Spark in the cloud without going bankrupt. Platform Lunar's journey from AWS Elastic MapReduce to Ephemeral Spark clusters on AWS EC2 spot instances in order to save costs and boost data engineer productivity.
little infrastructure management as possible • Infrastructure scaling as needed • Enable data engineers • Data-related feature cost visibility • Apache Spark all the things
• Pay-as-you-use per- second billing • Runs uninterrupted • Up to 75% cheaper than on-demand • Fixed price for contract term • Runs uninterrupted • Up to 90% cheaper than on-demand • Pay-as-you-use per- second billing • Marketplace-based with bidding on compute capacity • Can be interrupted at any time with a 2 minute warning beforehand
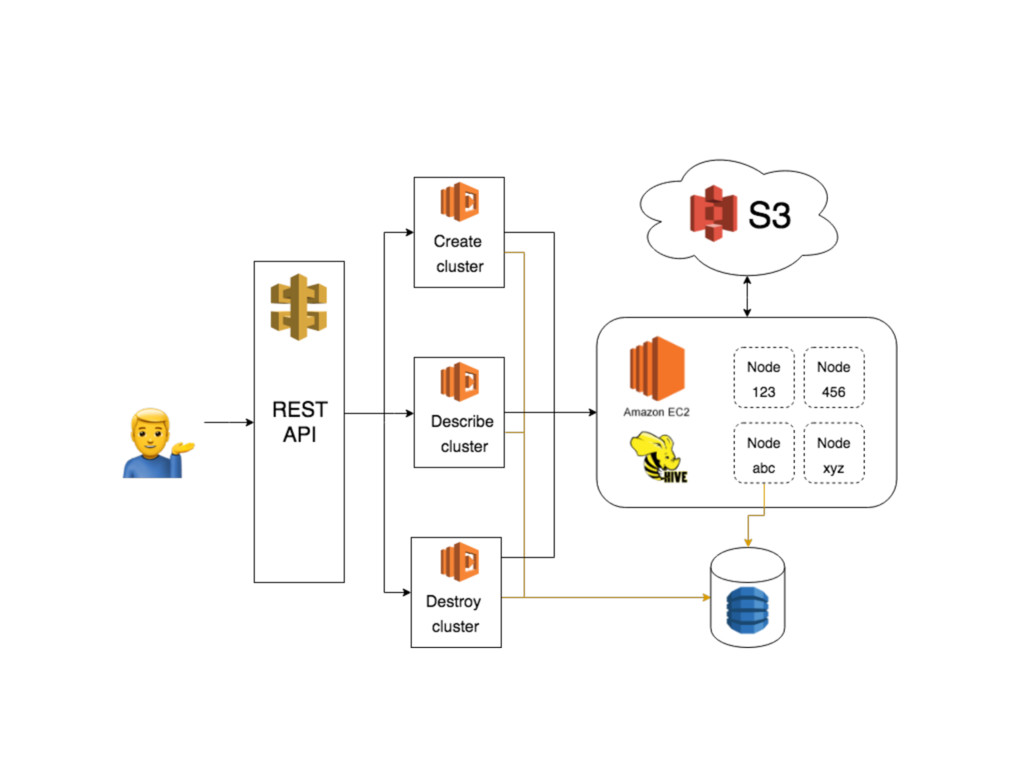
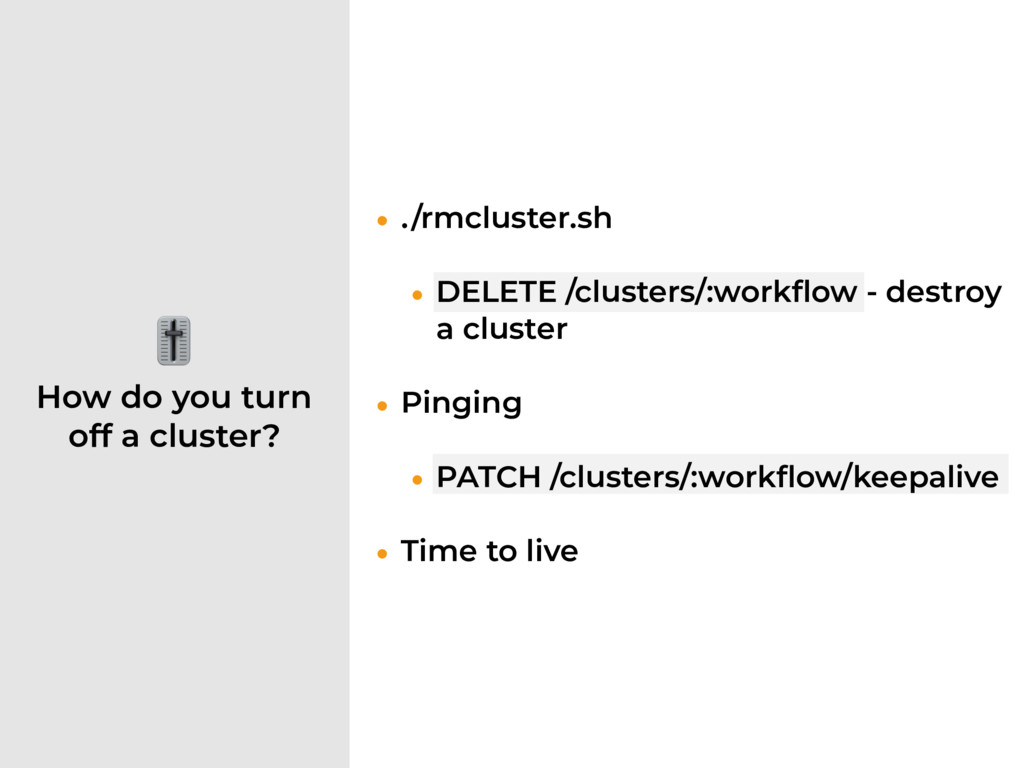
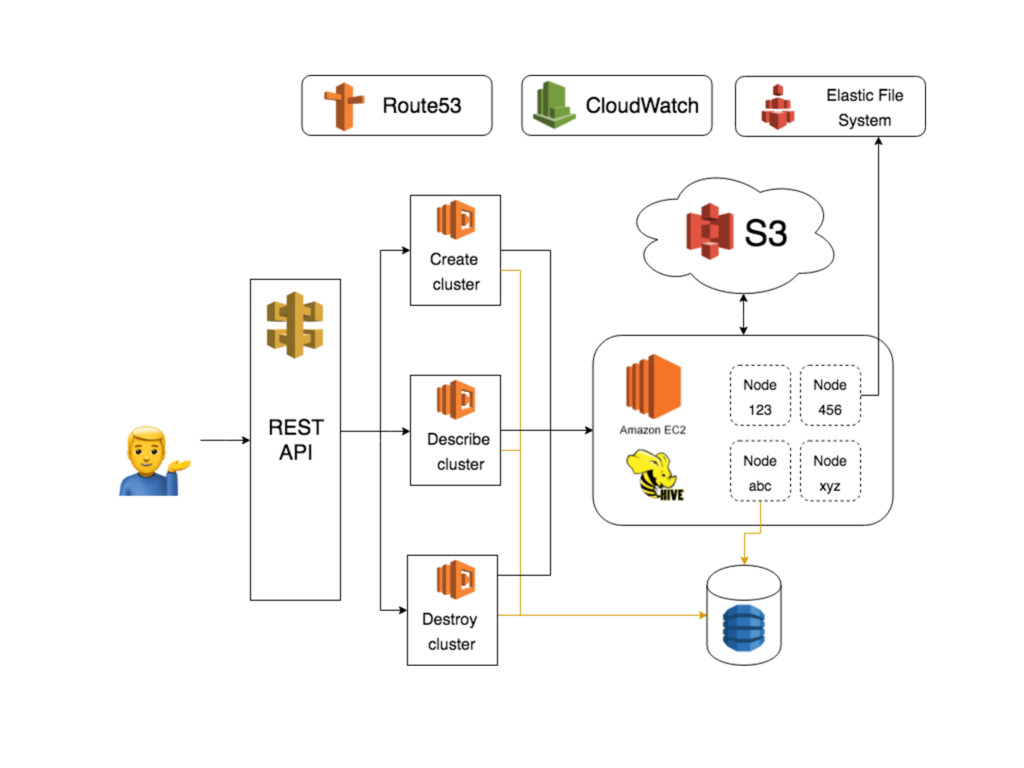
+ DynamoDB • POST /clusters - create new cluster • GET /clusters/:workflow - get cluster info • DELETE /clusters/:workflow - destroy a cluster • PATCH /clusters/:workflow/keepalive - keep a cluster running for a while
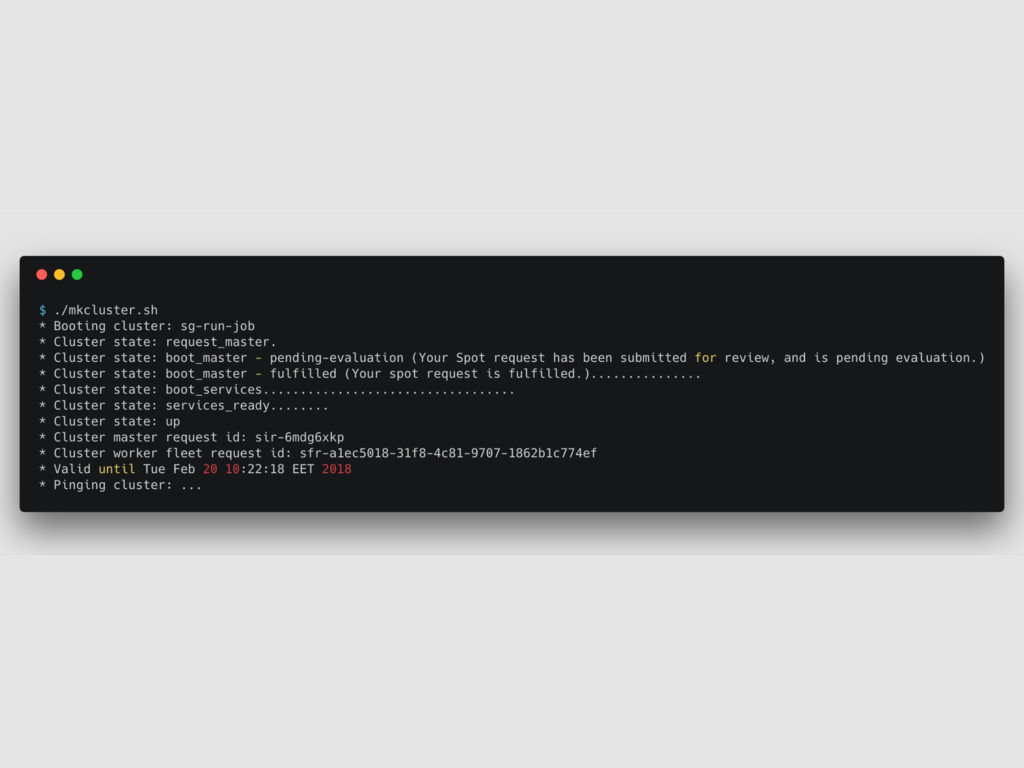
Livy (incubating) to run Spark Jobs • Livy - REST API to Apache Spark cluster • POST /batches - JAR file, class name, SparkConf params, executor and driver params • GET /batches/:batch_id - job state
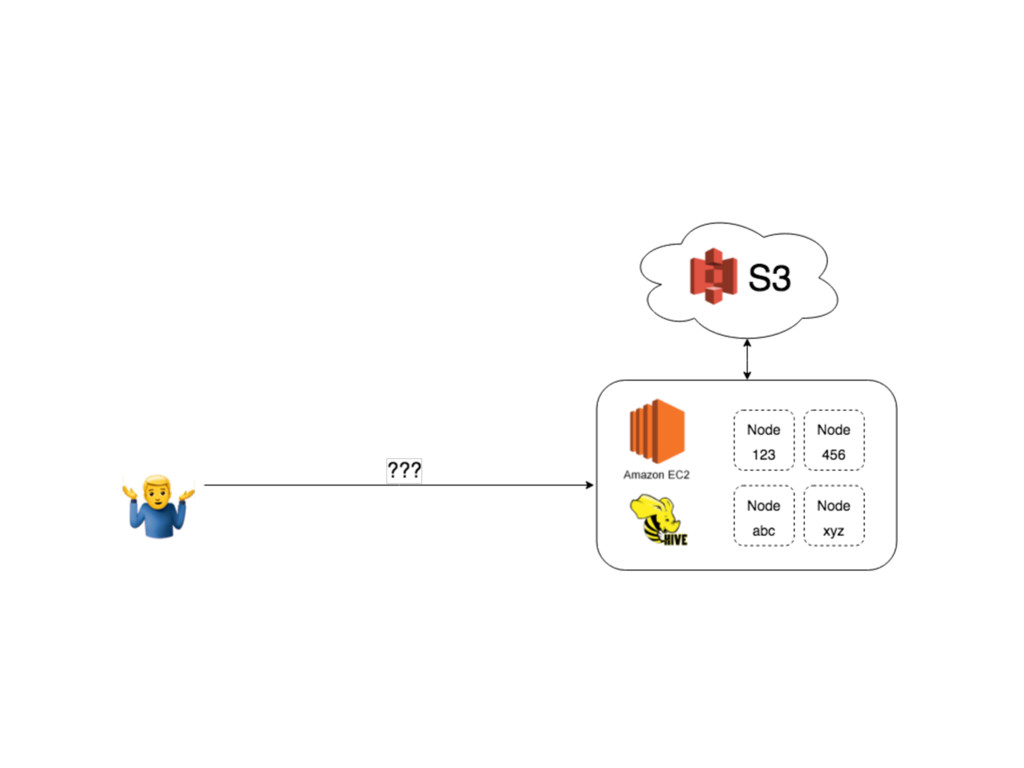
S3 log appender, AWS CloudWatch log appender • AWS Elastic File System (EFS) an Network File System (NFS) based solution • Files from EFS served via tiny Nginx instance, deleted periodically
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}