Share
Keras 是一個開源專案,透過 Python 實做的深度學習高階 API 函式庫。透過 Keras 可以快速的進入 Machine Learning 領域,這份投影片提供了 Google Colab 相關程式範例,邊做邊學~
![用 Keras 玩 Machine Learning SJ Chou [email protected] https://blog.toright.com](https://files.speakerdeck.com/presentations/529ab04c45e44d4cba9d81241c019755/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
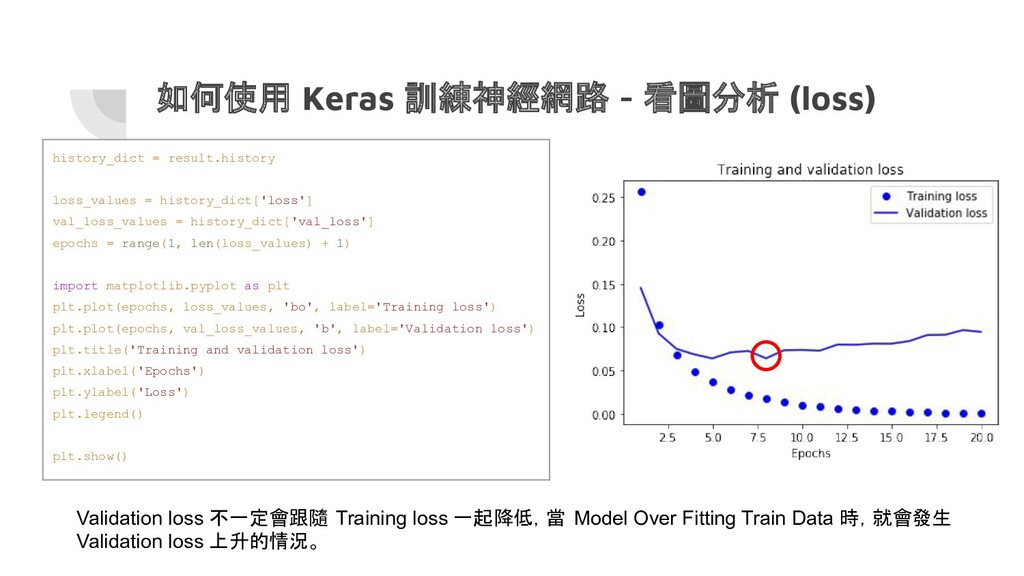{kind=link}
![如何使用 Keras 訓練神經網路 - 看圖分析 (accuracy) plt.clf() acc = history_dict['accuracy']](https://files.speakerdeck.com/presentations/529ab04c45e44d4cba9d81241c019755/slide_16.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
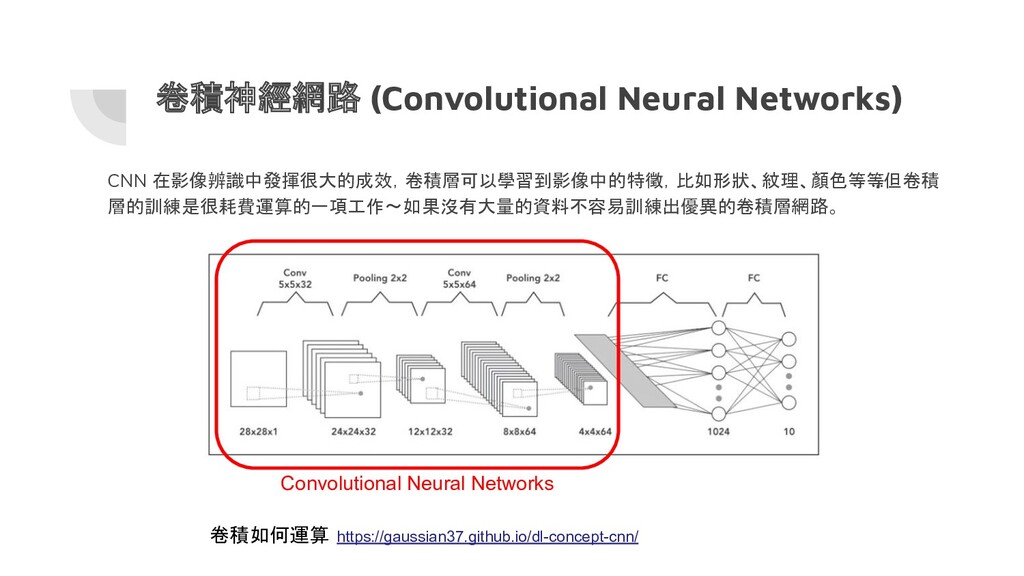{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
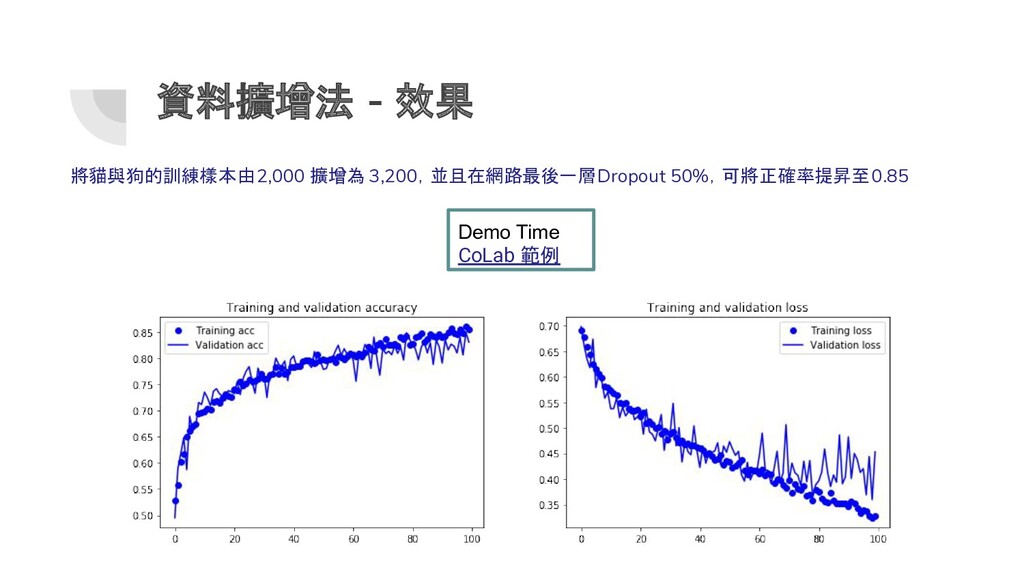{kind=link}
{kind=link}
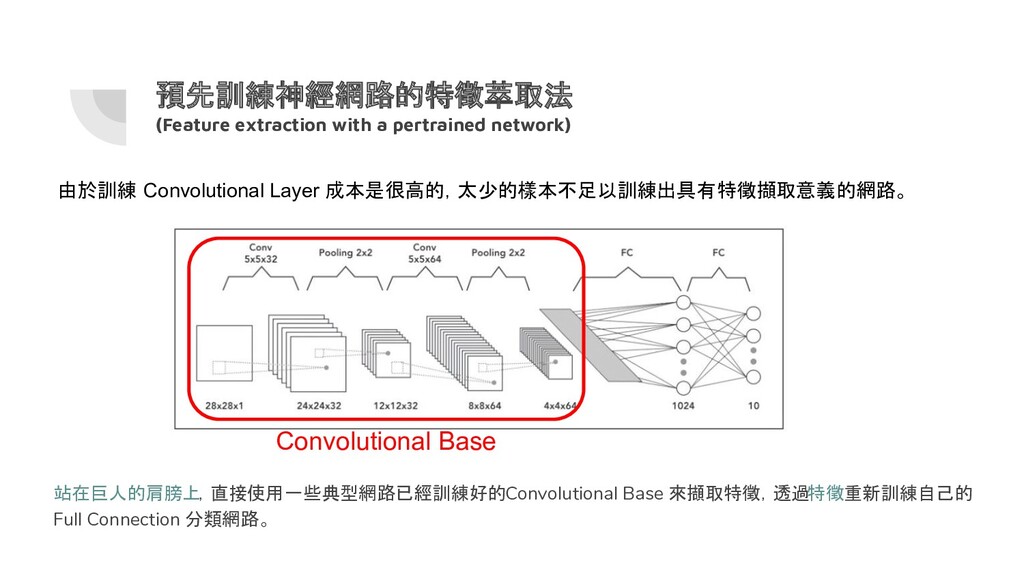{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![The End 2020/06/30 SJ Chou [email protected] https://blog.toright.com](https://files.speakerdeck.com/presentations/529ab04c45e44d4cba9d81241c019755/slide_48.jpg){kind=link}