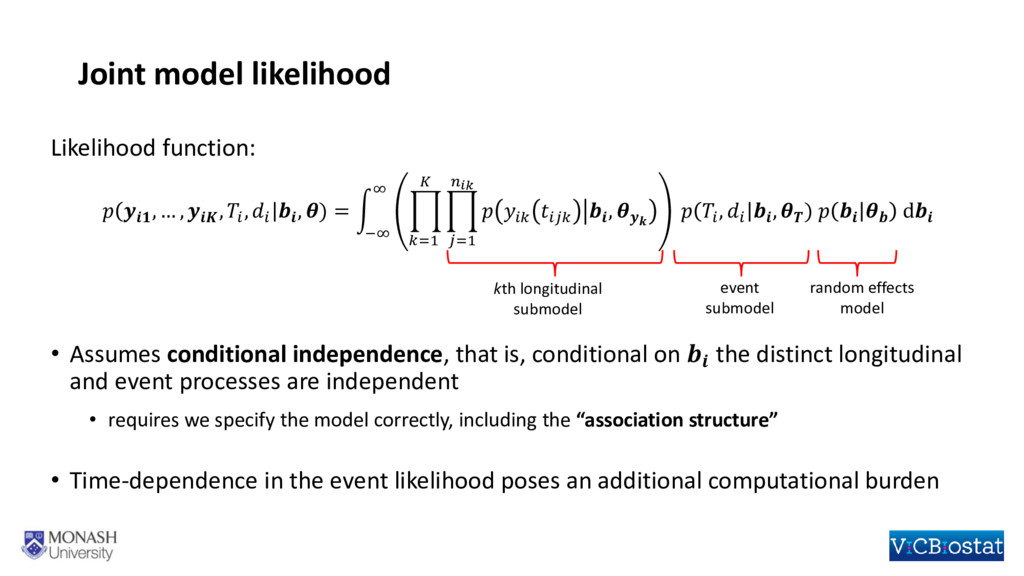
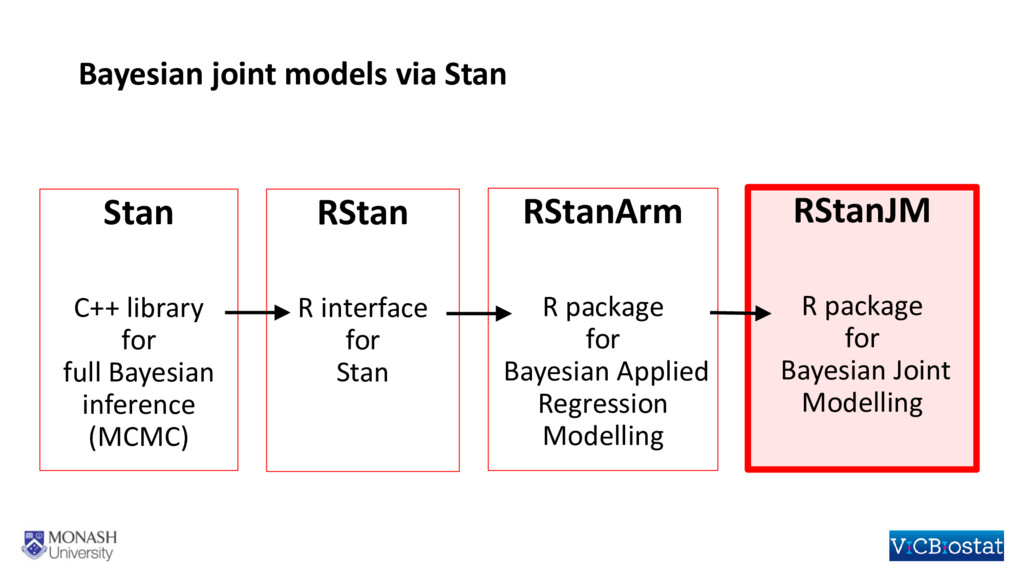
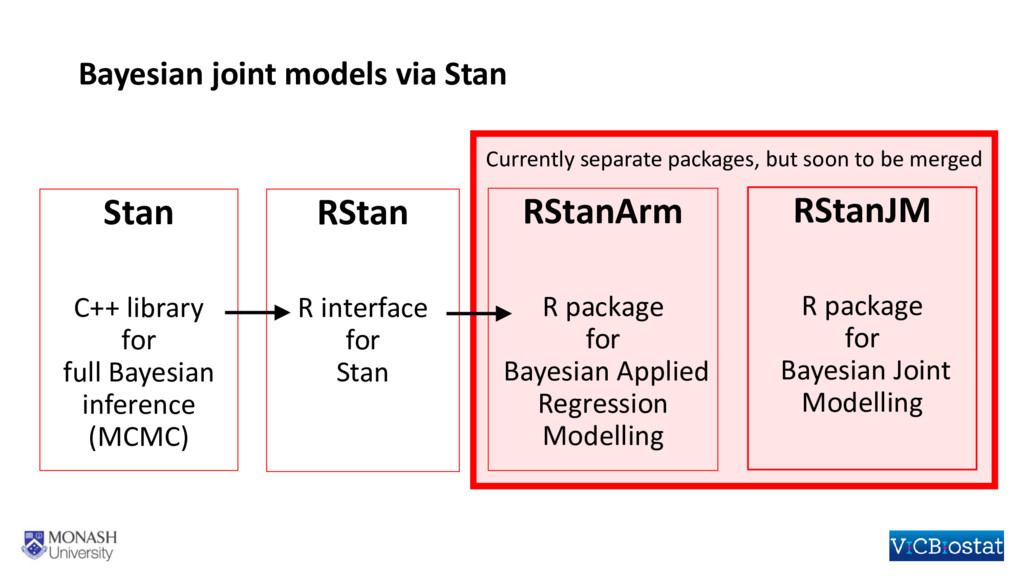
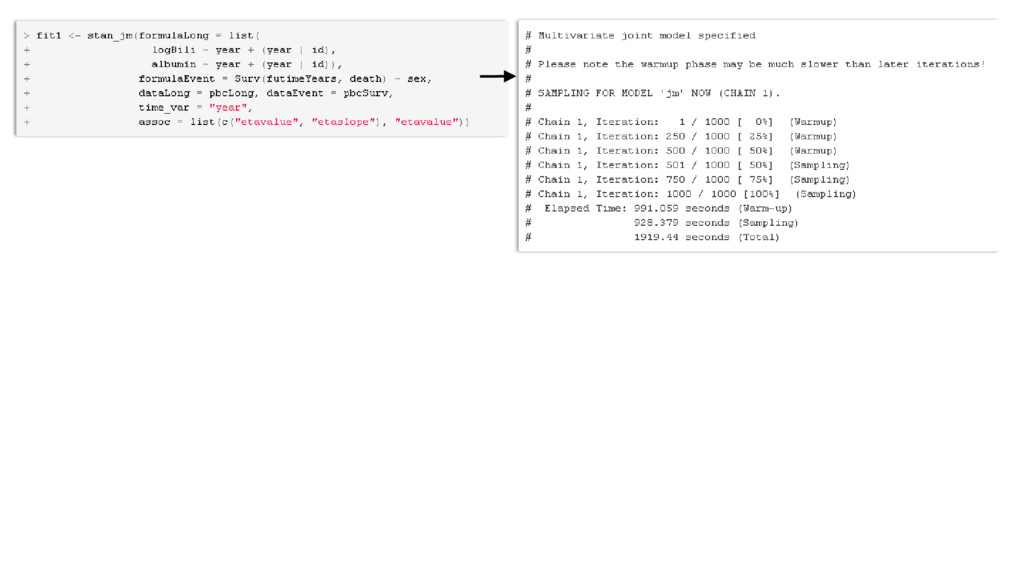
Methodological developments in the joint modelling of longitudinal and time-to-event data abound. Implementations of various versions of this methodology now enable researchers to fit joint models using standard statistical software packages. However, situations in which there are multiple longitudinal markers, or data clustered beyond the level of the individual, have not been widely considered and there is not yet readily available software for fitting joint models in either of these situations. In this talk I will outline the framework for fitting a shared parameter joint model for multiple longitudinal biomarkers and the time to an event. The longitudinal biomarkers are each modelled using a generalized linear mixed model which, through the use of cubic splines, can be extended to allow for flexible non-linear trajectories. The time-to-event is modelled through a parametric proportional hazards regression model. Dependence between multiple biomarkers is assumed to be captured through a shared multivariate normal distribution for the individual-level random effects, whilst the dependence between each biomarker and the time-to-event is based on shared random effects and can be parameterized in several ways. Estimation is under a Bayesian framework, which allows for the specification of a variety of prior distributions, such as shrinkage priors on regression coefficients, and the “LKJ” distribution for the correlation matrix on the individual-level random effects. Our approach easily extends to data that is clustered at levels beyond the individual, for example, when we have longitudinal and time-to-event data observed on patients within hospitals. I will briefly describe an R package rstanjm which facilitates fitting these models, by providing an interface to the software Stan. Stan (http://mc-stan.org) facilitates full Bayesian inference using an implementation of Hamiltonian Monte Carlo. I will demonstrate use of the R package through an example and discuss the potential benefits of using Stan for the underlying estimation.
Keywords: shared parameter model; joint model; Stan; Bayesian;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}