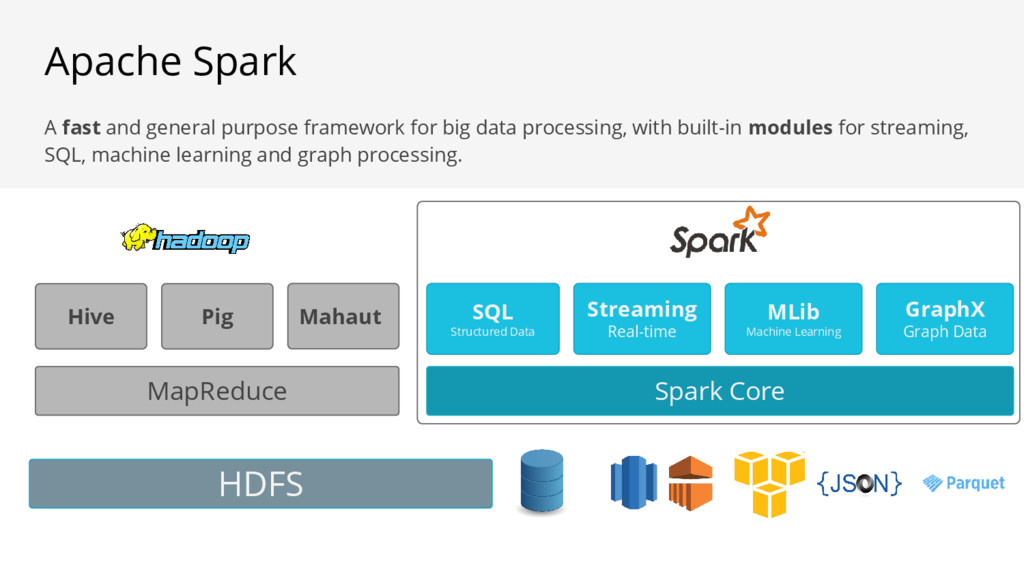
GraphX Graph Data A fast and general purpose framework for big data processing, with built-in modules for streaming, SQL, machine learning and graph processing. Apache Spark MapReduce Hive Pig Mahaut HDFS
the basic abstraction in Spark. Represents an immutable, partitioned collection of elements that can be operated on in parallel. Caching + DAG model is enough to run them efficiently Combining libraries into one program is much faster DataFrames - schema-RDD
framework that also does micro-batching (Trident). • Spark is a batch processing framework that also does micro-batching (Spark Streaming). Also read:https://www.quora.com/What-are-the-differences-between-Apache-Spark-and-Apache-Flink/answer/Santosh-Sahoo
latitude, longitude from hive_tweets”) // Train a machine learning model model = KMeans.train(points, 10) // Apply it to a stream sc.twitterStream(...) .map(lambda t: (model.predict(t.location), 1)) .reduceByWindow(“5s”, lambda a, b: a + b)
20k of RabbitMQ • Log compaction • Durable persistence • Partition tolerance • Replication • Best in class integration with Spark ◦ http://spark.apache.org/docs/latest/streaming-kafka-integration.html
FTP HTTP SMTP P Protobuf Json Broker Kafka Hive/ Spark SQL OLAP Load balance Failover HANA HANA OLAP Replication Service bus Normalization Extract Compensate Data {Quality, Correction, Analytics} Migrate method API/SQL Expense Travel TTX API Concur Next Gen C Tachyon
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Stream.scala 1. val conf = new SparkConf().setAppName("demoapp").setMaster("local[1]") 2. val sc](https://files.speakerdeck.com/presentations/b649c0a230de47ef8986d7637033d942/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
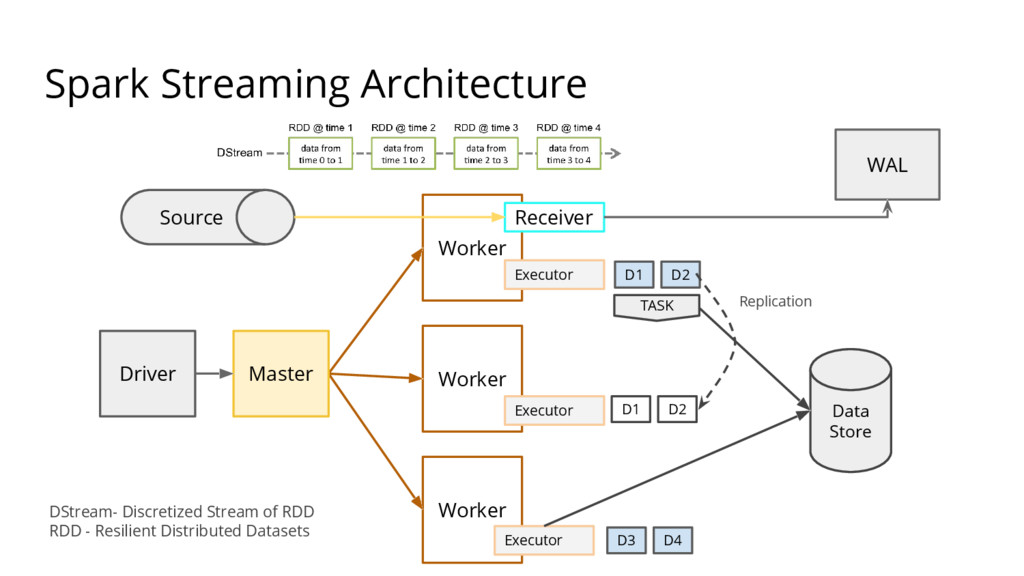{kind=link}
{kind=link}
{kind=link}
{kind=link}
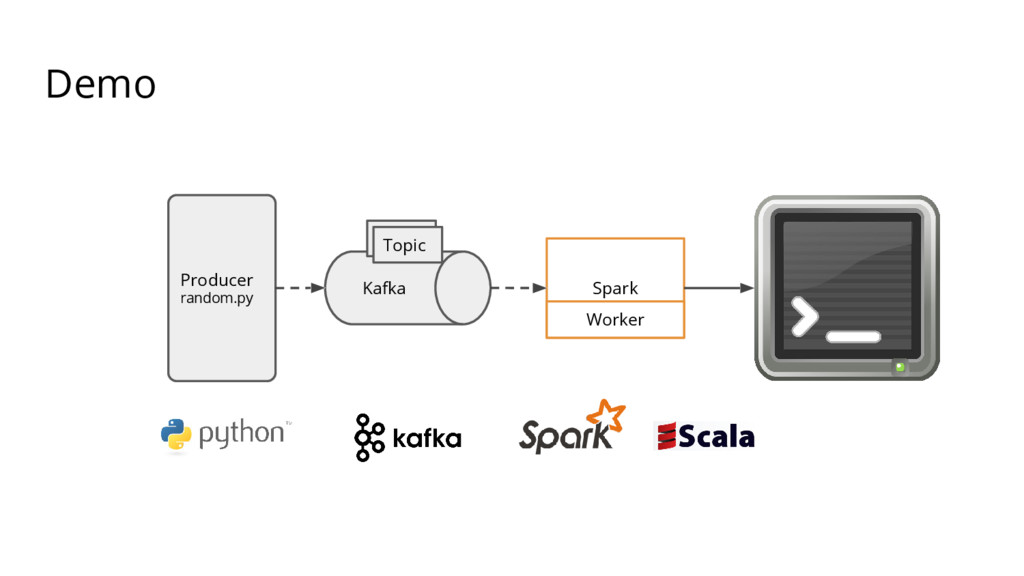{kind=link}
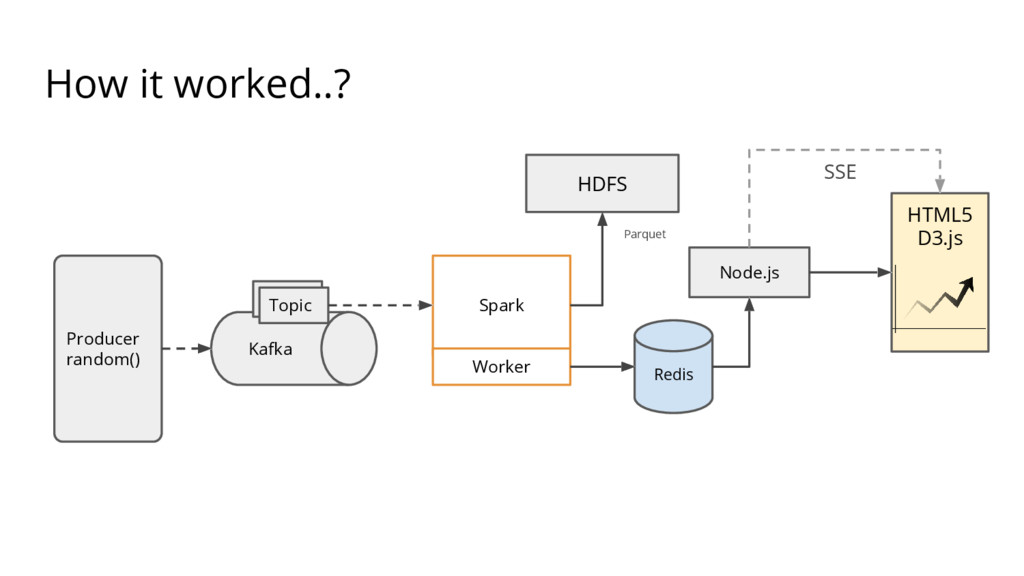{kind=link}
{kind=link}
{kind=link}
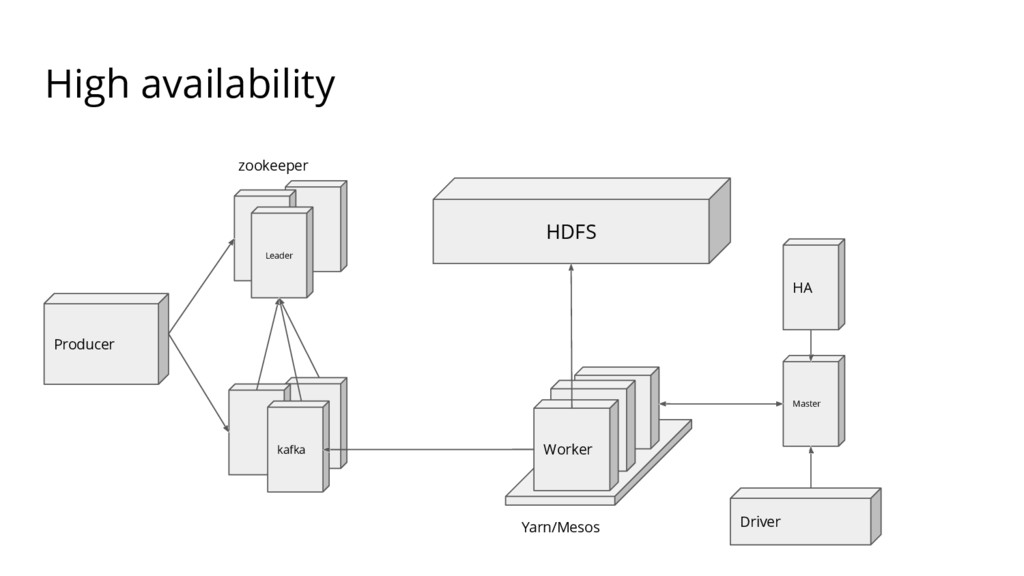{kind=link}
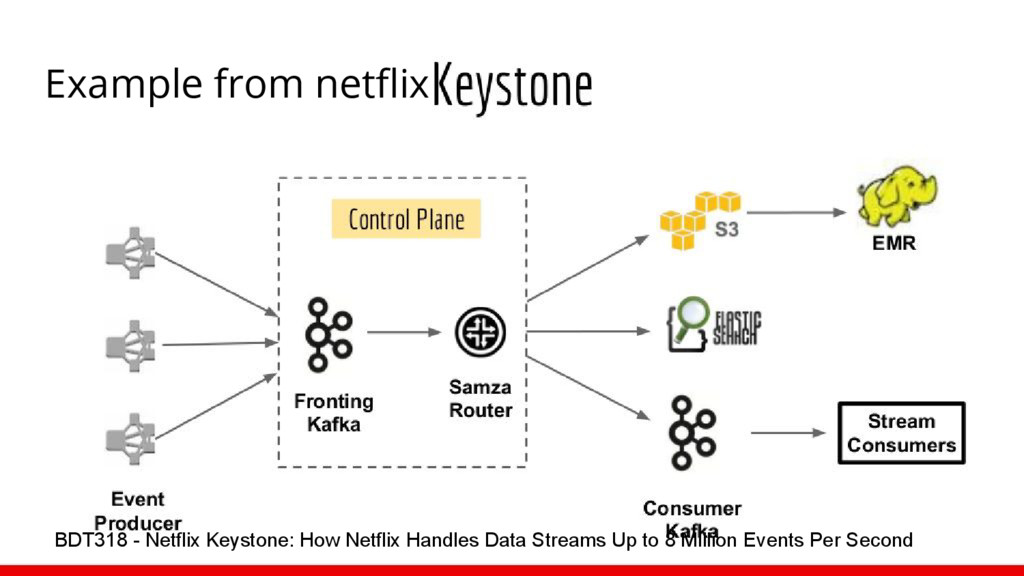{kind=link}
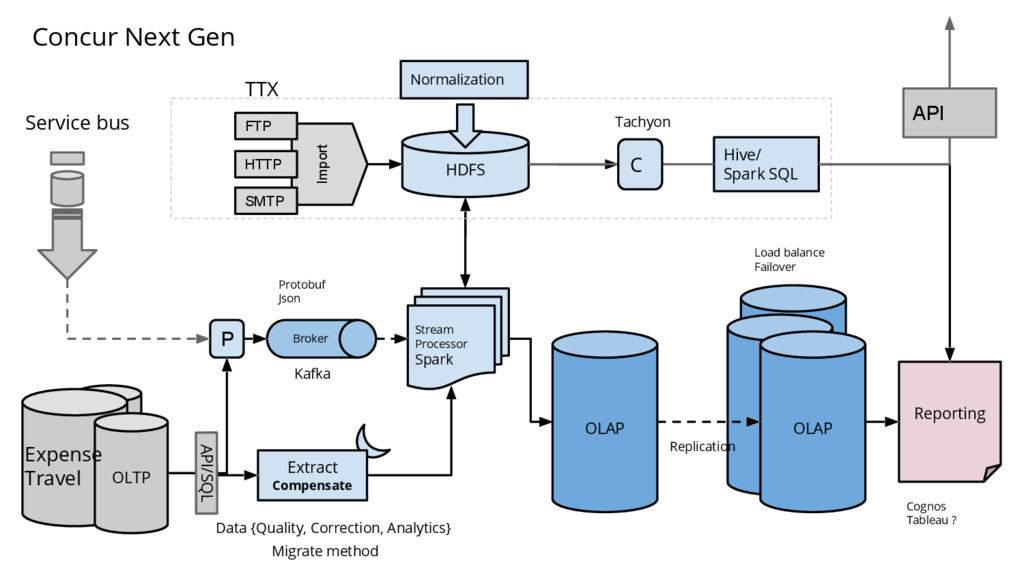{kind=link}
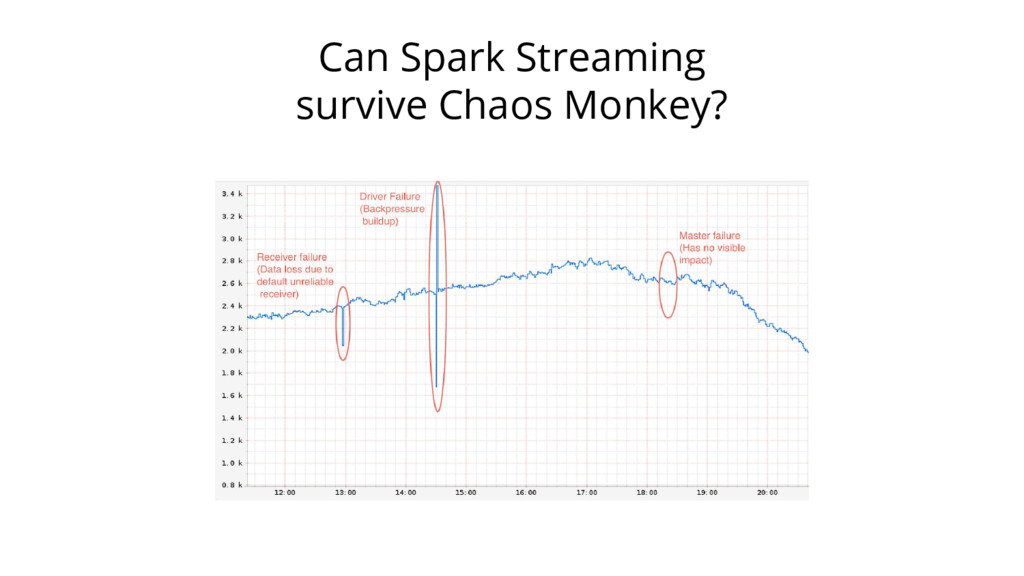{kind=link}
{kind=link}
{kind=link}