The simsurv package allows users to simulate simple or complex survival data. Survival data refers to a variable corresponding to the time from a defined baseline until occurrence of an event of interest. Depending on the field, the analysis of survival data can be known as survival, duration, reliability, or event history analysis. It has been common to make simplifying parametric assumptions when simulating survival data, e.g. assuming survival times follow an exponential or Weibull distribution. However, such assumptions are unrealistic in many settings. The simsurv package provides additional flexibility by allowing users to simulate survival times from 2-component mixture distributions or a user-defined hazard function. The mixture distributions allow for a variety of flexible baseline hazard functions. Moreover, a user-defined hazard function can provide even greater flexibility since the cumulative hazard does not require a closed-form solution. This means it is possible to simulate survival times under complex statistical models such as those for joint longitudinal-survival data. The package is modelled on the survsim package in Stata (Crowther and Lambert, 2012, Stata J).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[1] Leemis LM. Variate Generation for Accelerated Life and Proportional](https://files.speakerdeck.com/presentations/9197268555d443c284d108ece1b19b3c/slide_21.jpg){kind=link}
![[3] Crowther MJ, Lambert PC. Simulating Biologically Plausible Complex Survival](https://files.speakerdeck.com/presentations/9197268555d443c284d108ece1b19b3c/slide_22.jpg){kind=link}
![[3] Crowther MJ, Lambert PC. Simulating Biologically Plausible Complex Survival](https://files.speakerdeck.com/presentations/9197268555d443c284d108ece1b19b3c/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
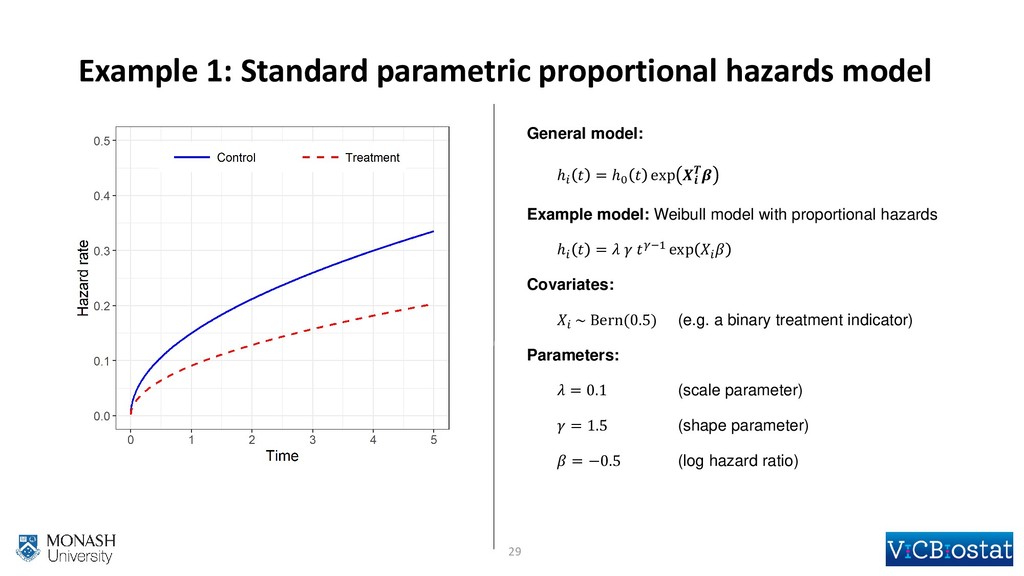{kind=link}
{kind=link}
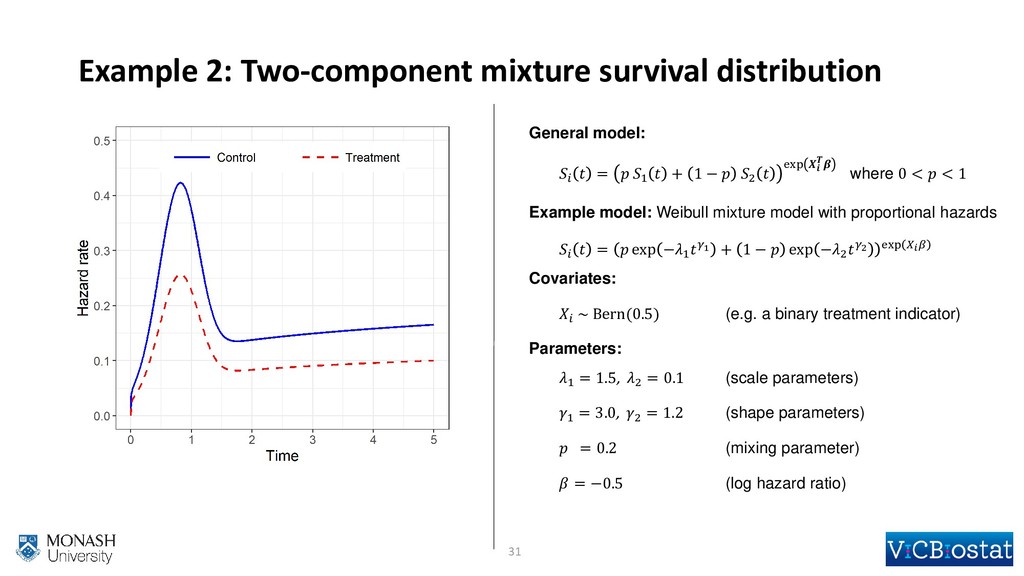{kind=link}
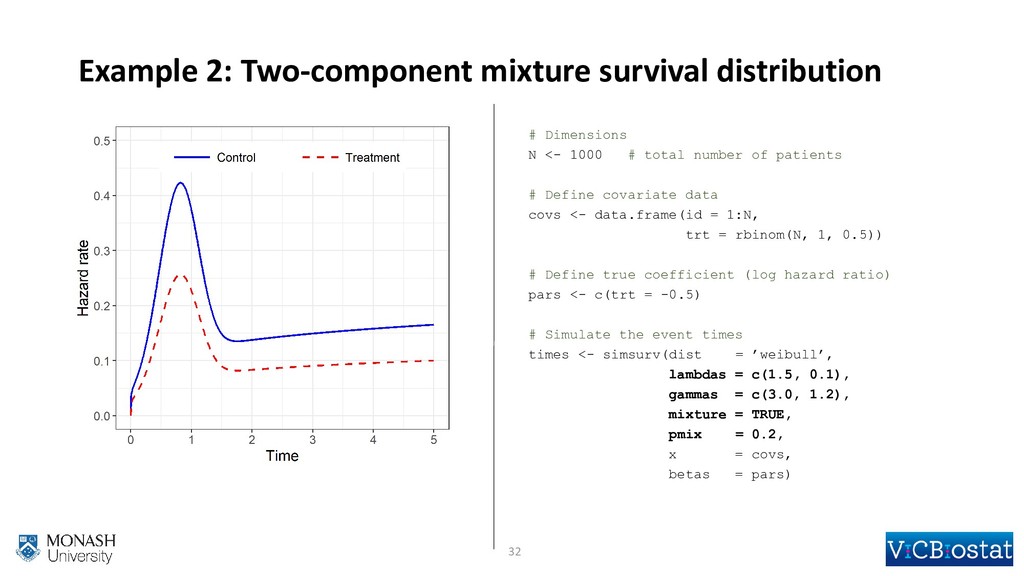{kind=link}
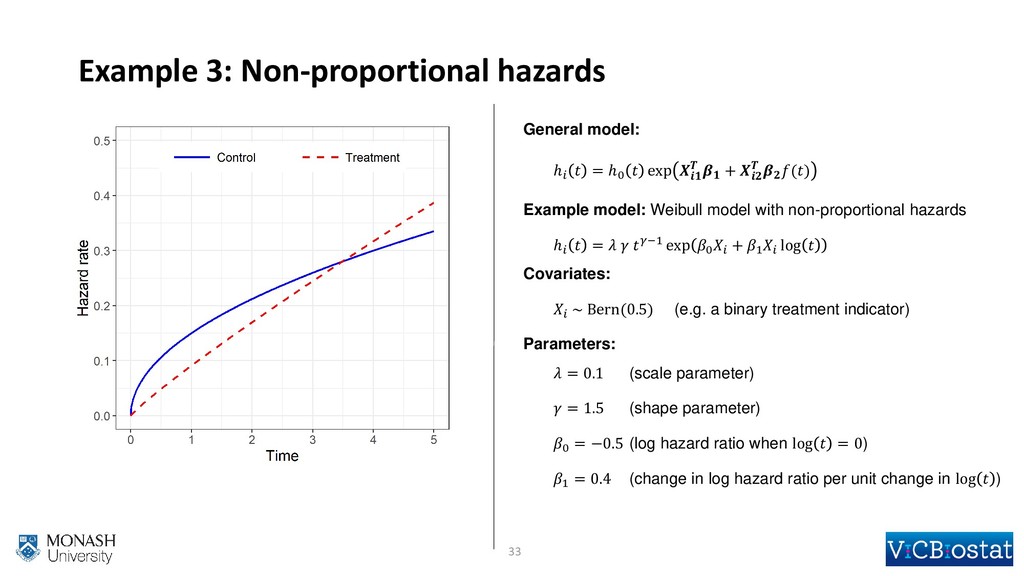{kind=link}
{kind=link}
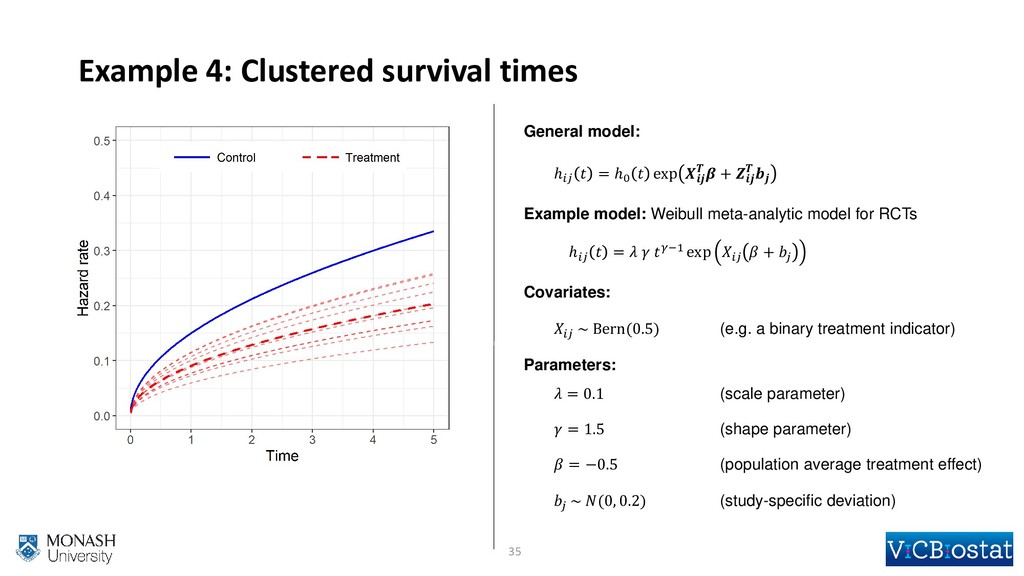{kind=link}
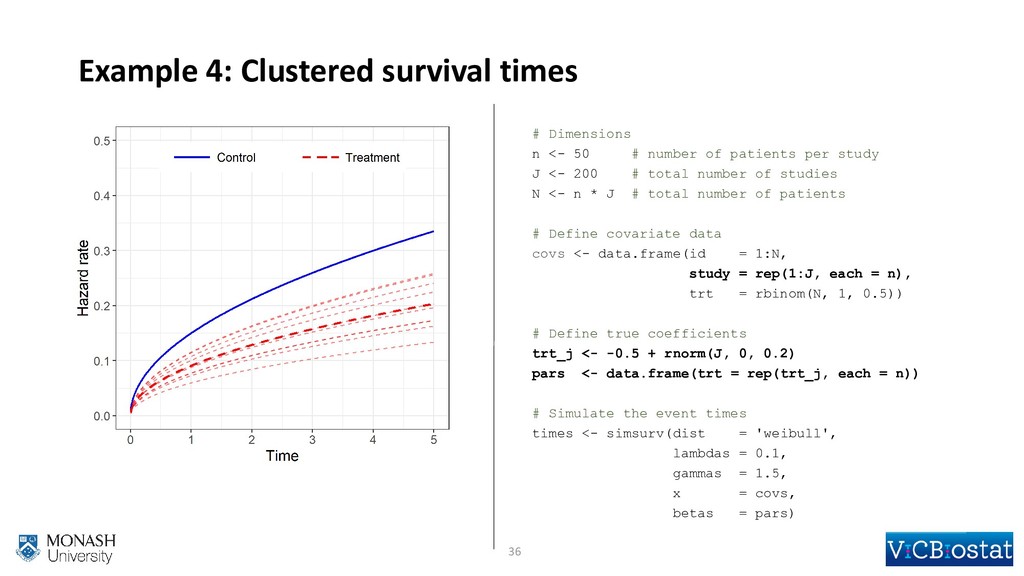{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [1] Leemis LM. Variate Generation for Accelerated Life](https://files.speakerdeck.com/presentations/9197268555d443c284d108ece1b19b3c/slide_41.jpg){kind=link}