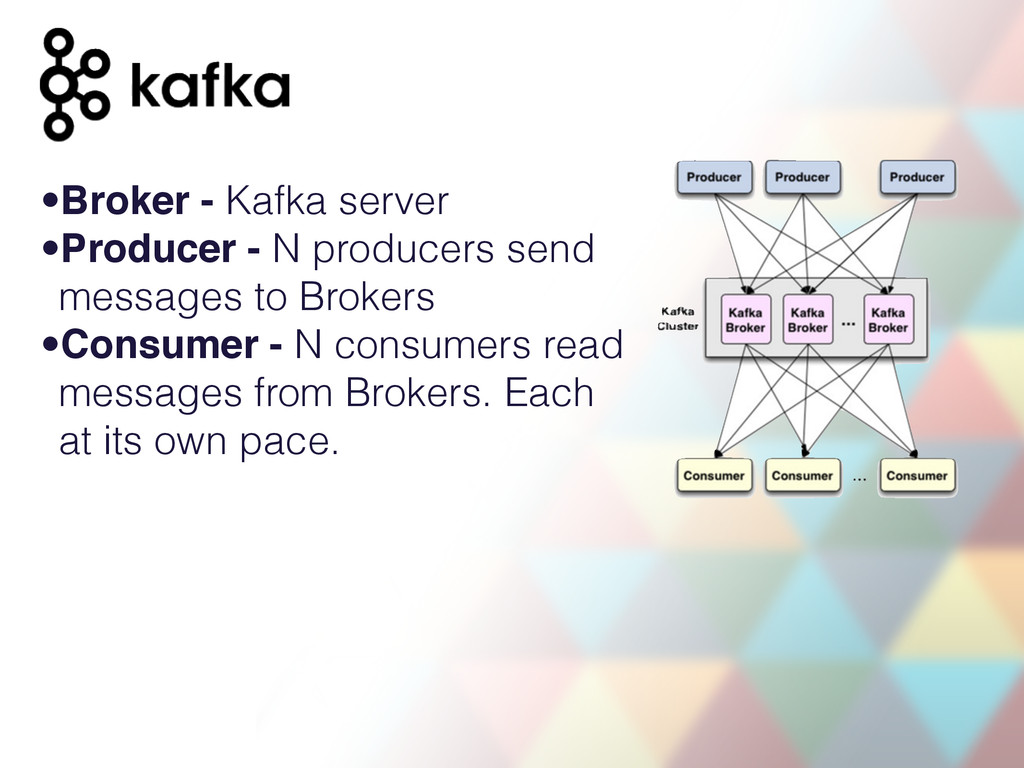
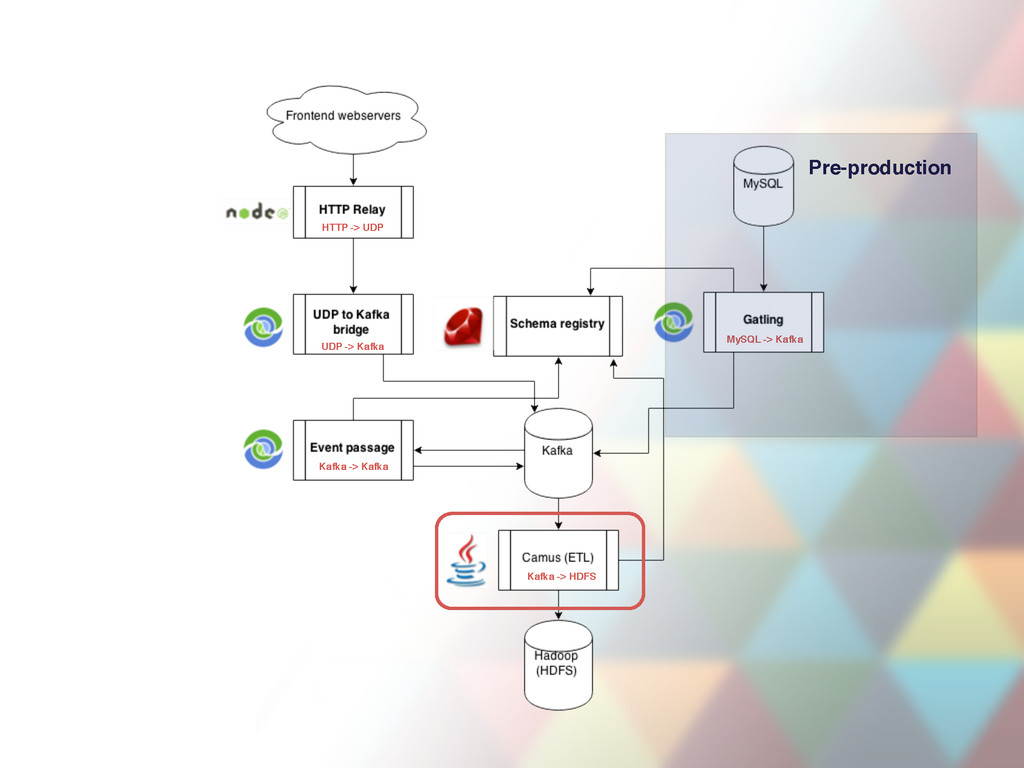
multiple nodes •Reliable: messages replicated across multiple nodes •Persistent: all messages are persisted to disk •Performant: works just fine with 70 000 message writes per second. Up to 700Mb/s (when replicating/rebalancing).
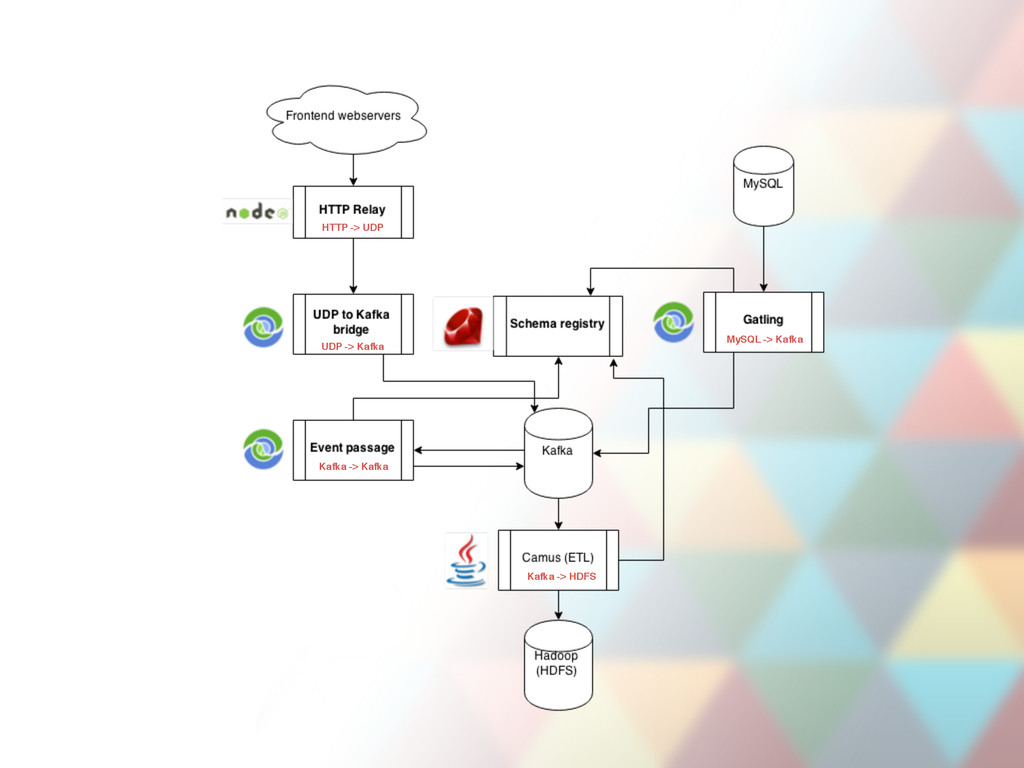
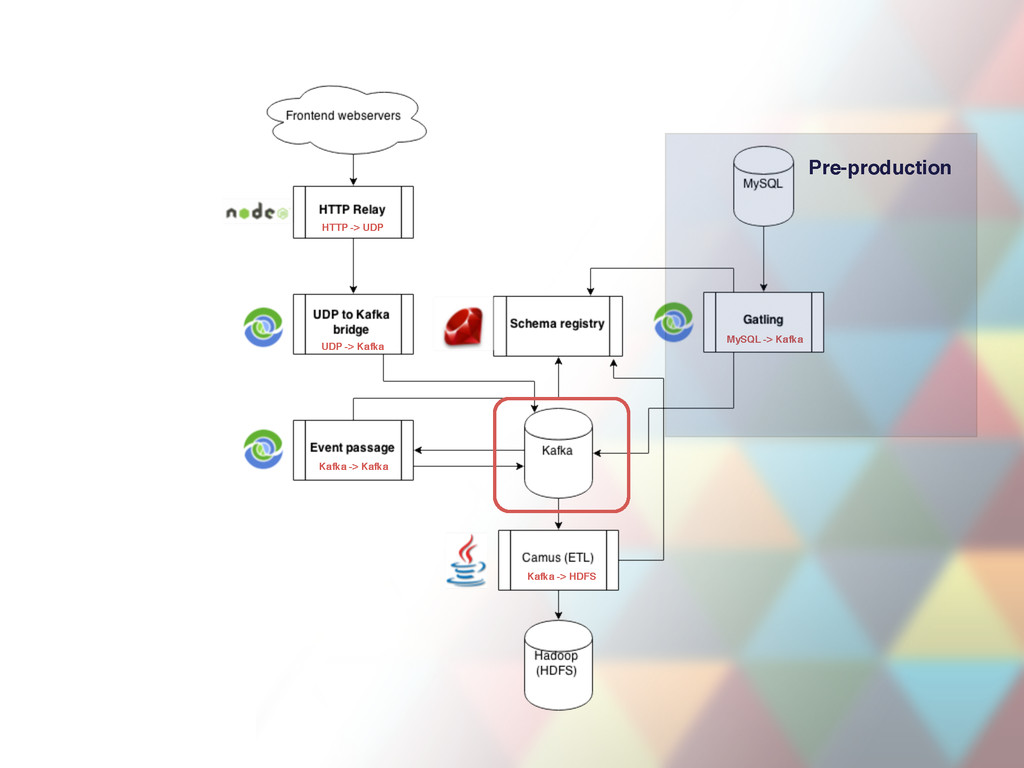
event batches • Unwraps the batch to single event JSON object • Enriches the object with metadata coming from HTTP request headers • Sends all events to UDP (svc-udp-kafka-bridge) • CI, continuous deploys • Single instance can be down
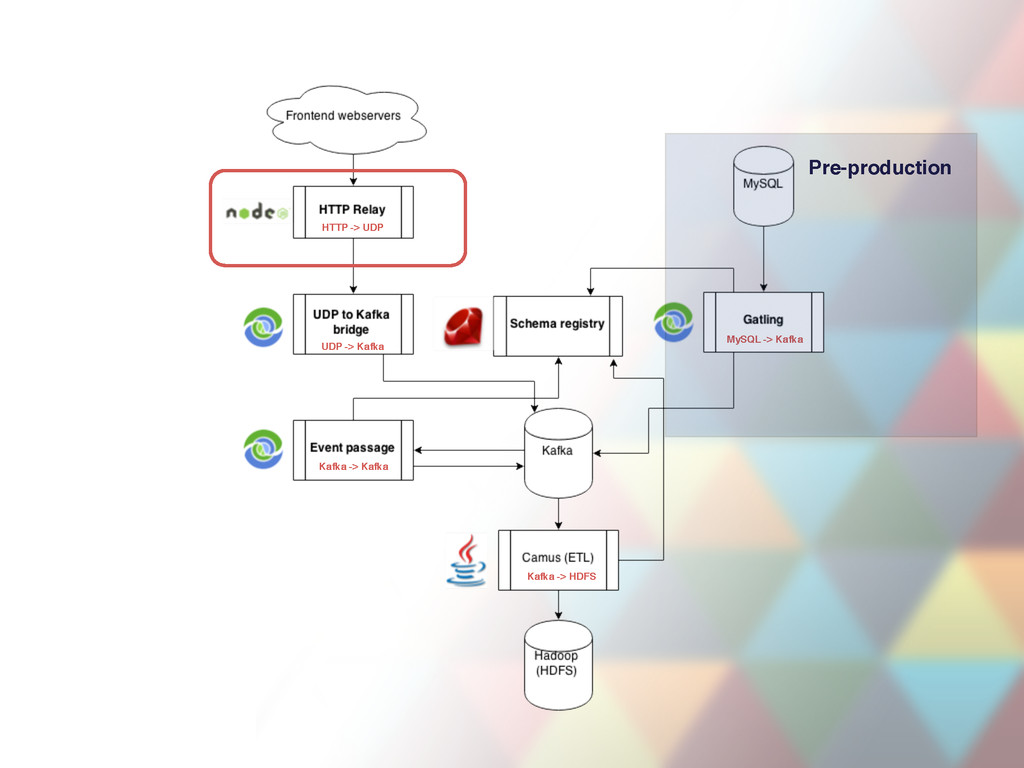
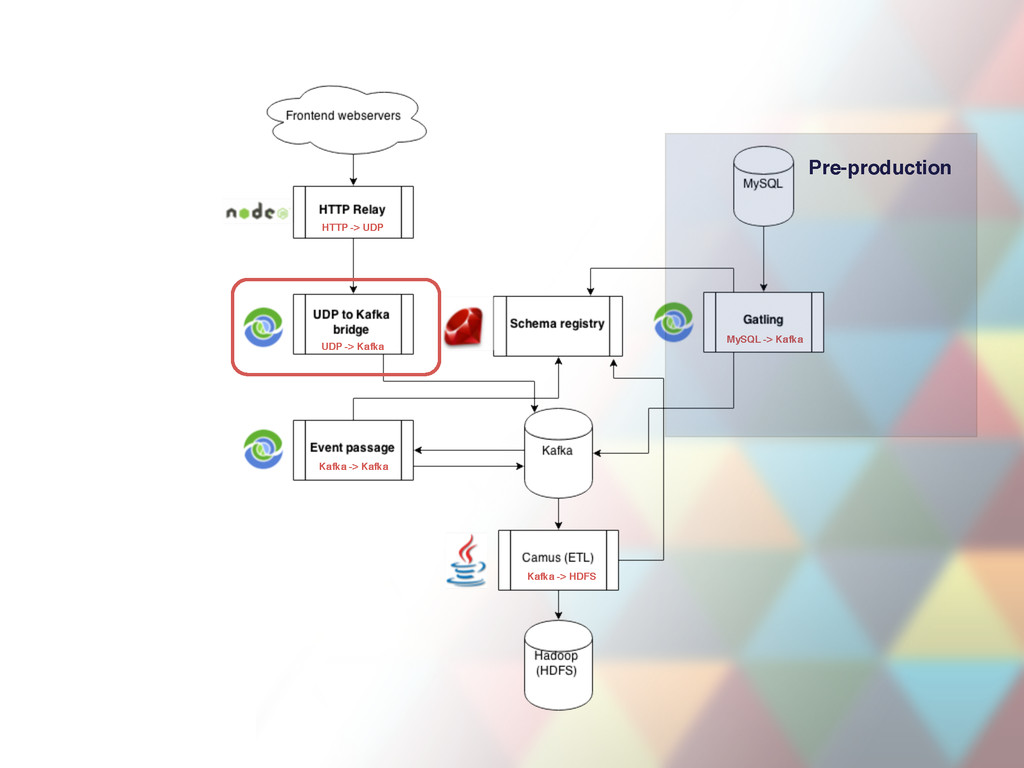
port for event JSON objects and relays them to Kafka broker • 47 instances deployed, ~6-10K requests per second through all instances, more during peak hours • CI, continuous deploys (takes a minute a deploy) • Uses clever socket trick during deploys to keep processing (SO_REUSEADDR) • Has internal in-memory buffer used in case Kafka is down. Only lasts ~1 minute depending on load. • Mission critical, both instances per host cannot be down
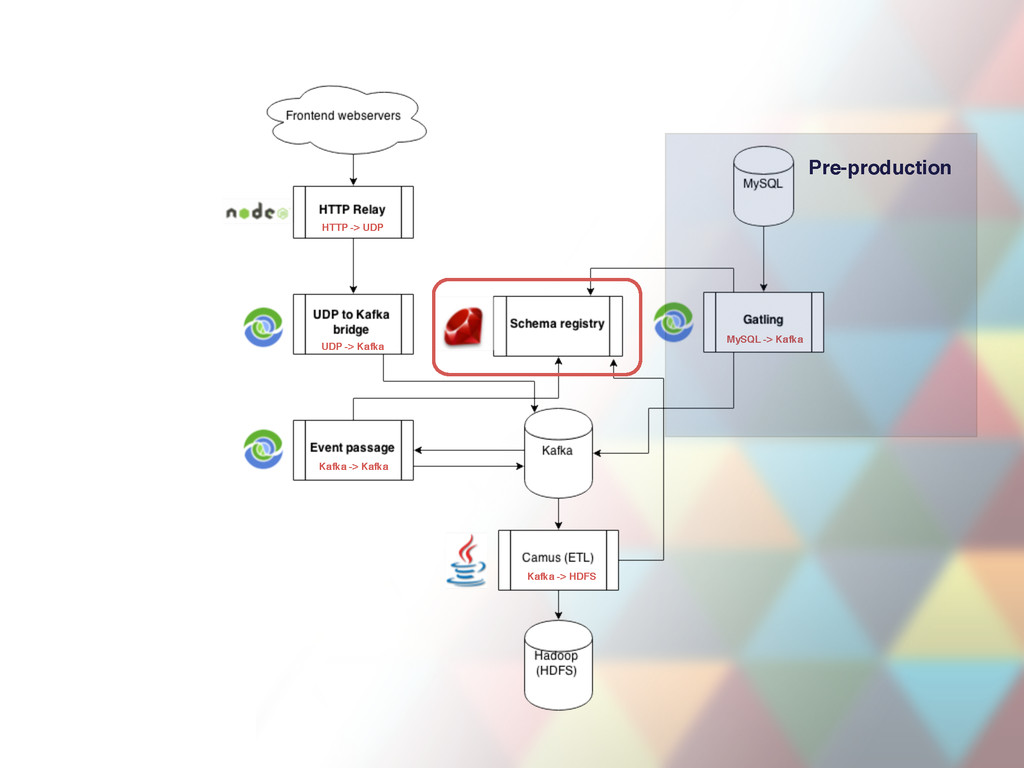
file server • + declarative ETL command generator • Centralized, human readable event registry page (field type descriptions, field purpose descriptions) • From just engage.inactive_seller.push_notification_sent to full descriptions of each field. • Schemas are used to encode event JSON files to binary Avro payload • CI, continous deploys • Deploy triggers redeploys of dependent services • Schemas automatically update in Hive tables (periodically).
event schemas from svc-schema-registry • Validate and encode events pushed by svc-udp-kafka-bridge to Avro payload • Push back to Kafka • JSON payload from events-hx topic becomes Avro byte payload in event.user.view_screen, event.user.view_item etc topics (one for each event type, ~200 in total). • Single instance processes ~1500+ events per second during peak hours • Can be down for ~ 5 days. • CI, continous deploys
(not a service!) • Periodically offloads Avro payload from event topics (event.user.view_screen, event.user.view_item etc) to Hadoop Distributed File System (HDFS). • + Do small transformations (ETL tasks) while offloading • Runs periodically, deployed from warehouse-jobs repo • Runs are scheduled via Oozie
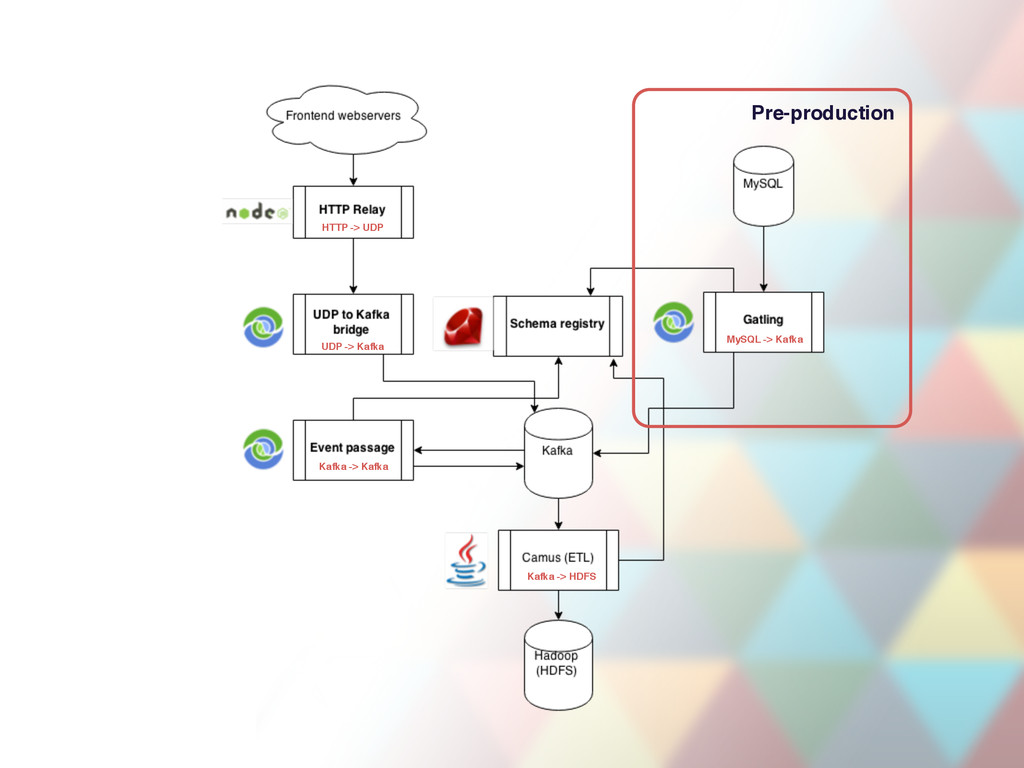
list of MySQL tables to HDFS nightly • We have ~1 day old snapshots of MySQL tables • Issues • Unreliable tooling • Lots of traffic each night to retransfer same data • We still get only a snapshot - table state at time X • In analytics we need facts not state (view) • Cannot build certain reports at all (data is gone)
stream • Captures change data for all tables like: • User insert • (login = “saulius”, email = “[email protected]”, real_name = “…”, …) • User update • (before: login = “saulius”, after: login = “nebesaulius”) • User delete • Encodes to Avro and pushes to Kafka • Why do this? • We get facts for free (e.g. user creation, removal) • We could recreate table snapshots faster, not just once per day • Real time data from MySQL (stream processing?) • We can recreate every table at any point in time.
this: SELECT CONCAT(ab.test_name, "_", ab.test_variant) test_id, COUNT(DISTINCT t.user_id) c FROM tracking_events.us__users_ex users INNER JOIN batch_views.ab_tests ab ON ab.portal = 'us' AND ab.test_name = 'orl' AND cast(users.id as string) = ab.user_id INNER JOIN (SELECT tp.user_id FROM tracking_events.us__user_sessions_ex tp WHERE tp.session_date BETWEEN '2014-12-10' AND ‘2014-12-12') tp ON tp.user_id = users.id LEFT JOIN (SELECT t.user_id FROM tracking_events.us__items_ex t WHERE t.created_at BETWEEN '2014-12-10' AND ‘2014-12-12') t ON t.user_id = users.id GROUP BY ab.test_name, ab.test_variant, users.id ORDER BY ab.test_variant ASC SELECT lister_count FROM listers_metric WHERE date BETWEEN '2014-12-10' AND ‘2014-12-12’ AND ab_test = ‘orl’ GROUP BY date, test_variant
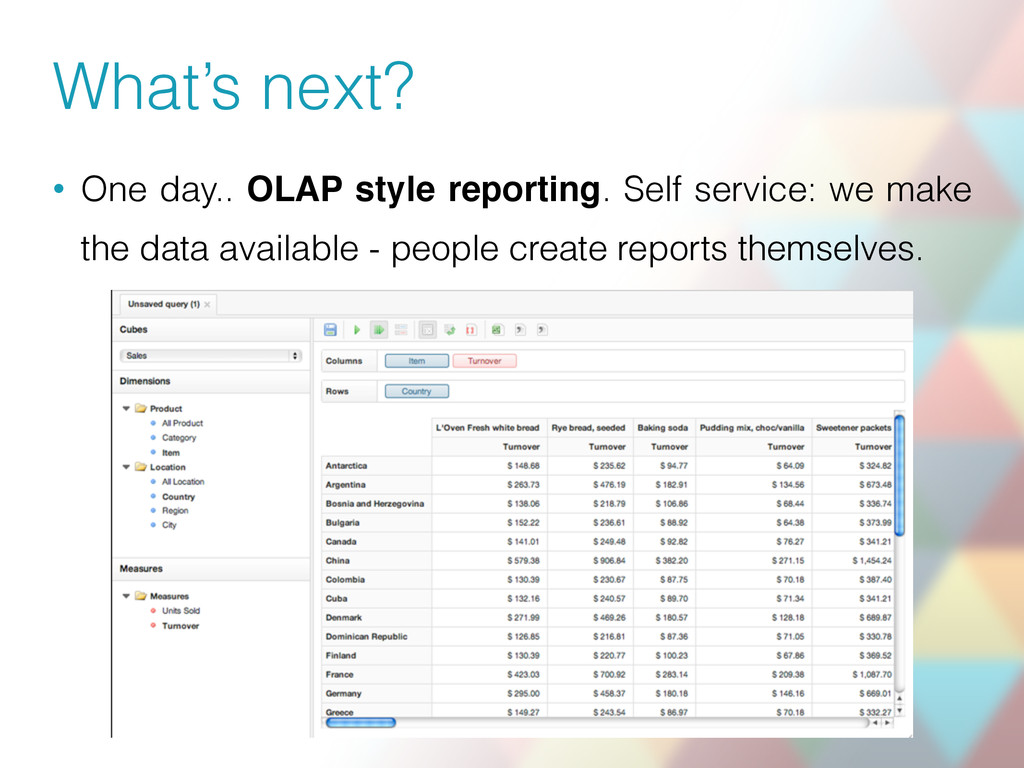
• Detect anomalies in event streams - identify failures quicker than we get a new support ticket • Join event streams with application metric or logging streams for root cause identification?
about real- time data's unifying abstraction • All Aboard the Databus! Linkedin’s Scalable Consistent Change Data Capture Platform • Wormhole pub/sub system: Moving data through space and time • The “Big Data” Ecosystem at LinkedIn • The Unified Logging Infrastructure for Data Analytics at Twitter • Kafka: A Distributed Messaging System for Log Processing • Building LinkedIn’s Real-time Activity Data Pipeline
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}