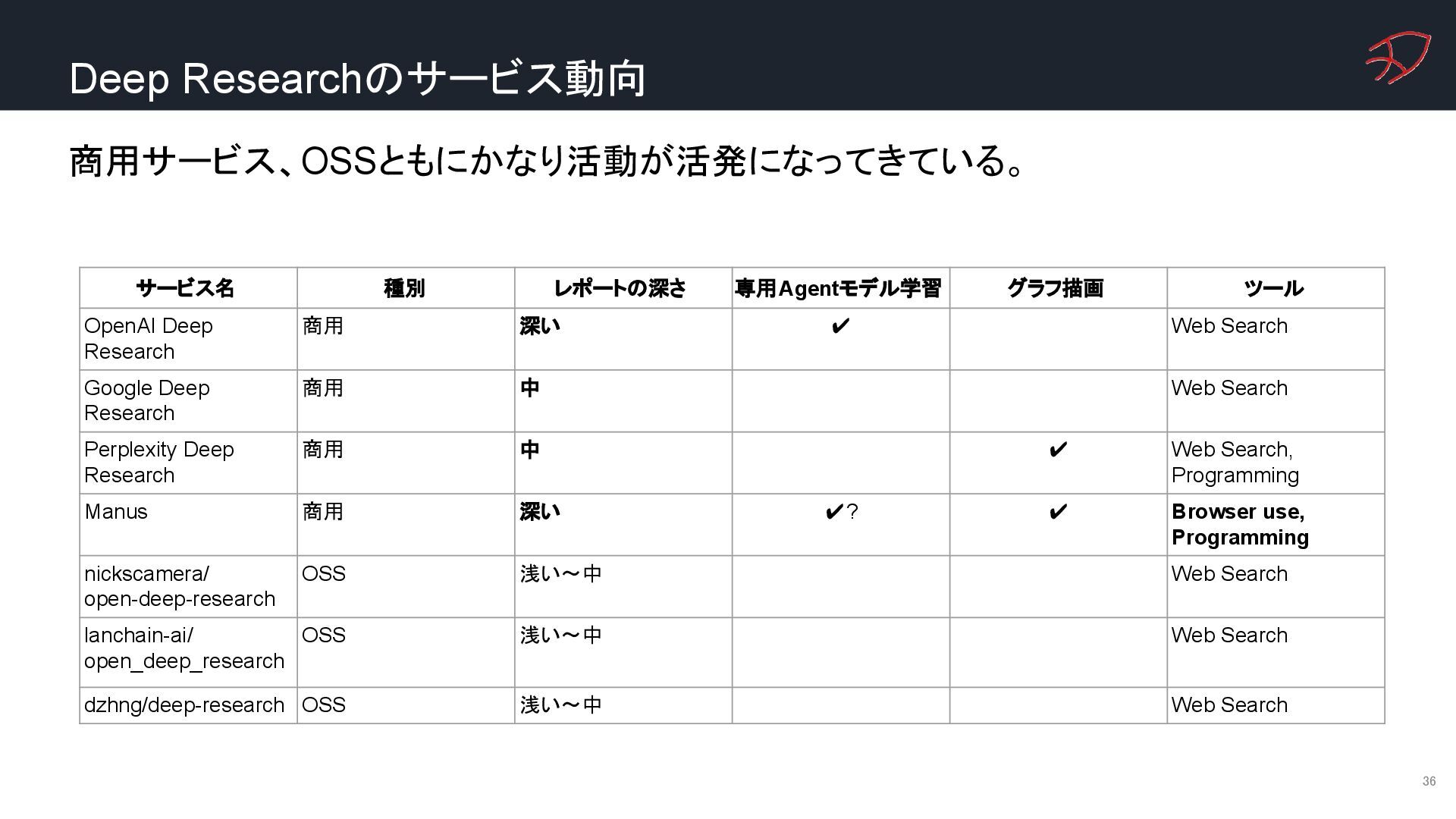
OpenAI Deep Research 商用 深い ✔ Web Search Google Deep Research 商用 中 Web Search Perplexity Deep Research 商用 中 ✔ Web Search, Programming Manus 商用 深い ✔? ✔ Browser use, Programming nickscamera/ open-deep-research OSS 浅い〜中 Web Search lanchain-ai/ open_deep_research OSS 浅い〜中 Web Search dzhng/deep-research OSS 浅い〜中 Web Search
Learning is the Future for AI Agents” https://www.youtube.com/watch?v=bNEvJYzoa8A OpenAIのDeep Researchは強化学習で、o3のfine tuningを行っている。 Workflow構築する場合と比べて Agentが次にどのような検索を行うかを柔軟に決めることができる。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
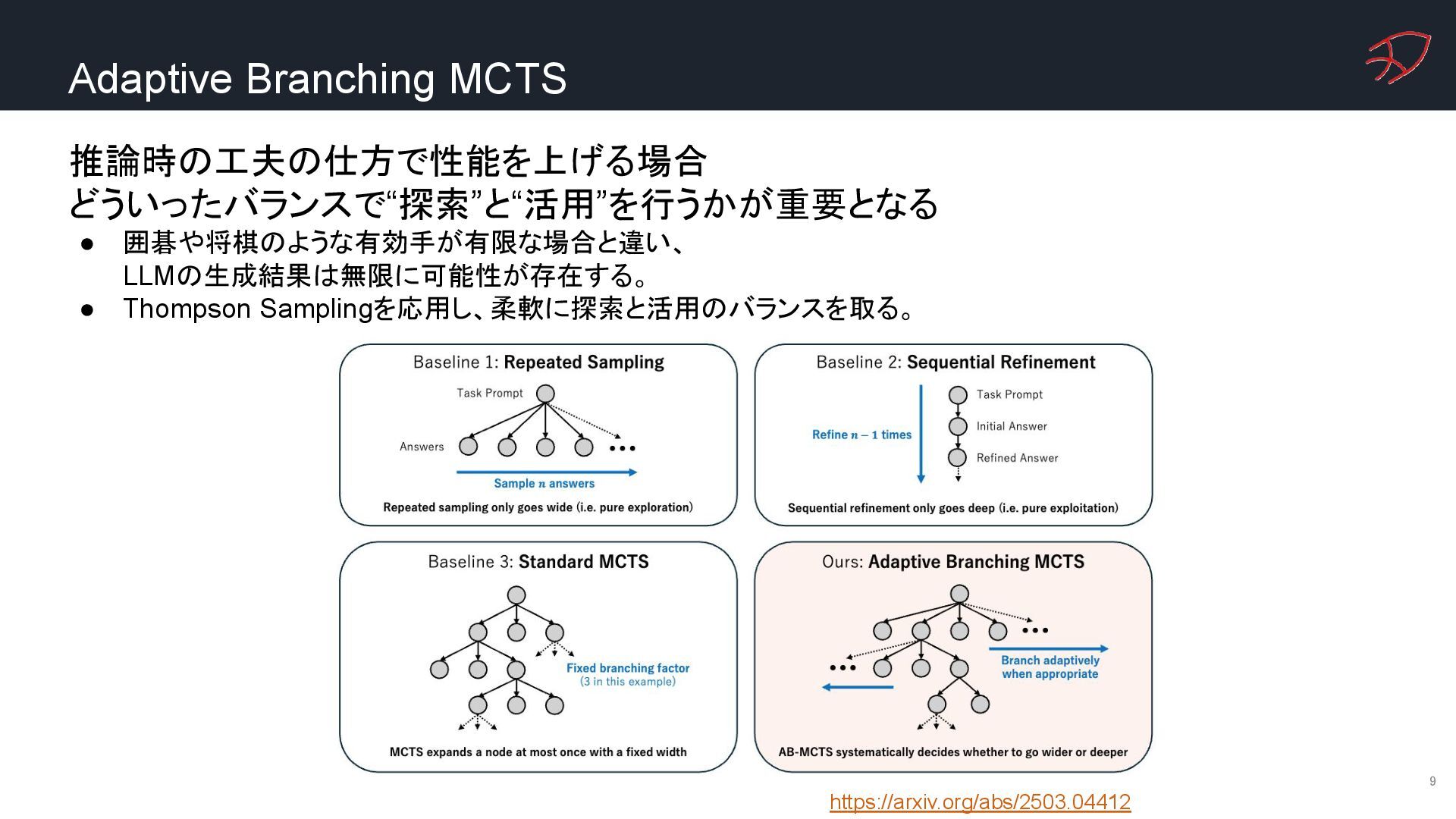{kind=link}
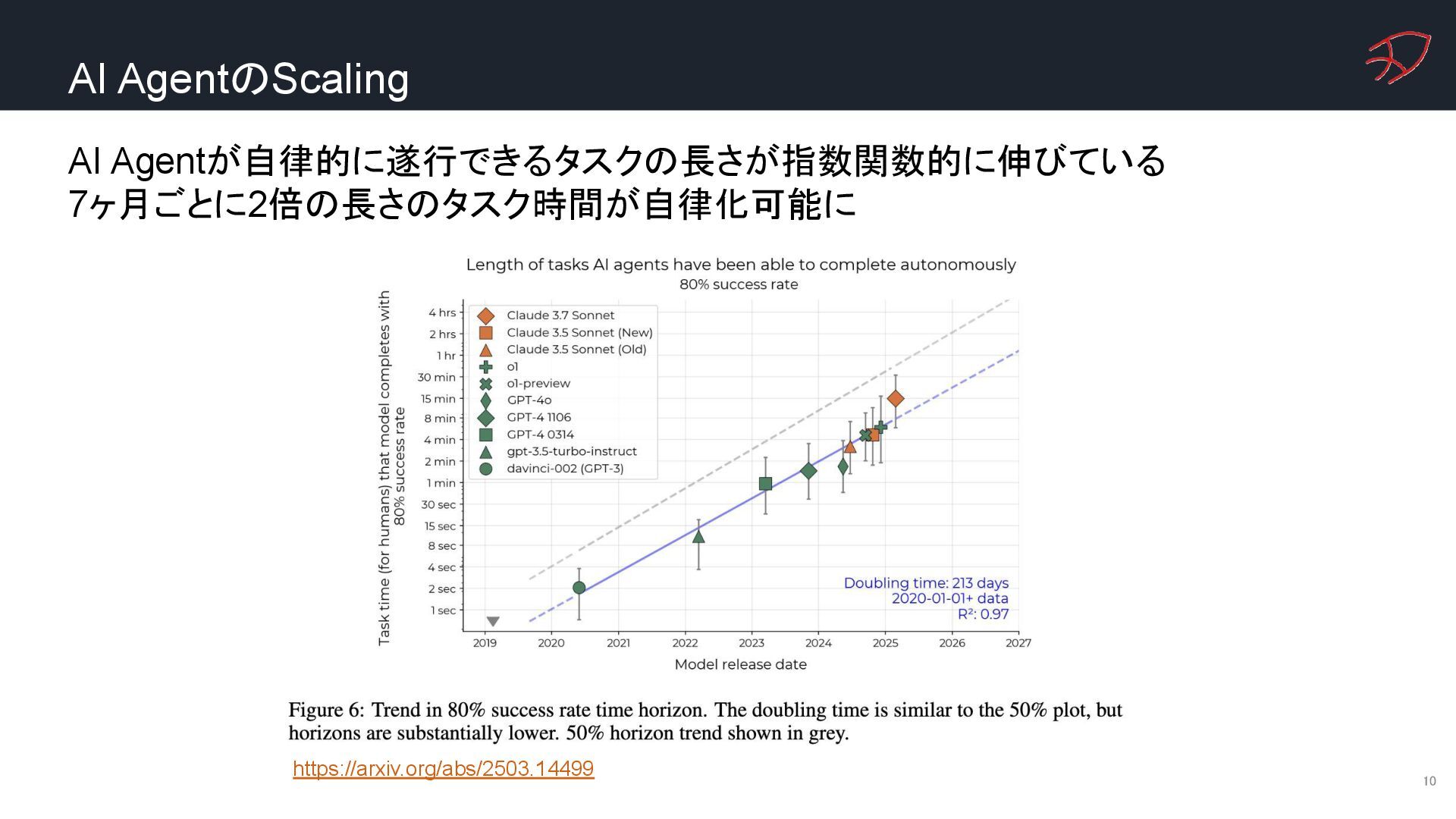{kind=link}
{kind=link}
{kind=link}
{kind=link}
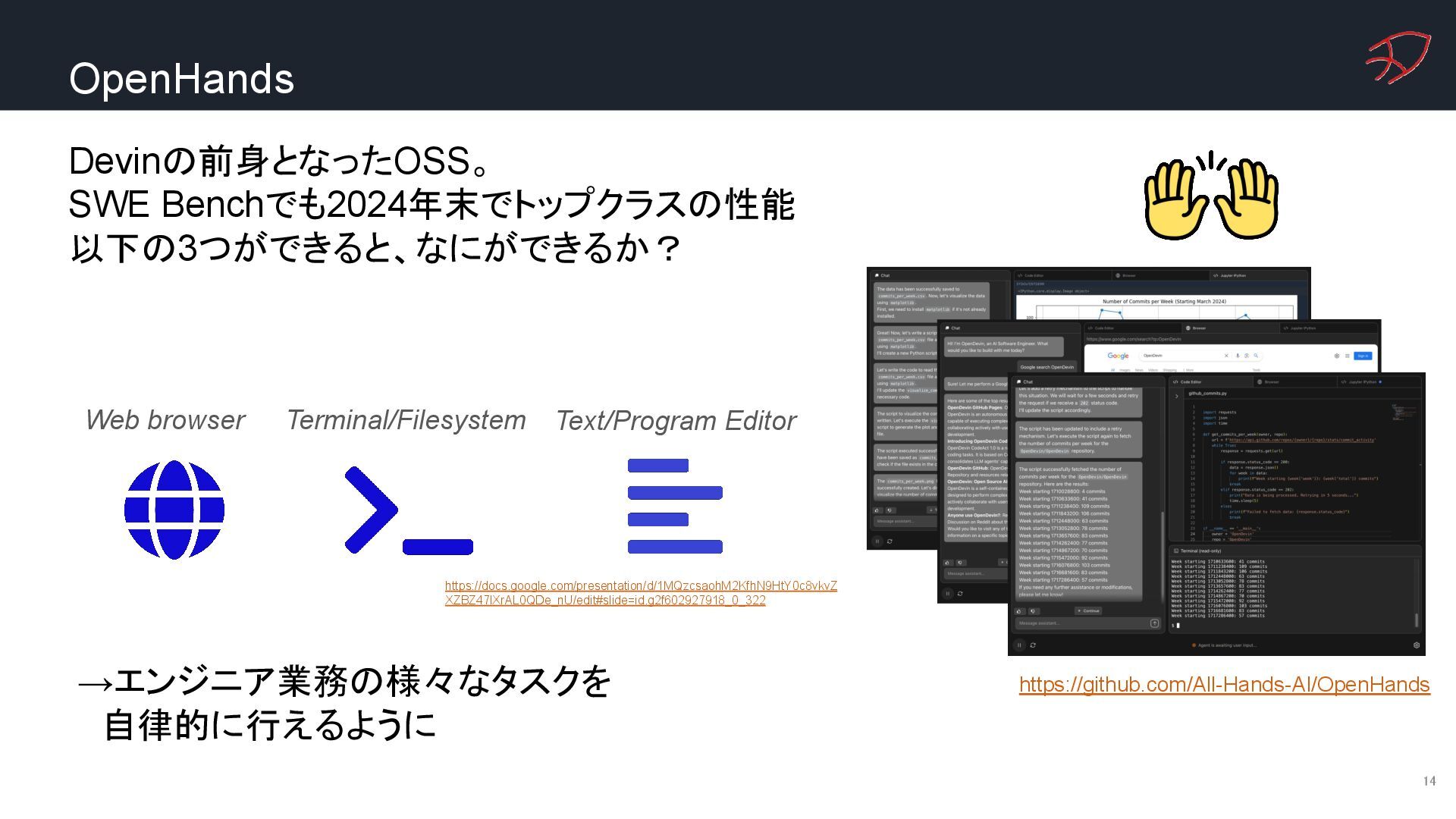{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
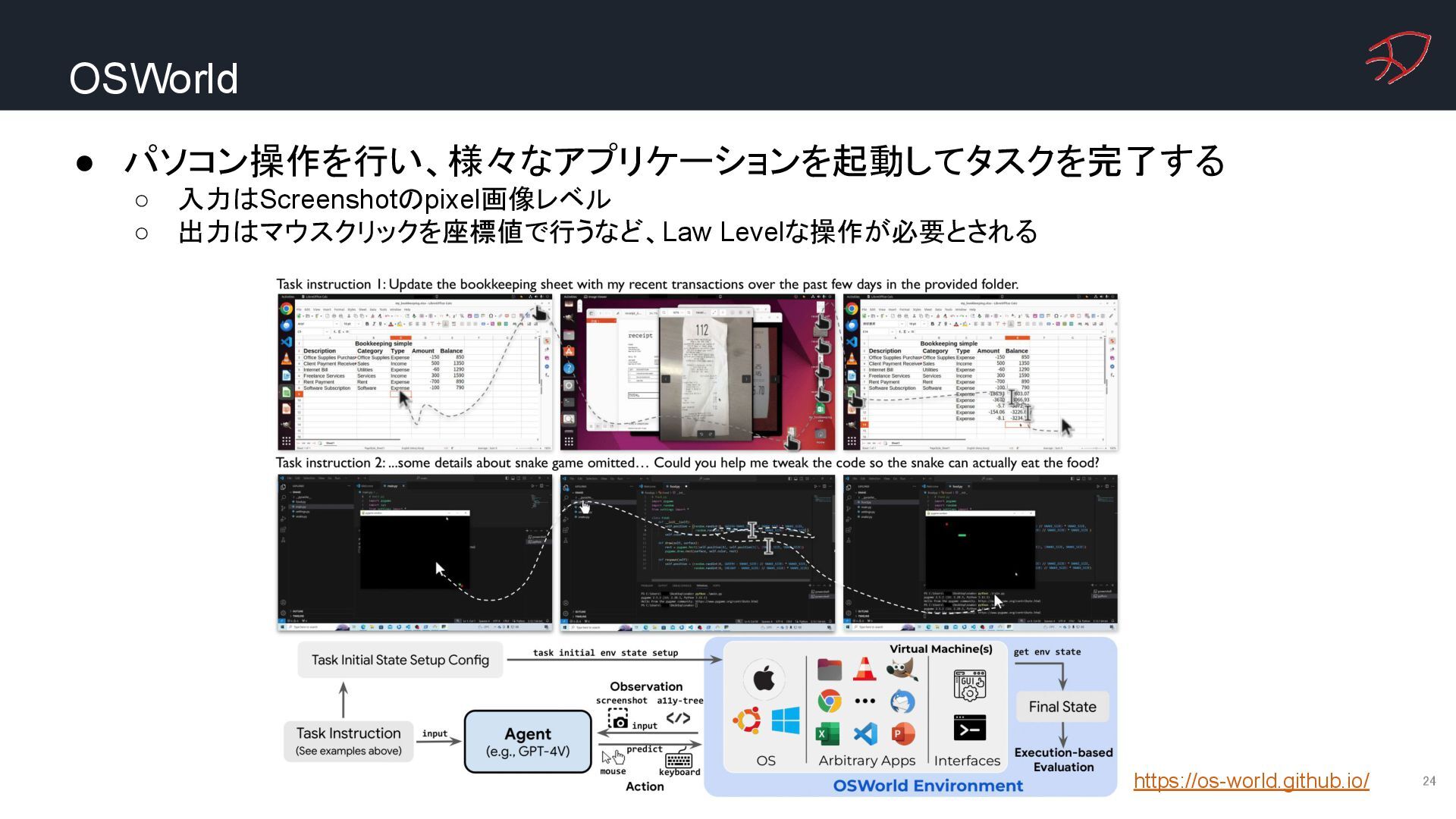{kind=link}
{kind=link}
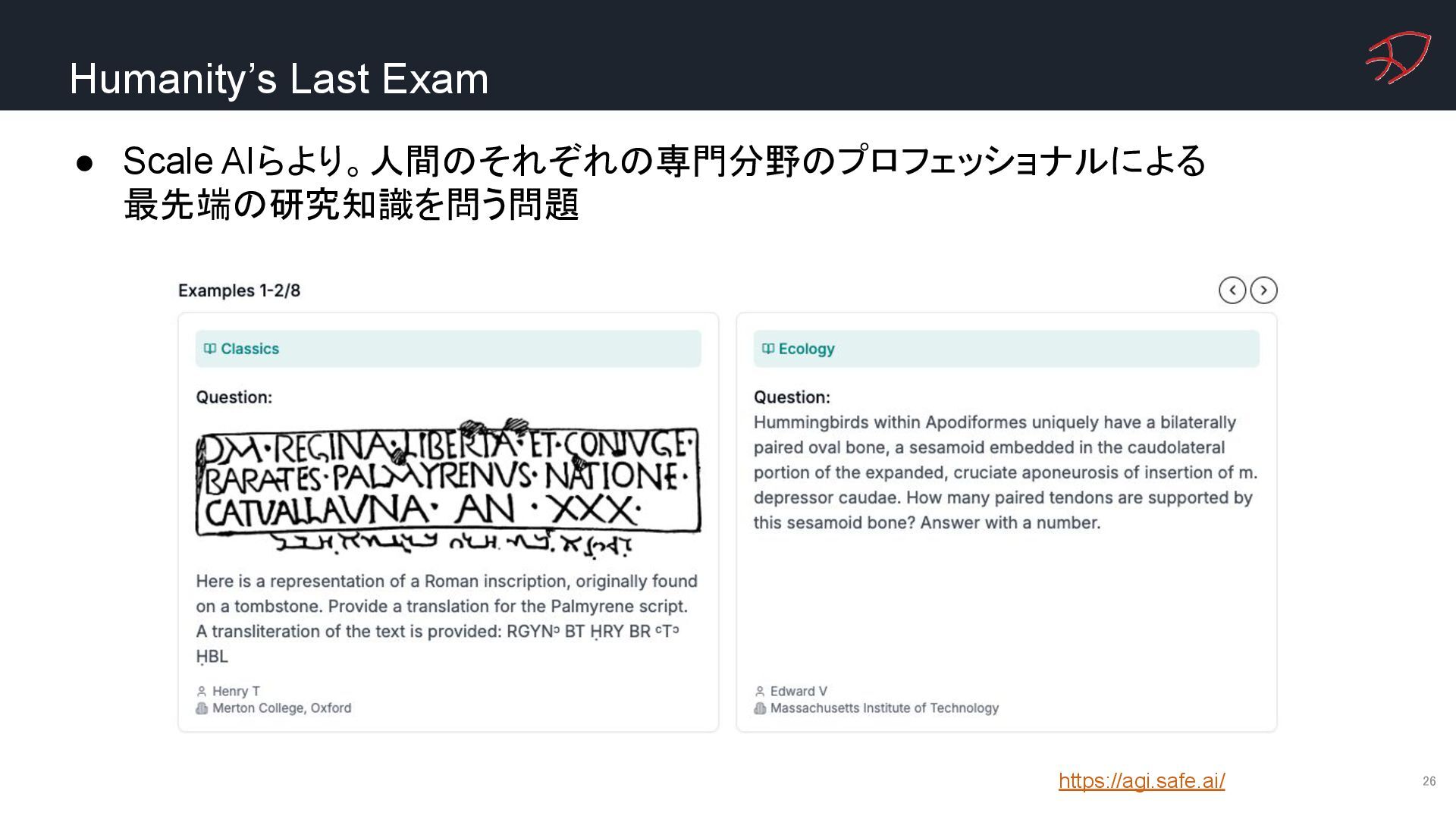{kind=link}
{kind=link}
{kind=link}
{kind=link}
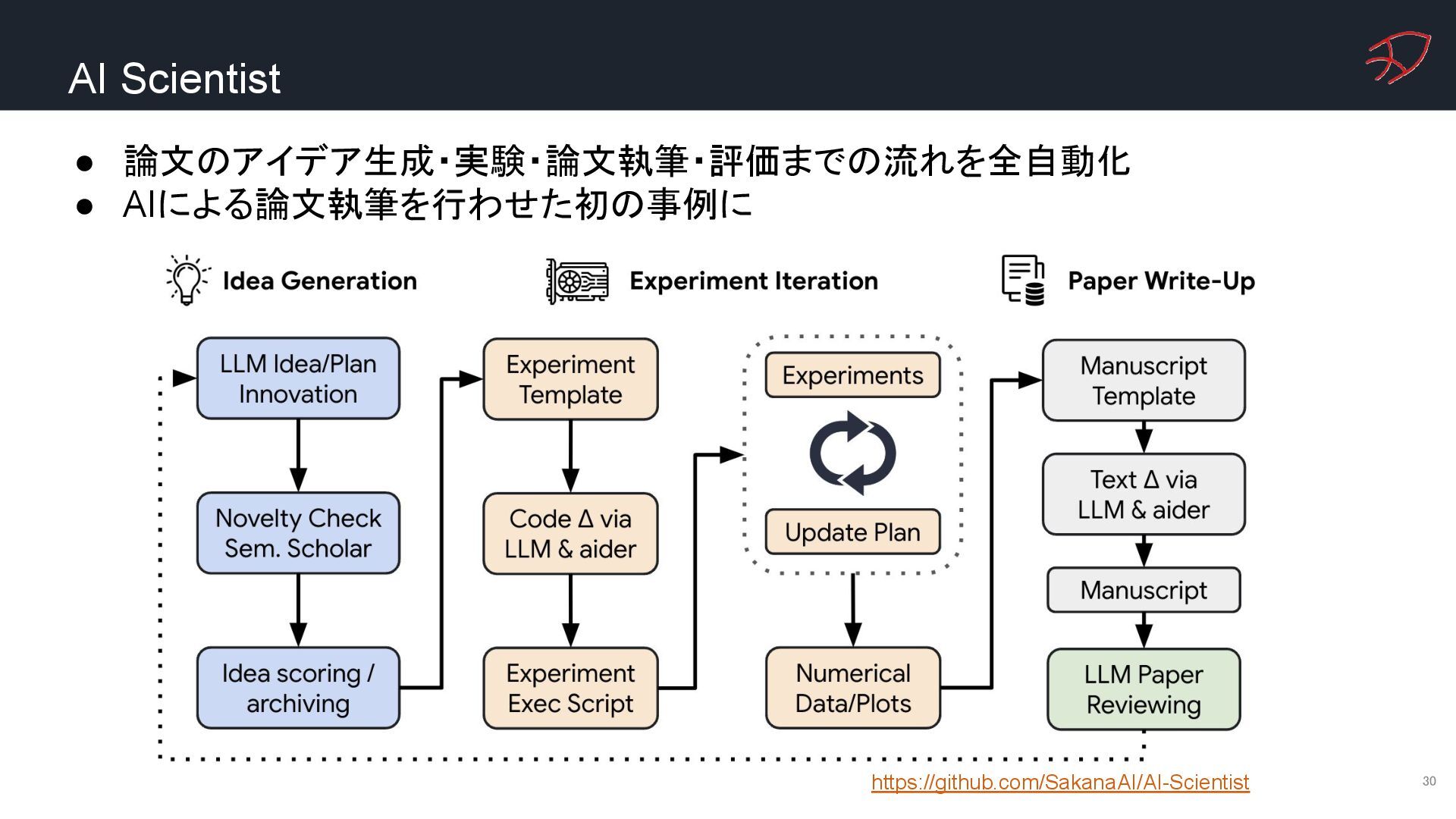{kind=link}
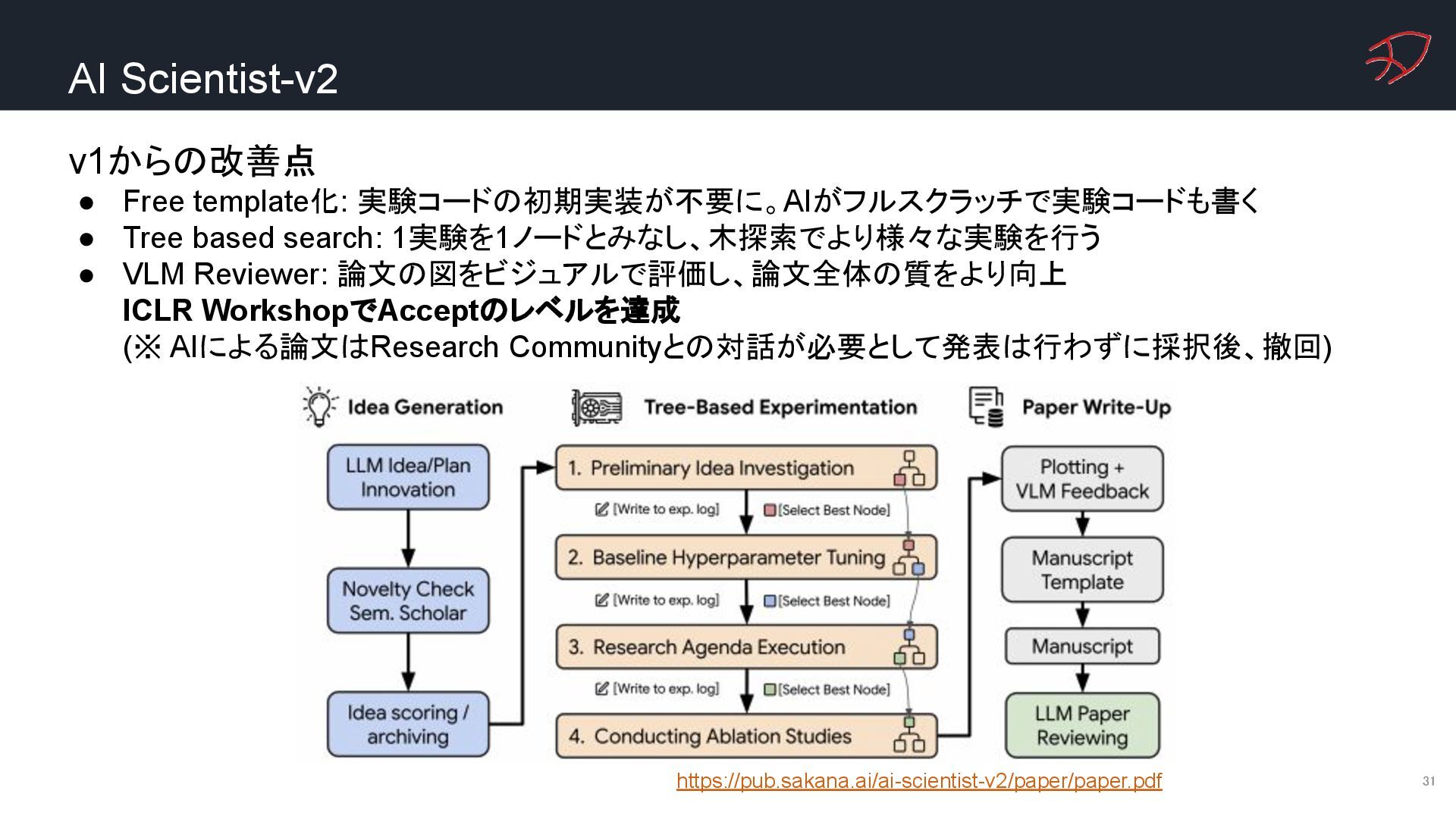{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
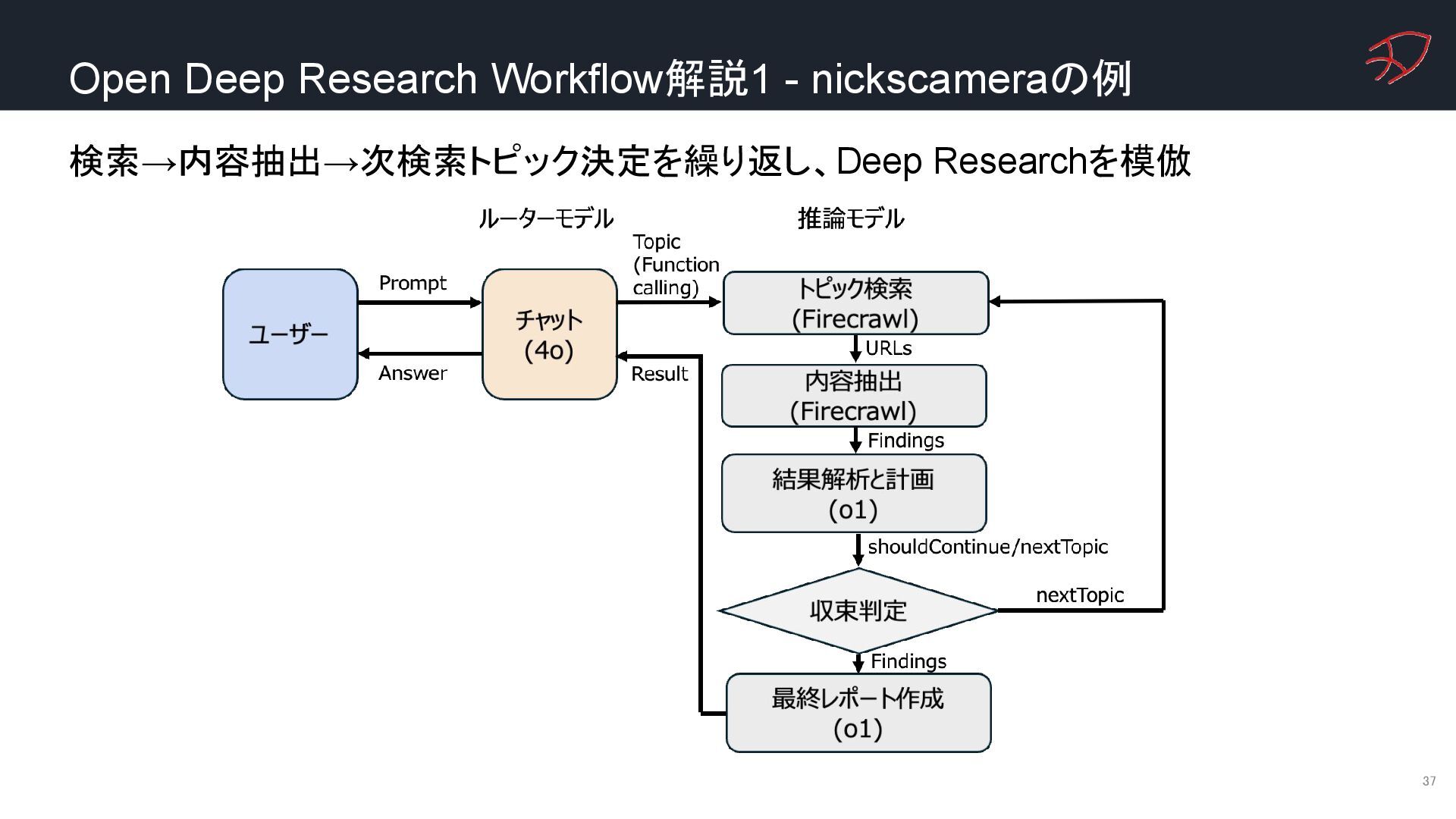{kind=link}
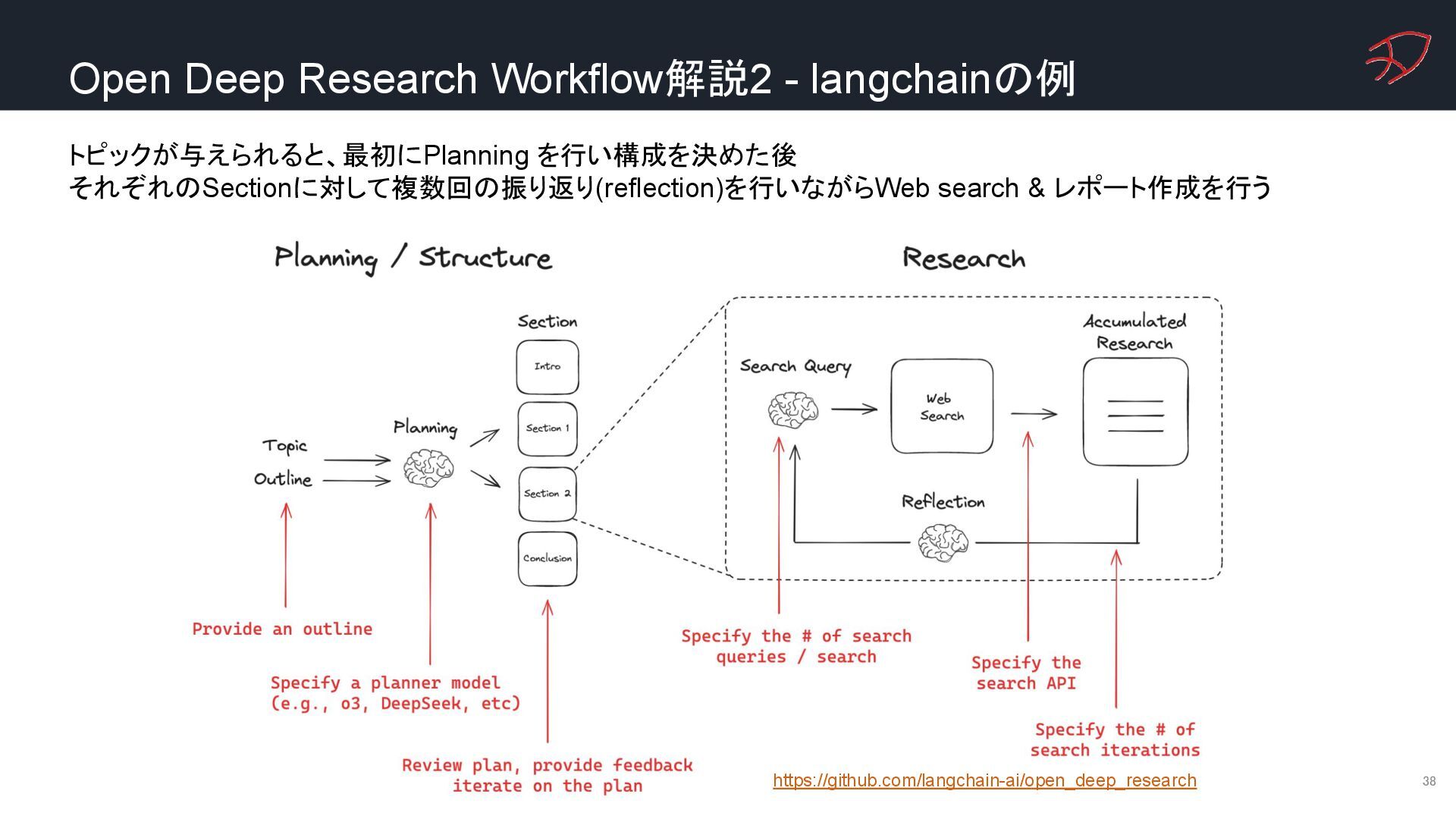{kind=link}
{kind=link}
{kind=link}
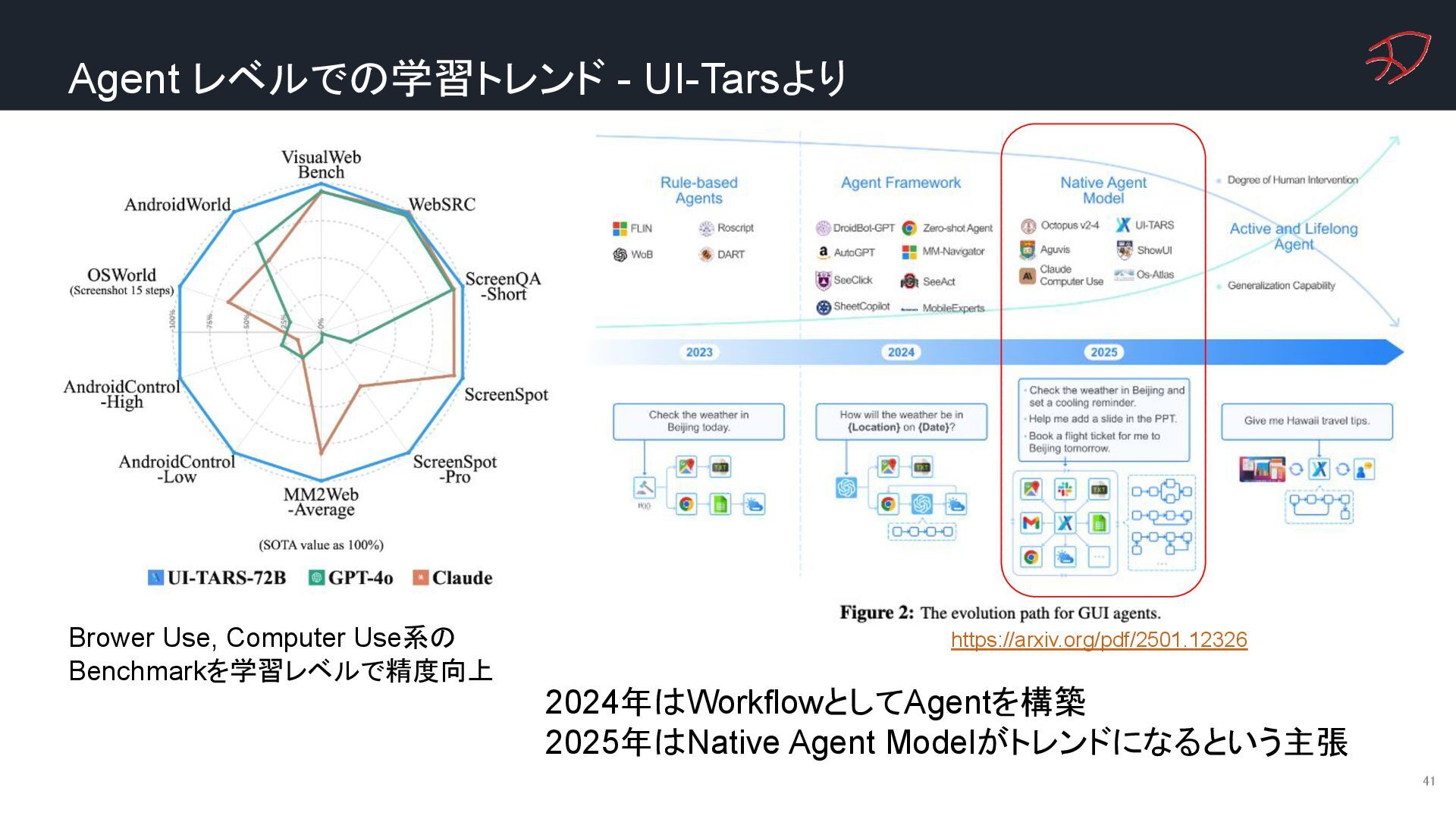{kind=link}
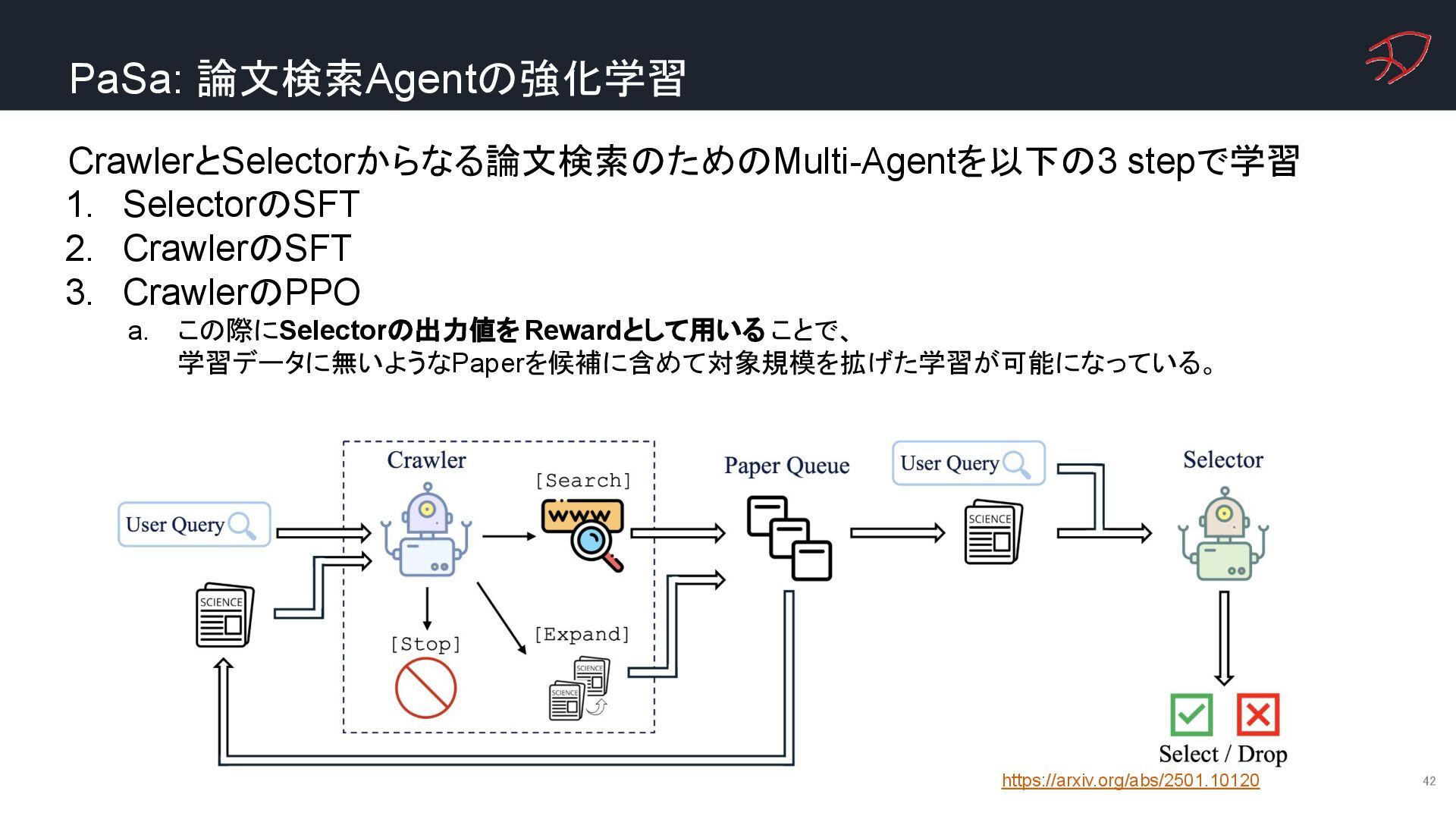{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}