Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, and Haofen Wang 共十位作者發表的論文 Retrieval-Augmented Generation for Large Language Models: A Survey 開啟了 LLM 落地應用的大門。
& Self-reflection • Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity • Retrieval-Augmented Generation for Large Language Models: A Survey • 利用 LangChain 實作多模態模型的 RAG:除了讀文章也能看圖答題 • CRAG: 革命性AI技術如何讓機器回答更精準? • SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION • Building adaptive RAG from scratch with Command-R
![LLM RAG 擷取增強生成 你以為的 LLM 只會一問一答嗎? [email protected] https://blog.toright.com](https://files.speakerdeck.com/presentations/59b38d99187e4373854f1462e2179b69/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
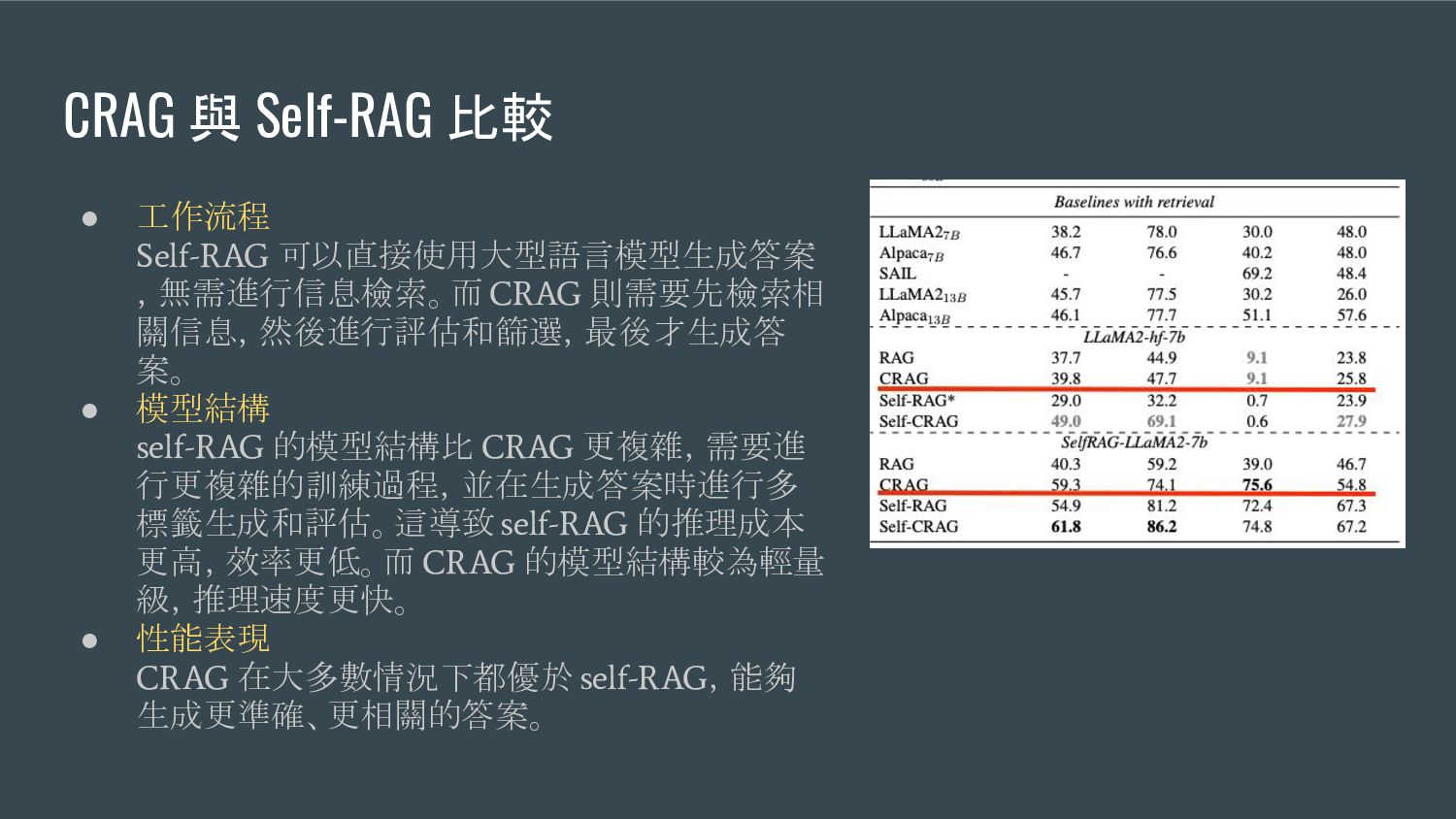{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks SJ Chou [email protected] https://blog.toright.com](https://files.speakerdeck.com/presentations/59b38d99187e4373854f1462e2179b69/slide_25.jpg){kind=link}