As software engineers, there is always a strong pressure on us to deliver our code quickly. But that could easily lead to cutting corners which is a false economy that hurts the project, morale, and, ultimately, the organization’s bottom line. Of course, as they say, “‘perfect' is the enemy of ‘done’.”, so this can certainly be taken too far. This talk discusses the tradeoffs of the two extremes, and examine how a healthy balance can be found by being careful and mindful of the code you write. After all, everything from (of course) system architecture all the way down to the names you choose for local variables impacts how easy the project is to maintain, and so is worth consideration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
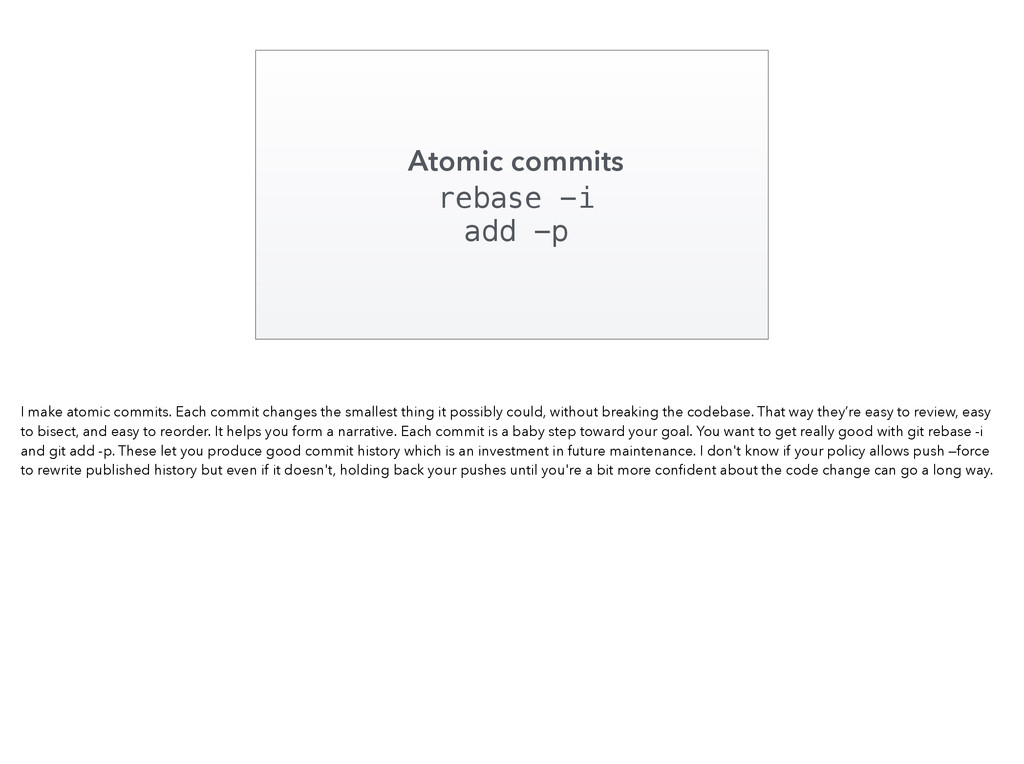{kind=link}
{kind=link}
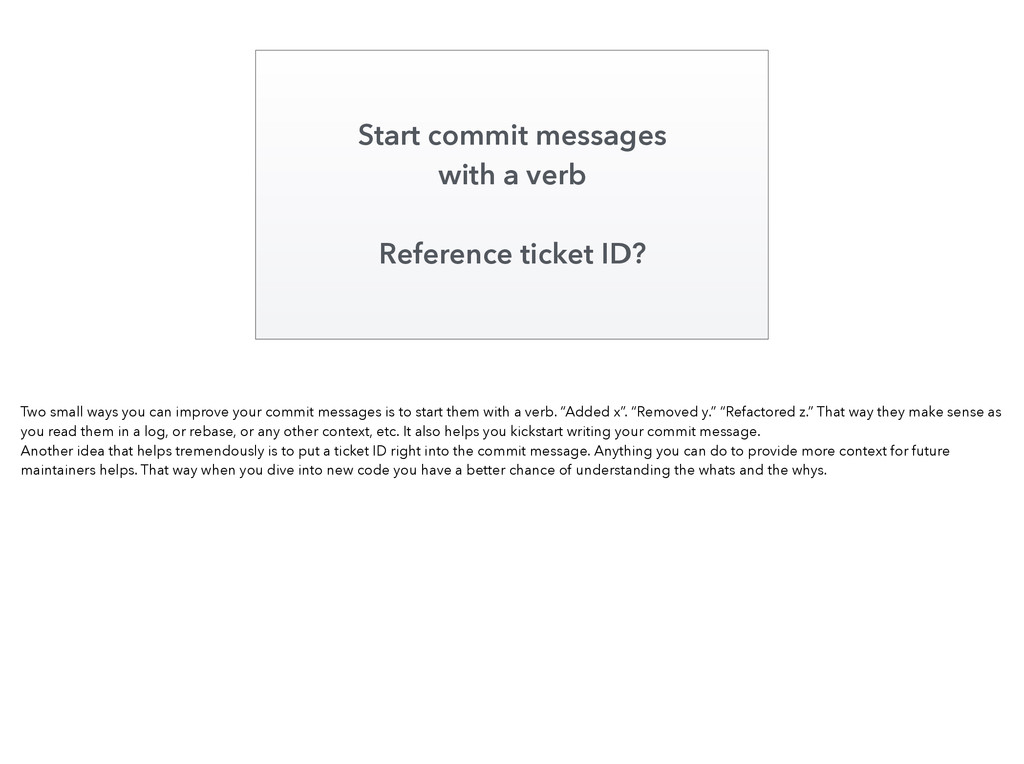{kind=link}
{kind=link}
{kind=link}
{kind=link}